記事ディレクトリ
マノリス・ケリス教授(MIT 計算生物学ディレクター)による「人工知能と機械学習」
この記事は、NLP の伏線であり、主にいくつかの伝統的な手法についての多くの基礎知識であり、最新の RNN、LSTM、BERT、Transformer、GPT などのモデルを深く理解するために必要であると言えます。
主にテキストの文法的および意味的関係、不確実性 (医療テキスト)、LDA トピック モデル、N グラム モデル、および単語埋め込み (エンベディング) について説明します。これにより、以前にモデルについてしか学ばなかったいくつかの混乱が解決されます。
最後に、大規模言語モデル (LLM) について大まかに説明し、いくつかの優れたビデオ リンクを提供しました (国立台湾大学の Honyi Li)。学習が終わったら、LLM について別のブログを書くつもりです。
このレッスンの概要

コース概要:
臨床テキストにおけるデータの価値
過度に単純化された言語学
用語の認識 + 否定性と不確実性への対処
機械学習を使用して用語を拡張する
エンティティと関係を識別するためのプレニューラル ネットワーク機械学習
言語モデル
共起に基づくベクトル空間埋め込み
曖昧さをなくすためにコンテキストを追加する
単語の埋め込みからフレーズ、文章などへ。
説明する:
- 臨床テキストにおけるデータの価値: このセクションでは、診断と治療の両方に重要な臨床医学テキストから貴重な情報を抽出する方法を検討します。
- 過度に単純化された言語学: このセクションでは言語学の基本をいくつか紹介します。これは非常に単純化されたバージョンですが、以下の内容を理解するのに役立ちます。
- 用語の認識 + 否定的および不確実性への対処: このパートでは、テキストから重要な用語を見つける方法を学び、また、医学文書を理解するための鍵となる否定および不確実性に対処するための戦略も学びます。
- 機械学習を使用した用語の拡張: このパートでは、機械学習手法を使用して特定された用語を拡張し、情報の完全性と正確性を高めます。
- エンティティと関係を識別するためのニューラル ネットワーク以前の機械学習: ニューラル ネットワーク モデル以前の機械学習手法は、テキスト内のエンティティとそれらの間の関係を識別するために使用されていました。
- 言語モデル: このセクションでは、テキストを理解して生成するための重要なツールである言語モデルの基本を紹介します。
- 共起に基づくベクトル空間埋め込み: このセクションでは、単語の共起情報を使用して、テキスト情報を表現する方法である単語ベクトルを構築する方法を紹介します。
- 曖昧さの解消に役立つコンテキストの追加: コンテキスト情報を追加すると、テキストの理解と曖昧さの解消に役立ち、テキストの理解の精度が向上します。
- 単語からフレーズ、文などへの埋め込みから: 単語ベクトルの概念が単語からフレーズ、文、さらには大きなテキスト単位まで拡張され、複雑なテキスト情報をよりよく理解して表現できるようになります。
極度に単純化された言語学
文法 + 構文 -> セマンティクス、この部分はより複雑で抽象的ですが、理解してください。

-
文法と構文に対する長年の関心: 私たちは文法と構文を長い間研究してきました。文法と構文は、文を構築し意味を伝える方法を決定する言語の基本構造です。
- 意味論: 意味論とは言語の意味レベルであり、単語や文が実際に何を意味するかを研究するものです。
-
文脈依存の生成ルールに基づいて定義された文法: 文法は、文脈に応じて変化する一連の生成ルールとして定義できます。
-
例えば
-
まず、プロダクション ルールとは何かを理解しましょう。コンピューター言語学では、言語の文法構造を記述するために生成規則が使用されます。通常は「X → Y」の形式で、X を Y に置き換えることができることを意味します。たとえば、「文 → 主語 + 述語」という生成ルールを持つことができます。これは、文が主語と述語で構成され得ることを意味します。
次に、コンテキスト依存の生成ルールとは何かを見てみましょう。この概念は、文脈依存文法から派生したものです。文脈依存文法では、生成ルールの形式は「X → Y」となり、X と Y は両方とも 1 つ以上のシンボルのシーケンスになります。これは、シンボルの置換が周囲のコンテキストに依存する可能性があることを意味します。たとえば、「she+eat+apple」の「eat」は、さまざまなコンテキストでさまざまな形式に置き換えることができます。たとえば、過去形のコンテキストでは「eat」に置き換えることができます。
最後に、変形(変形)とは、生成ルールに基づいて文章に何らかの変更を加える操作を指します。たとえば、受動態の文を能動態に変換したり、肯定的な文を否定的な文に変換したりする変換ルールを作成できます。
つまり、全体として、文脈に依存した生成規則と変換によって定義される文法は、言語の構造を記述する方法であり、さまざまな文脈におけるさまざまな単語の形式やさまざまな変換など、言語の複雑さを捉えることができます。文形式の。
-
変換: 文法には、ある文構造を別の文構造に変換する規則があります。
-
-
文脈自由文法 (文脈自由文法、CFG)、言語の構造を説明します。
-

-
文脈自由文法は、言語で文を生成する方法を記述する一連の生成ルール (生成ルール) で構成されます。ルールは通常 A → B の形式で、A を B に置き換えることができます。
-
コンテキストフリー文法では、各生成ルールは現在の非終端記号 (つまり A) のみを考慮し、非終端記号の周囲のコンテキストは考慮しません。それが「コンテキストフリー」と呼ばれる理由です。非終端記号は文、句などの文法構造の一部と見なすことができますが、終端記号は特定の単語または句読点です。
-
2 つのルールだけで構成される非常に単純な自然言語文法があるとします。
- 文 → 名詞句 + 動詞句
- 名詞句 → 冠詞 + 名詞
名詞 (「猫」や「犬」など)、動詞 (「走る」や「ジャンプ」など)、冠詞 (「a」や「that」など) もあります。
この文脈自由文法に従って、多くの規則的な文を生成することができます。たとえば、最初にルール 1 を使用して「名詞句 + 動詞句」を取得する文を生成し、次にルール 2 を使用して名詞句を置き換えて「冠詞 + 名詞 + 動詞句」を取得できます。最後に、非終端語を具体的な単語に置き換えて「猫が走る」を取得します。これは、定義した文脈自由文法に準拠した文です。
この例では、「名詞句」または「文」がどこに現れても、対応する置換ルールを適用できます。これらの非終端語の文脈を考慮する必要はありません。そのため、この文法は「文脈自由」と呼ばれます。 " 理由。
これは非常に単純化された例にすぎず、自然言語の実際の文法はさらに複雑で、多くの特殊なケースや例外があることに注意してください。
-
-
違い:
- 文脈自由文法: この文法の生成規則は「A → B」の形式で、A は非終端、B は非終端と終端のシーケンスです。このルールでは、現在の非終端 A のみが考慮され、文内での位置や周囲のコンテキストは考慮されません。つまり、A が出現する場合はどこでも、それを B に置き換えることができます。文脈自由文法は言語構造を記述する上で比較的単純ですが、一定の制限もあります。
- 文脈依存文法: この文法の生成規則は「ABC → AxB」の形式です。ここで、A、B、および C は非終端または終端であり、x は非終端と終端で構成されるシーケンスです。このルールでは、非終端 B の置換は、その周囲のコンテキスト A および C に依存します。つまり、周囲のコンテキストが A と C である場合にのみ、B を x に置き換えることができます。文脈依存文法は、言語構造をより柔軟に記述できますが、より複雑でもあります。
-
意味マッピング: 文の意味を理解できるように、文法規則を意味関数にマッピングできます。
-
終端記号は指示対象または機能です。文法では、終端記号は、文内で特定の意味を表すか機能を実行する実際の単語または句です。
-
環境は、(現代の用語では) セマンティック ネットワークの複雑な相互関係です。セマンティック分析では、環境は、一連のセマンティック要素 (単語や概念など) 間の関係のネットワークと見なすことができます。
-
意味は構成的であり、意味関数として表現されます。意味は単独で存在するのではなく、複数の部分から構成されます。これらの部分を組み合わせる方法がセマンティック機能です。
-
-
残された大きな問題: 「現実世界」の意味をどのように表現するか? これは自然言語処理の大きな課題の 1 つです。抽象的な意味表現を現実世界の言語にどのように適用するかです。
-
文法的関係: 単語の構成方法など、2 つのフレーズ間の構文的関係。このセクションでは、文法規則を使用して文の構造を解析する方法を説明します。
-
意味へのマッピング: フレーズの意味へのマッピング。このセクションでは、セマンティック マッピングを使用して文法構造を実際の意味に変換する方法を示します。
-
意味関係: 意味にマッピングした後、2 つの意味の間の意味関係を比較することです。このセクションでは、文の意味を理解し、文の各部分間の関係を見つける方法を示します。
-
用語のスポッティング + 否定、不確実性の処理
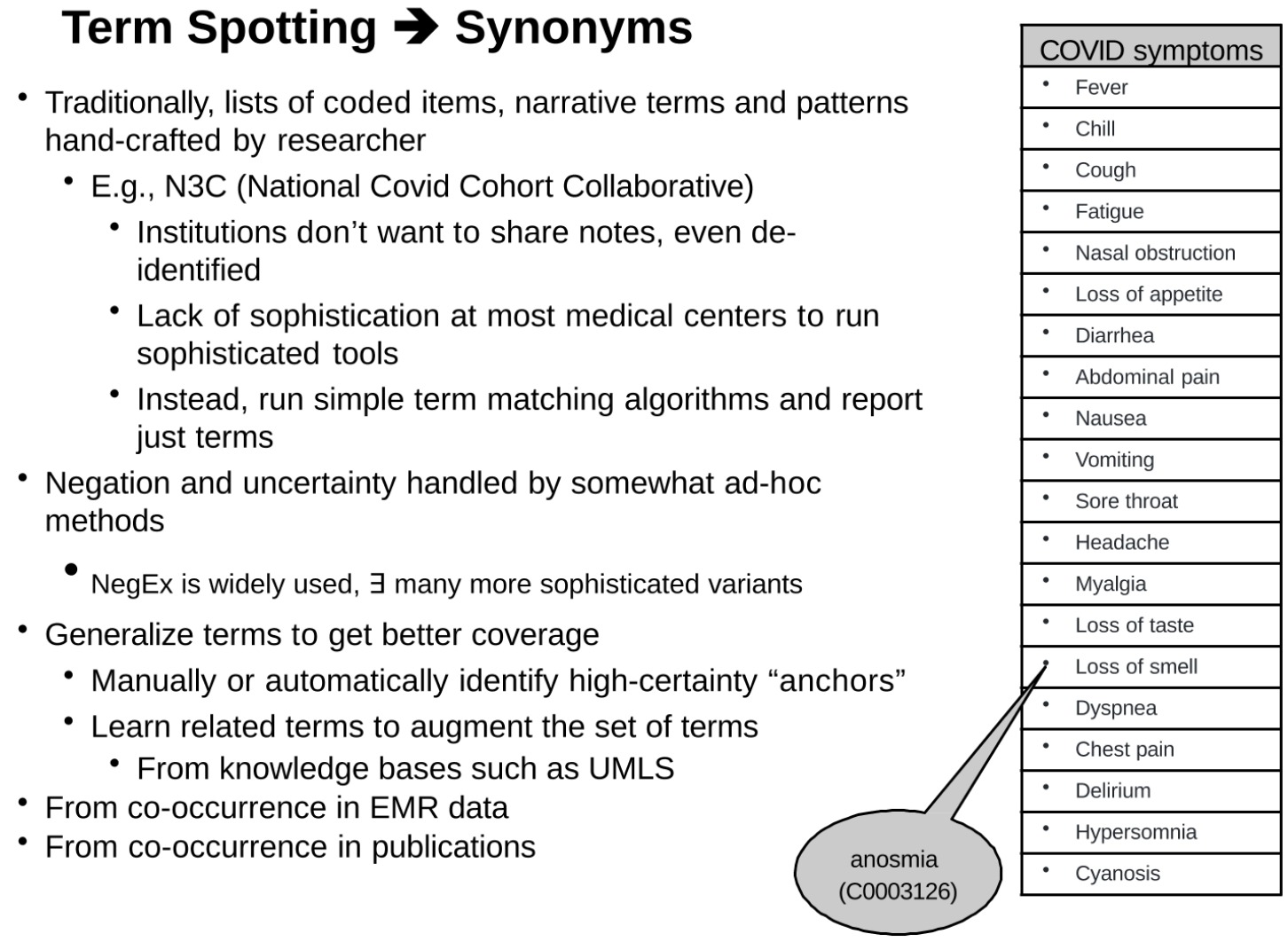
用語の認識、同義語の処理、否定と不確実性の処理を含む、臨床テキストにおける新型コロナウイルスの症状の検出と治療へのアプローチ
-
この一節は、用語の認識、同義語の処理、否定と不確実性の処理など、臨床テキストにおける 新型コロナウイルス の症状の検出と処理へのアプローチを説明しているようです。
-
従来、研究者はコード化された用語、物語用語、パターンのリストを手動で作成していました。
- 例:発熱、悪寒、咳、倦怠感、鼻づまり、食欲不振、下痢、腹痛、吐き気、嘔吐、喉の痛み、頭痛、筋肉痛、味覚障害、嗅覚障害、呼吸困難、胸痛、錯乱、眠気、チアノーゼ。
- たとえば、N3C (National Covid Cases Collaboration)
- 多くの政府機関は、たとえ匿名化された記録であっても、記録を共有することに消極的です。
- ほとんどの医療センターには、複雑なツールを実行するための高度な技術がありません。
- 代わりに、単純な用語マッチング アルゴリズムを実行し、用語だけをレポートします。
- これから生じる問題、つまり否定と不確実性は、比較的恣意的なアプローチを通じて扱われます。補題のみがあり、他の意味単語 (否定など) がないためです。
- NegEx は広く使用されており、さらに複雑な亜種が多数あります。
- 目標: 用語の一般化により、より適切な範囲をカバーします。
- 手動または自動による、確実性の高い「アンカー」の識別。
- 関連する用語を学習して用語セットを拡張します。
- UMLS などの知識ベースから得られます。
- EMR データの共起から派生。
- 出版された文献から出てきました。
この文章が強調しているのは、臨床テキストを理解するためには語彙の一致が重要であるが、多くの場合、これらの一致では同義語、否定、不確実性などのより多くの文脈情報を考慮する必要があるということです。これらの複雑な要因により、臨床テキストから有用な情報を抽出することがより困難になるだけでなく、より洗練された効果的なツールの必要性も生じます。

ここで簡単に説明します。
このパートでは、臨床テキストを処理する際に、否定的な単語 (否定) を処理する方法と否定的な表現 (NegEx) を認識する方法を紹介します。
まず、状態関連の否定を特定するには、人の臨床状態を説明するステートメントを特定し、そのステートメントがテキスト内で否定または反駁されているかどうかを判断することが含まれます。
次に、文に NegEx 否定語句が含まれるかどうか、および否定語が含まれるかどうかに基づいて、4 つの異なる比較実験セットが導入されます。これらの実験では、感度 (Sensitivity)、特異性 (Specificity)、陽性的中率 (陽性的中率、PPV)、および陰性的中率 (陰性的中率、NPV) を比較しました。
次に、この部分では、自然言語処理 (NLP) における否定の扱いの問題は通常複雑であるが、この場合、否定は主に病気、検査、薬、発見などを示す名詞句に適用されるため、問題は比較的簡単です。
実際には、退院概要の各文に出現するすべての UMLS (統一医療言語システム) 用語を探し、これらの用語の前に否定的な表現がないかどうかを確認します。例えば、「いいえ」、「否認する」、「否」、「なし」、「否認」、「除外」、「否認」等の表現があった場合、これらの表現は否定表現として認識されます。
さらに、「グラム陰性」、「これ以上は無理」、「ありえない」、「かどうかは不明」、「かどうかは不明」、「必ずしも」、「規則ではない」など、認識を誤らせる可能性のある単語やフレーズもあります。 「out」、「これ以上は」、「困難なく」、「これ以上は」など、ネガティブな言葉が含まれていますが、文脈上ネガティブな意味ではないので、特に注意が必要です。
このセクションは、退院サマリーで陰性所見と疾患を特定するための単純なアルゴリズムに関する論文への参照で終わります。このアルゴリズムは、上で提示された内容の出典と根拠を示しています。
ML による用語の拡張
何十年もの間、人々はこれらの意味的に関連する作業に多くの時間を費やし、フレーズ間の階層構造を確立してきました。統一医療言語システム (Unified Medical Language Systems、UMLS) など。これらは NLP の基本です

UMLS の中核となる部分はメタテサウルスです。2022 年の ab バージョンまでに、メタテサウルスにはすでに 182 個の原語が含まれています (オリジナルには 215 個ありましたが、古いものは削除されました)。これらのソース単語には、Medical Subject Headings (MeSH)、SNOMED、ICD-9、ICD-10、LOINC、RXNORM、NCI、CPT、GO、DXPLAIN、OMIM などが含まれます。
メタシソーラスは、語彙全体にわたる同義語のマッピングを提供します。たとえば、「心臓発作」と「急性心筋梗塞」および「心筋梗塞」は同義語です。
メタテサウルスには 4,662,313 個の固有の概念が含まれており、それぞれは固有の概念識別子 (CUI) で表されます。メタテサウルスは本質的に、各ソースから抽出されたすべての階層をハイブリッドに編集したものです。
また、同義語の使用に加えて、同義語やその他の関連単語など、他の関連語彙も利用できます。たとえば、病気の一般的な症状や治療法などです。これも再帰的な機械学習の問題です。つまり、用語に関連するケースを最もよく識別する方法を学習すること、つまり表現型解析として知られるプロセスです。
最後に、「Anchor & Learn」のような方法では、医療記録から二次用語を学習します。

医学書の用語、特に頭字語には多くの課題があります。まず、多くの頭字語があいまいなため、理解と解釈が非常に複雑になります。たとえば、MAC は「最小肺胞麻酔薬濃度」を表し、PCA は「凝固促進活性」を表し、CML は「カルボキシメチルリジン」を表し、IPA は「n-6-(デルタ-2-イソペンテニル) アデニン」を表します。 。頭字語にはいくつかの異なる意味があり、文脈によって解釈が異なります。
このセクションの調査によると、 Medline (Pubmed) 抄録に含まれる3 文字の頭字語の 81.2% があいまいで、平均 16.6 個の意味があります。まれな (出現頻度が 5 回未満) 意味を無視した場合、頭字語の 64.6% が依然としてあいまいで、平均 4.91 の意味があります。これは「ロングテール」分布を示しており、ほとんどの頭字語には少数の一般的な意味がありますが、多数の珍しい意味を持つ頭字語も多数存在します。
さらに、出現回数が 100 を超える頭字語の 82.8% が UMLS (統一医療言語システム) で見つかりますが、UMLS で見つかるのは全頭字語の 23.5% のみです。これは、既存の医学用語リソースがすべての医学用語、特にまれな用語や分野固有の用語を網羅しているわけではないことを示しています。
これらの問題に対処するために、機械学習を使用して用語を拡張できます。これには、ヒューリスティックを使用してテキスト内の医療概念を識別し、UMLS 内の関連概念にリンクする MetaMap と呼ばれるツールの使用が含まれる場合があります。機械学習手法を通じて、用語の文脈上の意味をより深く理解できるようになり、それによって曖昧さが軽減され、新しい用語や意味が発見される可能性があります。
エンティティと関係を識別するための NN 以前の ML

特徴ベースのモデルを構築する場合、テキストからさまざまな特徴を抽出できます。これらの特性には次のようなものがあります。
- 単語: テキスト内の個々の単語。
- 品詞: 名詞、動詞、形容詞などの各単語の文法カテゴリ。
- 格: 単語の格。固有名詞または文の先頭を識別する際に重要となる場合があります。
- 句読点: カンマ、ピリオドなどのテキスト内の句読点。
- 文書の章: 段落や見出しなどのテキストの構造情報。
- 従来の文書構造: 要約、導入、方法、結果、考察などのセクションの存在と順序。
- 認識されたパターンと辞書用語: テキスト内で認識される事前定義されたパターンと辞書用語。
- 語彙コンテキスト: ターゲット単語の周囲の単語とそのプロパティ。
- 文法的コンテキスト: 対象の単語に文法的に関連する単語とそのプロパティ。
たとえば、「昨日から始まった lasix、腹水の減少。」という文では、「lasix」と「腹水」はどちらも名詞で、「開始」と「減少」はどちらも過去形の動詞で、「昨日」は副詞です。この情報を使用して、医療文書の理解と解析に役立つ、より複雑な特徴モデルを構築できます。
潜在ディリクレ配分 (LDA)
より現代的なアプローチは LDA と呼ばれます

潜在ディリクレ割り当て (LDA、潜在ディリクレ割り当て) は、一般的に使用されるトピック モデリング手法です。その基本概念は次のとおりです。
-
各ドキュメントは複数のトピックの混合物である: LDA モデルでは、各ドキュメントが複数のトピックで構成されており、これらのトピックの割合は異なる可能性があると想定しています。たとえば、健康的な食事に関する記事は、「栄養」、「健康」、「食品」の 3 つのトピックで構成されているとします。
-
各トピックは単語の分布です。トピックが与えられると、それぞれの単語が出現する可能性が異なります。たとえば、「栄養」というトピックでは、「ビタミン」、「野菜」、「タンパク質」などの単語がよく使われる可能性があります。
-
各単語はトピックから抽出されます。ドキュメントでは、各単語はトピックの 1 つから抽出されます。抽出されたトピックは、文書トピックの比例配分に基づいて選択されます。
テキスト分析に LDA を適用する場合、通常、決定する必要があるパラメーターはトピックの数、つまり文書セット内で検出したいトピックの数です。LDA アルゴリズムは、各トピックの単語分布と各ドキュメントのトピック分布を自動的に検出します。

テキスト文書内の隠されたトピック構造を発見します。このモデルは、各ドキュメントが一連のトピックの混合から生成され、各トピックが単語の確率分布であると想定しています。
LDA の枠組みでは、各文書のトピック分布はディリクレ分布によって生成され、各トピックの単語分布もディリクレ分布によって生成されると仮定します。次に、ドキュメント内の単語ごとに、最初にドキュメントのトピック分布からトピックをサンプリングし、次にトピックの単語分布から単語をサンプリングします。このプロセスにより、文書内のすべての単語が生成されます。
このモデルでは、単語 (つまり、文書内の単語) のみを観察でき、トピックの分布、単語の分布、各単語のトピックの割り当てなど、他のすべてのものは隠されているため、推論アルゴリズム (ギブス サンプリングなど) を使用する必要があります。または変分推論) を使用して、これらの隠れた変数を推論します。
このグラフィカル モデルの記号の意味は次のとおりです。
- D: 文書の数。
- K: トピックの数。
- N: 各文書内の単語数。
- α、β: これらはディリクレ分布のパラメータであり、トピック分布と単語分布の形状を決定します。
- θ:各文書のトピック分布です。
- φ:トピックごとの単語分布です。
- z: これは各単語に対するトピックの割り当てです。
- w: これは観測された単語です。
このモデルの目標は、観察された単語を考慮して、すべての隠れた変数、つまりドキュメントごとのトピック分布、トピックごとの単語分布、単語ごとのトピック割り当てを推測することです。
W d , n W_{d,n}Wd 、 n特定の文書Z d , n Z_{d,n}で観察される n 番目の単語です。Zd 、 nは単語のトピック割り当てであり、N フレームは単語に属します。
そして、D フレームは文書レベル、θ θθは、この文書のトピック分布です (たとえば、この文書には、コンピューターに関する 20 のトピック、生物学に関する 60 のトピック、および神経科学に関する 20 のトピックがあります)。
ああαは、すべてのコーパスにわたって学習されるパラメータであり、文書の期待値 (事前確率) であり、文書内で特定のトピックがサンプリングされる確率を示します。
今度は左から右に見ていきます
1 つ目は事前確率Proportions パラメーターで、生成されるトピック分布の形状に影響します。そして、一旦決定されると、各文書のトピック分布を生成することができる。(この分布は、このドキュメントを生成するときに各トピックが選択される確率を表します。たとえば、ドキュメントのトピック分布が [0.1, 0.2, 0.7] の場合、このドキュメントを生成するときに最初のトピックが 0.1 であることを意味します。 、2 番目のトピックを選択する確率は 0.2、3 番目のトピックを選択する確率は 0.7 です。)
単語ごとのトピック割り当て (単語ごとのトピック割り当て) : 各単語を生成する前に、まず単語のトピックを決定する必要があります。これは、現在のドキュメントのトピック分布からサンプリングすることによって取得されます。たとえば、サンプリングしたトピックが 3 番目のトピックの場合、3 番目のトピックの単語分布から単語をサンプリングします。
観察された単語: 各単語のトピックを決定した後、単語を生成できます。これは、この単語のトピックの単語分布からサンプリングすることによって取得されます。この単語の分布は、単語を生成するときに各単語が選択される確率を表します。これで文書生成のプロセスが完了し、生成された単語が観察されます。
一般に、プロセスは文書のトピック分布を生成することから始まり、次に文書内の各単語について、最初にトピックを決定し、次に単語を生成します。これは階層的なプロセスであり、前の層の出力が次の層の入力となり、最終的に観察される単語が生成されます。
右から左に見てください
- トピックパラメータ: まず、各トピックの単語分布を選択します。この分布は、トピックに与えられた各単語の出現確率を定義します。
- トピック: 次に、特定のドキュメントについて、トピックの分布を選択します。この分布は、ドキュメント内に各トピックが出現する確率を定義します。
- 観察された単語: 最後に、文書内の各単語について、最初に文書のトピック分布からトピックを選択し、次にトピックの単語分布から単語を選択します。
2 つの方向は同等であるように見えます。1 つはドキュメント -> ドキュメントのトピック -> 単語であり、もう 1 つはトピック -> 単語です。
どちらの方向も逆方向に学習できます。これは、観察された単語から基礎となるトピックの分布とトピックのパラメーターを推測するプロセスです。このプロセスでは通常、ギブス サンプリングや変分ベイジアン法などの推論または最適化アルゴリズムを使用する必要があります。
言語の統計モデル: ジップの法則

単語にはべき乗則分布があり、さまざまな単語の頻度は指数関数的に減衰します。
-
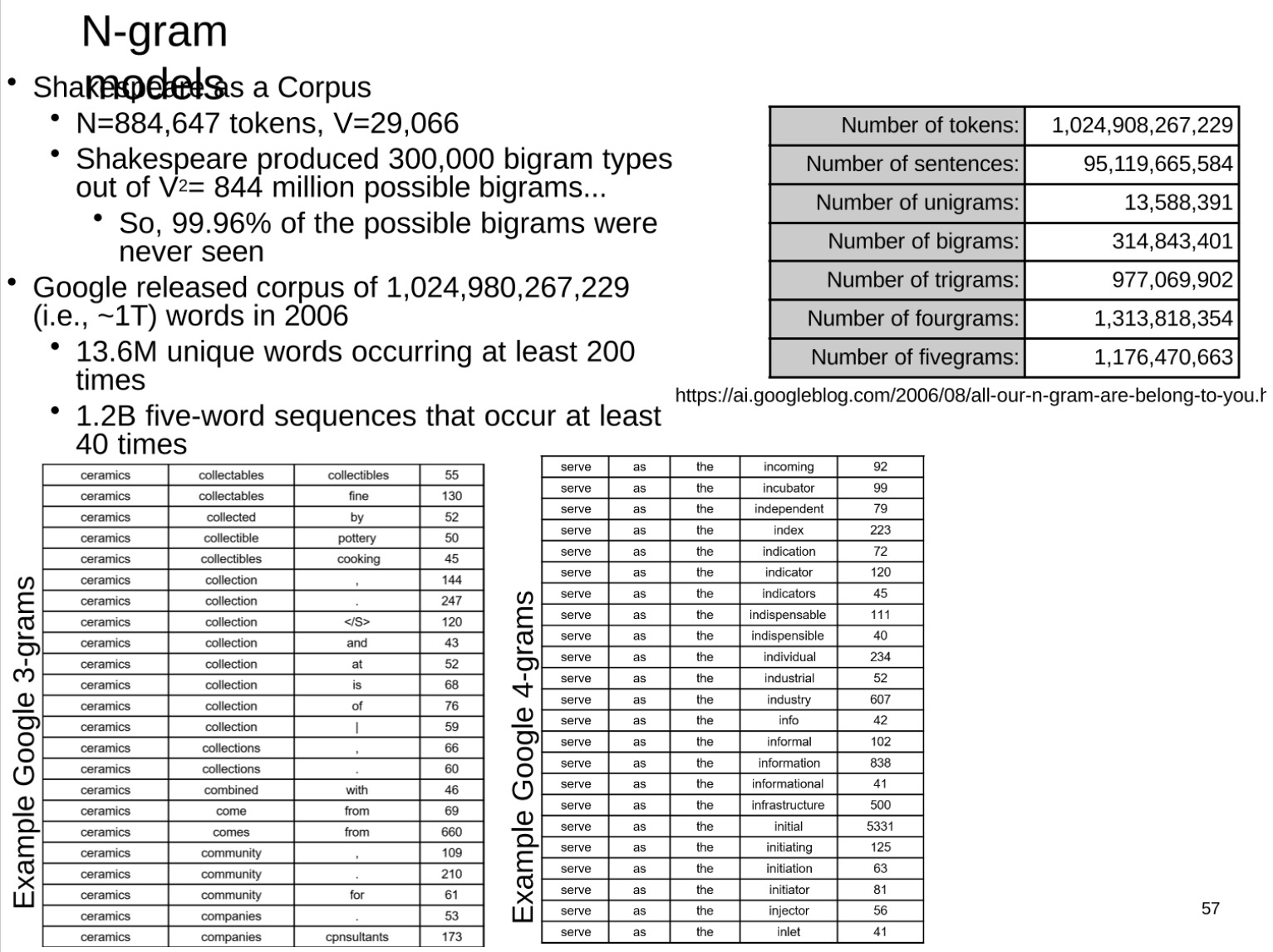
Nグラムモデル
-
バイグラムは単語のペアです
-
このセクションでは、大規模なコーパスへの N グラム モデルの実際の適用と、モデルのいくつかの制限について説明します。N グラム モデルは、単語の出現が前の N-1 個の単語にのみ関連していると想定する統計言語モデルです。大規模なコーパスの場合、N-gram モデルを使用して単語シーケンスの頻度をカウントできます。
このセクションでは最初にシェイクスピアの作品について触れます. シェイクスピアはその作品の中で 300,000 の異なるバイグラム タイプを作成しました. 理論的には、可能なバイグラムの数は語彙サイズの 2 乗、つまり 844 万種になります。しかし実際には、シェイクスピアで起こり得るダブレットの 99.96% は決して発生しません。これは、言語の実際の使用において、単語シーケンスの分布が非常に不均一であることを反映しています。
次にこの文章では、2006 年に Google がリリースした 1 兆 3000 億語のコーパスが引用されています。このコーパスには、少なくとも 200 回出現する 1,360 万の固有の単語と、少なくとも 40 回出現する 11 億 7000 万の 5 グラムが含まれています。この大規模な N-gram コーパスは、さまざまな言語モデルのトレーニングと評価に使用できます。
ただし、N-gram モデルにも制限があることに注意する必要があります。長距離の単語間の依存関係をうまく処理できず、また、データの疎性の問題、つまり、考えられる多くの N グラムが実際のコーパスに現れないという問題にも遭遇します。この状況を処理するには、いくつかの平滑化手法が必要です。または、ニューラル ネットワーク言語モデルなどのより複雑なモデルを使用して、複雑な単語間の関係をキャプチャする必要があります。

このパートでは、N-gram モデルを使用してシーケンスまたは文を生成する方法について説明します。このアプローチは、情報理論の創始者であるクロード シャノンによるものであることがよくあります。具体的な操作は以下の通りです。
まず、文開始記号を先頭に持つバイグラム (s>, w) が確率に従ってランダムに選択されます。- 次に、ダイアド (w, x) が確率に従ってランダムに選択されます。ここで、接頭辞 w は最初のダイアドの接尾辞と一致します。
- 同様に、新しいダイアドは連続的にランダムに選択され、文末記号の接尾辞が付いたダイアド (y, ) がランダムに選択されるまで、接頭辞は前のダイアドの接尾辞と一致します。
- 最後に、これらのバイグラム内の単語を連結して文を形成します。
シーケンスを生成するこの方法では、元のコーパスの文のスタイルをシミュレートできますが、この方法は完全に確率選択に依存しているため、生成された文は意味論的に完全に一貫しているわけではなく、単にコーパスのスタイルを模倣しているだけであることに注意してください。オリジナルのコーパス。
- シェイクスピアの記事はコンテンツを生成しますが、複数のグループ (n-gram) の形式では、n が大きいほど生成される効果が優れていることがわかります。
共起に基づくベクトル空間埋め込み
次の内容はトピックの入り口であり、現在最も人気のある大規模言語モデルの内容に入ります。これまでのものはすべて伝統的な方法です。
現代の NLP: 実際のモデリング言語: LLM

-
核となる視点
- モデルが微分可能である限り、任意の複雑なモデルを構築できます。次に、確率的勾配降下法によってトレーニングを行うことができます。
- 任意の大規模なラベルのないコーパスで事前トレーニングし、その後、微調整または少数ショット学習によって適応させることができます。
-
事前トレーニング タスクは通常、前のトークンを考慮して次のトークンを予測することです。
- 単語モデルでは、トークンの確率はコーパス内の頻度からのみ推定されます。
-
マルコフ仮定は、前のコンテンツが与えられたトークンの確率が、前のトークンが与えられたトークンの確率 (バイナリ モデル)、または最初の n 個のトークンが与えられたトークンの確率 (n 値モデル) と等しくなるようにモデルを単純化します。
-
複雑さは、コーパスの複雑さの全体的な尺度です。
- ここで、H§ は確率分布のエントロピーであり、直観的に言えば、困惑度はテキストを続けるための可能な方法の数です。k の困惑度は、平均的な驚きが、各ステップで k 個の同じ可能性の選択肢の中から推測しなければならないようなものであることを意味します。
- たとえば、医師のメモを口述筆記するときの困惑 (8.8) と、医師と患者の会話のときの困惑 (73.1) を比較しました。このことは、これらのアプリケーションで音声を正確に書き写すことがいかに難しいかを物語っています。
事前トレーニングについて簡単に説明します。
事前トレーニングは深層学習における重要な概念であり、その中心的な考え方は、まず大量のラベルなしデータでトレーニングし、一般的な言語表現を学習し、次に特定のタスクを微調整することです (微調整)。
簡単な例を挙げてみましょう。
あなたがフランス語を勉強しているとしますが、教師は少数の練習問題しか与えてくれないとします (これはラベル付きデータです。つまり、すべての例に正解があります)。しかし、自由に読めるフランス語のライブラリ全体もあります (これはラベルのないデータ、つまり大量のフランス語の本ですが、答えや説明はありません)。
事前トレーニングのプロセスは、最初に図書館でさまざまな本を読むのに多くの時間を費やすようなもので、指導してくれる教師はいませんが、たくさんの本を読むことで、フランス語の単語、文法、文脈をよく理解できるようになります。理解と感覚。このプロセスは、言語の一般的な表現を学習するために大量のラベルなしデータで事前トレーニングするニューラル ネットワークに似ています。
その後、先生に戻って、マークされた練習問題を解くとき、あなたはすでに多くの背景知識と言語の感覚を身につけているので、より正確に問題を解くことができます。このプロセスは、特定のタスク (テキスト分類、固有表現認識など) に関するニューラル ネットワークの微調整に似ており、事前トレーニングから得られた知識を使用して、特定のタスクのパフォーマンスを向上させます。
自然言語処理では、事前トレーニングと微調整の戦略が非常に効果的であることが証明されています。現実の世界では、多くの場合、ラベルのないデータ (Web ページ、書籍など) が存在するためです。少量のラベル付きデータのみ。事前トレーニングと微調整を通じて、これら 2 つのリソースをより効果的に活用し、モデルのパフォーマンスを向上させることができます。

上記の作業を実現するための重要な基礎は、単語をいわゆる意味空間にマッピングする埋め込みです。単語は空間内のベクトルで表されます。(ここでは似た意味の言葉が近いです)
このセクションは **分散セマンティクス** について説明します。この実装は非常に複雑に見えます (実際、実際そうです)。しかし、その重要なアイデアは非常にシンプルです。主な考え方は、同じコンテキスト内に出現する単語は意味的に関連している可能性があるということです(この単語をよく見てください。以前のように単語を表すためにハードコーディングするのではなく、コンテキストを使用して単語間の類似性を計算します)。これらの単語のどの単語がその文脈と同時に現れるかに注意を払うだけです)。
この関連性は高次元ベクトル (埋め込み空間) で表現され、各単語はこの高次元空間内の特定の点にマッピングされます。
word2vec、GloVe、Elmo、Bert、GPT など、いくつかの代表的な単語埋め込みモデル (より複雑、行列分解と同等) が図にリストされています。これらのモデルは分散セマンティクスの概念を使用し、大量のラベルのないテキスト データを学習します。 、単語ごとに高次元ベクトル (別名単語埋め込み) を生成します。これらの単語埋め込みは、意味の類似性、意味の関係など、単語の意味情報をキャプチャできます。
- word2vec: 単語のコンテキストを予測する (またはコンテキストから単語を予測する) ことによって単語埋め込みを生成します。
- GloVe (Global Vectors for Word Representation): 単語の共起統計に基づいて単語埋め込みを生成します。
- Elmo (言語モデルからの埋め込み): 双方向言語モデルを利用して、文脈依存の単語埋め込みを生成します。
- Bert (Transformer の双方向エンコーダ表現): Transformer アーキテクチャを使用して、コンテキスト依存の単語埋め込みを生成する双方向言語モデル。
- GPT (Generative Pretrained Transformer): Transformer アーキテクチャを使用してコンテキスト依存の単語埋め込みを生成する一方向言語モデル。
これらの単語埋め込みモデルの手法は異なりますが、いずれも大量のラベルなしテキスト データを使用して、単語のコンテキスト情報を学習することで単語の意味を捉えることができる単語埋め込みを生成します。
補足:ここで示したグラフは、この高次元空間をt-SNEを用いて次元削減し、可視化したものです。このスペースを使用すると、お互いに計算し、単語間の変換を実現できます。

具体的には、このプロセスを実現する方法。このプロセスが本当に素晴らしいんです。オートエンコーダーと同様に、エンコーダーは埋め込みであり、出力は意味空間内の座標 (オートエンコーダーでの表現学習に相当)、デコーダーは複雑なニューラル ネットワークであり、最後に予測されたトークン (トークンの可能性があります) を出力します。文字、単語、単語の一部など)
このプロセスは、エンコード(単語をベクトル表現に変換する、単語埋め込みまたは表現学習とも呼ばれる) とデコード(実際の予測) で構成されます。トレーニング プロセスでは、密な接続ネットワーク(Dense) と埋め込み層(Embedding) を通じて重みを更新し、最適化のためにバックプロパゲーション(Backpropagation) メソッドを使用します。(注: ここで、バックプロパゲーションはニューラル ネットワークだけでなく、埋め込み設定も変更します)
最初は単語の埋め込みが分散していますが、トレーニング後は、類似したコンテキストを持つ単語がクラスター化されます。コンテキスト情報を追加するには、複数の連続した文字を使用できます。トレーニングが進むにつれて、予測能力が向上します。
文字から単語に移行すると、単語の意味論と使用法が個々の文字よりも複雑になることが多いため、より大きなコンテキスト、より多くのレイヤー、および高次元の表現が必要になります。
言語モデル
言語モデルについてはここでは詳しく説明しません。それが何であるかを知っておいてください。いくつかの優れたビデオリンクが提供されています。学習が完了したら完全なブログを書き、このブログの下にブログリンクを貼り付けます。
RNN
まず、これらのモデルと単語埋め込みの関係について説明します。
RNN (リカレント ニューラル ネットワーク)、LSTM (Long Short Term Memory Network)、および Transformer はすべて、テキスト データや時系列データなどの連続データを処理するために使用されるモデルです。どちらもシーケンス内のパターンをキャプチャし、将来のシーケンス要素についての予測を行います。これらのモデルは両方とも、単語埋め込みを生成するために使用できます。また、事前トレーニングされた単語埋め込みを入力として使用することもできます。
単語埋め込みを生成するタスクにおいて、これらのモデルは、類似したコンテキストの単語を埋め込み空間内の類似した点にマッピングすることを学習できます。たとえば、word2vec モデルは、単純な 2 層ニューラル ネットワーク (実際には非常に基本的な RNN) を使用してトレーニングできます。BERT や GPT などのより複雑なモデルでは、Transformer 構造が使用されます。
したがって、実際には、単語の埋め込みを権威ある公式 Web サイトから直接ダウンロードして、ローカルでトレーニングすることができます。モデルを使用して自分で埋め込みをトレーニングすることも可能です。両者の間の境界線は曖昧です。
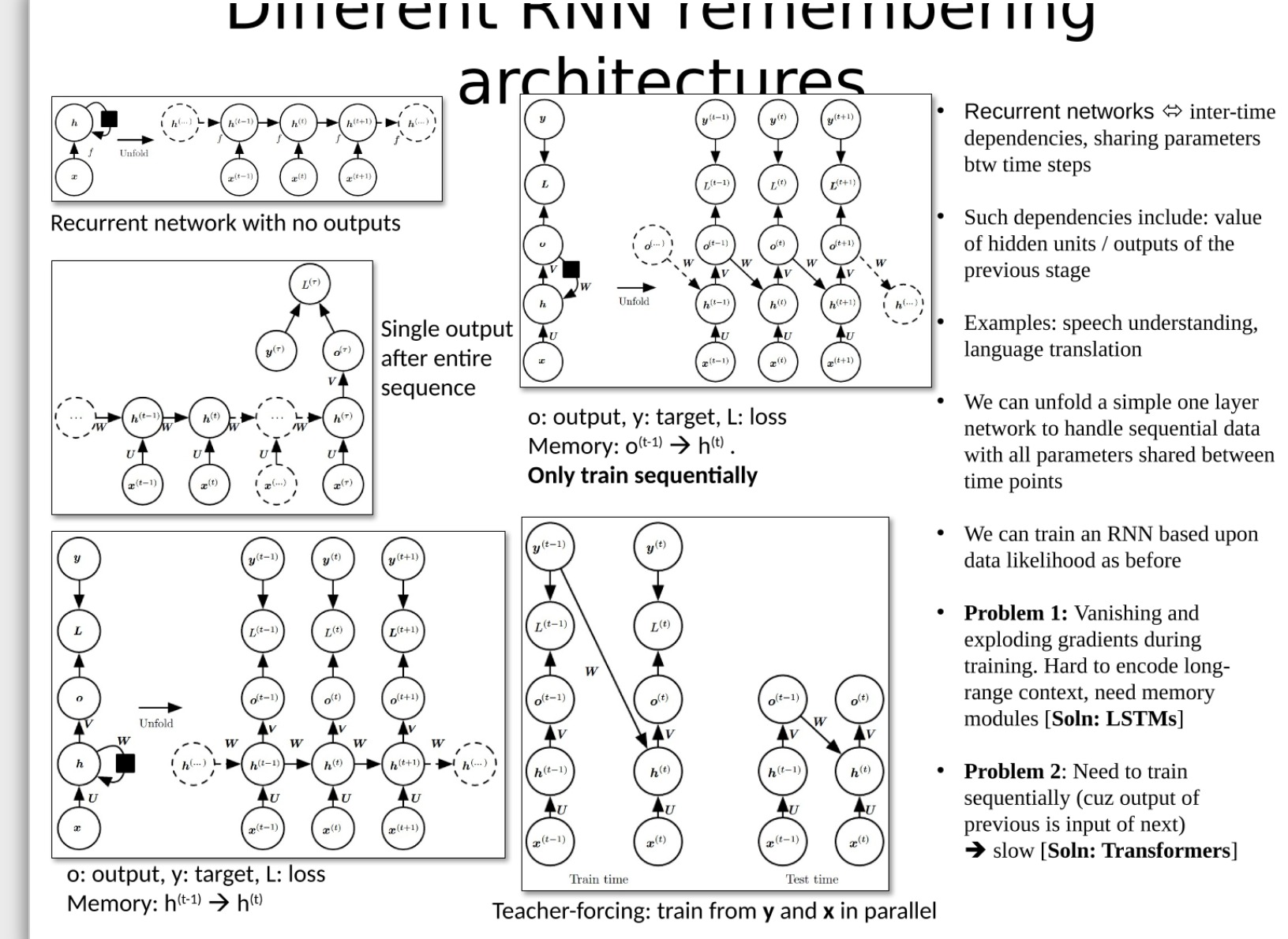
具体的な内容については、以前のブログ「pytorchニューラルネットワークノート-RNNとLSTM」を参照していただき、冒頭に学習用の動画リンクを掲載しましたが、非常に分かりやすいです。
LSTM

推奨学習コース: LSTM を手で裂く李紅儀
エルモ
言語モデルからの (コンテキストに応じた) 埋め込み

ELMo (Embeddings from Language Models) は、言語モデルをトレーニングして単語埋め込み (単語を表すベクトル) を生成する深層学習モデルです。これらの単語埋め込みでは単語のコンテキストが考慮されるため、Word2Vec や GloVe などの従来の単語埋め込みよりも豊富な意味情報が提供されます。
ELMo の主な機能は次のとおりです。
- コンテキストに応じた単語の埋め込み: 各単語に固定の単語の埋め込みを提供する Word2Vec や GloVe などのモデルとは異なり、ELMo はコンテキストに応じて変化する各単語の埋め込みを提供します。これは、同じ単語でも異なる文に異なる単語が埋め込まれている可能性があることを意味します。たとえば、「サッカーをしましょう」という文と「シェイクスピアが書いた劇の中で」という文では、「遊ぶ」の意味が異なるため、単語の埋め込みも異なります。
- 双方向 LSTM : ELMo は、双方向の Long Short-Term Memory (LSTM) ネットワークを使用してテキストをモデル化します。このネットワークは単語のコンテキスト情報も考慮するため、より正確なコンテキスト単語の埋め込みが可能になります。
- 事前トレーニング: ELMo は、事前トレーニングされた言語モデルを通じて単語埋め込みを生成します。この事前トレーニング タスクは教師なしです。つまり、ラベル付きデータは必要ありません。この事前トレーニング済み言語モデルのタスクは、文脈を考慮して単語の次の単語を予測することであり、このタスクには大量のテキスト データが必要です。
ELMo 単語埋め込みを使用する利点は、事前トレーニングされたモデルが大量の意味情報をキャプチャできることです。その情報は、テキスト分類、エンティティ認識、センチメント分析などのさまざまな自然言語処理 (NLP) タスクに使用できます。ただし、ELMo モデルの欠点は、計算コストが非常に高く、トレーニングと使用に多くのコンピューティング リソースが必要なことです。
LSTM を学習した後、ELMO を学習できますが、GPT を学習する前に変圧器を学習する必要があります
学習コース: Li Honyi-ELMO、BERT、GPT の説明