文章
以下の文章の内容については、著者:Chen Siyu、教育経済学、西南大学、電子メール:[email protected]
アントン・コリネク、経済研究のための言語モデルと認知自動化。NBER、2023 年。
ChatGPT などの大規模言語モデル (LLM) は、経済学やその他の分野の研究に革命をもたらす可能性があります。私は、アイデア出し、執筆、背景調査、データ分析、コーディング、数学的導出という 6 つの領域に沿って、LLM が研究助手と家庭教師の両方として有用になり始めている 25 の使用例を説明します。一般的な手順を示し、LLM 機能を実験的な機能から非常に有用な機能まで分類しながら、それぞれを活用する方法の具体的な例を示します。私は、継続的な進歩により、これらすべての領域で LLM のパフォーマンスが向上し、LLM を利用してマイクロタスクを自動化する経済研究者の生産性が大幅に向上すると仮説を立てています。最後に、経済研究における LLM による認知自動化の長期的な影響について推測します。
「経済学研究のための言語モデルと認知自動化」
目次



1. 概要
本稿では、大規模言語モデルの機能を着想、記述、背景調査、データ分析、プログラミング、数学的導出の6つの領域に分け、これらにおける大規模言語モデルLLMの役割と実用性を25の事例を用いて説明します。 6つのエリア。この文書では、LLM の役割を実験的、有用、非常に有用な 3 つのレベルに分けています。この論文では、LLM の継続的な開発により、上記 6 つの領域における LLM のパフォーマンスが向上し、LLM を使用してマイクロタスクを自動化する経済研究者が生産性を大幅に向上できるようになると仮説を立てています。最後に、この論文は経済学における LLM を研究することによってコグニティブ オートメーションの長期的な重要性を予測します。
2. はじめに
1. 研究の背景
大規模 LLM の最近の進歩は、経済学やその他の分野の研究に革命をもたらす可能性があります。LLM はボトルネックを突破したばかりで、幅広い認知タスクで役立つようになりました。2022 年 11 月 28 日に Open AI によってリリースされた GPT3.5 モデルは、リリースから 2 か月以内に 1 億人以上の顧客を獲得し、GPT3 .5 では、人間が印刷した作品と同等の量のテキストを作成するのに 14 日かかります。(トンプソン)。Google と Microsoft は、ユーザーに LLM へのアクセスを提供することを計画しています。
2. 研究目的
1) 生産性の向上
この記事では、最近の研究に基づいた最新の LLM モデルの 25 の例を説明します。著者の実験を経て、本稿ではLLMの機能を着想、執筆、背景調査、データ分析、コーディング、数学的導出の6種類に分類した。この記事では、これらの機能の使用手順を説明し、具体的な例を使用して説明します。さらに、この記事では、LLM の各機能を実験的なものから非常に役立つものまで分類しようとしています。(29 ページの表 1 を参照)。この文書では、この説明が他の研究者が LLM の機能を使用するのに役立つことを願っています。現在、論文では LLM が最も有用なツールであると考えています。LLM は、研究者が 1 日に何度も取り組む小さな「マイクロタスク」を自動化しますが、人間の研究助手に割り当てるには小さすぎます。LLM は高速でトランザクション コストが低いため、このようなタスクに適しています。さらに、LLM は、コーディングやデータ分析タスク、アイデア出しや執筆にも役立ちます。研究者は、LLM をワークフローに組み込むことで、生産性を大幅に向上させることができます。
2) 将来のLLMの機能を予測する
LLM の現在の機能を研究すると、将来の世代の LLM の機能を予測できます。近年、最先端の LLM のトレーニングに使用される計算量 (計算能力) は 6 か月ごとに平均 2 倍になり、LLM の機能が急速に成長しています。こうした進歩は今後も続き、より堅牢な LLM システムが間もなくリリースされることが広く予想されています。長期的には、この論文は、LLM が認知自動化の時代に突入する可能性があり、それは経済学やその他の分野における科学の進歩に重大な影響を与える可能性があると仮説を立てています。さらに、この認知自動化は、認知労働の価値にも明らかな影響を与える可能性があります。
3. 文献レビュー
1) LLM の機能を過小評価する
Bender は、LLM を「ランダムなオウム」(Bender et al., 2021) または「高度なオートコンプリート」と考えています。トンプソン氏の研究によると、「メンサ インターナショナルの元会長は、ChatGPT が言語 IQ テストで 147 点を達成したと報告しました。」人間の知能レベルは比較的静的ですが、LLM は急速に発展しており、新しい反復ごとに変化します。強力な。
2) LLM の機能を過大評価する
他の研究者は、ChatGPT は人工汎用知能 (AGI)、つまり人工知能であると考えています。LLM は、コンテンツが完全に間違っている場合に権威あるスタイルのテキストを生成する可能性があり、読者をだまして誤ったコンテンツを信じ込ませる可能性があります。
この論文では、LLM はコンテンツの生成において比較優位性をますます高めており、現在では人間がコンテンツの評価と識別において比較優位性を持っていると主張しています。LLM は、大量のテキストの処理においても超人的です。これらの機能により、人間と機械の協力が容易になります。
3、大規模言語モデル LLM
1.ベーシックモデル
ボンマサニ氏は、LLM を 2020 年代の人工知能の新しいパラダイムと見なすことができる基本モデルのクラスであると考えています。基本モデルは、パラメータ数が 1011 程度であり、さらに増加している大規模な深層学習モデルです。研究者は豊富なデータに基づいてモデルを事前トレーニングして基盤を作成し、その後、微調整と呼ばれるプロセスを通じてさまざまなアプリケーションに適応させます。たとえば、チャットボット (ChatGPT など) またはコンピューター コードを生成するシステム (Codex など) として機能するように LLM を微調整します。OpenAI の GPT-3.5、DeepMind の Chinchilla、Google の PaLM と LaMDA、Anthropic の Claude は、最先端の LLM です。
基本モデルの事前トレーニングでは、自己教師あり学習のプロセスで大量の計算とデータが使用され、モデルはマスクされたデータを継続的に予測することでトレーニング データに固有の構造を学習します。たとえば、LLM をトレーニングするには、研究者がマスクされた単語を含むテキストのスニペットをモデルに供給すると、モデルは欠落している単語が何であるかを予測するように学習します。これらのデータは、ウィキペディア、科学記事、書籍、その他のオンライン ソースから取得されます。
2. OpenAIが提案するスケーリング則
基本モデルと拡張 LLM は、最新世代の LLM が人間の広範な能力と特定の AI システムの能力の間のギャップを狭めるという点で、前世代の深層学習モデルとは異なります。LLM の全体的なパフォーマンスは、数世代の機械学習モデルの経験則である予測可能なスケーリング則に従って向上します。カプラン氏は、対数損失によって測定される LLM の適合度が、モデルをトレーニングするために実行される計算の数である「トレーニング計算」とパラメーターの数とサイズとともに増加することが、スケーリング則によって観察されると主張しています。ホフマン氏は、スケーリング パラメーターの数と LLM トレーニング データのサイズを比例的に増やすことが最適であると主張しています。
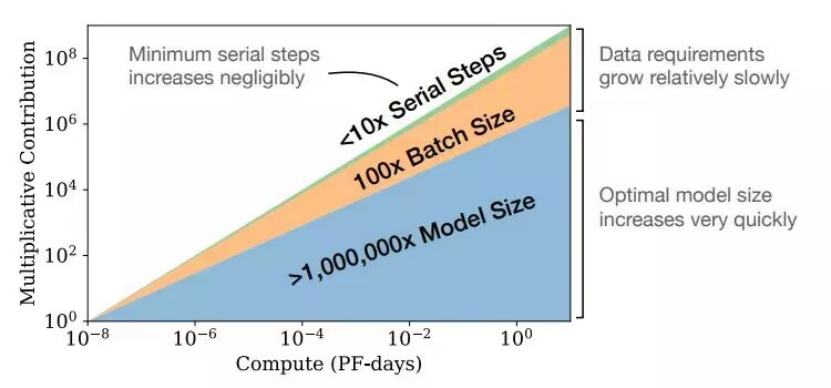
スケーリング ルールについては、「計算に最適な大規模言語モデルのトレーニング」という論文を参照してください。
第四に、LLM の適用
このセクションでは、経済研究における LLM の使用例を、アイデア作成、執筆、背景調査、コーディング、データ分析、数学的導出の 6 つの領域に分けて紹介します。このペーパーでは、ドメインごとに一般的な説明と、LLM の機能を活用する方法を示すいくつかの具体的な使用例を示します。特に断りのない限り、この文書では現在主要な公的システムである GPT-3 (text-davinci-003) を使用します。これは ChatGPT よりもわずかに強力ですが、同様の出力を生成します。再現性を最大限に高めるために、モデルの「温度」パラメーターを 0 に設定します。これにより、システムによって提供される応答が決定的になります。このシステムは 2021 年時点のデータに基づいてトレーニングされており、インターネットにアクセスしない場合、生成されるテキストはトレーニング プロセス中に取得されたパラメーターに完全に基づいています。さらに、システムにはメモリがなく、情報をあるステージから次のステージに引き継ぐことはできません。システムが処理できるテキストの量は 4000 文字未満で、これは約 3000 単語に相当します。LLM によって生成される結果はプロンプトによって異なります。間隔や句読点の違いなど、ヒントの小さな変更によっても、まったく異なる出力が得られる可能性があります。
このホワイトペーパーで紹介するすべてのアプリケーションに共通するのは、LLM の応答時間が速く、トランザクションコストが低いということです。そのため、一部のタスクでは LLM がエラーを起こしやすいにもかかわらず、LLM はマイクロタスクのアウトソーシングに非常に役立ちます。
1. アイデア
1) ブレーンストーミング
研究者は人間の知識の横断面にわたる大量のデータに基づいて LLM をトレーニングするため、LLM は定義されたトピックに関連するアイデアや例のブレーンストーミングに非常に役立ちます。
この記事はLLMに対し、「人工知能の進歩が不平等を悪化させる可能性がある経済経路についてブレインストーミングをしてください」と求めている。LLM モデルによってリストされているチャネルは革新的ではありませんが、関連性があり、大部分が妥当であり、この記事で検討しているよりも広範です。ポイント 5 以降、人間のブレインストーミングの傾向と同様に、LLM の創造性が低下し、応答が繰り返されることが論文では観察されています。
2) アイデアを評価する
LLM はさまざまなアイデアを評価することもでき、特にさまざまな研究プログラムの長所と短所を提供します。「AI が不平等に及ぼす影響について論文を書いています。AI がどのように不平等を拡大できるかについての論文と、AI がどのように不平等を削減できるかについての論文、どちらがより役立つと思いますか?」というテキストを入力します。
LLM モデルからの回答は、AI がどのように不平等を増大させるかを研究することは前向きな仕事にはより有用であるのに対し、AI がどのように不平等を削減するかを研究することは規範的な仕事にはより有用であることを示唆しています。
3) 反証を提供する
LLM は、特定の観点を支持する議論や反論を提示するのが得意です。これは、人間の脳によくある確証バイアスを排除するのに役立ちます。この論文のケースは「AI は不平等を悪化させる。主な反対意見は何ですか?」です。
LLM によって与えられる反論には、良いものもあれば悪いものもありますが、LLM の出力は、著者が知っている主要な点をカバーしています。
2. ライティング
LLM の中核となる能力はテキスト生成です。LLM は、要点に基づいたテキストの合成、テキスト スタイルの変更、テキストの編集、スタイルの評価、見出しの生成、見出しとツイートの生成など、執筆関連の多くのタスクに非常に役立ちます。
1) 合成テキスト
LLM は、大まかな箇条書きを、適切に構造化された読みやすい文章に翻訳できます。この記事では、「次の議論を統合し、段落を超えたトピック センテンスを書いてください。」という例を使用します。テキストを合成する機能により、研究者は執筆プロセス自体ではなく、エッセイ内のアイデアに集中することができます。LLM は特定のスタイルで記述することもできます。たとえば、上記の例に、「学術的な文体で書く」、「口語的な文体で書く」、「経済学者でなくても理解できる文体で書く」、または「好きな政治家の文体で書く」を追加すると、違いが生じます。LLM は LaTeX 形式でテキストを書くこともできます。
2) テキストを編集する
LLM は、テキスト内の文法またはスペルの間違いを修正し、スタイルを変更し、明瞭さと簡潔さを向上させることができます。この一連の機能は、文章を上達させたいと考えている非ネイティブ スピーカーにとって最も役立ちます。以下の例では、エラーのある各単語とシステムによる修正が太字で強調表示されています。この記事では、「次の文を修正していただけますか?」というコマンドを使用します。
LLM は編集内容を解釈できるため、学生はそこから学ぶことができます。LLM は、さまざまなレベルの読者が理解できるように、さまざまなレベルの読者に応じてテキストを変換することもできます。たとえば、「8 歳の子供でも理解できるように、下のテキストを書き直してください。」を使用します。
3) テキストを評価する
LLM は、テキストのスタイル、明瞭さ、類似性を評価することもできます。しかし、この論文の要約草案に関する次の質問に対する LLM の回答は理想的ではありません。
「次の文章の主な文体の欠点は何ですか?」 「これらの欠点を修正するためにこの文章を書き直していただけますか?」 著者は、LLM によって特定されたすべての欠点に同意します。書き直されたバージョンでは、これらの欠点の一部が軽減されますが、完全に軽減されるわけではありません。このシステムは、「次の議論のうち、理解するのが最も難しいのはどれですか?」のような質問にも答えることができます。
4) タイトルと概要を生成する
LLM は、キャッチーなタイトルや概要を生成できます。以下の例は、最近の論文 (Korinek and Juelfs、2022) の著者の要約によって与えられた 3 つのタイトルに基づいています。
1. 将来を見据えた社会: 自律型機械と労働力の衰退に備える 2. 仕事の終わり? 自動化機械が労働力に与える影響を乗り越える 3. 自律型機械が労働力に与える影響: 仕事と収入をどのように分配するかLLM が提案した 3 つのタイトルはすべて、この論文に適しています。
5) ツイートを生成する
LLM はツイートを生成でき、私たちの実験では、テキストを要約するために 5 つのツイートを書くように LLM に命令しました。
3. 背景調査
1) 文章を要約する
この記事の実験は、テキストを文に要約することです。「大規模言語モデル (LLM) には、経済研究に革命をもたらす可能性があります。この記事では、LLM が役立つ 6 つの分野 (アイデア化、文脈調査、執筆、データ分析、コーディング、数学的導出) について説明します。一般的な説明とその方法を示します。これらのドメインは活用されており、LLM 機能は実験的、有用、非常に役立つものとして分類されています。私は、継続的な進歩により、これらのドメインにおける LLM のパフォーマンスが向上し、LLM を使用してマイクロタスクを自動化する経済性が向上し、人間の生産性が大幅に向上すると仮説を立てています。 , 「私は、LLM を通じて、認知自動化が経済研究に与える長期的な影響について推測します。この論文では、LLM のケースを示し、実証することによって、大規模言語モデルの可能性について議論します。」 LLM が提供する結論文は、すべてのポイントをカバーしています。
2) 文献レビュー
LLM の用途は文献検索に限定されています。LLM は存在しない論文を検索する場合があります。より正確なツールは Web サイト https://elicit.org: で見つけることができます。このサイトは既存の論文のみを報告します。
3) 書式設定の参照
この記事の場合は、「次の参照を bibtex 形式に変換してください」です。次に、APA 形式でフォーマットします。LLM がトレーニング データ セット内で引用度の高い作品、たとえば「stiglitz weiss の bibtex 参照」を見つけた場合、LLM は適切な作品を作成できます。そのため、ユーザーは関連著作物の詳細な引用情報をコピーしたり入力したりする必要はありませんが、引用数が少ない著作物の bibtex 参考文献をシステムが生成すると、論文と引用情報が露骨に改ざんされてしまいます。
4) テキストを翻訳する
Jiao et al. (2023) は、ChatGPT などの LLM は、リソースが豊富なヨーロッパ言語の商用翻訳製品と競合すると主張しています。しかし、リソースが少なく、デジタル化されたテキストやデジタル化された翻訳が少ない言語では、パフォーマンスが低下します。
5) 説明理論
LLM は家庭教師として機能し、多くの一般的な経済概念を非常に明確に説明します。これは、何か新しいことを学ぼうとしている学生や、専門分野のより高度な研究者にとっても非常に役立ちます。この記事のケースは、「操作変数はなぜ役立つのか?」を説明することです。LLM は操作変数については非常によく説明していますが、厚生経済学の第 1 定理と第 2 定理に対する答えは非常に不十分です。
4. プログラミング
GPT3.5 は多くのコンピューター コードでトレーニングされているため、エンコードにおいては非常に強力です。OpenAI の Codex には、code-davinci-002 モデルを通じてアクセスすることも、Copilot として GitHub に統合することもできます。言語モデル text-davinci-003 は code-davinci-002 の子孫であるため、自然言語だけでなくコンピューター コードも生成できます。LLM が最も熟練している 2 つのプログラミング言語は Python と R ですが、基本的な Excel 関数から複雑な C/C++ コードまで、一般的なプログラミング言語であればどれでも動作します。
1) コードを書く
この例は、フィボナッチ数を計算するための Python コードです。このシステムのもう 1 つの例は、グラフィックスの描画です。この記事では、上記のプロンプトを「フィボナッチ数を計算し、最初の 10 個の数値をプロットし、指数曲線と比較する Python コード」に変更します。結果はうまくいきました。
しかし、現在公開されている LLM は、人間の支援なしでほとんどの経済問題、たとえば、最適な消費平滑化や最適な独占価格設定などの基本的な経済問題をシミュレートするための完全なコードを作成できるほど強力ではありません。
2) コードの説明
LLM は、特定のコードが何を行うのかを平易な英語で説明することもできるため、研究者がなじみのないプログラミング言語を使用する場合に特に役立ちます。
3) コードを翻訳する
多くの場合、あるプログラミング言語のコードを別の言語に翻訳する必要があります。たとえば、プロジェクトを別のプラットフォームに移植したり、LLM は、StackExchange などのオンライン コーディング フォーラムで見つかった、便利だが言語が間違っているコード スニペットを変更したりできます。
現在の LLM は、ほとんどの一般的な言語間でショートコードを翻訳するのに非常に優れています。より長いシーケンスの場合、LLM は依然として人間の支援を必要とします。
4) バグを修正する
この記事で使用するケースは、「次のコードのどこが間違っていますか?」です。
LLM は、スペルミスや基本文法の違反を見つけるのに非常に役立ちます。また、この範囲を超える機能もいくつかあります。たとえば、インデックスが混乱している場合に LLM を適用することもできます。コードの基礎となるアルゴリズムのエラーなどの高レベルのエラーの場合、LLM では依然として手動のデバッグが必要です。
5. データ分析
1) テキストからデータを抽出する
この論文では、LLM が書かれたテキストからデータを抽出する方法を実験します。「マークは経済学で A、数学で B+ を取得しました。サリーは経済学と数学の両方で A- を取得しました。フランクは経済学で B、数学で C を取得しました。次のように再フォーマットされます: 経済学の名前と学年、数学の学年。 」
LLM は、電話番号、郵便番号、社会保障番号、クレジット カード番号、銀行口座番号、日付、時刻、価格、パーセンテージ、測定値 (長さ、重量など) の 10 種類のデータも抽出できます。
2) データをフォーマット別に整理する
LLM は、データを必要な形式に変換することもできます。前の例を基にして、LLM はまずデータをカンマ区切り値 (CSV) 形式でフォーマットし、次にそれを LaTeX テーブルとしてフォーマットします。
3) テキストの分類
この論文は、米国労働省の職業情報ネットワーク (O*NET) データベースにある 5 つのタスクを自動化が容易か困難かを分類するよう GPT3.5 に求め、その分類を正当化します。実験結果は、この分類は合理的ですが、完全に堅牢ではないことを示しています。プロンプトの単語が変更されると、基本的に同じ質問に対するシステムの回答も変更されました。
4) アイデアを抽出する
LLM はテキストから感情的な態度を抽出することもできます。たとえば、LLM はツイートを「ポジティブ」または「ネガティブ」に分類できます。同様に、LLM は米国の金利を決定するための連邦公開市場委員会 (FOMC) の声明を分類することができます。委員会はフェデラルファンド金利の目標レンジを引き上げ、米国債、政府機関債、政府機関モーゲージ担保証券の保有を削減した。委員会はインフレ率を2%の目標に戻すことにも断固として取り組んでいる。システムの評価は正しく、それには十分な理由があります。
5) 人間の被験者をシミュレートする
Argyle et al. (2022) は、LLM のトレーニング データには人間に関する多くの情報が含まれていることを観察し、LLM を使用して人間の被験者をシミュレートすることを提案しました。彼は GPT3 を実際の人間の社会人口学的コンテキストに設定し、調査の質問に対するその後の応答が、記述されたコンテキストを持つ人間の実際の応答と高度に相関していることを実証しました。Horton (2022) は、模擬被験者を使用したいくつかの行動実験を再現および拡張することにより、経済学の応用を実証しています。
6. 数学的導出
Noorbakhsh et al. 2021) は、数学的タスクに合わせて LLM を微調整できることを示しました。Frieder et al. (2023) は大学院レベルの数学問題のデータセットを開発し、ChatGPT の数学能力は通常の数学大学院生の数学能力よりも著しく低いと結論付けました。現在の LLM は主にテキストと数学的論文を通じてトレーニングされます。
1) モデリング
この論文では、消費者の購買力を、ある商品については等弾性であり、別の商品については線形であるという LLM を使用して記述し、LaTeX で記述し、変数を価格に割り当てます。このヒントに基づいて、LLM はコンシューマの最適化問題の処理を続行する必要があることを認識します。左の列は生成されたテキストを示し、右の列は LaTeX によってコンパイルされたバージョンを示します。LLM が適切な予算制約を正しく設定し、関連する最大化問題を確立していることがわかります。ラグランジュ方程式では、システムには異常な符号を持つ予算制約が含まれています。3 つの 1 次条件のうち 2 つを正しく導出しましたが、等弾性効用関数の導関数では間違っていました。生成されたテキストを読んでエラーを特定するには時間がかかりますが、LLM は最大化問題とラグランジュ問題を自動的に書き出し、部分最大化問題を数秒で解決するため、貴重な研究時間を節約できます。
2) 導出式
前の例で示したように、LLM は現在、方程式を導出する能力がある程度制限されています。実際、上記の例を続けると、この更新では一次条件のエラーが修正され、システムが剰余を生成する必要があります。システムは最適化問題の解を正確に推定します。
ただし、システムの数学的機能はまだかなり制限されています。正しい解を取得した後、ラグランジアンの符号エラーを修正し、残りの導出を再生成しようとしますが、システムは文字化けを生成します。著者は他のいくつかの導出を試みましたが、エラー率が高すぎてシステムがこのアプリケーションで機能できないことがわかりました。
3) モデルの説明
現在の LLM は、単純なモデルを説明する能力にも限界があります。以下は、有名なバットとボールの問題の背後にある数学を体系的に説明する例です。バットとボールの問題を解き、すべての中間ステップを述べます。プロンプトが異なれば、結果も異なります。LLM は、「思考連鎖プロンプト」として知られる中間ステップを実演するよう求められたときに、より信頼性の高いコンテンツを作成することがよくありました。これは、学生が報告された解決策の背後にある中間ステップを説明するよう求められたときに間違いを犯しにくいのと同様です (Wei et al., 2022b)。
V. 結論
以下の表は、この文書で説明されているすべてのタスク例を、LLM アプリケーションの 6 つのドメインごとに分類してまとめたものです。表の 3 列目には、2023 年 2 月 1 日時点での、記載されている LLM 関数の有用性に関する著者の主観的な評価が報告されています。著者の評価の範囲は 1 から 3 で、1 は LLM の実験的であるが結果に一貫性がなく、人による厳密な修正が必要であることを示しています、2 は有用で時間の節約になる可能性がある機能を示していますが、一貫性がない可能性があり修正には注意が必要です、3 は LLM の能力を示しています。これは、すでに非常に機能的であり、ほとんどの場合期待どおりに動作することを意味します。
1 = 実験的; 結果に一貫性がなく、人間による厳密な監視が必要
2 = 役に立ちます。監督が必要ですが、時間を節約できる可能性があります
3 = 非常に便利です。これらをワークフローに組み込むと時間を節約できます。
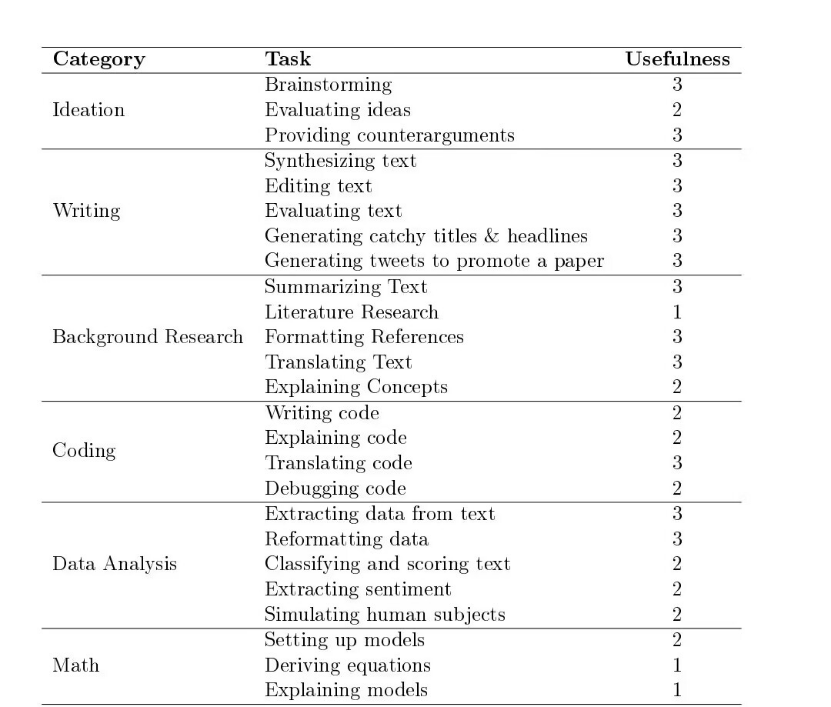
LLM は、アイデア出し、執筆と背景調査、データ分析、コーディング、数学的導出などのタスクに役立つ調査ツールとして登場しました。
短期的には、LLM によるコグニティブ自動化により、研究者の生産性が向上します。これは経済学の全体的な進歩速度を高めるのに役立つかもしれません。
中期的には、LLM は研究論文の内容を生成する上でますます有用になるでしょう。人間の研究者は、アドバイザーと同様に、質問をしたり、回答を得る方法を提案したり、生成されたコンテンツが有用であるかを区別したり、情報を編集してフィードバックを提供したりすることで、比較優位に焦点を当てます。LLM の進歩は、LLM がタスクの実行においてますます優れていることを意味し、人間が入力、編集、フィードバックを提供する必要性が少なくなります。
長期的には、経済学者は AI の進歩から得られる「厳しい教訓」を学ぶ必要があり、サットン氏は次のように説明しています: AI の歴史のほとんどにおいて、研究者は領域固有の知識を AI システムにプログラムすることで AI システムをより効率的にすることに取り組んできました。これは常に短期的には効果があるが、その効果は最終的には横ばいになる、と彼は観察しました。
十分なコンピューティング能力があれば、十分に高度な AI システムが優れた経済モデルを生成して解明できる可能性があり、最終的には人間の経済学者の認知作業が不要になる可能性があります。
六、展望
コグニティブ・オートメーションは、経済学者に次のような新しい研究上の疑問を投げかけます。
1. コグニティブ オートメーションは労働市場にとって何を意味しますか? コグニティブ オートメーションは肉体労働の自動化も加速しますか? 私たちの社会は、今後の変化にどのように備えるのが最善でしょうか?
2. コグニティブ オートメーションが教育に与える影響は何ですか? 人的資本の価値は低下しますか?
3. コグニティブ オートメーションは技術の進歩と経済成長にどのような影響を与えますか? 人間の労働を自動化できた場合、将来の成長のボトルネックは何でしょうか?
4. AI の調整問題を最もよく解決するにはどうすればよいですか?