アプリケーションシナリオ
データテーブルは、各プロジェクトグループのデータ情報を受け取るために使用されます。データのアップロード頻度は非常に高く、データ量は 1 週間で 10 万件以上に達します。データ
テーブルsys_orderの単純な構造は次のとおりです

。データ量が増加すると、プロジェクト データベース テーブルのデータ量が大きすぎます。shardingSphere を使用して groupId フィールドに従って水平テーブル分割を実行する必要があり、各プロジェクト グループがテーブルに対応するため、管理が便利であり、データ テーブルへの負担が軽減されます。
実装手順
Maven 依存関係をインポートする
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
yamlファイルを設定する
spring:
shardingsphere:
mode:
# 运行模式类型。可选配置:内存模式 Memory、单机模式 Standalone、集群模式 Cluster
type: Memory
props:
#是否在日志中打印 SQL。
#打印 SQL 可以帮助开发者快速定位系统问题。日志内容包含:逻辑 SQL,真实 SQL 和 SQL 解析结果。
#如果开启配置,日志将使用 Topic ShardingSphere-SQL,日志级别是 INFO。 false
sql-show: true
#是否在日志中打印简单风格的 SQL。false
sql-simple: false
#用于设置任务处理线程池的大小。每个 ShardingSphereDataSource 使用一个独立的线程池,同一个 JVM 的不同数据源不共享线程池。
executor-size: 20
#次查询请求在每个数据库实例中所能使用的最大连接数。1
max-connections-size-per-query: 1
#在程序启动和更新时,是否检查分片元数据的结构一致性。
check-table-metadata-enabled: false
#在程序启动和更新时,是否检查重复表。false
check-duplicate-table-enabled: false
datasource:
names: ds0
ds0:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/db0
username: root
password: root
rules:
sharding: #ShardingSphere-JDBC全局序列配置规则
key-generators:
# 雪花算法生成数据库id,不使用可以不设置
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
#分片算法配置
sharding-algorithms:
## 分片算法名称
fenpian-table-1:
#对应 Override getType
type: MOD # 使用取模分片算法
props:
sharding-count: 20 # 取模数量,暂时分20张表吧
tables:
# 逻辑表名称
sys_order:
# 由数据源名 + 表名组成(参考 Inline 语法规则)
actual-data-nodes: ds0.sys_order${
0..20}
# 分表策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
table-strategy:
#standard: # 用于单分片键的标准分片场景
standard:
#数据库的键
shardingColumn: group_id
sharding-algorithm-name: fenpian-table-1
# 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
主要な設定手順
共有部分はテーブルを分割するために使用する必要があるアルゴリズムで、1 つは ID の生成に使用されるスノーフレーク アルゴリズム、もう 1 つはテーブルの分割で使用されるモジュロ アルゴリズムです
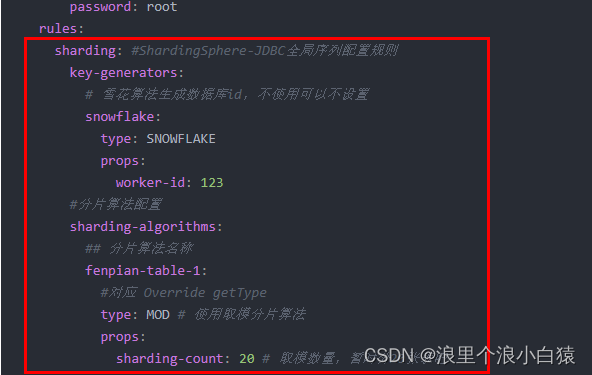
。分割テーブルは、データ ソースと分割戦略によって使用されます。この使用はライブラリを一時的に分割するものではありません

フォローアップテスト
追加を待っています...