Visual Blocks for ML は、Google が開発したオープンソースのビジュアル プログラミング フレームワークです。使いやすいノーコード グラフィカル エディターで ML パイプラインを作成できます。
Visual Blocks for ML を実行するため。GPU が動作していることを確認する必要があります。残りはコードを複製して実行するだけです。以下に簡単に説明します。
Visual Blocks for ML は JavaScript をサポートする Web ブラウザ上で動作し、主に TensorFlow.js を使用するため、サーバーの GPU リソースではなくローカル GPU を使用するため、データはアップロードされず、データのプライバシーは保護されます。他のフレームワークではサポートされない可能性があります。
しかし、Visual Blocks for ML の最大の特徴は、何が起こったのかを視覚的な方法で段階的に説明することです。これにより、反復処理を迅速化し、最終的に結果をより迅速にリリースできるようになり、設計プロセスがスピードアップします。
この記事では、簡単に紹介する例として、ML セグメンテーション モデルを使用して既存の写真にステッカーと仮想背景を追加します。
公式デモ
1. 画像のセグメンテーション
公式デモはこちらです: https://visualblocks.withgoogle.com/#/demo、[デモ: 独自のデモを作成] タブをクリックします。
このページにアクセスするには、カメラの許可が必要な場合があります。
左側のコンポーネント ライブラリから画像をロードするには、[入力] をクリックしてプロジェクトの下部パネルにドラッグします。
プリロードされたストック画像を選択し、独自の写真をアップロードできます
ボディ セグメンテーション モデルの適用 - コンポーネント ライブラリからノードをドラッグする必要はありません。入力イメージ ノードの出力を表す小さな円をクリックしてドラッグし、利用可能な候補ノードのリストから選択または検索するだけです。
マスク ビジュアライザーの追加 - セグメンテーション モデルの出力を表示するには、マスク ビジュアライザー ノードをワークフローに追加する必要があります。上記のボディ セグメンテーション モデルの出力からドラッグし、推奨ノードであるマスク ビジュアライザを選択します。
これまで正しい手順に従った場合は、以下のスクリーンショットのようなものが表示されるはずです。

顔のランドマーク モデルを適用することで、私たちの目標は頭にステッカーを追加することなので、顔の領域を特定するためのモデルを作成する必要があります。顔のランドマーク モデルでは、ステッカーを正しい位置に配置できるように、「顔の上部」などのアンカー ポイントを定義できます。
最後に、仮想ステッカーを追加します。まず、左側のコンポーネント ライブラリから新しい入力イメージ ノードをドラッグする必要があります。ここでは電球のイメージを使用しました。ステッカーとして任意の画像を使用できますが、背景が透明であることを確認してください。
次に、顔ランドマーク出力から仮想ステッカーをドラッグして選択する必要があります。機能するには、さらに 2 つの入力、ステッカー イメージとマスク ビズアライザーが必要です。
最後に、「Scale」パラメータと「OffsetX/Y」パラメータを調整して位置を調整します。結果は次の図に示されています。

上の画像では、顔のマッピング結果を写真として表示できるLandmarkビジュアライザもビジュアライゼーションに使用しています。
前景を配置したら、イメージ ミキサーを使用して背景イメージを追加することもできます。
左側のコンポーネント ライブラリから新しい入力イメージ ノードを選択します。これはプリロードされた背景です。
次に、左側のコンポーネント ライブラリの [エフェクト] タブにある仮想ステッカー ノードをドラッグし、上で構成した最後のノードを新しい仮想ステッカー ノードの入力 Image1 に出力し、背景画像を入力 Image2 に接続します。ドロップダウン モードを「destination-over」に変更します。最終的な結果は次のとおりです。

このツールは、パイプラインを .js コードに変換するためのエクスポートまたは共有機能も備えているため、他のユーザーがワークフローをインポートして再作成できます。
上記では公式 Web サイトの DEMO を使用しましたが、Jupyter Notebook を使用してローカルで実行する方法を見てみましょう。
ジュピターノートブック
ここではデモンストレーションとして Colab を使用して、独自の環境で Visual Blocks を実行することもできます。
Visual ブロックに必要な Python ライブラリをインストールします。
!pip install visualblocks
Visual Blocks サーバーを起動します。
import visualblocks
server = visualblocks.Server()
次に、ビジュアル ブロック UI を開きます。
server.display()
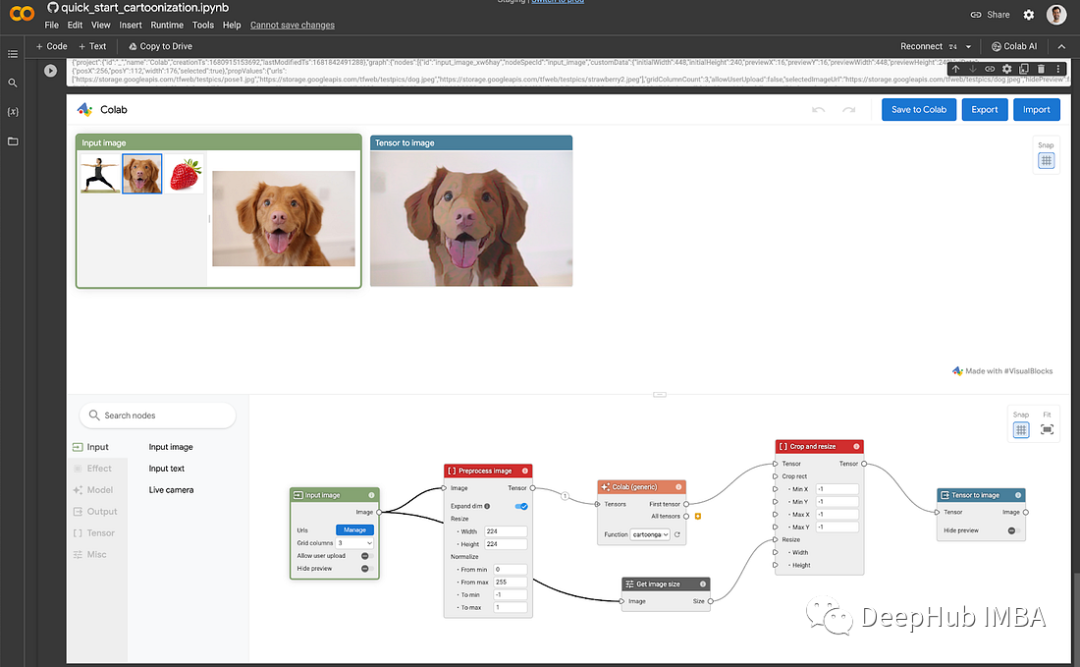
これで、ワークフローをローカルに作成できるようになりました。作成が完了したら、[Colab に保存] をクリックすると、今後の実行に備えてワークフローの .js が Jupyter Notebook に保存されます。
自分で試してみたい場合は、以下のファイルを使用できます。
https://avoid.overfit.cn/post/ed762d829e1d40d4968a1c4f24018663
要約する
個人的には、Google がオープンソース化した ML 用の Visual Blocks は、実用的なアプリケーションにはほとんど意味がないと感じています。これは単なる TensorFlow.js テクノロジーのデモンストレーションかもしれませんが、研究の方向性は非常に優れているはずです。たとえば、カメラの場合、ローカル特徴抽出はネットワーク凡例を必要とせずに実行されるため、帯域幅とサーバー リソースが節約され、ユーザーのプライバシーも保証されます。これがFederated Learningの方向性ではないでしょうか?興味があれば見てみると楽しいですよ。