目次
TechLead をフォローして、AI に関するあらゆる次元の知識を共有してください。著者は 10 年以上のインターネット サービス アーキテクチャ、AI 製品の研究開発、チーム管理の経験があり、復旦大学同済大学で修士号を取得し、復丹ロボット知能研究所のメンバーであり、Alibaba Cloud 認定の上級アーキテクトです。 、プロジェクト管理の専門家、AI 製品の研究開発で数億の収益を上げています。
このペーパーでは、自然言語処理 (NLP) における構文分析の理論と実践について包括的に説明します。この記事では、構文と文法の定義から、さまざまな構文理論と方法に至るまで、構文分析のさまざまな側面を細心の注意を払って分析しています。最後に、PyTorch の実践的なデモンストレーションを通じて、これらの理論を具体的なタスクに適用する方法を示します。この記事は、読者に構文解析の包括的で詳細かつ実践的なガイドを提供することを目的としています。

I.はじめに
構文解析は、自然言語処理 (NLP) において重要かつ不可欠なタスクです。自然言語を巨大な建物と考えると、構文解析はこの建物の設計図のようなものです。この設計図があるからこそ、人々は言語の構造を理解し、意味分析、感情分析、機械翻訳などの高度なタスクをより正確に実行できるのです。
構文解析は学術研究において重要な位置を占めるだけでなく、商用アプリケーション、検索エンジン、ロボット対話システムなどの多くの分野でも重要な役割を果たしています。たとえば、高度な検索アルゴリズムは構文分析を使用してクエリをより正確に理解し、より関連性の高い検索結果を返します。
構文解析の重要性はよく知られていますが、その実装と応用は一朝一夕に達成できるものではありません。それには、数学的モデル、アルゴリズム、さらには人間の言語に対する深い理解が必要です。この記事では、構文解析の理論的基礎を包括的かつ詳細に紹介し、PyTorch フレームワークを使用して実践的なデモンストレーションを行います。
構文と文法の定義から始めて、それらの歴史的背景と理論的分類を探り、構成と依存関係の 2 つの主流の構文解析手法を紹介し、最後に PyTorch の実践的なコードのデモを提供します。この記事が理論学習と実践の応用において強力なサポートになれば幸いです。
2. 構文と文法: 定義と重要性
構文とは何ですか?
構文は、言語の構造と規則、つまり、単語、フレーズ、文がどのように結合されて意味のある表現になるかという研究に焦点を当てています。簡単に言えば、構文は文を構築するための「レシピ」のようなもので、単語 (材料) を組み合わせて完全で意味のある文 (料理) を作る方法を教えてくれます。
例
「猫はマットの上に座りました。」という単純な文を考えてみましょう。この文では、主語 (猫)、述語 (sat)、および目的語 (マットの上) が完全な文に結合されていることがはっきりとわかります。構文の規則。
構文とは何ですか?
構文とは異なり、文法 (Grammar) は、構文、音韻論 (Phonology)、意味論 (Semantics) などの側面を含む広い用語です。文法は、語彙の選択、語順、時制などを含むがこれらに限定されない、言語を正しく効果的に使用する方法を指定します。
例
先ほどの「猫はマットの上に座った」という文をもう一度考えてみましょう。「マットは猫の上に座った」のように語順を変えると、意味はまったく異なります。これは文法の役割であり、文が正しく構成されているだけでなく、明確な意味を持っていることを確認します。
構文と文法の重要性
構文と文法は、言語の理解と言語生成に不可欠な要素です。これらは、機械翻訳、テキストの要約、感情分析などの高度な NLP タスクのための強固な基盤を提供します。
構文の重要性
- 解釈可能性: 構文構造は、文の意味をより深く理解するのに役立ちます。
- 多様性: 構文規則により言語がより豊かで多様になり、表現力が向上します。
- 自然言語処理アプリケーション: 構文分析は、情報検索、機械翻訳、音声認識などのさまざまな NLP タスクの基礎となります。
文法の重要性
- 正確性: 文法規則により、言語の標準性と正確性が保証されます。
- 複雑さと深さ: 優れた文法構造は、より複雑で奥深いアイデアや情報を表現できます。
- 異文化コミュニケーション: 文法規則を理解すると、言語や文化を超えてより正確にコミュニケーションを図ることができます。
3. 構文理論: 歴史と分類
構文研究には長い歴史があり、さまざまな構文理論が言語構造の理解と分析の方法にさまざまな影響を与えます。このセクションでは、構文理論の歴史的背景とさまざまな分類について詳しく説明します。
生成文法
背景
生成文法は、限られたルールセットを通じて可能なすべての法的文章を生成する (つまり、生成する) ことを目的として、1950 年代にノーム チョムスキーによって提案されました。
例
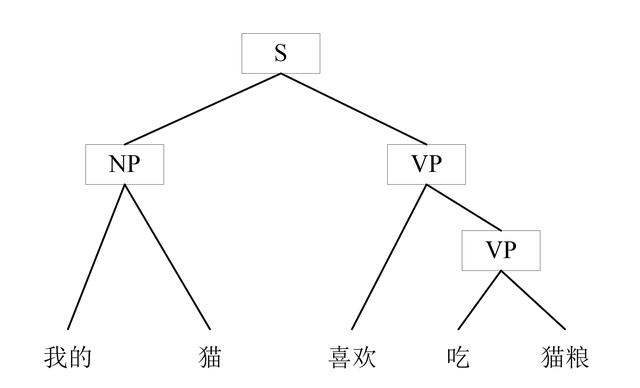
生成文法では、「ジョンはリンゴを食べる」などの文は、より高レベルの「S」(文)表記から生成されたものと見なすことができ、「S」は主語(NP、名詞句)と「S」に分解できます。述語 (VP、動詞句)。
依存関係の文法
背景
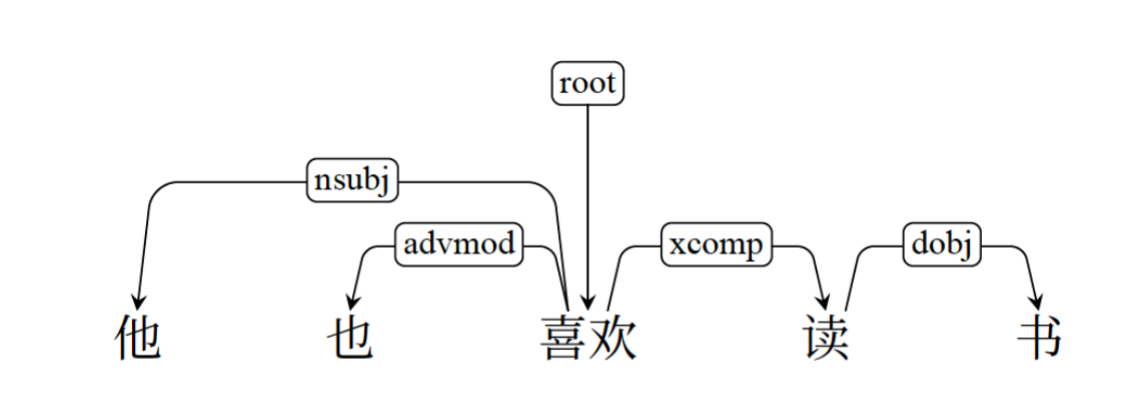
依存文法の中心的な考え方は、言語内の単語が意味を伝えるために互いに依存しているということです。この理論は、文内の単語の位置だけでなく、単語間の関係を強調します。
例
「ジョンはリンゴを食べる」という文では、「食べる」は実行者としての「ジョン」に依存しており、「リンゴ」は「食べる」の目的語である。これらの依存関係は、文の構造と意味を理解するのに役立ちます。
構築文法
背景
構築文法は、単語やフレーズが与えられたコンテキスト内でより大きな構造にどのように適合するかに関係します。この理論は、言語使用のダイナミクスと柔軟性を強調しています。
例
「バケツを蹴る」というフレーズを考えてみましょう。文字通りの意味は「バケツを蹴る」ですが、特定の文化や文脈では、このフレーズは実際には「死ぬ」という意味になります。構築文法は、この特定のコンテキストにおける意味の複雑さを説明できます。
カテゴリ文法
背景
カテゴリ文法は、数学的論理を使用して語彙項目がより複雑な式にどのように結合されるかを記述する、論理中心の文法システムです。
例
カテゴリー文法では、「run」などの動詞は、主語 (名詞) から述語 (動詞) までの関数として見ることができます。これは論理記号を使うとわかりやすく表現できます。
4. 語句および構文のカテゴリー
フレーズと構文カテゴリを理解することは、構文分析を実行する際の重要な手順の 1 つです。このセクションでは、これら 2 つの概念と構文解析におけるそれらの重要性について詳しく紹介します。
フレーズ
フレーズは、文の中で単位として出現する単語のグループであり、多くの場合、特定の文法的および意味的機能を持ちます。
名詞句 (NP)
意味
名詞句は通常、1 つ以上の名詞とそれに関連する修飾語 (形容詞や属性など) で構成されます。
例
- 「速い茶色のキツネ」は、「速い」と「茶色」が「キツネ」を修飾する形容詞である名詞句です。
動詞フレーズ、VP
意味
動詞句には、主要な動詞と、場合によっては一連の目的語または補語が含まれます。
例
- 「ジョンはリンゴを食べている」という文では、「リンゴを食べている」は動詞句です。
構文のカテゴリ
構文カテゴリは、文内の単語または語句の機能を抽象的に表現したものです。一般的な構文カテゴリには、名詞 (N)、動詞 (V)、形容詞 (Adj) などが含まれます。
アトミックカテゴリ
意味
これらは最も基本的な構文カテゴリであり、通常は名詞 (N)、動詞 (V)、形容詞 (Adj) などが含まれます。
例
- 「犬」は名詞です。
- 「走る」は動詞です。
- 「幸せ」は形容詞です。
複雑なカテゴリ
意味
複合カテゴリは、特定の構文規則によって結合された 2 つ以上の基本カテゴリで構成されます。
例
- 名詞句 (NP) は、「幸せな犬」など、名詞 (N) と形容詞 (Adj) で構成される複合カテゴリです。
5. 句構造ルールと依存構造
文の構造と構成を理解するには、通常、句構造ルールと依存構造という 2 つの主要な側面が関係します。以下では、これら 2 つの概念を 1 つずつ紹介します。
語句構造の規則
句構造ルールは、個々の単語から文または句の構造を生成する方法を説明する一連のルールです。
文の生成
意味
一般的な句構造ルールは、名詞句 (NP) と動詞句 (VP) を組み合わせて文 (S) を形成することです。
例
- 文(S) = 名詞句(NP) + 動詞句(VP)
- 「猫はマットの上に座った」(NP) + 「マットの上に座った」(VP) = 「猫はマットの上に座った」(S)
動詞句の複雑さ
意味
動詞句 (VP) 自体には、その構成要素として他の名詞句 (NP) や副詞 (Adv) が含まれる場合もあります。
例
- 動詞句 (VP) = 動詞 (V) + 名詞句 (NP) + 副詞 (Adv)
- 「食べる」(V) + 「リンゴ」(NP) + 「早く」(Adv) = 「リンゴを早く食べる」(VP)
依存構造
依存構造は、単語がフレーズや文にどのように組み合わされるかではなく、単語間の依存関係に焦点を当てます。
コア要素と依存要素
意味
係り受け構造では、各単語には「頭部」と、この頭部に依存する一連の「係り受け」があります。
例
- 「素早い茶色のキツネが怠惰な犬を飛び越える」という文では、「ジャンプ」が「頭」要素としての動詞です。
- 「素早い茶色のキツネ」はこの動詞の主語であるため、従属要素です。
- 「怠惰な犬の上で」はこの動詞の目的語であり、依存要素でもあります。
どちらの構造にも独自の利点と適用シナリオがあります。多くの場合、句構造ルールは正式な文法と一致しやすく、文の生成が容易になります。依存構造により単語間の関係が強調され、文の意味が理解しやすくなります。
6. 構文解析手法
構文分析は、文の意味と構成をより深く理解するために文の構造を解析するために使用される、NLP における重要なタスクです。このセクションでは、主流の構文解析手法をいくつか紹介します。
トップダウン分析
意味
文の最も高いレベル (通常は文 (S) 自体) から始めて、徐々にそれをより小さな構成要素 (名詞句、動詞句など) に分割します。
例
「猫はマットの上に座った」という文では、トップダウン分析によりまず文全体が特定され、次にそれが名詞句「猫」と動詞句「マットの上に座った」に分解されます。
ボトムアップ分析
意味
文の単語から始めて、それらを徐々に結合して、より高いレベルのフレーズや構造を形成します。
例
同じ文「猫はマットの上に座りました」について、ボトムアップ分析では、まず単語「The」、「cat」、「sat」、「on」、「the」、「mat」を特定し、次にそれらを結合します。名詞句と動詞句、そして最終的には文全体になります。
アーリーアルゴリズム
意味
より複雑な文法システムに適した、より効率的な構文解析手法。
例
文に複数の可能な解析方法がある場合 (つまり、曖昧さがある場合)、ear アルゴリズムは、そのうちの 1 つだけを見つけるのではなく、可能なすべての解析構造を効果的に識別できます。
統計的解析 (確率的解析)
意味
機械学習または統計的手法を使用して、最も可能性の高い文構造を予測します。
例
あいまいな文に直面した場合、統計ベースの手法では、ルールだけに依存するのではなく、事前トレーニングされたモデルを使用して、最も可能性の高い文構造を予測できます。
遷移ベースの解析
意味
一連の操作(プッシュ、ポップ、左、右など)を通じて、文の依存関係を徐々に構築していきます。
例
「彼女はリンゴを食べる」という文を処理する場合、変換ベースの分析は「彼女」から始まり、一連の操作を通じて徐々に「食べる」と「リンゴ」を追加し、それらの間の依存関係を確立します。
PyTorch の実践的なデモンストレーション
このセクションでは、PyTorch を使用して上記の構文解析メソッドのいくつかを実装します。次のコード スニペットは Python と PyTorch で書かれており、理解しやすいように十分なコメントが付けられています。
トップダウン分析
サンプルコード
以下のコードは、PyTorch を使用して単純なトップダウン解析モデルを実装する方法を示しています。
import torch
import torch.nn as nn
# 定义模型
class TopDownParser(nn.Module):
def __init__(self, vocab_size, hidden_size):
super(TopDownParser, self).__init__()
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.rnn = nn.LSTM(hidden_size, hidden_size)
self.classifier = nn.Linear(hidden_size, 3) # 假设有3种不同的短语类型:NP, VP, PP
def forward(self, x):
x = self.embedding(x)
x, _ = self.rnn(x)
x = self.classifier(x)
return x
# 示例输入:5个词的句子(用整数表示)
input_sentence = torch.tensor([1, 2, 3, 4, 5])
# 初始化模型
model = TopDownParser(vocab_size=10, hidden_size=16)
output = model(input_sentence)
print("输出:", output)入出力
- 入力: 整数で表される文 (各整数は語彙内の単語のインデックスです)。
- 出力: 文内の各単語が属する句タイプ (名詞句、動詞句など)。
ボトムアップ分析
サンプルコード
# 同样使用上面定义的 TopDownParser 类,但训练和应用方式不同
# 示例输入:5个词的句子(用整数表示)
input_sentence = torch.tensor([6, 7, 8, 9, 10])
# 使用相同的模型
output = model(input_sentence)
print("输出:", output)入出力
- 入力: 整数で表される文。
- 出力: 文内の各単語に使用できるフレーズのタイプ。
これは単なる単純な実装例であり、実際のアプリケーションではさらに詳細な設定や最適化が必要になる場合があります。
7. まとめ
構文分析は、自然言語処理 (NLP) の重要なコンポーネントとして、人間の言語の構造を理解して解析する上で重要な役割を果たします。歴史的背景から理論的な分類、フレーズや依存構造の理解に至るまで、構文解析の多次元を 1 つずつ探求します。実用レベルでは、PyTorch を適用することで、これらの理論を現実世界のタスクに実装する方法がさらに明らかになります。理論と実践を統合することで、言語構造をより深く理解できるだけでなく、さまざまな NLP 問題をより効果的に処理できるようになります。この学際的な統合は、将来のより革新的なアプリケーションと研究のための強固な基盤を提供します。
TechLead をフォローして、AI に関するあらゆる次元の知識を共有してください。著者は 10 年以上のインターネット サービス アーキテクチャ、AI 製品の研究開発、チーム管理の経験があり、復旦大学同済大学で修士号を取得し、復丹ロボット知能研究所のメンバーであり、Alibaba Cloud 認定の上級アーキテクトです。 、プロジェクト管理の専門家、AI 製品の研究開発で数億の収益を上げています。