目次
コルーチンの原理:
(学習ソース: Youlin Lab )
スレッドはプロセスの実行本体であり、実行エントリと、プロセスの仮想アドレス空間から割り当てられたスタック (ユーザー スタックやカーネル スタックを含む) を持ちます。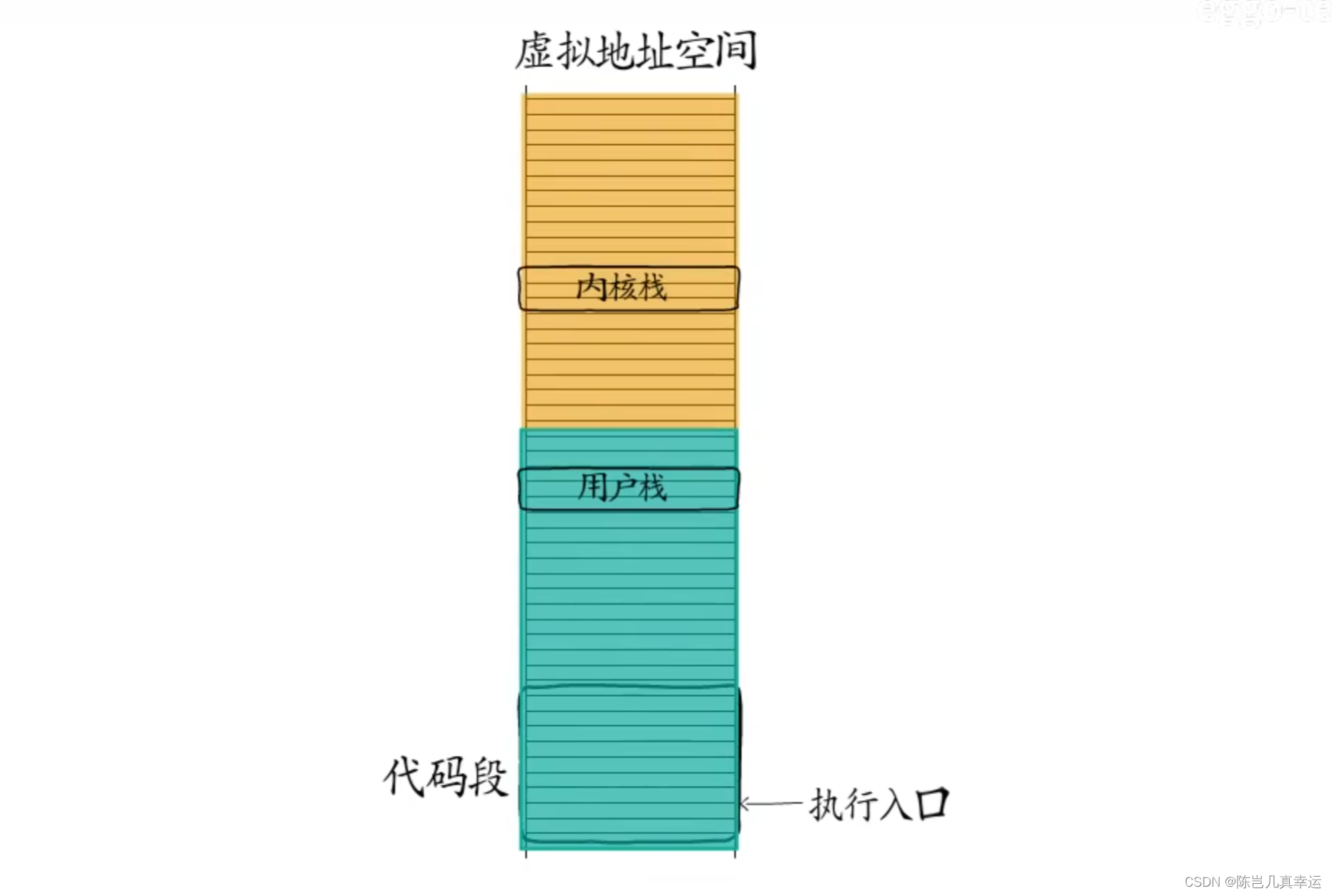
オペレーティングシステムはスレッド制御情報を記録し、スレッドは CPU タイムスライスを取得した後にのみ実行できますが、このとき、CPU 内のスタックポインタ、命令ポインタ、その他のレジスタを対応するスレッドに切り替える必要があります。
スレッドが複数の実行本体を作成し、それらに独自の実行エントリを割り当て、実行スタックとして使用するためにメモリを適用する場合、スレッドは必要に応じてこれらの実行本体をスケジュールできます。 , スレッドはまた、制御情報 (ID、スタックの場所、実行エントリのアドレス、実行サイト) を記録する必要があります。スレッドは、実行する実行本体を選択できます。このとき、CPU 内の命令ポインタは、その実行エントリを指します。実行本体とスタック ベース また、スタック ポインタ レジスタは、スレッドによって割り当てられた実行スタックも指します。
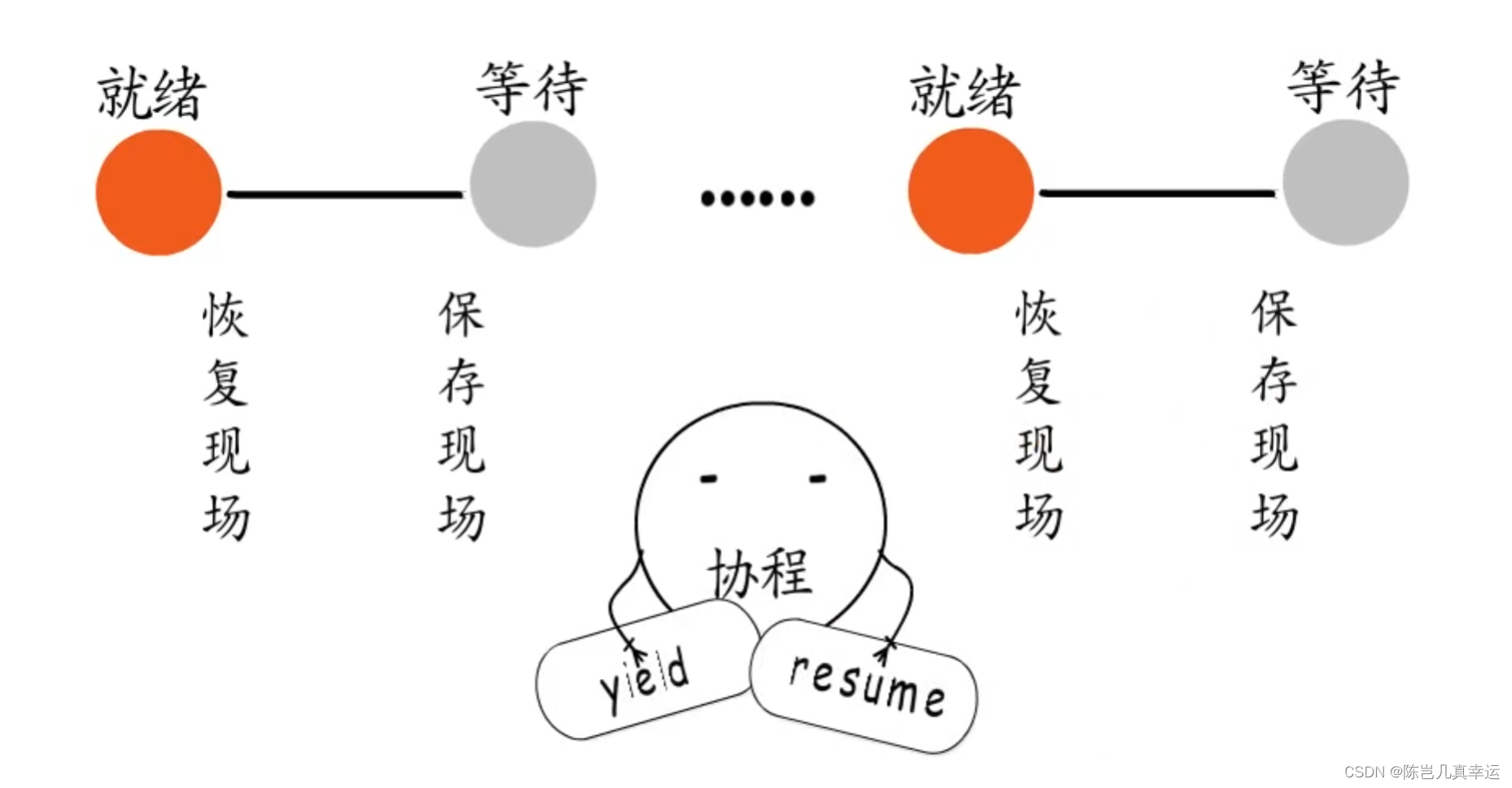
実行体を切り替える場合は、現在の実行体の実行サイトを保存してから別の実行体に切り替える必要がありますが、同様に以前の実行体に戻すこともできるので、継続して実行することができます。前回中断した場所から実行します。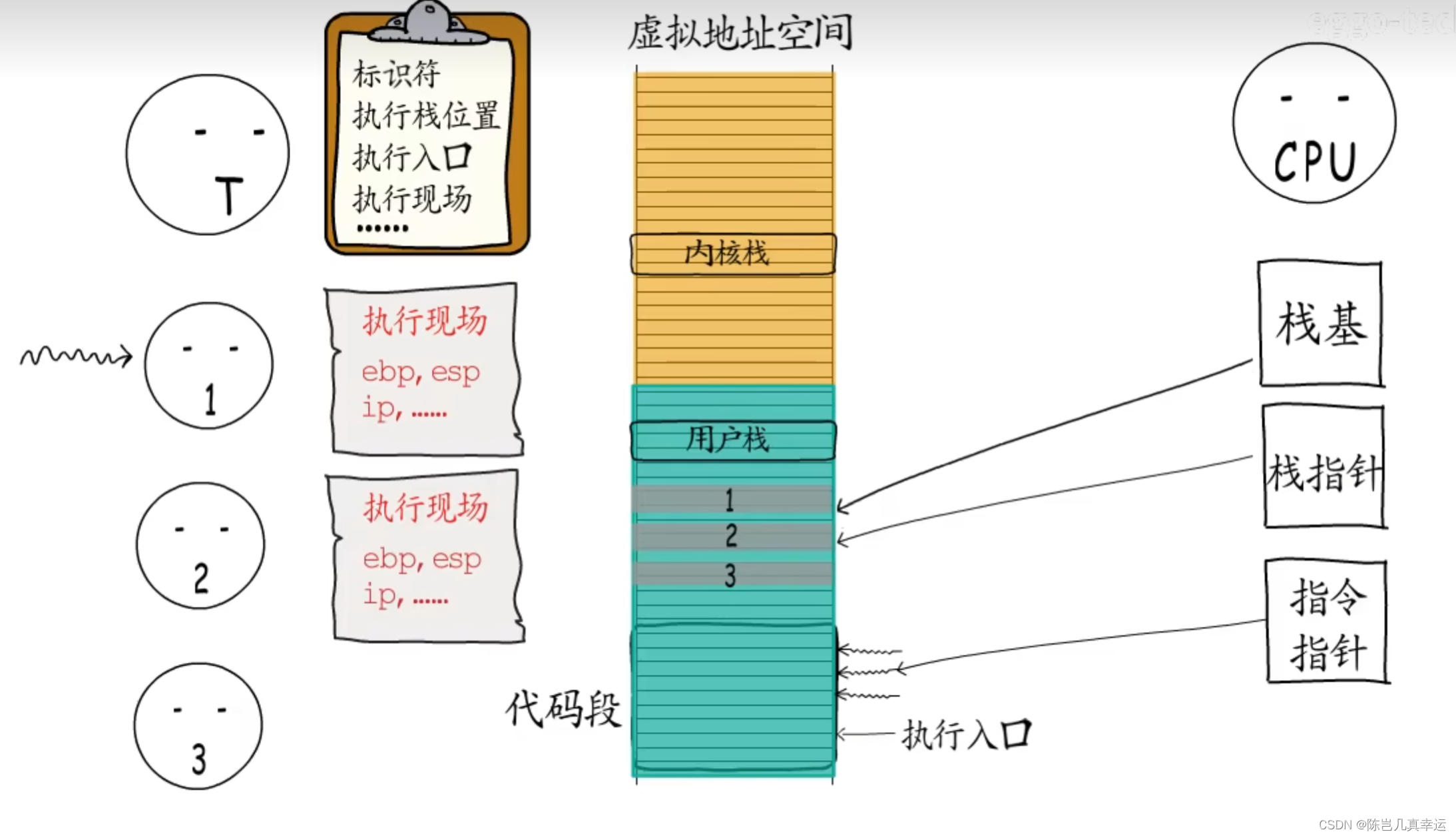
スレッドによって作成されるこれらの実行本体は、コルーチンです。ユーザー プログラムはカーネル空間を操作できず、ユーザー スタックをコルーチンに割り当てることしかできず、オペレーティング システムはコルーチンについて何も知らないため、コルーチンはユーザー モード スレッドとも呼ばれます。
コルーチン作成時に実行エントリを指定し、最下位層でコルーチンの実行スタックと制御情報を割り当て、ユーザーモードのスケジューリングを実現します。実行権を放棄する場合は、実行サイトも保存する必要があります。割り込みから実行を再開します。コルーチンのアイデアの鍵は、制御フローの積極的な放棄と回復です。
各コルーチンには独自の実行スタックがあり、独自の実行シーンを保存できます。コルーチンはユーザープログラムが必要に応じて作成することができ、コルーチンが自ら実行権を放棄した場合には、実行場所が保存され、他のコルーチンに切り替わります。コルーチンが実行を再開すると、実行前の状態に戻ります。このようにして、ユーザー モード柔軟なで軽量スケジュールされたによって。
プロセス、スレッド、コルーチンの違いと関係
IO多重化におけるコルーチン
オペレーティング システムによって記録されたプロセス制御情報、オープン ファイル記述子テーブル、プロセスによってオープンされたファイル、作成されたソケットなどがすべてこのテーブルに含まれます。すべてのソケット操作はオペレーティング システムによって提供され、システム コールを通じて完了します。ソケットが作成されるたびに、対応するオープン ファイル記述子テーブルにレコードが追加され、異なるソケットを識別するために 1 つのソケット記述子だけがアプリケーションに返されます。
各 TCP ソケットが作成されると、オペレーティング システムはそれを読み取りバッファおよび書き込みバッファと照合します。応答データを取得するには、受信したデータをカーネルの読み取りバッファからユーザー空間にコピーする必要があります。同様の作業を行う必要があります。ソケットを介して送信するデータも、最初に書き込みバッファに配置する必要があります。
質問: ユーザー プログラムがデータを受信したい場合、読み取りバッファにデータがあるとは限りません。また、データ送信の場合、書き込みバッファに空きがあるとは限りません。
①: ブロッキング IO: CPU を待機キューに入れ、ソケットが再度タイム スライスを取得する準備ができるまで待機してから実行を続行します。ソケットの処理にはスレッドが占有されます。
②:ノンブロッキングIO:CPUを放棄する必要はないが、ソケットの準備ができているかを頻繁に確認する必要があるビジー待機方式であるため、ポーリング間隔の把握が難しく、CPU空きが発生しやすい消費し、応答遅延が増加します。
③: IO 多重化: オペレーティング システムがサポートを提供し、待機する必要があるソケットを監視セットに追加します。これにより、システム コールを通じて複数のソケットを同時に監視でき、ソケットが遅延したときにソケットを 1 つずつ処理できます。ソケットを待ってブロックしてもビジー待機にはなりません。
select:読み取り可能、書き込み可能、異常の 3 種類のイベントをサポートします。
監視するディスクリプタを設定でき、待機時間も設定可能で、準備完了のfdがあるか待機時間を超えるとselectが戻り、最大1024個まで監視可能(fs_Setはunsigned long型のデータ)、16 要素)、
イベントの準備完了またはタイムアウトを待機: select が呼び出されるたびに、すべてのリスナー コレクションを渡す必要があり、データをユーザー モードからカーネル モードに頻繁にコピーする必要があります。
すべてのコレクションを走査する必要があるたびに、どの fd が準備ができているかを判断します。
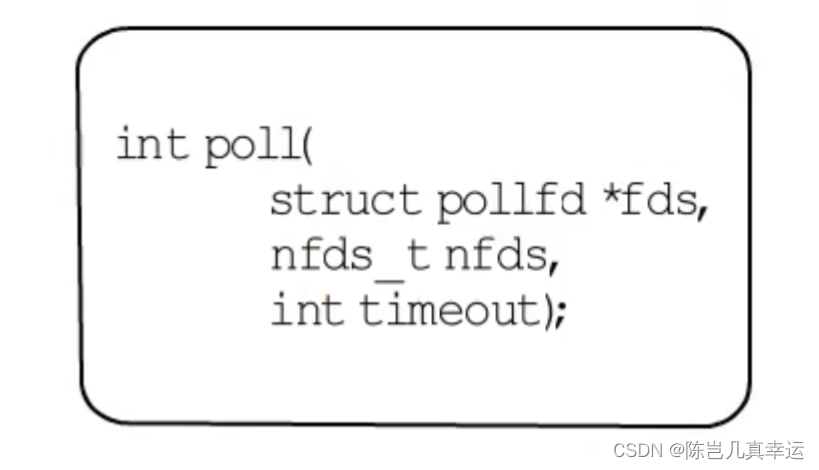
poll: select と比較して、ファイル記述子の数に制限はなく、fd の数は開いているファイル記述子の最大数と同じです。
ただし、ポーリングが呼び出されるたびに、ポーリングをユーザー状態からカーネル状態にコピーする必要があり、準備が整った fd を見つけるためにセットが走査されます。
epoll:そのような問題はありません
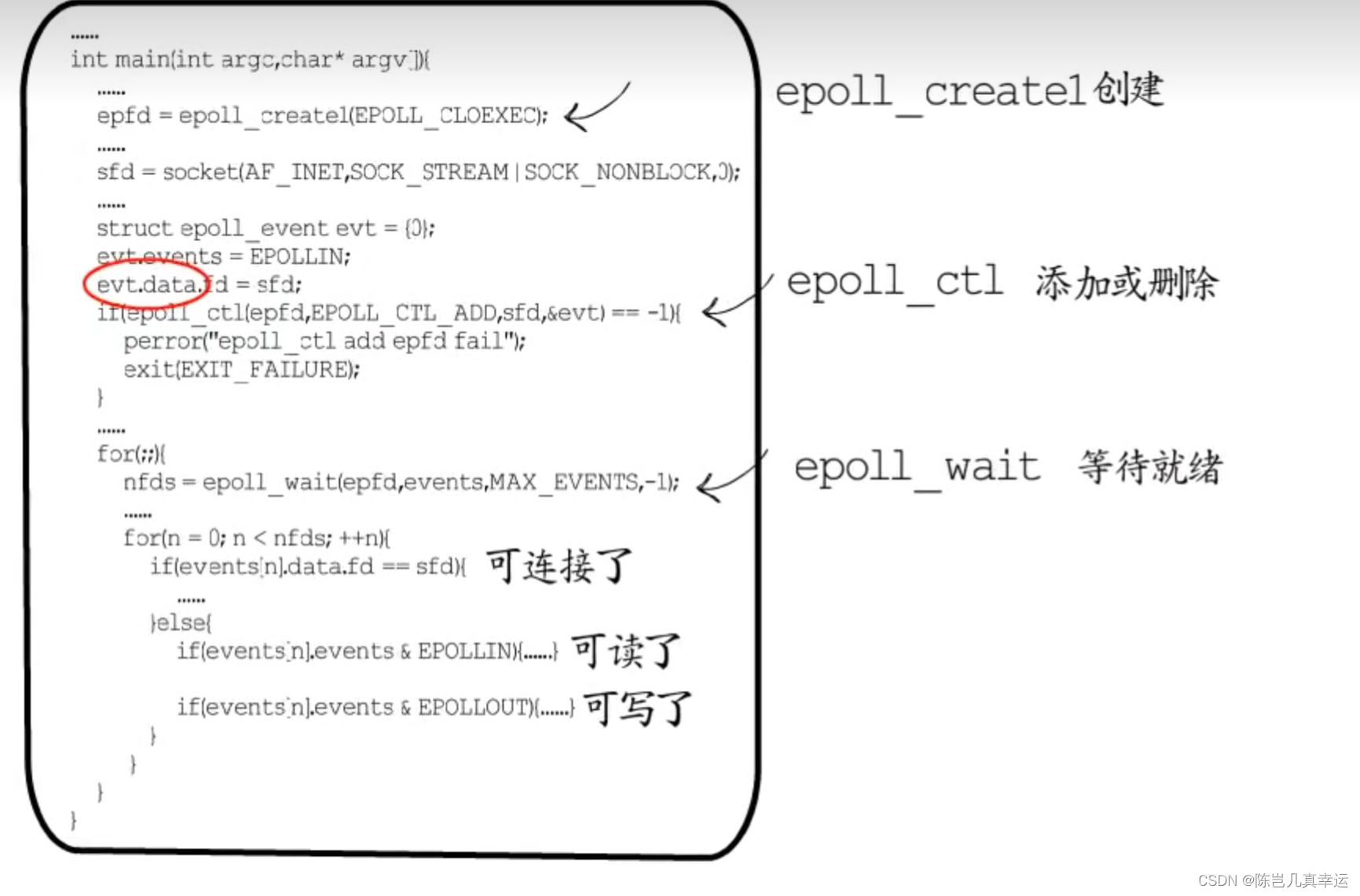
epoll_create: epoll を作成してハンドルを取得し、fd_events を保存するホワイトボードを作成します。
epoll_ctl : カーネルへの新規ディスクリプタの登録やファイルディスクリプタの状態変更に使用される fd に対応するイベント情報を追加または削除します。登録された記述子は、カーネル内の赤黒ツリーに維持されます。
fd と監視するイベントのタイプ (EPOLLIN、EPOLLOUT など) を指定することに加えて、event_data を渡すこともできます。対応する fd を処理するために必要なデータ構造を定義し、1 つの fd を渡すだけで済みます。すべての Listen コレクションを渡すことなく、毎回操作する必要があり、登録する必要があるのは 1 回だけです。
epoll_wait: この関数を通じて取得された fd は準備ができており、監視コレクションをトラバースする必要はありません。カーネルは、コールバック関数を通じて管理のためにI/O 準備完了記述子をリンクリストに追加します。

2 つのトリガー モード:
LT: 水平トリガー
epoll_wait() が記述子イベントの到着を検出すると、このイベントのプロセスに通知します。プロセスはイベントをすぐに処理する必要はなく、次の epoll_wait() 呼び出しで通知されます。プロセスをもう一度。これはデフォルトのモードであり、ブロッキングと非ブロッキングの両方をサポートします。
ET:
エッジ トリガー パターンと LT パターンの違いは、プロセスが通知の直後にイベントを処理する必要があることです。
次回 epoll_wait() を呼び出すとき、イベントの到着は通知されません。epoll イベントが繰り返しトリガーされる回数が大幅に減少するため、効率は LT モードよりも高くなります。ファイル ハンドルの読み取り/書き込み操作のブロック化による複数のファイル記述子の処理タスクの枯渇を避けるために、非ブロック化のみがサポートされています。ET モードでは、プロセスが時間内に処理されなかった場合、次回ファイル記述子でイベントが発生したときにのみイベントが通知されます。
質問:ソケットが読み取り可能であるが、リクエストの半分しか読み取られていない場合、つまり、ソケットが再び読み取り可能になるまで待機する必要があり、次のソケットの処理を続行する前に、次のソケットを記録する必要があります。ソケットの処理状況を読み込む際には、最後に保存したシーンも復元する必要があります。つまり、IO 多重化でビジネス ロジックを実装する場合、イベントが待機して準備が完了したら、シーンを保存して復元する必要があります。 コルーチンでの使用に適しています
コルーチンでの使用に適しています
IO多重化ではイベントループが依然として存在し、ループ内でready fdを1つずつ処理する必要がありますが、その処理プロセスは特定のサービスに焦点を当てたものではなく、コルーチンスケジューリングを指向しています。
ポートの監視に使用される fd の準備ができている場合は、新しい fd を作成するための接続を確立し、それを処理のためにコルーチンに渡します。コルーチンの実行エントリは業務処理関数のエントリを指し、IO イベントは実行時に登録されます。業務処理プロセス中に待機する必要があり、その後諦めるため、コルーチンが実行を継続する場所に実行権が切り替わります。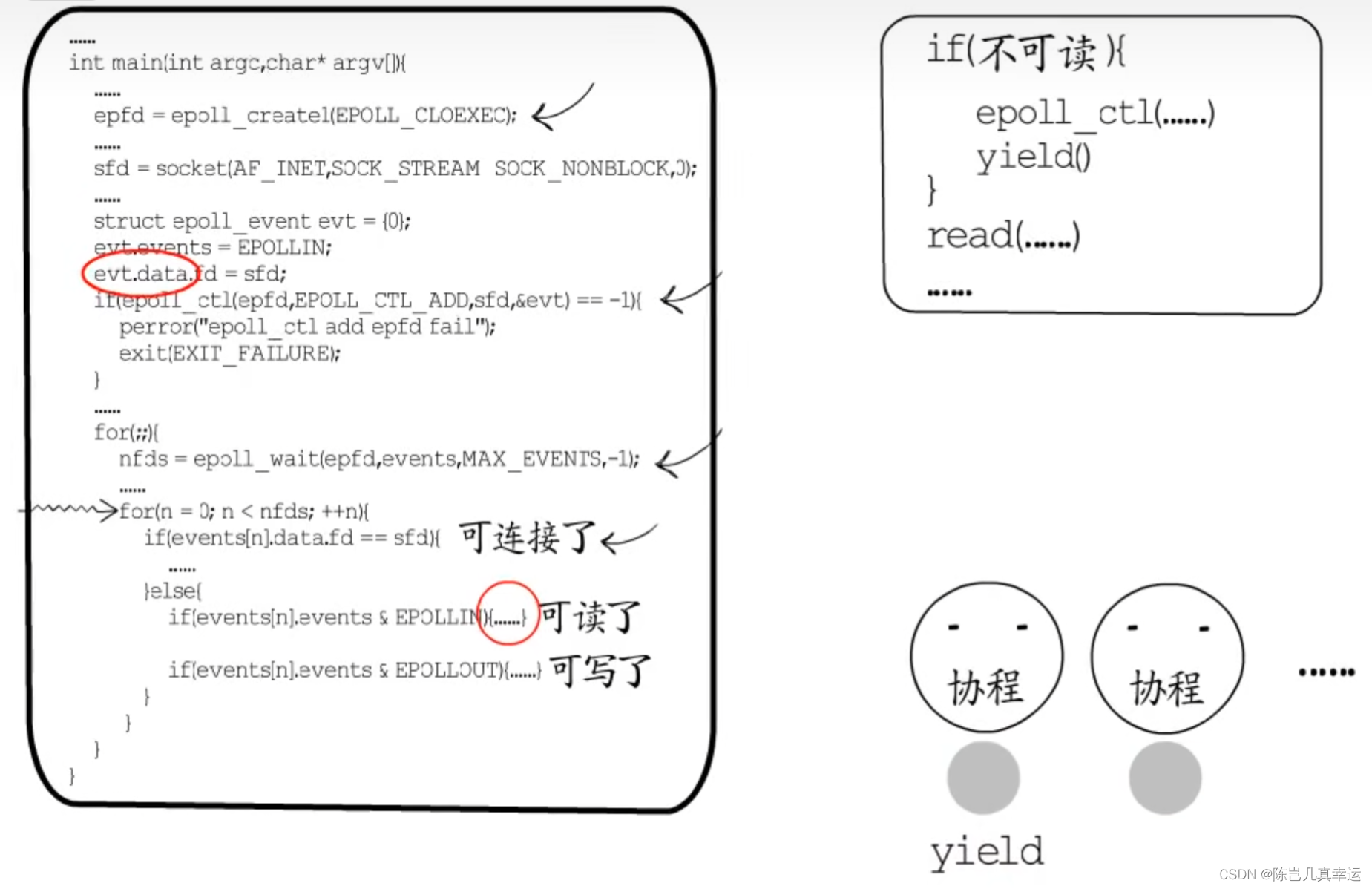
IO イベントを待っている他の fds の準備ができている場合は、関連するコルーチンを復元するだけで済みます。コルーチンには独自のスタックがあり、シーンの保存と復元が簡単です。
IO多重化層のイベントループは、特定のビジネスロジックから切り離されており、res、write、connectなどの待機が必要な関数をラップし、IOイベントの登録やアクティブな放棄を実現できます。これにより、これらのラッパー関数をビジネス ロジック レベルで使用して、従来の順序でビジネス ロジックを実装できるようになります。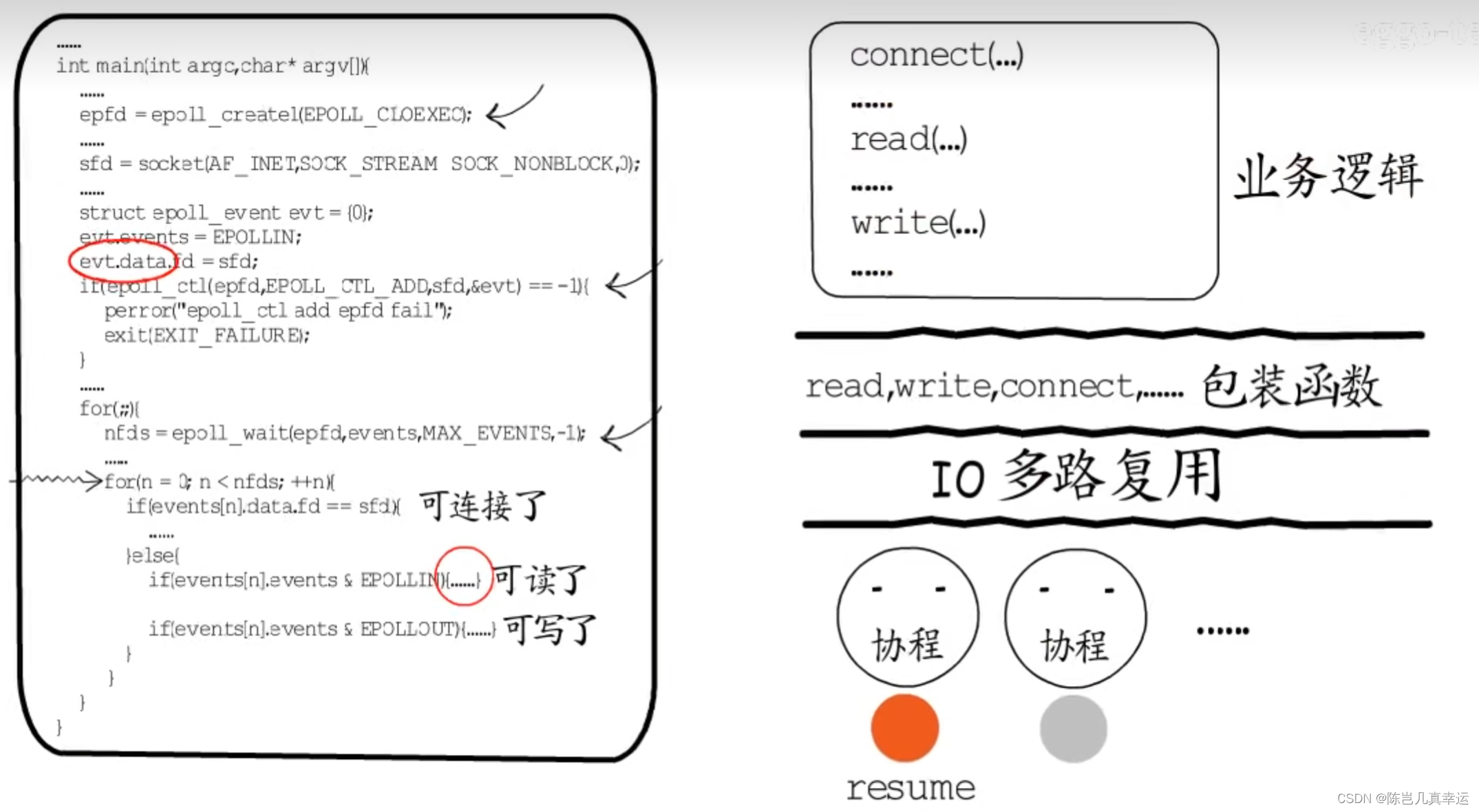
このラッパー関数は、待機する必要があるときに IO イベントを登録し、その後コルーチンを放棄するため、ビジネス ロジックを実装するときにシーンの保存と復元を気にする必要がなくなります。コルーチンと IO 多重化の組み合わせにより、IO が節約されます。多重化による高い同時実行パフォーマンスにより、ビジネス ロジックの実装も自由になります。
コルーチンの目的:
コルーチンは主に非同期ロジックを記述するために使用されます。コルーチンが存在する前に、非同期で同時実行を行いたい場合は、複数のスレッドを開くか、関数コールバックのノンブロッキング コードを記述する必要があります。
コルーチンの利点: 
 コルーチン切り替えのオーバーヘッドはスレッドのオーバーヘッドの 100 分の 1 であり、コルーチンは単一スレッド上で同時タスクを簡単に実装できます。
コルーチン切り替えのオーバーヘッドはスレッドのオーバーヘッドの 100 分の 1 であり、コルーチンは単一スレッド上で同時タスクを簡単に実装できます。