午前3時30分、眠すぎる、明日の埋め合わせが必要だ…。
最近行ったプロジェクトがキャッシュに関するものなので、参考までにキャッシュに関する記事を書きますが、もし記事内に間違いがあればご指摘いただければ幸いです。
キャッシュには、CPU キャッシュからプロセス内キャッシュ、プロセス外キャッシュまで幅広い範囲が含まれます。しかも、もう午前1時を回っているので、髪の毛を少し残しておかなければいけないのですが、この記事では詳しくは書きません、ごめんなさい。
記事ディレクトリ
CPUキャッシュについて
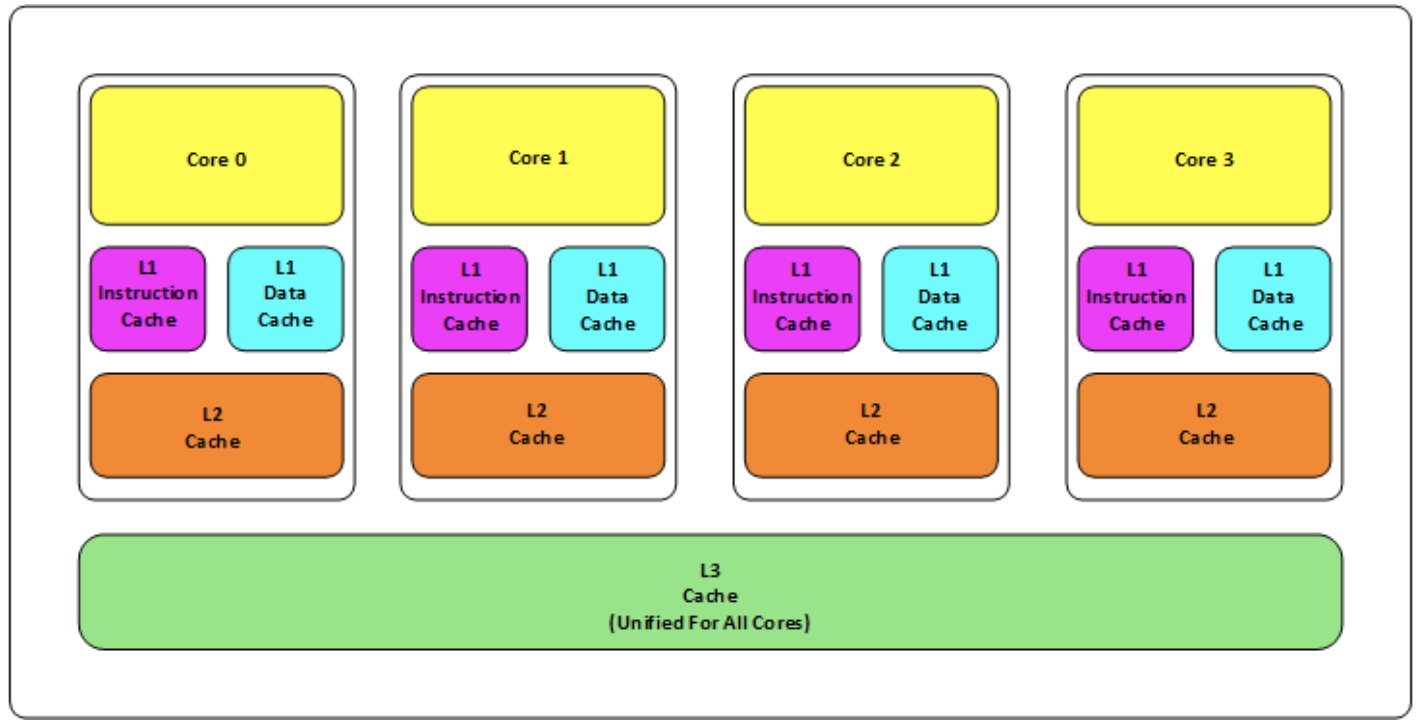
ここで CPU キャッシュについて説明します。キャッシュの中心となる概念は、ヒット、消去、一貫性などのすべてのものであるためです。
CPU については以前にいくつか書き直しましたが、ここでは写真を 1 枚だけ添付します。
ps: 最近、あるメーカーの CPU が 3 レベル キャッシュ アーキテクチャとバス ロックを変更したと聞きました。関連するリソースをお持ちでしたら、送ってください。検討してみます。
マルチレベルキャッシュについて
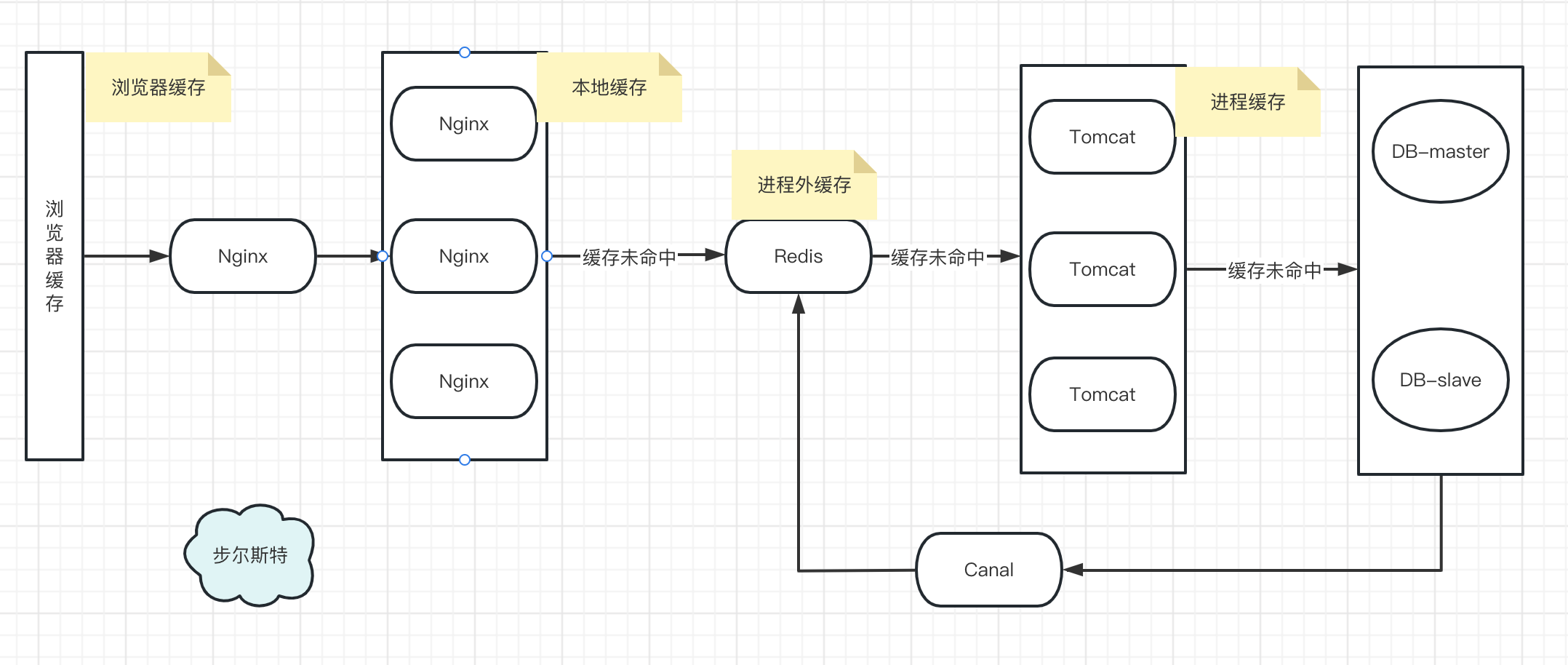
以前にマルチレベル キャッシュの詳細な設計に関する記事を書いたため、この記事の焦点はマルチレベル キャッシュではありません。
簡単な手順:
- ブラウザキャッシュ
- Nginx リバースプロキシ、OpenResty クラスターをロード
- OpenResty は Nginx と Lua をベースにしており、Lua ビジネスコーディングを実装でき、キャッシュパフォーマンスが非常に優れており、JD Technology による圧力テストの比較も行われています。
- OpenResty キャッシュが見つからない場合に Redis をクエリする
- Redis キャッシュが見つからない場合は、プロセス キャッシュをクエリします
- キャッシュと DB の間のデータの一貫性を確保するために、データ同期に Canal と DTS を使用することもできます (Mysql の Binlog と、スレーブを装ったマスター/スレーブの原理に基づく)
2次キャッシュについて
2 次キャッシュのベスト プラクティス: Caffeine + Redis
- 最初に Caffeine に移動し、ヒットしなかった場合は Redis に移動します
- データの一貫性を確保するために、Canal / DTS をデータ同期に使用できます。
- プロセスが Caffeine をキャッシュする場合は、タイミング同期を設定するだけです
パフォーマンスの最適化:
- Caffeine は、並行性をサポートする基礎となる ConcurrentHashMap 構造のため、プロセス キャッシュに使用されます (各プロセス キャッシュのパフォーマンス比較レポートは後で公開されます)
- アウトプロセス キャッシュの場合、私は通常、フォールト トレランスや複数のデータ構造などに基づいて、何も考えずに Redis を選択します。(memcacheとの比較解析などは後日公開します)
J2Cache などの 2 次キャッシュ フレームワークも市販されており、フレームワーク自体は特別な作業を行わず、主に一般的なインプロセス キャッシュとアウトプロセス キャッシュを統合します。
Springベースで開発されている場合、AOPをベースに設計されたSpring Cacheフレームワークは一般的に使用されるキャッシュに適合しており、独自のアノテーションや戦略はビジネスから自然に切り離されており、非常に優れていますが、ここでRedisをどのように統合するかには特別な注意が必要です!!!
Redisを統合する場合、Spring Cacheのクリア戦略はRedisからキャッシュを削除するときにkeys命令を使用するため、keys命令の時間計算量はO(N)です。キャッシュの数が多いと、明らかな障害が発生します。本番環境の Redis ではこのコマンドが無効になり、エラーが発生します。
//keys 指令
byte[][] keys = Optional.ofNullable(connection.keys(pattern)).orElse(Collections.emptySet())
.toArray(new byte[0][]);
if (keys.length > 0) {
statistics.incDeletesBy(name, keys.length);
connection.del(keys);
}
したがって、DefaultRedisCacheWriter (キャッシュの追加、削除、変更などのロジックを内部的にカプセル化する Spring Cache によって提供されるデフォルトの Redis キャッシュ ライター) を書き換えることができます。
キーコマンドの代わりにスキャンコマンドを使用してください
//使用scan命令代替keys命令
Cursor<byte[]> cursor = connection.scan(new ScanOptions.ScanOptionsBuilder().match(new String(pattern)).count(1000).build());
Set<byte[]> byteSet = new HashSet<>();
while (cursor.hasNext()) {
byteSet.add(cursor.next());
}
byte[][] keys = byteSet.toArray(new byte[0][]);
正直なところ、多値キャッシュや2次キャッシュは、スキルを誇示するために使用しないでください。不要な開発コストや未知の問題が増加する可能性があります。また、データ量の評価も必要です。それは本当にお金の無駄です。
知恵の言葉:ビジネスを組み合わせないテクノロジーはフーリガンです。
インプロセスキャッシュ
インプロセスキャッシュの利点は何ですか?
キャッシュなしと比較した場合、インプロセス キャッシュの利点は、データの読み取りにデータベースなどのバックエンドへのアクセスが必要なくなることです。
アウトプロセス キャッシュ (redis/memcache など) と比較して、インプロセス キャッシュはネットワーク オーバーヘッドを節約するため、第一にイントラネット帯域幅を節約し、第二に応答遅延が低くなります。
インプロセスキャッシュの欠点は何ですか?
データがサイトやサービスの複数のノードにキャッシュされ、データが複数のコピーに保存されている場合、一貫性を保証することは困難です。
インプロセスキャッシュのデータの一貫性を確保するにはどうすればよいですか?
- 単一のノードから他のノードに通知できます。
- 他のノードは MQ を通じて通知できます。
- 結合を回避し、複雑さを軽減するために、「リアルタイムの一貫性」は単純に放棄され、各ノードがタイマーを開始して、定期的にバックエンドから最新のデータを取得し、メモリ キャッシュを更新します。ダーティ データは、バックエンド データを更新するノードとタイマーを通じてデータを更新する他のノードの間で読み取られます。
インプロセスキャッシュを頻繁に使用できないのはなぜですか?
サイトとサービスのインプロセス キャッシュは、実際には階層化アーキテクチャ設計のステートレス原則に違反しています。
インプロセスキャッシュはいつ使用できますか?
- 読み取り専用データは、プロセスの開始時にメモリにロードされると見なされます。(InitializingBeanを実装します)
- 非常に高い同時実行性を実現するために、透過的な送信バックエンドに極度のプレッシャーがかかっている場合は、インプロセス キャッシュを検討できます。(スパイク)
- データ不整合サービスはある程度まで許可されます。
キャッシュを介したサービス間のデータ受け渡しの誤り
- データ パイプラインのシナリオでは、キャッシュよりも MQ の方が適しています。
- 複数のサービスは単一のキャッシュ インスタンスを共有すべきではなく、垂直に分割して分離する必要があります。
- サービス指向アーキテクチャでは、サービスをバイパスしてバックエンド キャッシュ/データベースを読み取ることはできませんが、RPC インターフェイスを介してアクセスする必要があります。
雪崩バグを考慮せずにキャッシュを使用する
キャッシュがダウンすると、すべてのリクエストがデータベースにプッシュされ、容量が事前に見積もられていない場合、データベースが過負荷になる可能性があり (キャッシュが復元されるまでデータベースが稼働しない可能性があります)、システム全体が停止する可能性があります。使用不能になる。
容量は事前に見積もる必要があり、キャッシュがハングアップした場合でも、データベースはキャッシュを保持できるため、上記の解決策を実装できます。
それ以外の場合は、さらなる設計が必要です。
高可用性キャッシュ クラスター (アクティブおよびスタンバイなど) を使用すると、キャッシュ インスタンスがハングアップした後、自動的にフェイルオーバーできます。
キャッシュ水平セグメンテーションを使用すると、キャッシュ インスタンスが一時停止された後、すべてのトラフィックがデータベースに送信されなくなります。
マルチサービス共有キャッシュインスタンスの不正
- キーの競合が発生し、お互いのデータがフラッシュされる可能性があります (namespace:key を使用してキーを作成し、それらを分離できます)。
- サービスごとに対応するデータ量とスループットは異なり、1 つのインスタンスを共有すると、あるサービスが別のサービスのホット データを搾取してしまう可能性があります。
- インスタンスを共有すると、サービス間の結合が発生します。これは、マイクロサービス アーキテクチャの「データベース、プライベート キャッシュ」の設計原則に反します。
たとえば、私が行ったモノリシック アーキテクチャ プロジェクトでは、Caffeine がキャッシュに使用され、各ビジネスに Caffeine インスタンスが存在します。
キャッシュとデータベース間の不整合の解決策
- マスターとスレーブの同期。
- ツール (DTS/cannal) を通じてスレーブ ライブラリのビンログをサブスクライブすると、スレーブ ライブラリのデータ同期が完了する最も正確な時間を知ることができます。
- ライブラリから書き込み操作を実行した後、キャッシュへの削除を再度開始し、この期間中にキャッシュに書き込まれる可能性のある古いデータを削除します。
キャッシュを最初に操作するか、データベースを最初に操作します
- 読み取りリクエストの場合、最初にキャッシュを読み取り、ヒットがない場合はデータベースを読み取り、その後キャッシュに戻します。
- 書き込みリクエスト
- 最初にキャッシュ、次にデータベース
- キャッシュ、設定の代わりに削除を使用してください
キャッシュ アサイド パターン ソリューション
読み取りリクエストの場合:
(1) 最初にキャッシュを読み取り、次にデータベースを読み取ります。
(2) キャッシュがヒットした場合は、データを直接返します。
(3) キャッシュがミスした場合は、データベースにアクセスし、データをキャッシュに戻します。
書き込みリクエストの場合:
(1) キャッシュを更新する代わりにキャッシュを削除します。
(2) データベースを操作してからキャッシュを削除します。
キャッシュが変更されずに常に削除されるのはなぜですか
改造コストが高すぎるので、何も考えずに削除することを選択するのは大きな問題ではありません
キャッシュ関連のクリーンアップ戦略
FIFO (先入れ先出し)
戦略では、キャッシュ領域が新しいデータのためのスペースを確保するのに不十分な (最大要素制限を超えている) 場合、最初にキャッシュに入ったデータが最初にクリアされます。ポリシー アルゴリズムは主にキャッシュ要素の作成時間を比較します。このタイプの戦略は、データの有効性が必要であり、最新のデータの可用性を確保することが優先されるシナリオで選択できます。
LFU (lessfrequency used)
最も頻繁に使用されない戦略は、有効期限が切れているかどうかに関係なく、要素の使用回数に応じて判断され、使用頻度が低い要素はクリアされて領域が解放されます。ポリシー アルゴリズムは主に要素の hitCount (ヒット数) を比較します。高頻度データの有効性を保証するシナリオでは、このタイプの戦略を選択できます。
LRU (最も最近使用されていない) 最も最近使用されていない
戦略では、有効期限が切れているかどうかに関係なく、要素が最後に使用されたときのタイムスタンプに従って、最も遠い使用されたタイムスタンプを持つ要素をクリアして領域を解放します。戦略アルゴリズムは主に、要素が get によって最後に使用された時間を比較します。これはホット データのシナリオにより適しており、ホット データの有効性を確保することが優先されます。
さらに、次のような簡単な戦略もいくつかあります。
有効期限から判断して、有効期限が最も長い要素をクリーンアップします。
有効期限から判断して、最近期限切れになる要素をクリーンアップします。
ランダム
にクリーンアップします。キーワード (または要素の内容) の長さに応じてクリーンアップします。等
カフェインを選ぶ理由
基礎となるデータ構造、W-TinyLFU アルゴリズム、そしてもちろん各コンポーネントの信頼できるパフォーマンス比較表を使いたくない人はいないでしょう? (Caffeineのソースコードについては、また別の日に別記事で書きます)
Redis を選ぶ理由
理由はありません、何も考えずに選んでください 来週、Redis7 のソースコードについて記事を書きますが、それは理解できると思います。
Redis アプリケーションのベスト プラクティス
- ホーム ページに最新のプロジェクト リストを表示する: Redis はメモリ常駐キャッシュを使用します。これは非常に高速です。LPUSH は、リストの先頭にキーとして格納されるコンテンツ ID を挿入するために使用されます。LTRIM は、リスト内の項目数を最大 5000 に制限するために使用されます。ユーザーが取得する必要があるデータの量がこのキャッシュ容量を超える場合は、リクエストをデータベースに送信する必要があります。
- 削除とフィルタリング: 記事が削除された場合は、LREM を使用してキャッシュから完全に削除できます。
- リーダーボードと関連問題: リーダーボードはスコアによって並べ替えられます。ZADD コマンドはこの機能を直接実現でき、ZREVRANGE コマンドを使用するとスコアに応じた上位 100 ユーザーを取得でき、ZRANK を使用するとユーザー ランキングを取得でき、非常に直接的で操作が簡単です。
- ユーザーの投票と時間で並べ替えます: リーダーボード、スコアは時間の経過とともに変化します。LPUSH および LTRIM コマンドは、記事をリストに追加するために組み合わせて使用されます。バックグラウンド タスクを使用してリストをフェッチし、リストの順序を再計算します。ZADD コマンドを使用して、結果のリストを新しい順序で設定します。負荷の高いサイトであっても、リストは非常に迅速に取得できます。
- 期限切れアイテムの処理: Unix 時間をキーとして使用して、リストを時間順に並べ替えます。current_time と time_to_live を取得すると、期限切れのアイテムを見つけるという大変な作業が行われます。別のバックグラウンド タスクは、ZRANGE...WITHSCORES を使用してクエリを実行し、期限切れのエントリを削除します。
- カウント: IP アドレスがいつブロックされたかを知るなど、さまざまな統計にはさまざまな用途があります。INCRBY コマンドを使用すると、カウントをアトミックにインクリメントすることでこれを簡単に行うことができ、GETSET を使用してカウンターをリセットし、expires 属性を使用してキーを削除する時期を識別します。
- 特定の時間に特定のアイテム: これは訪問者固有の問題であり、ページビューごとに SADD コマンドを使用することで解決できます。SADD は、既存のメンバーをセットに追加しません。
- Pub/Sub: 更新時にユーザーとデータのマッピングを維持することは、システムの一般的なタスクです。Redis のパブリッシュ/サブスクライブ機能を使用すると、SUBSCRIBE、UNSUBSCRIBE、および PUBLISH コマンドを使用してこれを簡単に行うことができます。
- キュー: キューは現在のプログラミングのいたるところにあります。Redis には、プッシュおよびポップ タイプのコマンドに加えて、実行中に別のプログラムによってプログラムをキューに追加できるブロッキング キュー コマンドもあります。