最近読んだ本では、ソースコードが非常に明確でした。これまでの私の理解と組み合わせて、これについていくつかのエッセイを書き留め、後で参照できるようにここに移動したいと思います。
物語は、単層パーセプトロンが「排他的論理和」演算を実行できないことから始まります。
パーセプトロン(Perception) が最初に提案されたとき、発明者としてローゼンブラット (Rosenblatt) は広く賞賛されましたが、彼の反対者たちは排他的論理和問題を解くことを不可能にしました。未来では、人工知能開発史上初めて寒い冬に遭遇し、ローゼンブラットもこれが原因でうつ病で亡くなりました。当時、ローゼンブラット氏が知らなかったのは、多層パーセプトロンが「排他的論理和」問題に代表される非線形問題を解決できるということであり、ディープラーニングで使用されるディープニューラルネットワークがどのように構成されるのかも知らなかったということです。これにより、一連のスマート アプリケーションが出現しました。もちろん、当時は多層ニューラル ネットワークのトレーニング メカニズムを見つけることができなかったことが進歩の鍵でした。バックプロパゲーション(BP) アルゴリズムの導入により、ニューラル ネットワークは複雑な非線形問題に直面しても強力な回帰とパフォーマンスを示しました。 . 分類能力。
単層パーセプトロンはなぜ「排他的論理和」演算を実現できないのか
これは、本質的に線形ユニット である単層パーセプトロンの構造から始まります 。
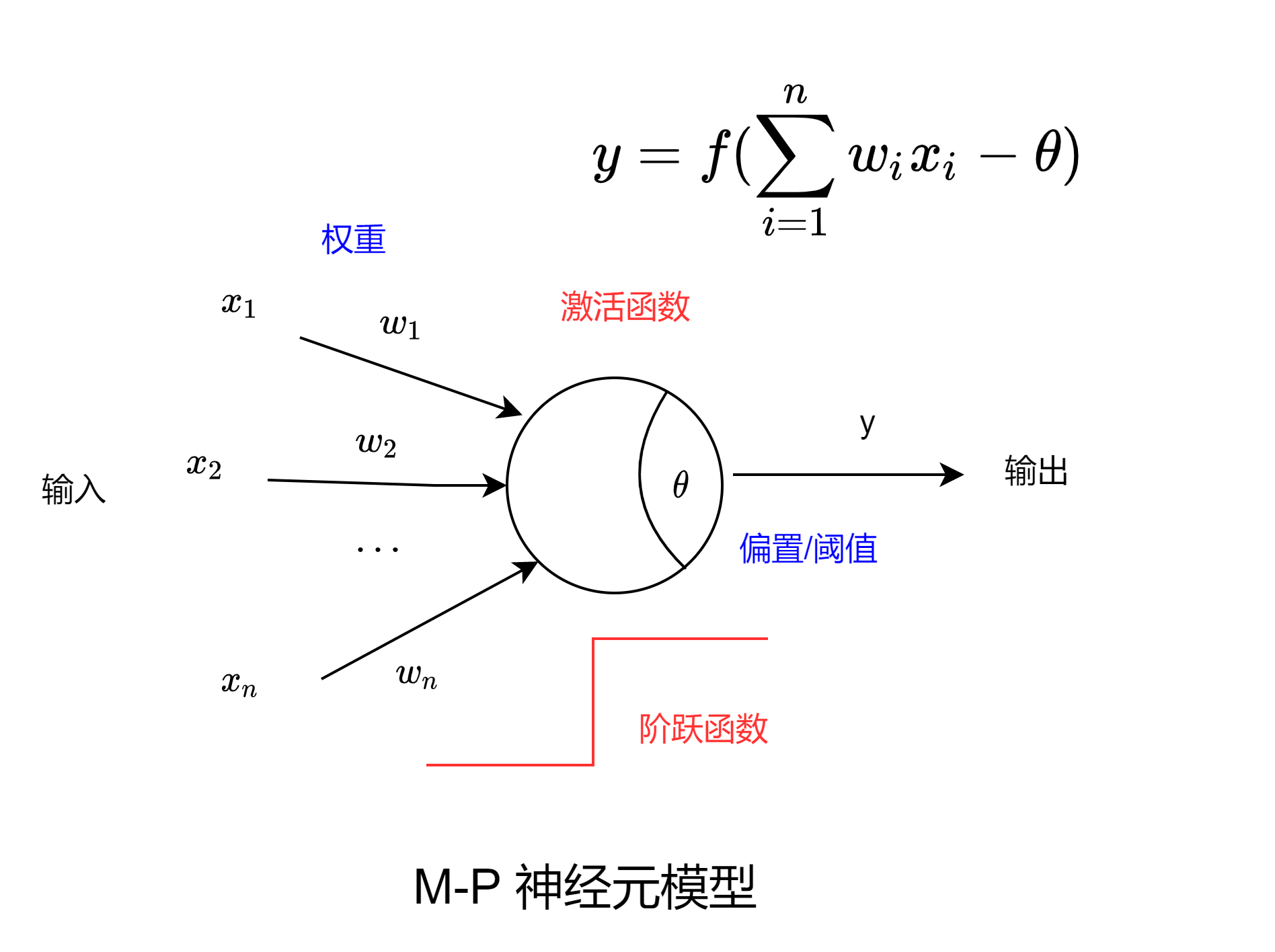
平面では、「and」、「or」、「not」の問題については、線形超平面を描いて問題を区別できます。しかし、「XOR」問題では、そのような線形超平面は見つかりません。つまり、少なくとも 2 つの分割線が必要です。




バイナリを例に取ると、これを数式から簡単に証明できます。 このような線形超平面があると仮定します。
{ w 1 + θ > 0 ( 1 ) w 2 + θ > 0 ( 2 ) θ < 0 ( 3 ) w 1 + w 2 + θ < 0 ( 4 ) \left\{ \begin{aligned} w_1+ \theta > 0 &&(1) \\ w_2+\theta > 0 &&(2) \\ \theta< 0 &&(3) \\ w_1+w_2+\theta < 0 &&(4) \end{aligned} \right。⎩ ⎨ ⎧w1+私>0w2+私>0私<0w1+w2+私<0( 1 )( 2 )( 3 )( 4 )
(1) ~ (3) を組み合わせると、 { w 1 + θ > 0 w 2 > − θ > 0 ⇒ w 1 + w 2 + θ > 0 \left\{ \begin{aligned} w_1+\theta>0 を得ることができます。
\\ w_2 > -\theta >0 \end{aligned} \right. \Rightarrow w_1+w_2+\theta>0{
w1+私>0w2>−私>0⇒w1+w2+私>0
そしてこれは明らかに (4) と矛盾します。つまり、そのような線形超平面は存在しません。
2層パーセプトロンで「排他的論理和」演算を実現
PyTorch を通じて、2 層ニューラル ネットワークを使用して「排他的 OR」演算をシミュレートします (cuda のバージョンが適切でないため、作者はソース コードと一致する GPU アクセラレーションを使用せず、CPU 上で直接トレーニングしました)。
最初に構築する必要があるのは、4 つの入出力関係のペアです。
x = [[0,0],[0,1],[1,0],[1,1]]
y = [[0],[1],[1],[0]] # 用列表构建输入和输出
次に、2 層のニューラル ネットワークを構築します。
net = nn.Sequential(
nn.Linear(2,20), # 全连接层,2个输入,20个输出
nn.ReLU(), # ReLU激活函数层
nn.Linear(20,1), # 全连接层,20个输入,1个输出
nn.Sigmoid() #Sigmoid 激活函数层
)
次は通常のトレーニングプロセスです。トレーニングの全体的な処理コードは次のとおりです。
import torch
import torch.nn as nn # 导入torch模块和nn模块
x = [[0,0],[0,1],[1,0],[1,1]]
y = [[0],[1],[1],[0]] # 用列表构建输入和输出
x_tensor = torch.tensor(x)
y_tensor = torch.tensor(y) # 将列表转换成Tensor变量
x_tensor = x_tensor.float()
y_tensor = y_tensor.float()
net = nn.Sequential(
nn.Linear(2,20), # 全连接层,2个输入,20个输出
nn.ReLU(), # ReLU激活函数层
nn.Linear(20,1), # 全连接层,20个输入,1个输出
nn.Sigmoid() #Sigmoid 激活函数层
)
print(net) # 输出网络结构,也可以去掉
optimizer = torch.optim.SGD(net.parameters(), lr = 0.05) # 设置优化器
loss_func = nn.MSELoss() # 设置损失函数,均方误差函数
for epoch in range(5000): # 训练部分
out = net(x_tensor) # 实际输出
loss = loss_func(out, y_tensor) # 实际输出和期望输出传入损失函数
optimizer.zero_grad() # 清除梯度
loss.backward() # 误差反向传播
optimizer.step() # 优化器开始迭代
if epoch % 1000 == 0: # 每1000epoch显示
print(f'迭代次数:{
epoch}') # 输出迭代次数
print(f'误差:{
loss}') # 输出损失函数的输出值
out = net(x_tensor)
print(f'out:{
out.data}') # 输出训练到最后的结构
torch.save(net,'net.pkl') # 保存整个网络模型
操作の結果は次のようになります。
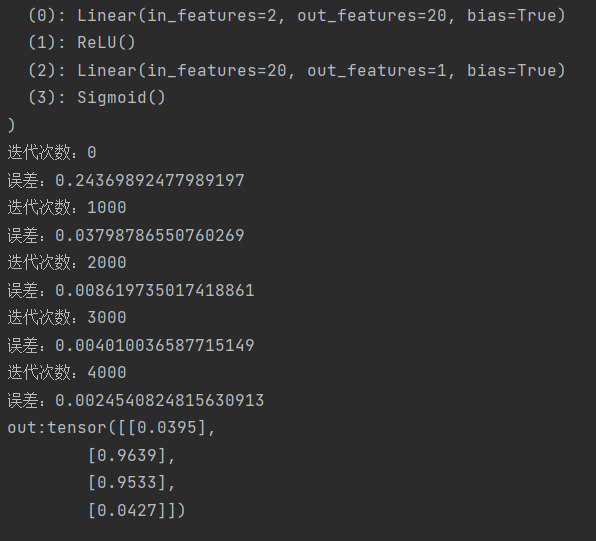
4000 回のトレーニング後、誤差はわずか 2 パーセントまで減少したことがわかります。そこに保存されている「net.pkl」ファイルはトレーニングしたネットワークであり、ネットワークの構造 (層数など) とその重みが含まれています。
次に、トレーニングされたモデルをロードし、検証のために一連のパラメーター (0,1) を入力します。プロセスは次のとおりです。
import torch # 导入torch模块
x = [[0,1]]
x_tensor = torch.tensor(x) # 设置输入
x_tensor = x_tensor.float() # 将Tensor变量转换成FloatTensor类型,直接传入CPU
net = torch.load('net.pkl') # 加载保存的网络模型
out = net(x_tensor) # 将输入传入网络得到输出
# out = out.cpu() # 将输出从GPU传入CPU
outfinal = out.data # 取输出的数据
if outfinal > 0.5: # 判断输出结果是否大于0.5,决定最终输出
outfinal = 1
else:
outfinal = 0
print(f'out={
outfinal}') # 输出最终输出
out=1 が予想される結果と一致していることがわかり、読者は他の入力も検証できます。「スズメは小さくて完成度が高い」という、単純な「XOR」演算だけではありますが、読者はニューラルネットワークの学習の基本的な過程を垣間見ることができ、そこがこの例の繊細さだと思います。