森の中で二股に分かれた道のうち、あまり人が通らない方を選んだのですが、それ以来すべてが変わりました。
--- ロバート・フロスト
目次
1. デシジョン ツリーの概要
1.1 関連概念
1.2 グラフィック表現
1.3 ルール表現
2. デシジョン ツリー情報の計算
3. ID3 関連の概要
3.1 ID3 アルゴリズムの概要
3.2 アルゴリズム プロセス
4. Matlab の実装
4.1 データセット
4.5 コードの実装
1. デシジョンツリーの概要
1.1 関連概念
決定木とは何ですか? デシジョン ツリーは、その名前が示すように、意思決定を行うために当然使用されます。
どのように決定を下すか? ロジックをツリー形式で表す意思決定プロセス。木である以上、枝があるはずで、枝の分岐は、どの枝に進むかを判断するための一種の区切りを表します。デシジョン ツリーは次の部分で構成されます。
(1) ルートノード: 決定木の開始点です。
(2) 分岐点: 内部ノードに属し、いわゆる分岐は特定の特徴または属性を選択することです。
(3) 内部ノード: ルート ノードと分岐点を含み、通常はほとんどのサンプルが取得されます。
(4) リーフノード: 従属変数分類のラベルを決定する決定木の終点です。
1.2 グラフィック表現
デシジョン ツリーのグラフィック表現は次のとおりです。
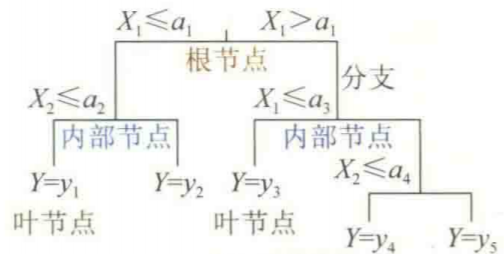
1.3 ルールの表現
決定木のルールは次のように表されます。
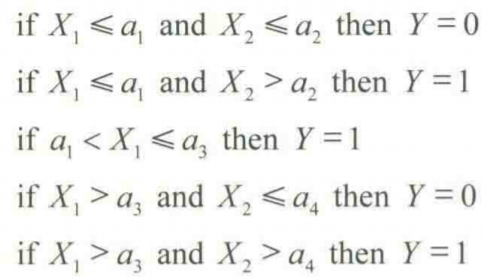
2. 決定木の情報計算
私たちはなぜ情報コンピューティングを行うのでしょうか? これは決定木の枝を選択するものですが、分岐を行うためには特性変数の情報を計算し、情報利得が最も大きい特性変数を決定木の枝として選択する必要があります。
情報計算はどうやって行うのですか?まず、次の概念を紹介します。
(1) エントロピー: 分岐しているため、エントロピーは分岐の無秩序に相当し、分岐はより無秩序を軽減し、情報利得が大きいものを見つけることになります。例えば、コインを投げたい場合、表と裏が出る確率は1/2ですが、このとき誰かがコインは表でなければならないと言えば、このときのエントロピーは0、つまりランダム性です。は0です。計算式は次のとおりです。
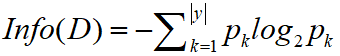
システムがより秩序正しくなればなるほど、情報エントロピーは低くなり、逆に、システムがより混沌とすると、情報エントロピーは高くなる。したがって、情報エントロピーはシステムの秩序度の尺度であると言えます。
(2) 情報ゲイン:情報によって生み出される価値であり、例えば上記のコインの例では、情報ゲイン=1-0=1の場合、計算式は次のようになります。
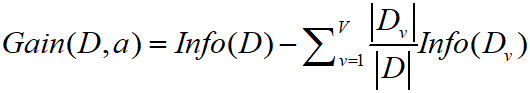
情報利得は特定の属性に対するもので、データセット D を分割する属性を選択し、分割後の 2 つのセットの純度を計算し、2 つのセットのエントロピーの加重平均を計算します。エントロピーと比較して、後者から前者を減算して、サンプル集合 D をこの属性で除算して得られる情報利得を求めます。
3. ID3 の概要
3.1 ID3アルゴリズムの概要
ID3 は、反復バイナリ ツリーの第 3 世代であり、実際には決定木の構築に使用される貪欲アルゴリズムです。ID3 アルゴリズムは概念学習システム (CLS) に由来しており、各ノードではまだ使用されておらず、最も高い情報利得を持つ特徴量を分割基準として分割し、決定木が完全に完了するまでこのプロセスを継続します。サンプルに対する分類トレーニング。
3.2 アルゴリズム処理
入力: サンプル セット S、属性セット A
出力: ID3 デシジョン ツリー。
(1) 全種類の属性を処理した場合はリターン、そうでない場合は 2) を実行
(2) 情報利得の最大属性 a を計算し、この属性をノードとして使用します。サンプルが属性 a によってのみ分類できる場合は戻り、そうでない場合は 3) を実行します。
(3) 属性 a の可能な値 v ごとに、次の操作を実行します。
i. 属性 a の値が v であるすべてのサンプルを S のサブセット Sv として取得します。
ii. 属性セット AT=A-{a} を生成します。
iii. サンプルセット Sv と属性セット AT を入力として使用して、ID3 アルゴリズムを再帰的に実行します。
4. Matlab の実装
4.1 データセット
データ セットは UCI データ セット内のマッシュルーム データを選択し、スタイルは次のとおりです。
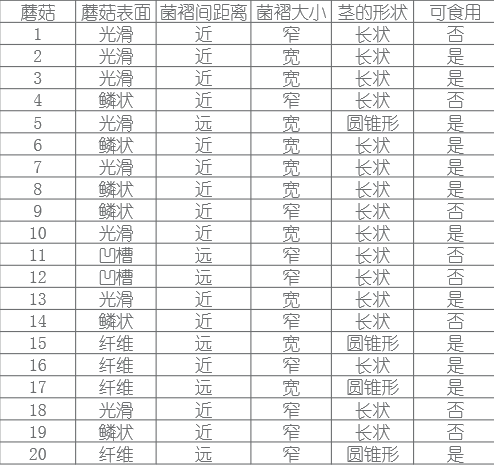
データセットのダウンロード アドレス: https://archive.ics.uci.edu/ml/datasets/Mushroom
4.5 コードの実装
%样本集的熵
sum=20;yes=12;no=8;
Entropy_S=-(yes/sum)*log2(yes/sum)-(no/sum)*log2(no/sum);
%disp(['样本集S的熵:',num2str(Entropy_S)])
%蘑菇表面状况
sum_s=8;yes=6;no=2;%蘑菇表面光滑
Entropy_s=-(yes/sum_s)*log2(yes/sum_s)-(no/sum_s)*log2(no/sum_s);
%disp(['蘑菇表面光滑的熵:',num2str(Entropy_s)])
sum_y=6;yes=2;no=4;%蘑菇表面鳞状
Entropy_y=-(yes/sum_y)*log2(yes/sum_y)-(no/sum_y)*log2(no/sum_y);
%disp(['蘑菇表面鳞状的熵:',num2str(Entropy_y)])
sum_g=2;yes=0;no=2;%蘑菇表面凹槽
Entropy_g=-0-(no/sum_g)*log2(no/sum_g);
%disp(['蘑菇表面鳞状的凹槽:',num2str(Entropy_g)])
sum_f=4;yes=4;no=0;%蘑菇表面纤维
Entropy_f=-(yes/sum_f)*log2(yes/sum_f)-0;
%disp(['蘑菇表面纤维的熵:',num2str(Entropy_f)])
Gain_surface=Entropy_S-(sum_s/sum)*Entropy_s-(sum_y/sum)*Entropy_y-(sum_g/sum)*Entropy_g-(sum_f/sum)*Entropy_f;
disp(['蘑菇表面状况的信息增益:',num2str(Gain_surface)])
%菌褶间距
sum_d=6;yes=4;no=2;%菌褶间距远
Entropy_d=-(yes/sum_d)*log2(yes/sum_d)-(no/sum_d)*log2(no/sum_d);
sum_c=14;yes=8;no=6;%菌褶间距近
Entropy_c=-(yes/sum_c)*log2(yes/sum_c)-(no/sum_c)*log2(no/sum_c);
Gain_gillsize=Entropy_S-(sum_d/sum)*Entropy_d-(sum_c/sum)*Entropy_c;
disp(['菌褶间距的信息增益:',num2str(Gain_gillsize)])
%菌褶大小
sum_b=10;yes=10;no=0;%
Entropy_b=-(yes/sum_b)*log2(yes/sum_b)-0;
sum_n=10;yes=2;no=8;%
Entropy_n=-(yes/sum_n)*log2(yes/sum_n)-(no/sum_n)*log2(no/sum_n);
Gain_gillsize=Entropy_S-(sum_b/sum)*Entropy_b-(sum_n/sum)*Entropy_n;
disp(['菌褶大小的信息增益:',num2str(Gain_gillsize)])
%茎的形状
sum_t=4;yes=4;no=0;%
Entropy_t=-(yes/sum_t)*log2(yes/sum_t)-0;
sum_e=16;yes=8;no=8;%
Entropy_e=-(yes/sum_e)*log2(yes/sum_e)-(no/sum_e)*log2(no/sum_e);
Gain_gillsize=Entropy_S-(sum_t/sum)*Entropy_t-(sum_e/sum)*Entropy_e;
disp(['茎的形状的信息增益:',num2str(Gain_gillsize)])
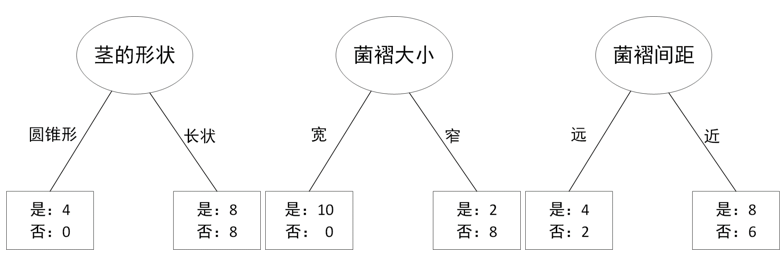
disp('-------判断第二个分支属性------------')
%% 判断第二个分支属性
%在分类时,分支属性菌褶代大小为宽时,蘑菇均为可食用,所以以菌褶大小窄继续划分
%样本集菌褶大小窄的信息熵
sum=10;yes=2;no=8;
Entropy_S=-(yes/sum)*log2(yes/sum)-(no/sum)*log2(no/sum);
disp(['样本集菌褶大小窄的熵:',num2str(Entropy_S)])
%蘑菇表面状况
sum_s=2;yes=0;no=2;%蘑菇表面光滑
Entropy_s=0-(no/sum_s)*log2(no/sum_s);
sum_y=4;yes=0;no=4;%蘑菇表面鳞状
Entropy_y=0-(no/sum_y)*log2(no/sum_y);
sum_g=2;yes=0;no=2;%蘑菇表面凹槽
Entropy_g=0-(no/sum_g)*log2(no/sum_g);
sum_f=2;yes=2;no=0;%蘑菇表面纤维
Entropy_f=-(yes/sum_f)*log2(yes/sum_f)-0;
Gain_surface=Entropy_S-(sum_s/sum)*Entropy_s-(sum_y/sum)*Entropy_y-(sum_g/sum)*Entropy_g-(sum_f/sum)*Entropy_f;
disp(['蘑菇表面状况的信息增益:',num2str(Gain_surface)])
%菌褶间距
sum_d=3;yes=1;no=2;%菌褶间距远
Entropy_d=-(yes/sum_d)*log2(yes/sum_d)-(no/sum_d)*log2(no/sum_d);
sum_c=7;yes=1;no=6;%菌褶间距近
Entropy_c=-(yes/sum_c)*log2(yes/sum_c)-(no/sum_c)*log2(no/sum_c);
Gain_gillsize=Entropy_S-(sum_d/sum)*Entropy_d-(sum_c/sum)*Entropy_c;
disp(['菌褶间距的信息增益:',num2str(Gain_gillsize)])
%茎的形状
sum_t=1;yes=1;no=0;%菌褶间距远
Entropy_t=-(yes/sum_t)*log2(yes/sum_t)-0;
sum_e=9;yes=1;no=8;%菌褶间距近
Entropy_e=-(yes/sum_e)*log2(yes/sum_e)-(no/sum_e)*log2(no/sum_e);
Gain_gillsize=Entropy_S-(sum_t/sum)*Entropy_t-(sum_e/sum)*Entropy_e;
disp(['茎的形状的信息增益:',num2str(Gain_gillsize)])結果は次のとおりです。
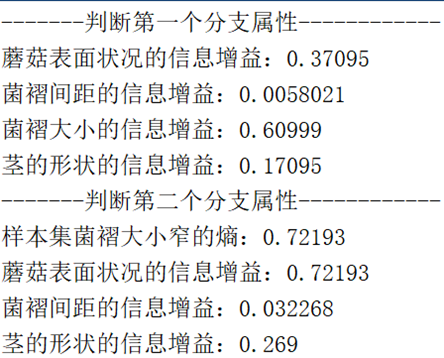
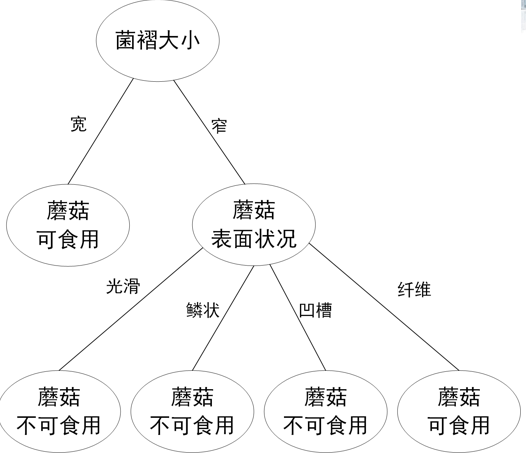
結果の決定木は次のようになります。