A distributed system refers to a system in which multiple nodes communicate and collaborate through a network. It has the advantages of high availability, high scalability, and high performance, but it also faces some challenges, such as data consistency, fault tolerance, load balancing, etc. . In order to solve these problems, some classic theories and methods have appeared in distributed system design, such as CAP theory, BASE theory, consistency, etc.
CAP theory
CAP theory means that a distributed system cannot satisfy the following three characteristics at the same time:
-
Consistency: All nodes access the same latest copy of data
-
Availability (Availability): Every request can get a non-error response, and the data obtained is not guaranteed to be the latest data
-
Partition tolerance: the system can continue to provide services in the event of network partition or failure
The implication of CAP theory is that in a distributed system, when a network partition or failure occurs, only a trade-off between consistency and availability can be made, and both cannot be guaranteed at the same time. Therefore, designers of distributed systems need to choose appropriate architectures and strategies according to different business scenarios and requirements. For scenarios that require strong consistency, such as bank transfers, you can choose the CP architecture and sacrifice availability; for scenarios that can tolerate a certain degree of data inconsistency, such as social networks, you can choose the AP architecture to ensure availability in the face of a large user group. consistency.
BASE theory
BASE theory is an extension and supplement to CAP theory. It is a summary of the practice of large-scale distributed systems. Its core idea is that even if strong consistency cannot be achieved (CAP's consistency is strong consistency), the application can adopt appropriate way to make the system achieve eventual consistency. BASE is an abbreviation of three phrases: Basically Available (basically available), Soft state (soft state) and Eventually consistent (final consistency).
-
Basically Available: It means that when a distributed system fails, it can still guarantee the availability of core functions, but it may reduce the quality of service, such as response time and system throughput.
-
Soft state: refers to the intermediate state of the data in the distributed system, and this state does not affect the overall availability of the system. The soft state is mainly caused by the delay in data synchronization.
-
Eventually Consistency (Eventually consistent): It means that all nodes in the distributed system can finally reach a consistent state after a certain period of time. Final consistency weakens the requirement for real-time consistency of the system, allowing data inconsistency within a certain period of time.
The BASE theory is a reflection and compromise on the ACID characteristics (atomicity, consistency, isolation, and durability) of traditional transactions. It pursues higher availability and scalability at the expense of strong consistency.
consistency
The consistency problem refers to that in a distributed system, because multiple nodes need to communicate and coordinate through the network, and the network itself is unreliable, there may be delays, packet loss, retransmissions, etc., resulting in different nodes. There are inconsistencies or conflicts in the data. For example, in a distributed database, a consistency problem arises if one client writes a new value to one node and another client reads the old value from another node. Consistency issues will affect the correctness and reliability of distributed systems, so some protocols and algorithms need to be used to solve them.
2PC
Two-phase commit (2PC): It is a protocol that guarantees strong consistency of distributed transactions. It divides the commit process of a transaction into two phases: the preparation phase and the commit phase. In the prepare phase, the transaction coordinator sends a prepare request to all participants, asking them to perform transactions and lock resources, and then waits for their responses; in the commit phase, if the coordinator receives the consent response from all participants, it sends a commit to them If the coordinator receives a rejection response or a timeout from any participant, it sends them a rollback request, asking them to release resources and cancel the transaction.
The advantage of 2PC is that it is simple and efficient. It only needs two phases to complete the transaction commit or rollback, and it can guarantee strong consistency. The disadvantage of 2PC is that it is prone to blockage. If the coordinator or participant fails in the second phase, other nodes cannot know the final state of the transaction and can only wait for the failure recovery or timeout. In addition, 2PC will also occupy more resources, because it needs to lock the resources of all participants in the first phase, and will not release them until the end of the second phase.
3PC
Three-phase commit (3PC): An improvement to 2PC, it divides the transaction commit process into three phases: preparation phase, pre-commit phase, and commit phase. In the prepare phase, the transaction coordinator sends a prepare request to all participants, asking them to perform transactions and lock resources, and then waits for their responses; in the pre-commit phase, if the coordinator receives the consent response from all participants, it sends Pre-submit the request and enter the pre-submit state; if the coordinator receives a rejection response or timeout from any participant, it sends a rollback request to them and enters the abort state; in the commit phase, if the coordinator receives all participants If the coordinator receives a timeout or interruption message from any participant, it sends a rollback request to the remaining participants and enters the abort state.
The advantage of 3PC is that it avoids blocking. It reduces the probability of coordinator or participant failure in the second phase by introducing a pre-commit phase, and can roll back or commit quickly when a failure occurs. The disadvantage of 3PC is that it increases the network overhead, because it needs to send one more round of messages, and needs to maintain a timeout mechanism to handle abnormal conditions. Moreover, 3PC cannot fully guarantee strong consistency.
3PC strong consistency fails because it cannot handle all possible abnormal situations, such as network partition, coordinator failure, participant failure, etc. These abnormal conditions will cause the information between different nodes to be out of sync, resulting in inconsistency of data or state. If during the commit phase, the network is partitioned, causing the coordinator and some participants to lose contact with other participants, then different partitions may have different commit decisions. This will cause data inconsistency.
3PC is a protocol that tries to avoid blocking and deadlock while ensuring strong consistency, but it is not perfect, and it also has its own limitations and defects. Therefore, in the actual distributed system, the 3PC protocol is rarely used, but other more advanced and general consensus algorithms or protocols, such as Paxos algorithm, Raft algorithm, etc. are used. These algorithms or protocols can tolerate any number of node failures and can guarantee linear consistency or eventual consistency.
Paxos
The Paxos algorithm is a distributed consensus algorithm proposed by Leslie Lamport in 1989. Its goal is to be in a network composed of several proposers (Proposer), several acceptors (Acceptor) and several learners (Learner). In the system of , choose a value as the consensus result. The Paxos algorithm is divided into two sub-processes: basic Paxos and majority Paxos.
Basic Paxos refers to selecting a value as the consensus result in a system composed of several proposers and several acceptors. The basic Paxos process is as follows:
-
First, each proposer selects a proposal number (Proposal Number) and a proposal value (Proposal Value), and sends a Prepare message to all recipients;
-
Then, after each acceptor receives the Prepare message, if the proposal number is greater than any number it has seen before, it will reply with a Promise message and promise not to accept any proposal with a number smaller than this value; otherwise, ignore the message;
-
Then, after each proposer receives the Promise message from the majority of acceptors, it selects the largest accepted proposal value (if it exists) as its own proposal value, and sends an Accept message to all acceptors;
-
Finally, after each recipient receives the Accept message, if the proposal number is still greater than or equal to the value it promised before, it will reply the Accepted message and accept the proposal value; otherwise, it will ignore the message. When the majority of acceptors reply the Accepted message, the proposed value is selected as the consensus result.
Majority Paxos refers to selecting a value as the consensus result in a system composed of several proposers, several acceptors, and several learners. The process of majority Paxos is as follows:
-
First, each proposer selects a proposal number and a proposal value, and sends a Propose message to a leader (Leader);
-
Then, the leader collects the Propose messages of all proposers, and selects a maximum proposal number and an arbitrary proposal value as its own proposal, and sends a Prepare message to all acceptors;
-
Then, after each recipient receives the Prepare message, if the proposal number is greater than any number it has seen before, it will reply with a Promise message and promise not to accept any proposal with a number smaller than this value; otherwise, ignore the message;
-
Finally, the leader sends a Learn message to all learners after receiving the Promise message from the majority of recipients, and notifies them of the consensus result. When most learners receive the Learn message, the proposed value is selected as the consensus result.
The advantage of the Paxos algorithm is simplicity and efficiency. It only needs two rounds of messages to complete a consensus on a value, and it can guarantee linear consistency. The disadvantage of the Paxos algorithm is that it is difficult to understand and implement, it involves multiple actors and multiple sub-processes, and it needs to deal with various possible situations. The Paxos algorithm is also not suitable for dynamically changing systems, because it needs to know the number and identity of all nodes in advance.
Raft
The Raft algorithm is a distributed consensus algorithm proposed by Diego Ongaro and John Ousterhout in 2013. Its goal is to select a leader in a system composed of several nodes and maintain the system through the leader. state. The Raft algorithm divides the system into three roles: leader, follower and candidate, and maintains the state of the system through heartbeat and log replication.
The process of Raft algorithm is as follows:
-
First of all, all nodes are started as followers. If a follower does not receive the heartbeat message from the leader within a period of time, it will consider the leader to be invalid and become a candidate to initiate an election;
-
Then, each candidate sends a voting request to other nodes and votes for itself. If a candidate receives votes from a majority of nodes, it becomes the new leader and sends a heartbeat message to other nodes; another candidate or leader, abandon the election and convert to a follower;
-
Next, each leader is responsible for receiving the client's request and appending it as a log entry to its own log, and then sending a log replication request to other nodes asking them to write the log entry into their own log;
-
Finally, after each follower receives the log replication request, if the log entry matches its own log, it will write it into its own log and reply with a confirmation message; otherwise, it will reply with a rejection message. When a leader receives the confirmation message from the majority of nodes, it marks the log entry as committed and applies it to its own state machine; then sends a commit notification to other nodes asking them to apply the log entry to itself in the state machine.
The advantage of the Raft algorithm is that it is easy to understand and implement. It divides the system into three roles and maintains the state of the system through heartbeat and log replication. The disadvantage of the Raft algorithm is that there may be a high network overhead, because it needs to send heartbeat messages frequently and needs to synchronize the logs of all nodes. The Raft algorithm is also not suitable for high concurrency scenarios, because it only allows one leader to handle all requests.
Easy-Retry
After explaining the common consensus protocols and algorithms above, the blogger introduces EasyRetry, an open source distributed consensus solution.
Easy-Retry is a distributed service retry component implemented based on the idea of BASE, which aims to ensure the final consistency of data through the retry mechanism. It provides functions such as console task observation, configurable retry strategy, execution callback after retry, and rich alarm configuration. Through these methods, abnormal data can be comprehensively monitored and played back, thereby greatly improving data consistency while ensuring high availability of the system.
core advantages
data persistence
Data security in core scenarios in the system is a very important means of guarantee. Based on the memory retry strategy (currently the well-known SpringRetry or GuavaRetry in the industry are implemented based on memory retry), data persistence cannot be guaranteed. EasyRetry provides There are three retry modes: local retry, server retry, local retry and server retry. EasyRetry's local retry scheme still retains the strategy of memory retry to deal with quick compensation in the case of transient unavailability. The server-side retry implements data persistence and supports multiple database configurations. Users can manage abnormal data through the console, customize multiple configurations, and complete data compensation operations conveniently.
Guarantee distributed transactions based on compensation mechanism
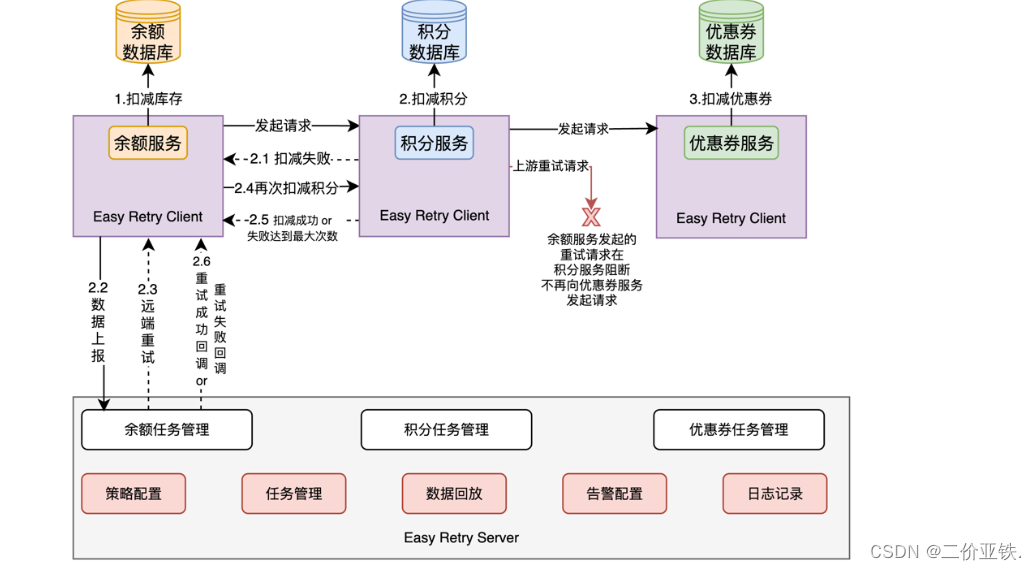
In a distributed system, we can use EasyRetry to capture and process abnormal data, and collect abnormal data generated by different systems to the console of EasyRetry for configuration and management. Through EasyRetry, we can customize the retry strategy and trigger time. When the retry task is executed successfully or reaches the maximum number of executions configured by the system, the server will send a callback request to the client. After receiving the callback request, the client can specify subsequent actions. For example, when the server initiates retries to reach the maximum number of requests but still fails, the client can perform a rollback operation to ensure the integrity of the transaction. By flexibly configuring the processing method of callback requests, we can perform corresponding processing operations according to specific business needs.
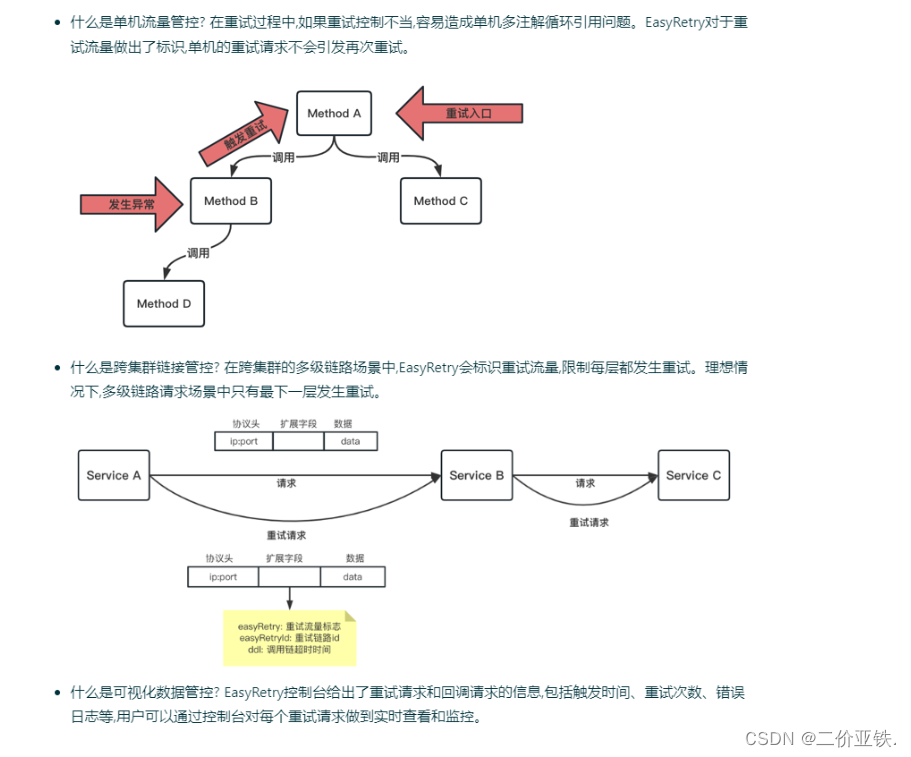
Avoid retry storms
Retry operations can be more lightweight and low-cost to ensure data consistency, but the risks it brings cannot be ignored, that is, retry storms. EasyRetry supports multiple methods to prevent retry storms, such as stand-alone traffic control, cross-cluster link control, and visualized data control.
Simple access
Both EasyRetry and SpringRetry are implemented based on annotations. You only need to add a @Retryable to complete the access. For the specific access method, please refer to the access guide
Configuration diversification
The EasyRetry console provides a variety of parameter configurations, including routing strategies, Id generation modes, partition designation, backoff strategies, maximum number of retries, and alarm notifications. Meet the configuration requirements of users in different scenarios.
scalability
EasyRetry reserves a large number of custom scenarios, such as retry result processors, custom method executors, idempotent ID generators and other modules, which reserve scalable space for users and can meet the needs of different scenarios according to system requirements .