I.はじめに
ビッグモデルの人気が高まっているため、中国ではビッグモデルをベースにしたローカルナレッジベースを構築したいというニーズが多いようで、5月末頃にQuivrが最初のバージョン0.0.1をリリースした際には、最初のバージョンは、基本的なシェルフを実現するために OpenAI の GPT モデルと組み合わせた LangChain テクノロジーのみを使用します。機能は完璧ではありませんが、研究アイデアを学習できます。当時、Quivr は個人の知識ベースを実現するベクトル データベースを構築するために Supabase を選択しましたGPT のモデル機能を使用して. それはまだ良い選択です. それ以来、Quivr の進歩に注目しています. 基本的に Quivr の更新頻度は比較的高いです. 構築方法の記事を書いた後5 月末にローカルで Quivr に基づいたナレッジ ベースを作成し続けましたが、基本的に、数人の友人が個人的にチャットして Quivr の構築についていくつかの質問をしたり、Quivr の将来の機能計画の方向性についての提案や期待もいくつかありました。 Quivr はより成熟して開発されており、個人や中小企業にとっては低コストの選択肢となる可能性もあります。
Quivr は 2 か月以上の更新で 50 以上のバージョンを連続リリースしており、元の機能の改善、コードのリファクタリング、多くの新機能の拡張など、Quivr はそれほど脆弱ではありません。はい、基本的な機能はほぼ網羅されています。興味のある方は試してみてはいかがでしょうか。
Quivr は常に更新されており、展開に変更が生じる可能性があるため、オリジナルの公開記事とビデオについては、興味があれば以下のリンクにアクセスしてください。Quivr の最新バージョンを展開したい場合は、次の手順を実行できます。この最新のアップグレード記事を直接読んでください。
【記事】Quivr、Supabaseをベースにローカルナレッジベースを構築
[ビデオ] Quivr は Supabase に基づいてローカルのナレッジ ベースを構築します
2. 特徴
2.1. 脳の拡張能力
1 つのブレインのみをサポートする単一アカウントから、複数のブレイン (特定の数は構成可能、デフォルトは 5) をサポートできるようになりました。そのため、Quivr システムを導入すると、複数のブレインを作成してナレッジ ベースを個別に維持し、データを削減できます。損失 取得範囲とデータ権限の分離。
ユーザーは、製品に関するインテリジェントなカスタマー サービス、配送に関する Q&A アシスタント、製品マネージャー アシスタントなど、好みに応じてナレッジ ベースをカスタマイズできます。
2.2. 脳の許可制御
[参照]、[編集]、[所有者]の 3 つの役割に応じて、単一のナレッジ ベースに対応するアクセス権を設定することをサポートし、リンクやメールを通じて他のユーザーと個人の頭脳を共有することもサポートします。
このように、個人のプライベート ナレッジ ベース、または企業チームが共有するナレッジ ベースを実装すると非常に便利で、各ユーザーが過去に同じナレッジを繰り返しアップロードする必要がなくなり、キーやデータの無駄が発生することがなくなります。知識の冗長性。
2.3、LLM拡張機能
オリジナル バージョンでは、GPT モデルと Claude モデルの統合のみがサポートされていましたが、現在は GPT4All などのローカル オープン ソース モデルのサポートが拡張されており、将来的にはさらに多くのオープン ソース モデルがサポートされる予定です。
2.4. オープン API インターフェース
Quivr は、フロントエンドとバックエンドを分離した独立したアーキテクチャを採用しています。Quivr は、FastAPI を使用して、バックエンドに RESTful API を提供します。バックエンド サービスは、フロントエンド アプリケーションを必要とせずに独立して使用できます。パーティ アプリケーションも、API インターフェイスを通じて簡単に統合できます。
3. 基本的な環境準備
3.1. 前提条件
導入プロセス中の不要なトラブルを減らすために、オペレーティング システムはUbuntu 22 以降を選択することをお勧めします。サーバーに関しては、OpenAI インターフェイスに正常にアクセスできる限り、GCP/AWS/Aliyun にインストールしました。 、主にネットワークの問題を解決するために、サーバーが配置されている地域を選択します。
システムメモリ: 個人的な展開やプレイのみの場合は 1GB 以上をお勧めしますが、正式な環境で使用する場合は、特定のビジネス トラフィックに応じて構成する必要があります。
システム ハードディスク: 導入デモの場合のみ、30 GB 以上が推奨されます。
次に、Quivr をUbuntu 22に迅速にデプロイして、ローカルのナレッジ ベース システムを構築する方法を示します。
3.2. Docker と Docker-Compose のインストール
まず Docker と Docker Compose をインストールします。次の手順に従います。
1. システム パッケージ リストを更新します。
sudo apt update
2. Docker が依存するパッケージをインストールします。
sudo apt install apt-transport-https ca-certificates curl software-properties-common
3. Docker の公式 GPG キーを追加します。
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
4. Docker ソフトウェア ソースを追加します。
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
5. パッケージリストを更新します。
sudo apt update
6. Docker エンジンをインストールします。
sudo apt install docker-ce docker-ce-cli containerd.io
7. Docker が正しくインストールされていることを確認します。
sudo docker run hello-world
8. Docker Compose をインストールします。
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
9. 実行権限を追加します。
sudo chmod +x /usr/local/bin/docker-compose
10. Docker Compose が正しくインストールされていることを確認します。
docker-compose --version
これで、Ubuntu に Docker と Docker Compose が正常にインストールされました。これらのコマンドを使用して、コンテナ化されたアプリケーションを管理および実行できます。
注:オブジェクト タイプ *libnetwork.endpointCnt のストアを更新できませんでした: ストアにキーが見つかりません
Restart docker deamon would fix it.
For ubuntu:
sudo service docker restart
4. Supabaseプロジェクトの作成
Supabase は、オープンソースの Firebase の代替品です。Postgres データベース、認証、インスタント API、エッジ機能、リアルタイム サブスクリプション、ストレージ、ベクトル埋め込みを操作します。無料アカウントでは 2 つのプロジェクトを作成できます。
1. アカウントを登録する
https://supabase.com/ にアクセスして無料アカウントにサインアップします。
2. プロジェクトを作成する

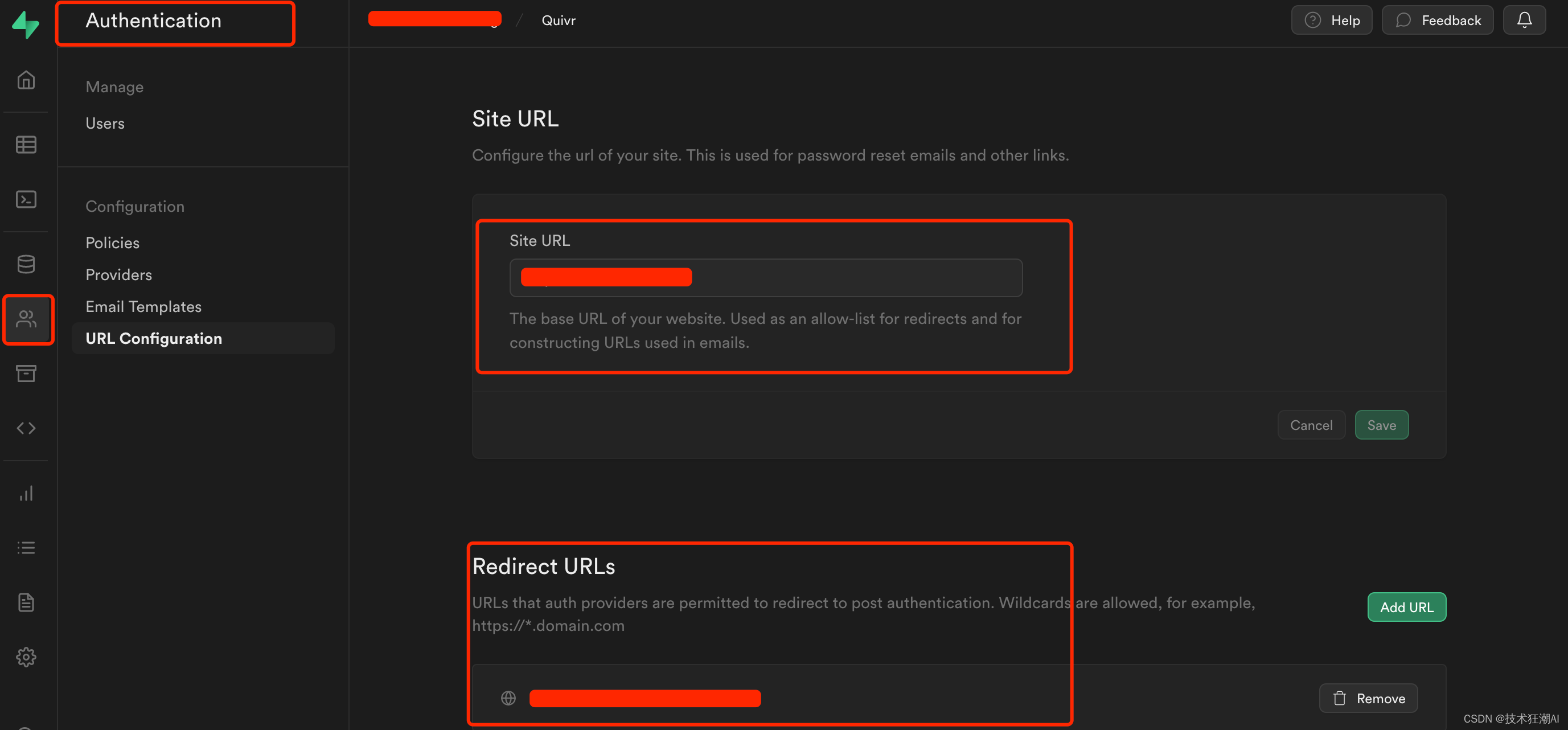
3. Web サイトの URL とリダイレクト アドレスを設定する
主にパスワードのリセットと電子メールのリダイレクト ジャンプ リンクに使用されます。アドレスはシステムのフロントエンド アクセス アドレスです: http://ip:3000
5. Quivr アプリケーションをデプロイする
5.1. リポジトリのクローン作成
git clone https://github.com/StanGirard/Quivr.git && cd Quivr
- ls -alhコマンドを使用すると、すべてのファイル (隠しファイルを含む) を表示できます。
通常、Quivr はメイン ブランチで新しいコンテンツを毎週更新し、未知のバグがいくつか存在するため、デプロイメントには最新リリースの安定バージョンを選択することをお勧めします。

5.2..XXXXX_envファイルのコピー
新しいバージョンのバックエンド コードはリファクタリングされており、新しい構成ファイルはbackend/core/ディレクトリの下にある必要があります。
cp .backend_env.example backend/core/.env
cp .frontend_env.example frontend/.env
5.3.frontend/.envファイルを更新する
NEXT_PUBLIC_ENV=local
NEXT_PUBLIC_BACKEND_URL=http://你的IP:5050/
NEXT_PUBLIC_SUPABASE_URL=your supabase project url
NEXT_PUBLIC_SUPABASE_ANON_KEY=your supabase api key
NEXT_PUBLIC_JUNE_API_KEY=your june api keyQuivr がローカル コンピューターにデプロイされている場合、backend_url は localhost を直接使用することに注意してください。Quivr がローカル サーバーまたはクラウド サーバーにデプロイされている場合は、バックエンド URL をサーバーの実際の IP アドレスに変更する必要があります。(多くの人はこの構成を無視します!)
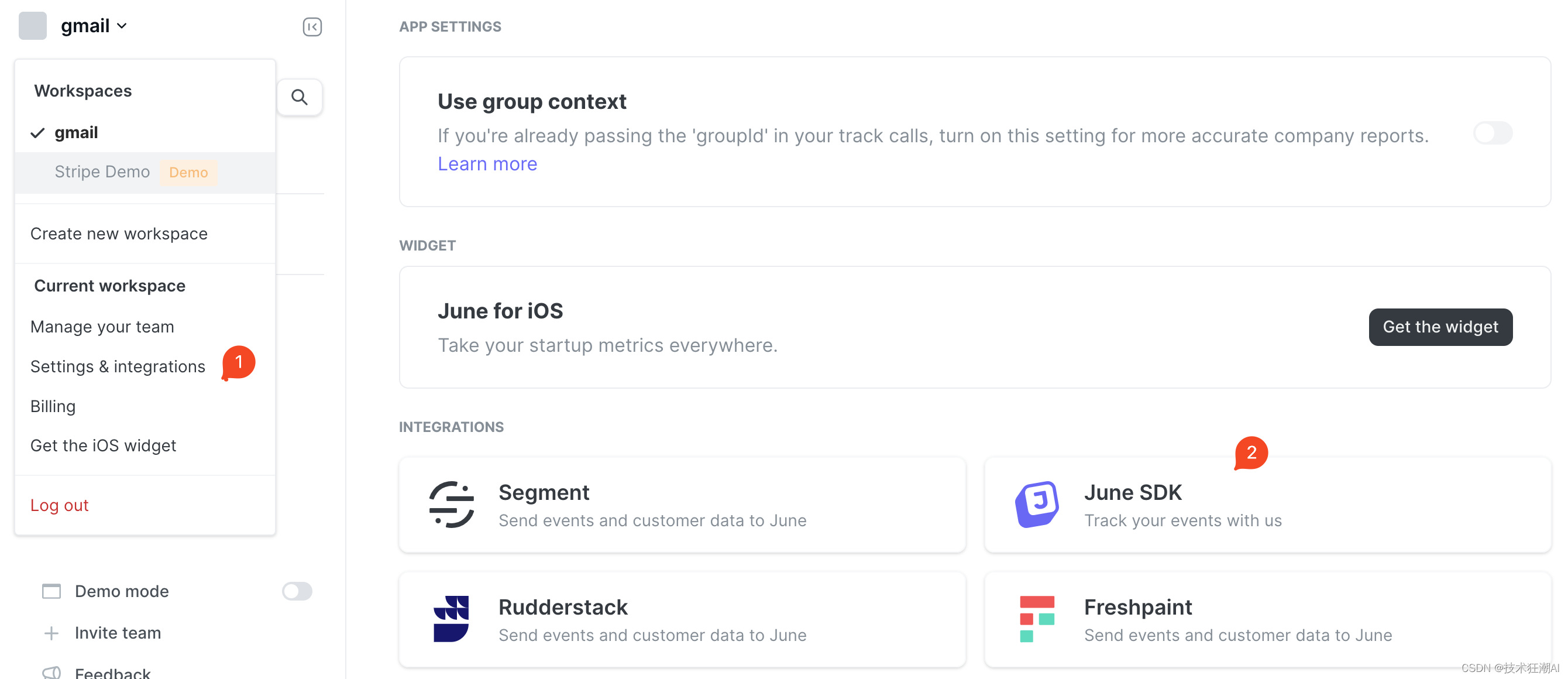
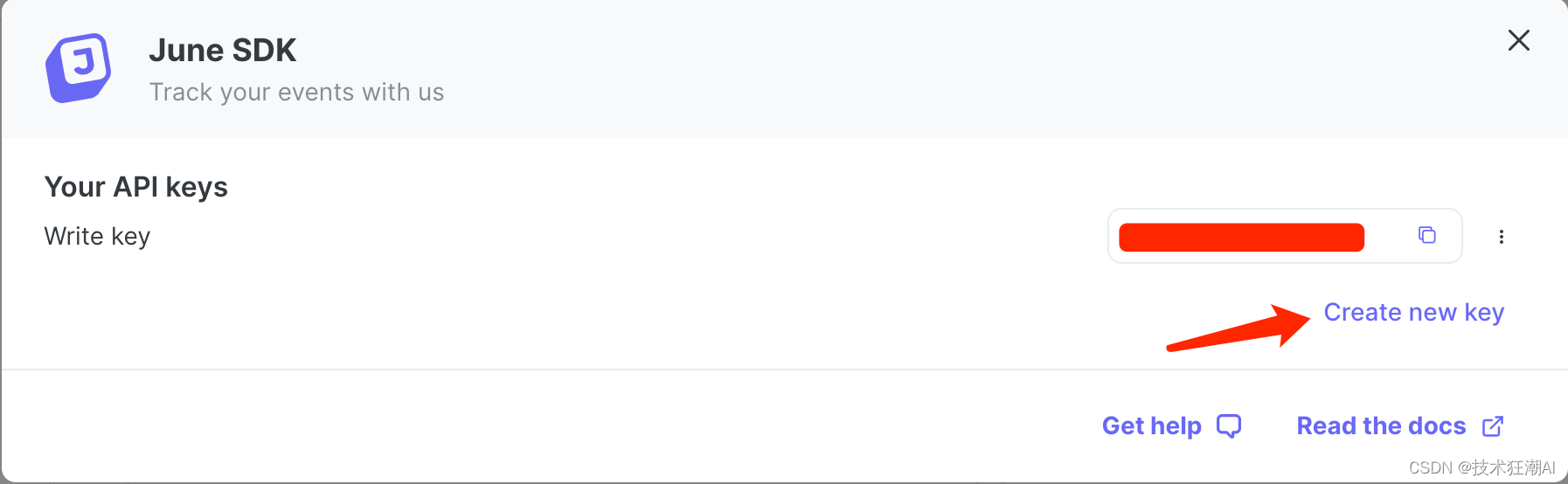
NEXT_PUBLIC_JUNE_API_KEY プロパティの構成手順:
Quivr は June Analytics が提供する API インターフェイスを統合します。 June Analytics を統合した後は、システムに正しい June API キー ( June キー ) を設定するだけで、 June の Web サイトがシステム データの収集と追跡を自動的に開始します。
データが収集されたら、 June Analytics ダッシュボードにログインして、収集されたデータを表示および分析できます。June ダッシュボードは、さまざまなレポート、グラフ、メトリクスを参照するための使いやすいインターフェイスを提供し、ユーザーの行動、イベント トリガー、その他の主要なメトリクスを理解できます。
6 月のダッシュボードを通じて、ユーザー アクティビティ、イベント追跡、コンバージョン率などのさまざまな分析ビューを探索できます。時間範囲、特定のユーザー、またはカスタム イベントに基づいてデータをフィルタリングして絞り込み、より具体的な洞察や洞察を得ることができます。
正式に開設されたサイトの場合は、必要に応じてアクセスすることを選択できます。デフォルトでは、このパラメータの設定を考慮する必要はありません。Web サイトのデータを収集および分析する必要がある場合は、6 月のアカウントに登録して申請できます。 6 月のキーの場合:
 5.4. backend/core/.envファイル を更新する
5.4. backend/core/.envファイル を更新する
SUPABASE_URL=your supabase project url
SUPABASE_SERVICE_KEY=your supabase api key
PG_DATABASE_URL=notimplementedyet
OPENAI_API_KEY=your openai api key
ANTHROPIC_API_KEY=null
JWT_SECRET_KEY=your supabase jwt secret key
AUTHENTICATE=true
GOOGLE_APPLICATION_CREDENTIALS=<change-me>
GOOGLE_CLOUD_PROJECT=<change-me>
# 默认50M
MAX_BRAIN_SIZE=52428800.
MAX_REQUESTS_NUMBER=2000
MAX_BRAIN_PER_USER=100
# Private LLM Variables
PRIVATE=False
MODEL_PATH=./local_models/ggml-gpt4all-j-v1.3-groovy.bin
# RESEND
RESEND_API_KEY=your resend api key
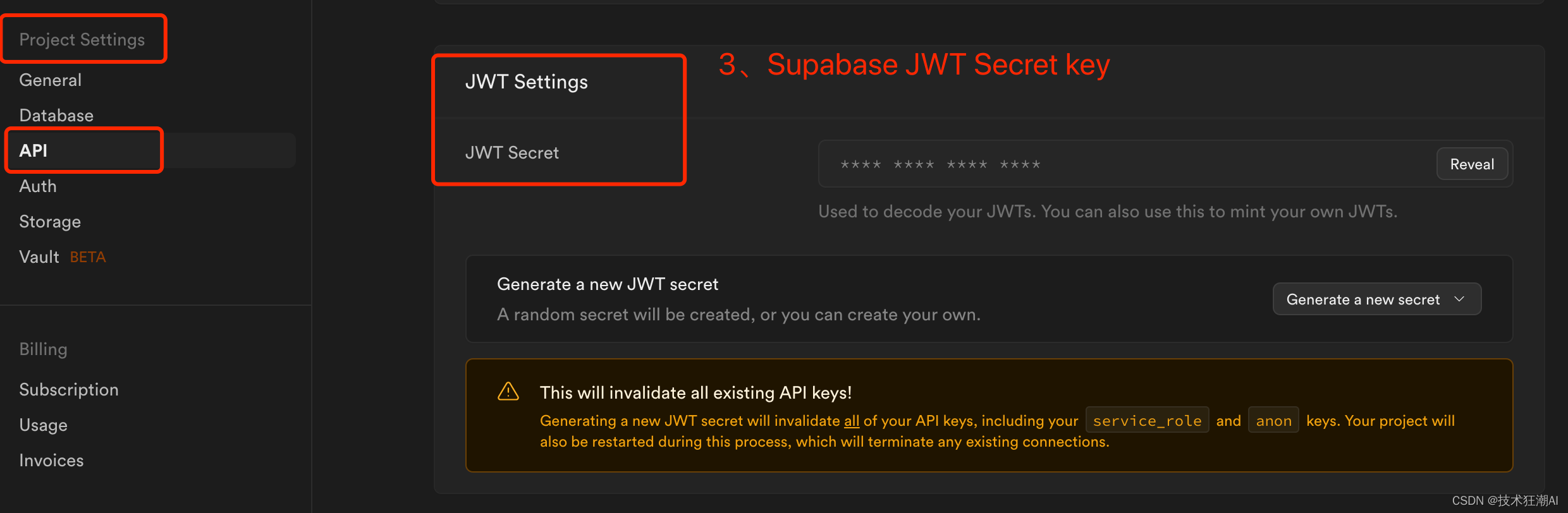
RESEND_EMAIL_ADDRESS=your resend email addresssupabase_url はSupabase ダッシュボードの [プロジェクト設定] -> [API] にある対応するプロジェクト URL であり、supabase_service_key は Supabase ダッシュボードの [プロジェクト設定] -> [API] にあることに注意してください。「プロジェクト API キー」セクションにある anon 公開キーを使用します。JWT_SECRET_KEY は、プロジェクト設定 -> JWT 設定 -> JWT シークレットの supabase 設定にあります。(ANTHROPIC_API_KEY に値を設定することはできませんが、キーは削除できないことに注意してください。削除しないとビルドが失敗します)

5.5. Supabase データベースとテーブルの作成
Web インターフェース ( SQL エディター-> 「新規クエリー」) を介してSupabase データベースで次の移行スクリプトを実行します。
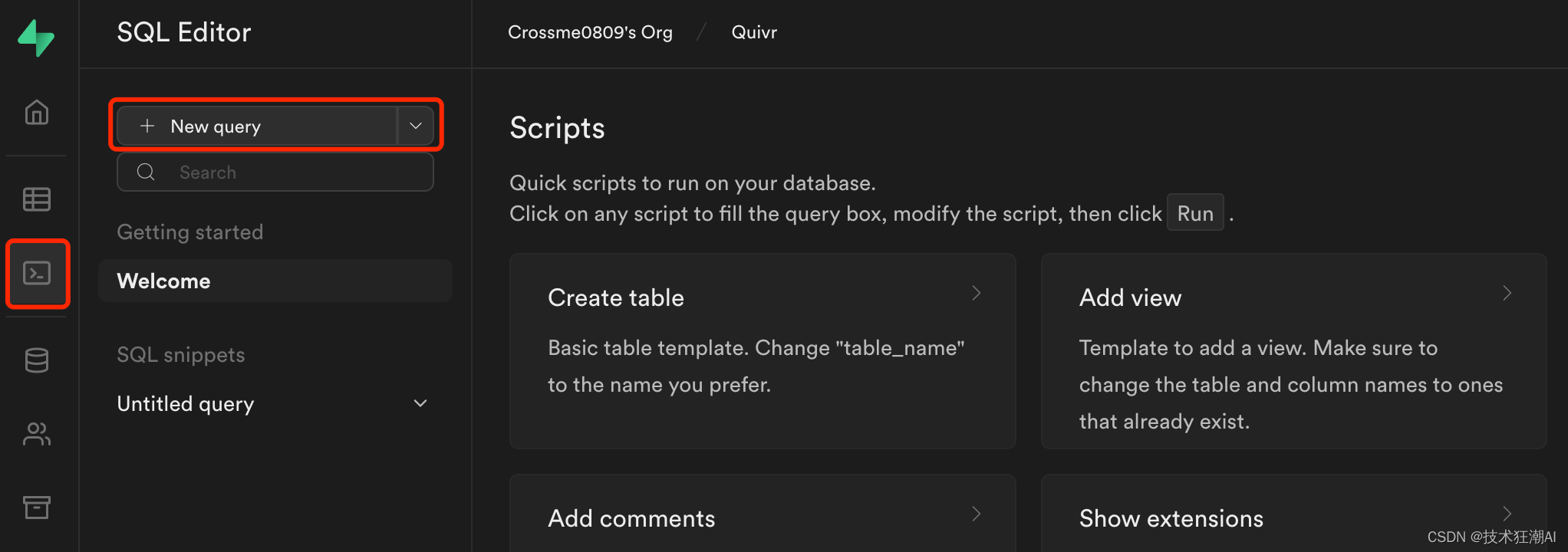
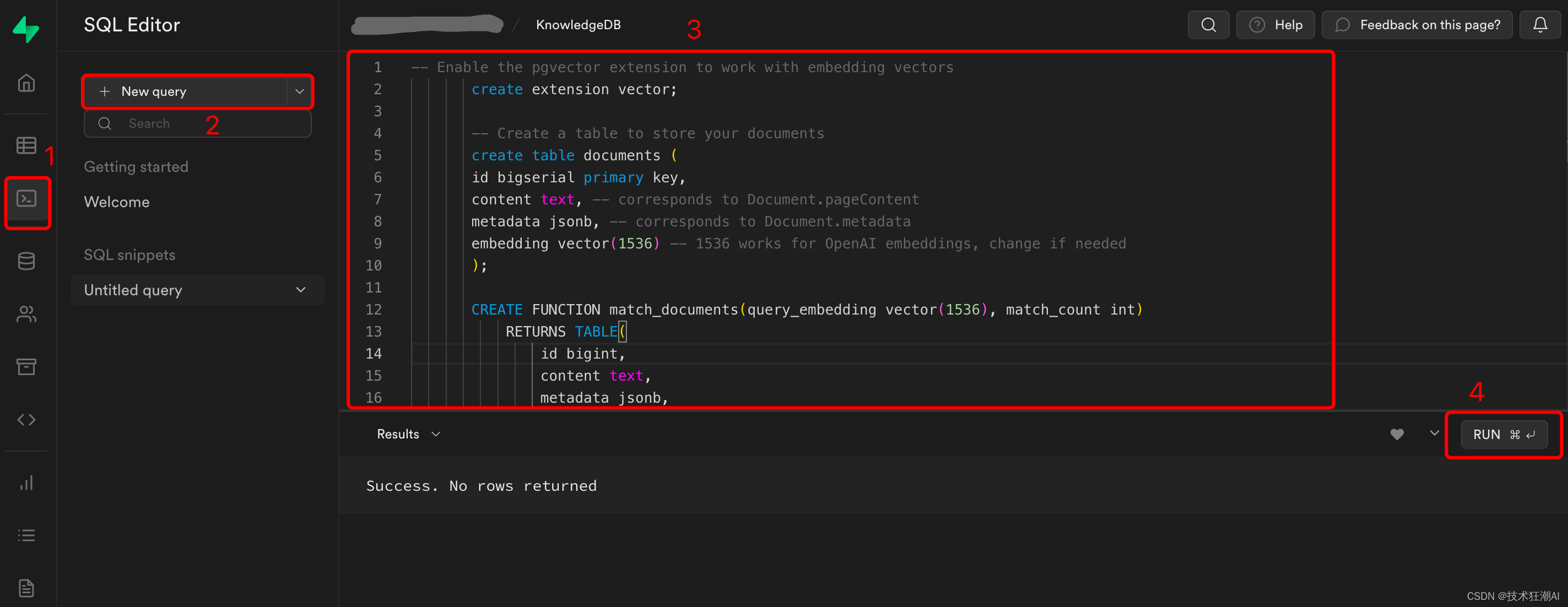
データベーススクリプトのアドレス:
https://github.com/StanGirard/quivr/blob/main/scripts/tables.sql
-- Create users table
CREATE TABLE IF NOT EXISTS users(
user_id UUID REFERENCES auth.users (id),
email TEXT,
date TEXT,
requests_count INT,
PRIMARY KEY (user_id, date)
);
-- Create chats table
CREATE TABLE IF NOT EXISTS chats(
chat_id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,
user_id UUID REFERENCES auth.users (id),
creation_time TIMESTAMP DEFAULT current_timestamp,
history JSONB,
chat_name TEXT
);
-- Create vector extension
CREATE EXTENSION IF NOT EXISTS vector;
-- Create vectors table
CREATE TABLE IF NOT EXISTS vectors (
id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,
content TEXT,
metadata JSONB,
embedding VECTOR(1536)
);
-- Create function to match vectors
CREATE OR REPLACE FUNCTION match_vectors(query_embedding VECTOR(1536), match_count INT, p_brain_id UUID)
RETURNS TABLE(
id UUID,
brain_id UUID,
content TEXT,
metadata JSONB,
embedding VECTOR(1536),
similarity FLOAT
) LANGUAGE plpgsql AS $$
#variable_conflict use_column
BEGIN
RETURN QUERY
SELECT
vectors.id,
brains_vectors.brain_id,
vectors.content,
vectors.metadata,
vectors.embedding,
1 - (vectors.embedding <=> query_embedding) AS similarity
FROM
vectors
INNER JOIN
brains_vectors ON vectors.id = brains_vectors.vector_id
WHERE brains_vectors.brain_id = p_brain_id
ORDER BY
vectors.embedding <=> query_embedding
LIMIT match_count;
END;
$$;
-- Create stats table
CREATE TABLE IF NOT EXISTS stats (
time TIMESTAMP,
chat BOOLEAN,
embedding BOOLEAN,
details TEXT,
metadata JSONB,
id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY
);
-- Create summaries table
CREATE TABLE IF NOT EXISTS summaries (
id BIGSERIAL PRIMARY KEY,
document_id UUID REFERENCES vectors(id),
content TEXT,
metadata JSONB,
embedding VECTOR(1536)
);
-- Create function to match summaries
CREATE OR REPLACE FUNCTION match_summaries(query_embedding VECTOR(1536), match_count INT, match_threshold FLOAT)
RETURNS TABLE(
id BIGINT,
document_id UUID,
content TEXT,
metadata JSONB,
embedding VECTOR(1536),
similarity FLOAT
) LANGUAGE plpgsql AS $$
#variable_conflict use_column
BEGIN
RETURN QUERY
SELECT
id,
document_id,
content,
metadata,
embedding,
1 - (summaries.embedding <=> query_embedding) AS similarity
FROM
summaries
WHERE 1 - (summaries.embedding <=> query_embedding) > match_threshold
ORDER BY
summaries.embedding <=> query_embedding
LIMIT match_count;
END;
$$;
-- Create api_keys table
CREATE TABLE IF NOT EXISTS api_keys(
key_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
user_id UUID REFERENCES auth.users (id),
api_key TEXT UNIQUE,
creation_time TIMESTAMP DEFAULT current_timestamp,
deleted_time TIMESTAMP,
is_active BOOLEAN DEFAULT true
);
--- Create prompts table
CREATE TABLE IF NOT EXISTS prompts (
id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,
title VARCHAR(255),
content TEXT,
status VARCHAR(255) DEFAULT 'private'
);
--- Create brains table
CREATE TABLE IF NOT EXISTS brains (
brain_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
name TEXT NOT NULL,
status TEXT,
description TEXT,
model TEXT,
max_tokens INT,
temperature FLOAT,
openai_api_key TEXT,
prompt_id UUID REFERENCES prompts(id)
);
-- Create chat_history table
CREATE TABLE IF NOT EXISTS chat_history (
message_id UUID DEFAULT uuid_generate_v4(),
chat_id UUID REFERENCES chats(chat_id),
user_message TEXT,
assistant TEXT,
message_time TIMESTAMP DEFAULT current_timestamp,
PRIMARY KEY (chat_id, message_id),
prompt_id UUID REFERENCES prompts(id),
brain_id UUID REFERENCES brains(brain_id)
);
-- Create brains X users table
CREATE TABLE IF NOT EXISTS brains_users (
brain_id UUID,
user_id UUID,
rights VARCHAR(255),
default_brain BOOLEAN DEFAULT false,
PRIMARY KEY (brain_id, user_id),
FOREIGN KEY (user_id) REFERENCES auth.users (id),
FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);
-- Create brains X vectors table
CREATE TABLE IF NOT EXISTS brains_vectors (
brain_id UUID,
vector_id UUID,
file_sha1 TEXT,
PRIMARY KEY (brain_id, vector_id),
FOREIGN KEY (vector_id) REFERENCES vectors (id),
FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);
-- Create brains X vectors table
CREATE TABLE IF NOT EXISTS brain_subscription_invitations (
brain_id UUID,
email VARCHAR(255),
rights VARCHAR(255),
PRIMARY KEY (brain_id, email),
FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);
--- Create user_identity table
CREATE TABLE IF NOT EXISTS user_identity (
user_id UUID PRIMARY KEY,
openai_api_key VARCHAR(255)
);
CREATE OR REPLACE FUNCTION public.get_user_email_by_user_id(user_id uuid)
RETURNS TABLE (email text)
SECURITY definer
AS $$
BEGIN
RETURN QUERY SELECT au.email::text FROM auth.users au WHERE au.id = user_id;
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION public.get_user_id_by_user_email(user_email text)
RETURNS TABLE (user_id uuid)
SECURITY DEFINER
AS $$
BEGIN
RETURN QUERY SELECT au.id::uuid FROM auth.users au WHERE au.email = user_email;
END;
$$ LANGUAGE plpgsql;
CREATE TABLE IF NOT EXISTS migrations (
name VARCHAR(255) PRIMARY KEY,
executed_at TIMESTAMPTZ DEFAULT current_timestamp
);
INSERT INTO migrations (name)
SELECT '20230809154300_add_prompt_id_brain_id_to_chat_history_table'
WHERE NOT EXISTS (
SELECT 1 FROM migrations WHERE name = '20230809154300_add_prompt_id_brain_id_to_chat_history_table'
);データベース スクリプトが実行されると、テーブル エディターで作成されたテーブルを確認できます。

5.6. 糸のタイムアウト時間を設定する
フロントエンド コンテナーで依存関係を構築すると、一般に時間がかかります。一部の依存関係は、ネットワーク上の理由により長時間完了しない場合があり、その場合、yarn 接続がタイムアウトになります。古いバージョンでは、スクリプトを変更できます。ネットワーク タイムアウト パラメーターを増やすための /frontend/Dockerfile ファイルの糸インストール部分新規バージョンではこのパラメーターが既に追加されているため、この手順は無視できます。
RUN yarn install --network-timeout 1000000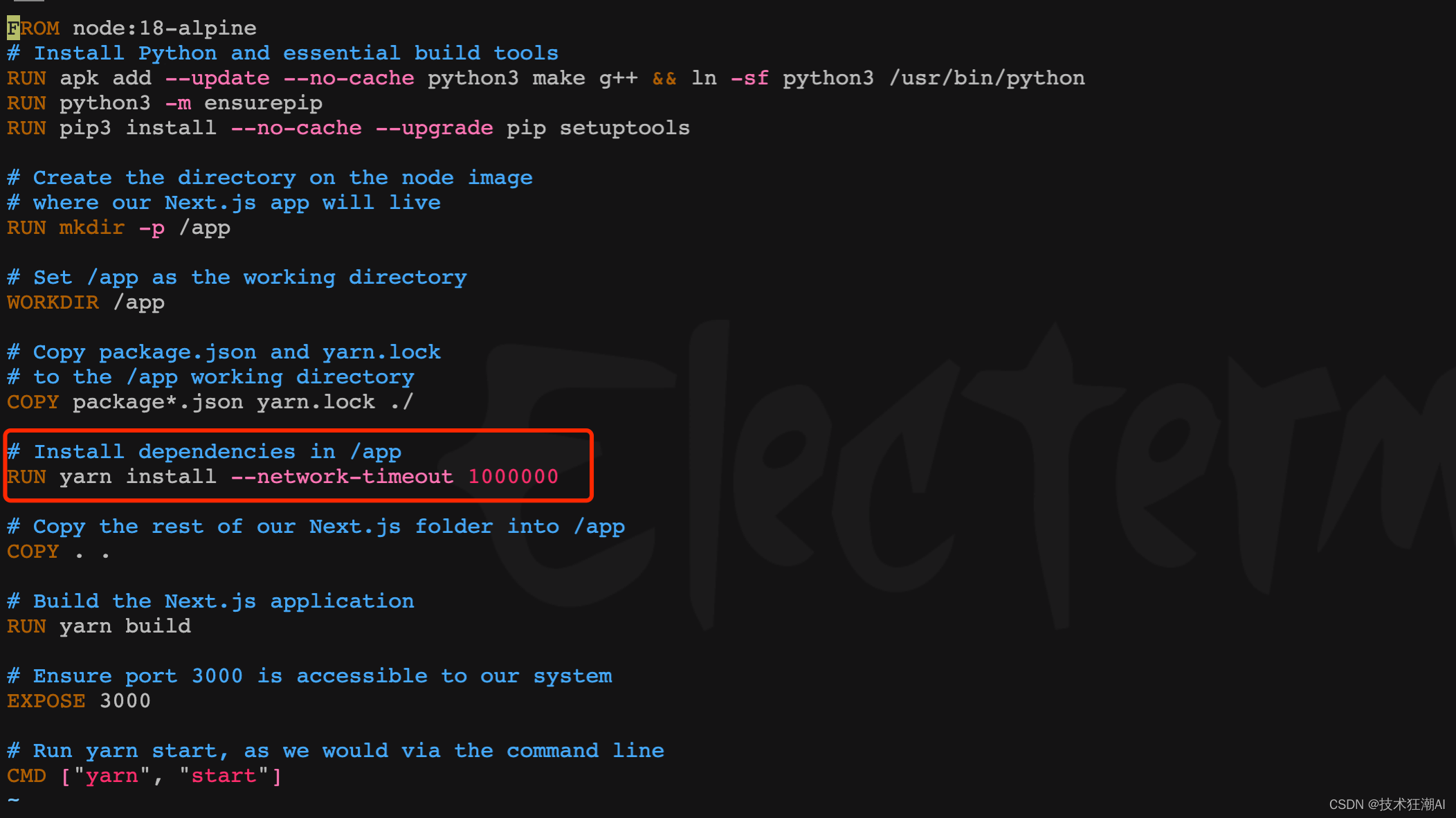
5.7. Quivr をビルドして起動する
docker compose -f docker-compose.yml up --build -dQuivr がビルドされて開始されると、次の図に示されます。

6. Quivr にアクセス
導入が完了したら、http://ip:3000 に直接アクセスし、最初の導入のために電子メールでアカウントを登録できます。
6.1. 新しい頭脳を追加する
Quivrには「脳」という概念があります。これらは、特定のトピックに関する質問に答えるために大規模言語モデル (LLM) にコンテキストを提供するために使用できる、閉じられた情報体系です。
LLM はさまざまなデータに基づいてトレーニングされますが、特定のトピックに関する質問に答えたり、そのデータを使用して特定のトピックに関する推論を行うには、そのトピックのコンテキストが与えられる必要があります。Quivr は、直感的な方法としてあなたの脳を使用してコンテキストを提供します。
Quivr でブレインが選択されると、LLM はそのブレインのコンテキストのみを取得します。これにより、ユーザーは特定のトピックに関する頭脳を構築し、それを使用してそのトピックに関する質問に答えることができます。将来的には、Quivr は他のユーザーと脳を共有できるようになります。
Quivr の新バージョンでは、複数のナレッジ ベース ブレーンの革新をサポートし、ナレッジ ベースのコンテンツ取得の分離を実現し、サポート ベースの承認もサポートして、承認されたユーザーのみがナレッジ ベースにアクセスまたは共有できるようにします。リンクを共有することで。数か月前のバージョンよりも機能が向上しています。
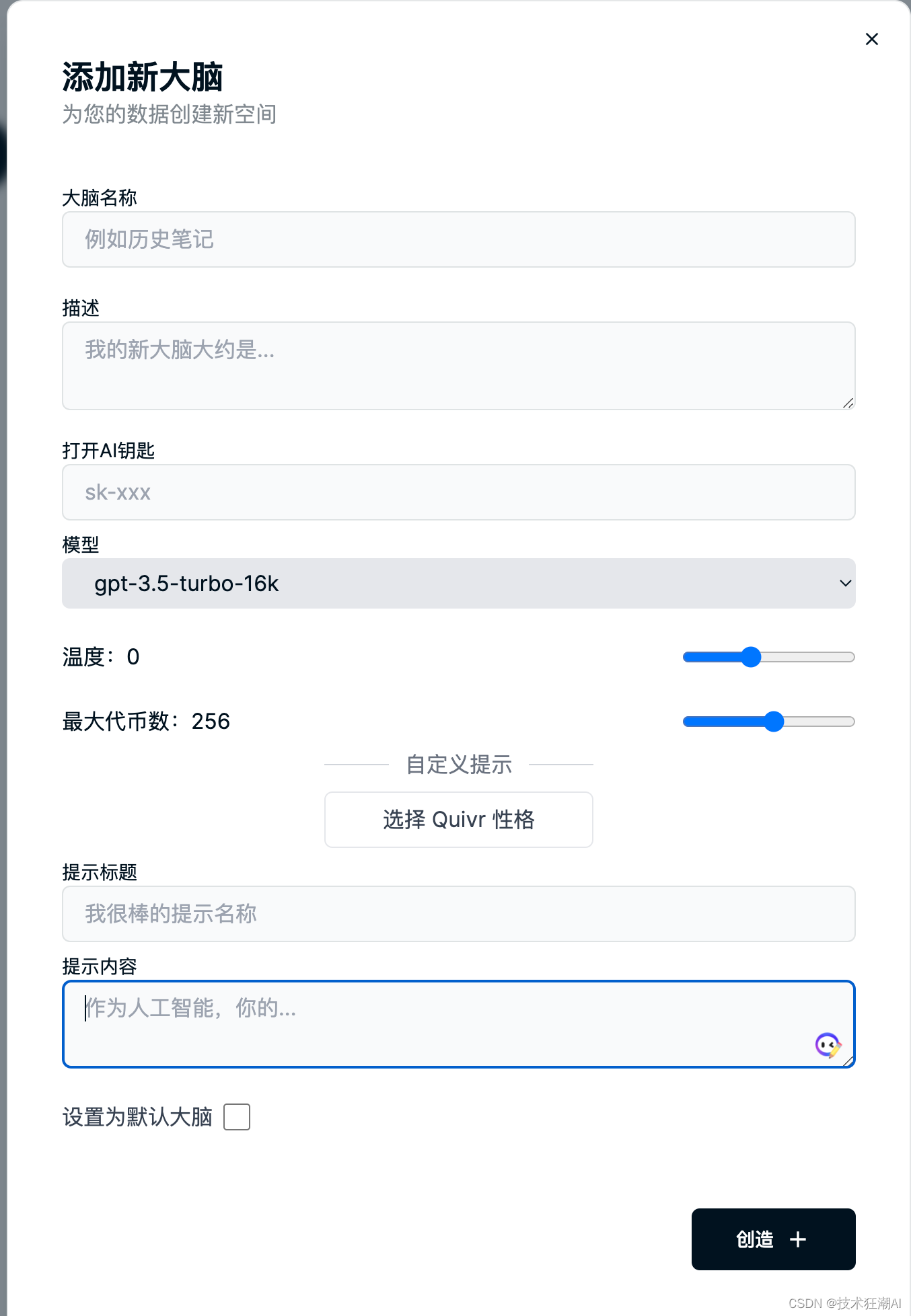
1) 頭を使うには、Quivr インターフェースの右上隅にあるヘッダーにある「頭を使う」アイコンからメニューを選択するだけです。
2) 「Create Brain」ボタンをクリックすると、新しい Brain を作成できます。脳の名前の入力を求められます。アカウントによって生成されたデフォルトの脳を使用することもできます。
3) 別のブレインに切り替えるには、メニューでブレイン名をクリックし、使用するブレインを選択します。
4) ブレインを選択していない場合、アップロードしたファイルはすべてデフォルトのブレインに追加されます。
5) 新しい Brain ナレッジ ベース インターフェイスでは、使用するモデルとモデル関連のパラメーターを設定することができ、同時に、ナレッジ ベース ブレインごとに固有のプロンプトと使用する OpenAI API キーを設定することもできます。これを設定すると、デフォルトで設定が読み取られ、ファイルに設定されたキーが読み込まれます。
注: チャット機能を使用している場合は、チャット機能を使用する前にメニューからブレインを選択する必要があります。
6.2. 共有知識ベース
ブレイン選択インターフェイスでは、ブレインの後ろにある共有ボタンをクリックして共有するか、他のユーザーをブレインに参加させ、URL または電子メールを通じてナレッジ ベースを共有するように招待します。
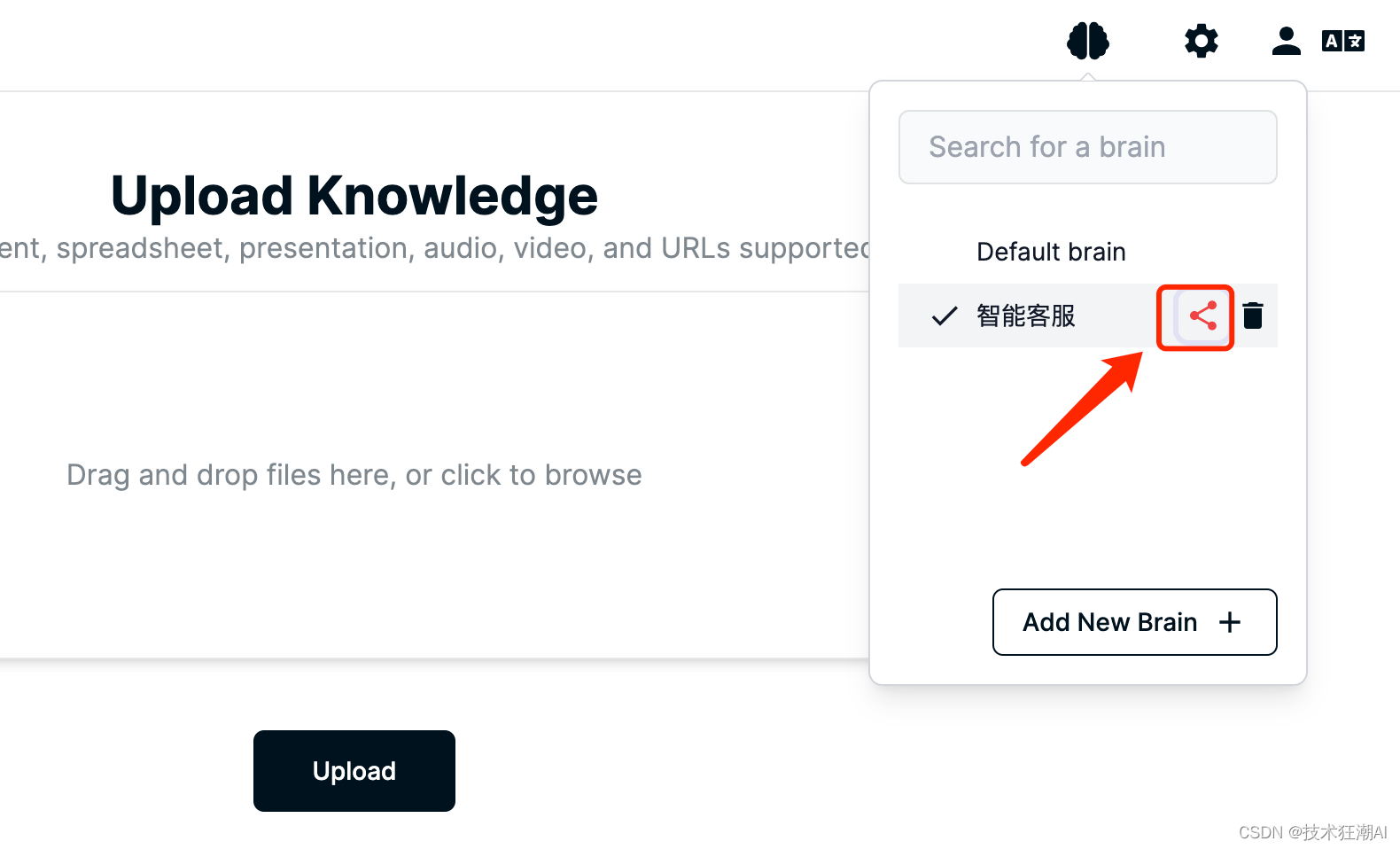

Quivr は、電子メールの招待を介して共有ブレインを処理するための Resend API を統合します。
メール送信機能を構成するために、/backend/core/.env ファイルに 2 つの環境変数が導入されています。
-
RESEND API KEY : これは、アプリケーション用に Resend によって提供される一意の API キーです。これにより、安全な方法で再送信プラットフォームと通信できるようになります。
-
再送信電子メールアドレス: これは、再送信によって電子メールを送信するときに送信者アドレスとして使用する電子メール アドレスです。
環境変数から Resend API キーと電子メール アドレスを取得した後、それを使用して resend.Emails.send メソッドで電子メールを送信します。
6.2. ナレッジベースのアップロード
ナレッジ ベース ブレインを作成した後、対応するナレッジ ベースを選択し、ドキュメントをアップロードしてベクター データ、サポート ドキュメント、オーディオ、ビデオ、および Web ページのリンクを構築できます。最終的にすべてのファイルは、ファイル内のテキスト コンテンツを抽出し、大規模モデルデータのAPI。
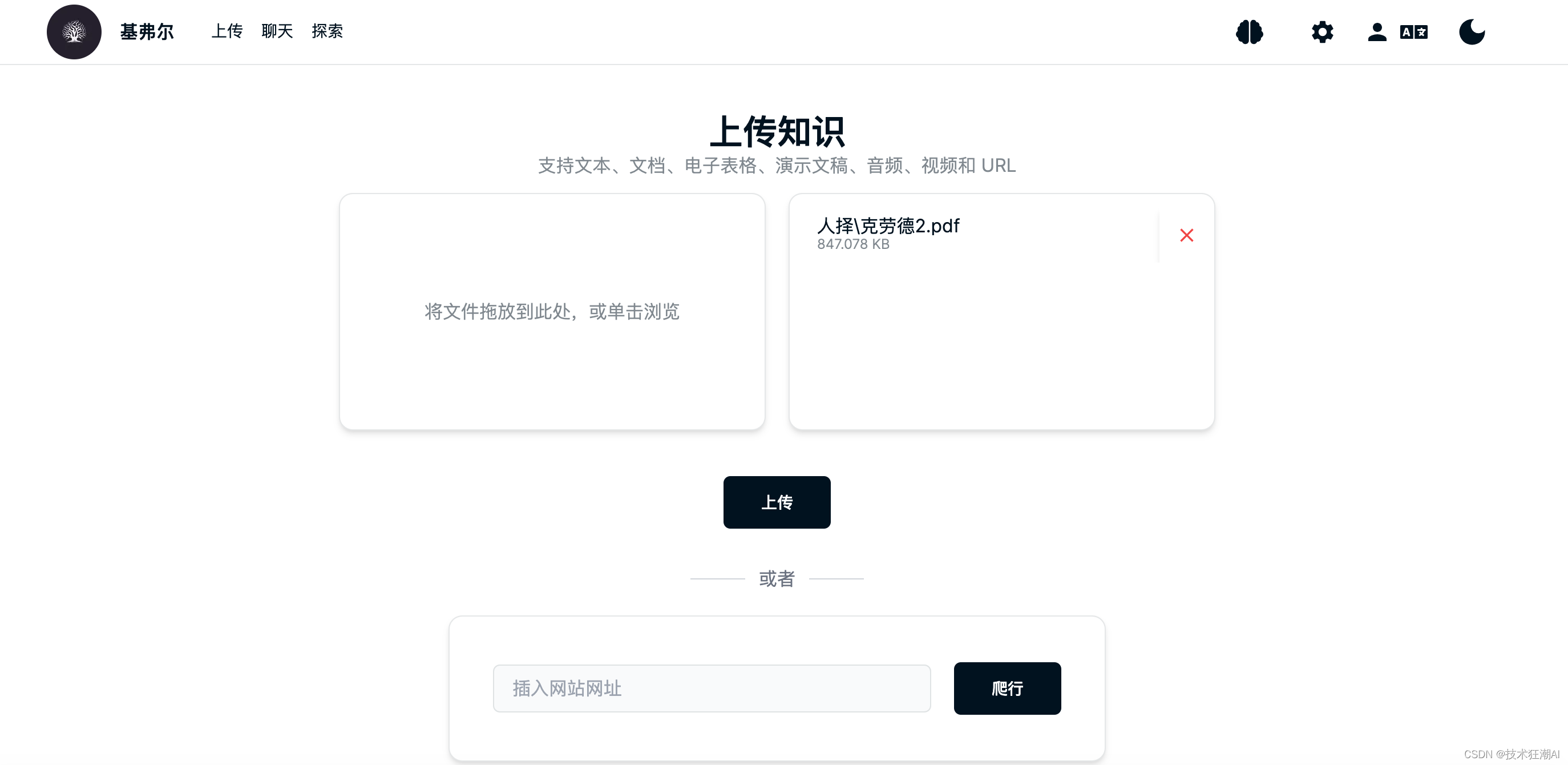
ファイルのアップロードが完了すると、次のプロンプトメッセージが表示されます

6.3、クエリナレッジベース
ナレッジ ベース ドキュメントの構築後、現在選択されているナレッジ ベース ブレインのコンテンツを検索できます。ここでは、日本に留学中の魯迅先生の藤野氏を例に、Quivr がナレッジ ベースのコンテンツを正しく認識するかどうかをテストします。ナレッジベースのドキュメント。 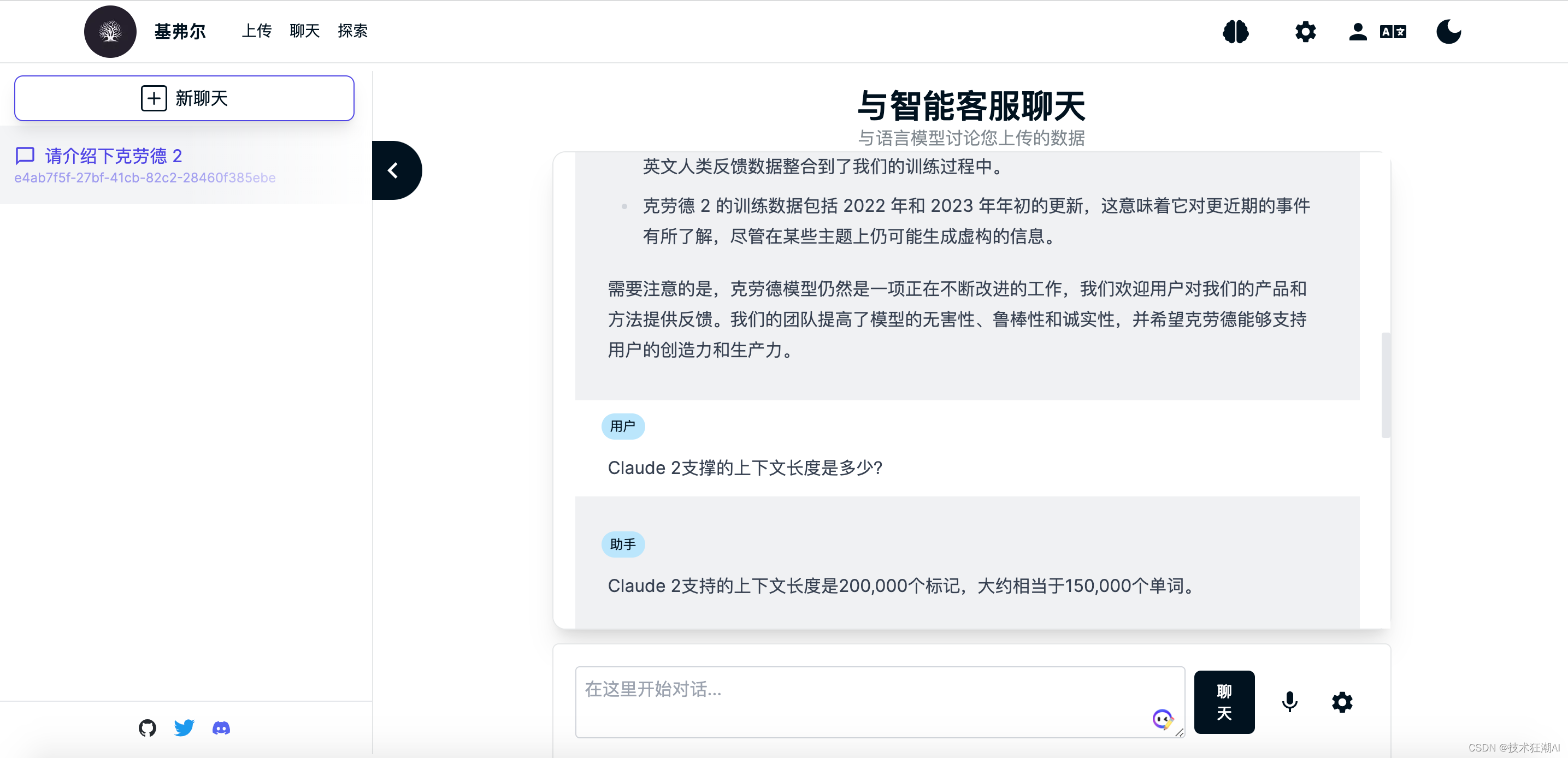
独自の知識を学ぶ前、GPTモデルは日本で医学を学んだ魯迅氏の先生が誰であるかを知らず、通常はランダムに日本の名前を名乗り、何度も尋ねましたが、その生活は一貫していませんでした。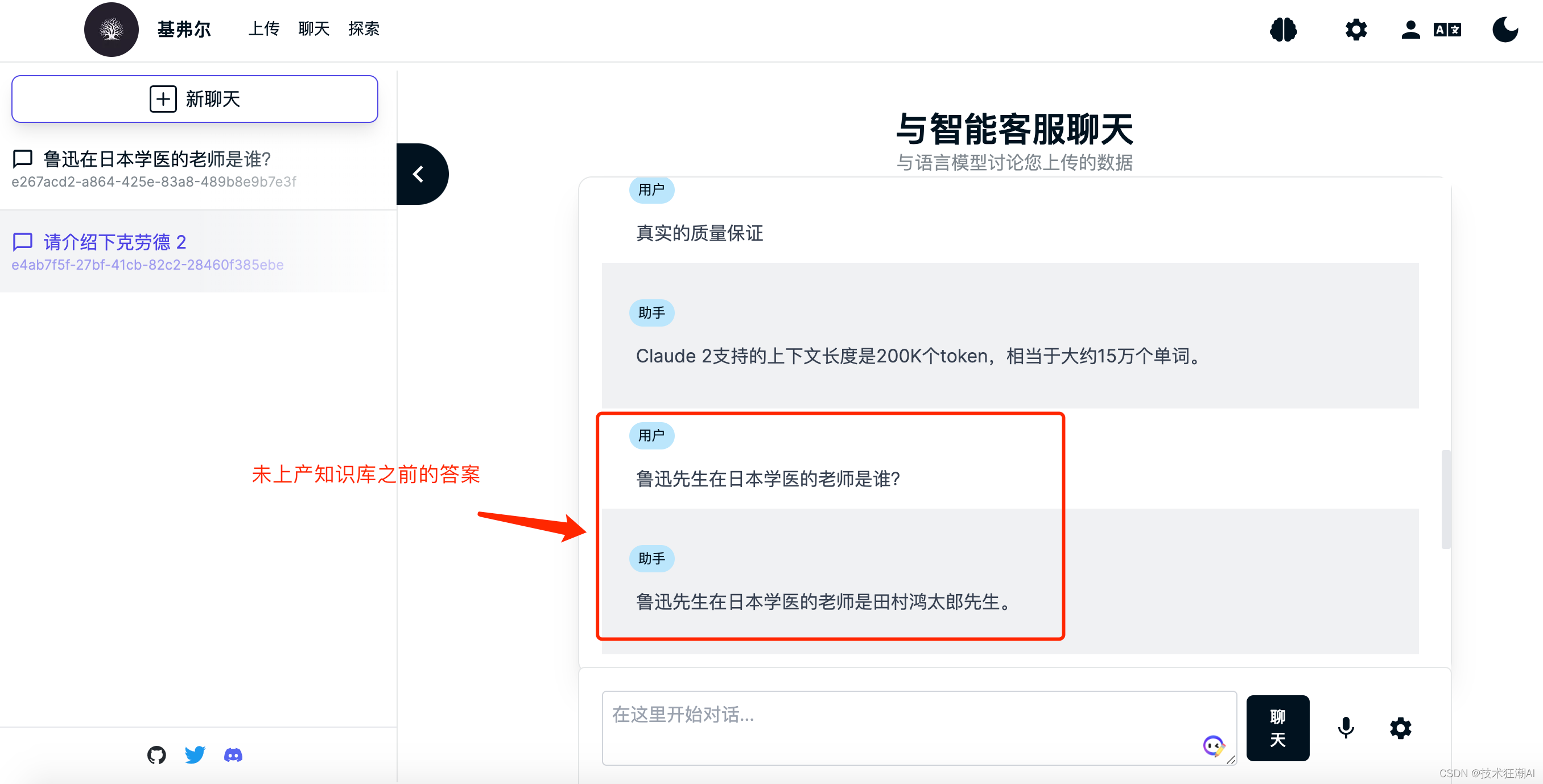 魯迅氏の「藤野氏」に関する記事の一部をアップロードした後、再度質問してみたところ、無事に正解を取得できた。
魯迅氏の「藤野氏」に関する記事の一部をアップロードした後、再度質問してみたところ、無事に正解を取得できた。 
7. ローカライズされた LLM サポート
Quivr は、バージョン 0.0.46 でローカル LLM ラージ モデルへのアクセスを正式にサポートできます。現在、GPT4All でサポートされているプライベート LLM モデルのみをサポートしています (他のオープン ソース モデルは間もなく開始されます)。これは基本的に PrivateGPT プロジェクトによって提供される機能と同様です。 。データは常にローカルに保存されることを意味します。LLM がサーバーにダウンロードされ、問題に対してローカルで推論が実行されます。
7.1. 使用方法
-
/backend/core/.envファイルの「private 」プロパティを True に設定します。.env ファイルで他のモデル パラメーターを設定することもできます。
-
GPT4All モデルのダウンロード アドレス: https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin
ダウンロードした GPT4All モデルを /backend/local_models フォルダーに配置します。
GPT4All は、誰でも日常のハードウェア上で強力なカスタム大規模言語モデル (LLM)をトレーニングおよび展開できるオープン ソース ソフトウェア エコシステムです。Nomic AI は、オープンソース エコシステムへの貢献を監督し、品質、セキュリティ、保守性を確保します。
GPT4All ソフトウェア エコシステムは、次の Transformer アーキテクチャと互換性があります。
-
Falcon -
LLaMA(含むOpenLLaMA) -
MPT(含むReplit) -
GPT-J -
Replit - Replit Inc. の Replit アーキテクチャに基づく
-
StarCoder - BigCode に基づく StarCoder アーキテクチャ
サポートされているモデルの特定のリストは、GPT4All Web サイトから完全なリストを確認したり、サポートされているモデルをダウンロードしたりできます。これらのアーキテクチャのいずれかを使用してトレーニングされたモデルはすべて、すべての GPT4All バインディングを使用してローカルで、およびチャット クライアントで量子化して実行できます。gpt4all バックエンドに貢献することで、新しいバリアントを追加できます。
7.2. 今後の予定
Quivr は、ネイティブの民営化 LLM 機能にさらに多くのモデルを追加する予定です。Hugging Face のローカル埋め込みモデルを使用して、OpenAI API への依存を軽減します。将来的には、フロントエンドと API でプライベート LLM モデルを使用する機能も追加される予定です。現在のバージョンは、バックエンドがデプロイされている場合にのみ使用できます。
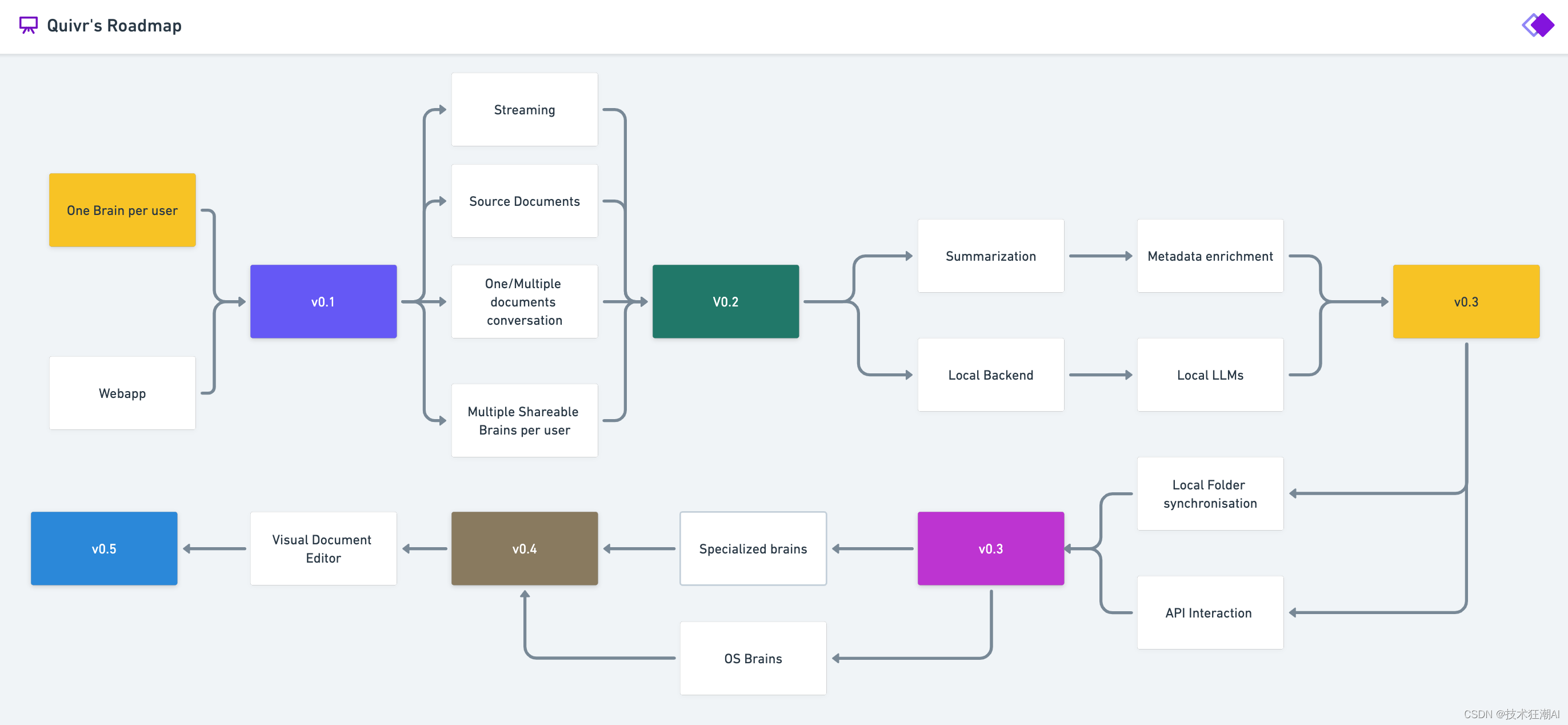
8. Quivr ロードマップ
九、参考資料
- Quivr GitHub
https://github.com/StanGirard/quivr
- Quivr FastAPI
https://api.quivr.app/docs
- APIを再送信する
https://resend.com/概要
- 6月の分析
https://analytics.june.so/
- GPT4All ウェブサイト
https://gpt4all.io/index.html
- GPT4全モデル
https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin
- GPT4全対応モデル
https://raw.githubusercontent.com/nomic-ai/gpt4all/main/gpt4all-chat/metadata/models.json