Due to the lack of knowledge of the blogger, after a period of study, he can only understand the basic level. This article will explain the graph convolutional neural network algorithm in a more general way. The next article will explain the code implementation part!
Article directory
GCN-Graph Convolutional Neural Network Algorithm Introduction and Algorithm Principle
3. The principle of GCN algorithm
3.2 Propagation formula of GCN
GCN-Graph Convolutional Neural Network Algorithm Introduction and Algorithm Principle
1. Where does GCN come from
The concept of GCN was first proposed at the International Conference on Learning Representation (ICLR) in 2017, and was written in 2016:

Neural networks have shown amazing results in various traditional tasks, such as: the results of CNN convolutional neural network series in the image field (such as image recognition), and the RNN cyclic neural network series on sequence data (language processing). Effect.
The convolution operation in the traditional convolutional neural network can only process regular data structures, such as pictures or languages, which belong to the data of the Euclidean space, so there is the concept of dimension. The characteristic of the data in the Euclidean space is that the structure is very regular. But in real life, there are actually many, many irregular data structures, typically graph structures, or topological structures, such as social networks, chemical molecular structures, knowledge graphs, etc.; even languages are actually complex internally. A tree structure is also a graph structure.
2. What does GCN do
The GCN graph convolutional neural network, in fact, has the same function as the convolutional neural network CNN, which is a feature extractor, except that its object is graph data . GCN has cleverly designed a method of extracting features from graph data, so that we can use these features to perform node classification, graph classification, and link prediction on graph data. By the way, the embedded representation of the graph (graph embedding) can be obtained, which shows that it has a wide range of uses.
The graph data here does not refer to pictures, but data with a graph structure:

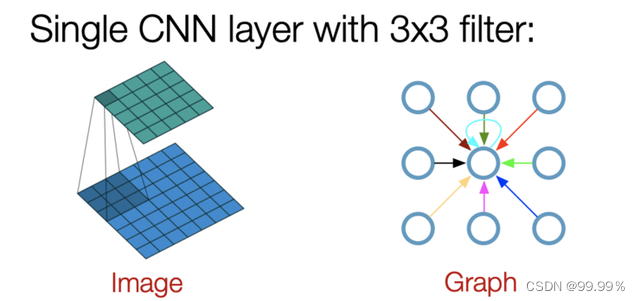
3. The principle of GCN algorithm
Assume that there is a batch of graph data, in which there are N nodes (nodes), each node has its own characteristics, assuming that there are a total of D characteristics, we set the characteristics of these nodes to form an N×D-dimensional matrix X, and then each node The relationship between will also form an N×N-dimensional matrix A, also known as the adjacency matrix (adjacency matrix). X and A are the inputs to our model.
The steps of the GCN algorithm can be simply summarized as follows:
first step clustering
Step two update
The third cycle
For each node, we obtain its feature information from all its neighbor nodes when clustering, including its own features of course.
for example
We want to estimate a person's salary level through clustering
Because there is a famous chicken soup "the average salary of your circle of friends is your salary"
Assume first: the average salary of all friends of a person is equal to the salary of that person, using the associated information (edge edge) in the social network (graph graph), we can get the effective information of the node

The current node can be inferred from neighboring nodes. We first consider using the sum of adjacent nodes to represent the current node:

If the edges in the graph have no weight, Xj is the eigenvalue of each node, and Aij, that is, the relationship between nodes can only be 0 or 1. When a node is not a neighbor node of i, Aij is 0.
Then we write Aij as an adjacency matrix A describing the relationship between nodes, and we can get:

But no weight is obviously inappropriate, because if I met Ma Yun once, we just know each other, but Ma Huateng and Ma Yun are close buddies, then the weight of the connection between me and Ma Yun and the weight of the connection between Ma Huateng and Ma Yun are both set to 1 It is unreasonable, so when dealing with problems, Aij must be any value from 0 to 1, so that my salary level can be calculated scientifically.
And it is unscientific to only consider the salary level of friends. For example, if some people can flatter their leaders, their salary will be higher than that of colleagues who do not have the skills to flatter.
Therefore, in order to accurately evaluate his salary, some characteristics of his own must be added. In the matrix is to add the self-connection matrix I:

So far, we have scientifically summed the salaries of our friends based on the characteristics of the nodes, then we need to take the average
Because it may be that some high-skilled techies have few friends but are all rich, while some people are good at socializing and have many good friends. Although the salary of good friends is low, they can’t stand many
So you need to average, the formula for averaging:

The denominator is the number of nodes, the numerator is the node characteristics, and then summed.
So far, we have obtained the salary level of a person by calculating the average. Of course, the simple average is definitely incomplete;
If my friend has only one boss, then the relationship network between me and the boss will be equivalent if the average algorithm is used, so it is definitely inappropriate to directly assign the characteristics of B to A
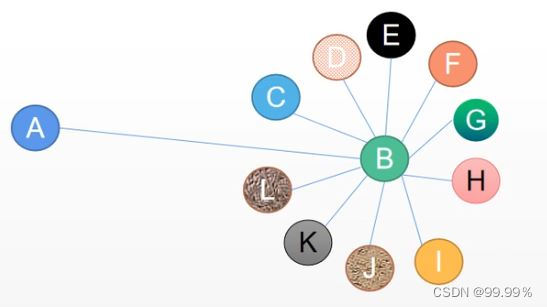
The propagation formula in GCN can solve this problem:
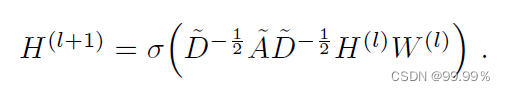
3.1 Structure of GCN
GCN is a multi-layer graph convolutional neural network. Each convolutional layer only processes first-order neighborhood information. By stacking several convolutional layers, information transmission in multi-order neighborhoods can be achieved .
Starting from the input layer, the forward propagation passes through the operation of the graph convolution layer, and then the operation of the softmax activation function to obtain the predicted classification probability distribution.
The role of softmax is to probabilize the output of the convolutional network. I directly understand Softmax as calculating the category of sample points based on the formula.
Suppose we construct a two-layer GCN, and the activation functions use ReLU and Softmax respectively, then the overall forward propagation formula is:

The model is actually composed of input layer + hidden layer (graph convolutional layer, similar to the fully connected layer) + SoftMax + output layer. The GCN model is visualized as:

GCN inputs a graph, and the feature of each node of GCN changes from X to Z through several layers. However, no matter how many layers there are in the middle, the connection relationship between nodes, that is, the adjacency matrix A, is shared.
3.2 Propagation formula of GCN
GCN is a neural network layer. The input of each layer of GCN is the adjacency matrix A and the feature H of the node. The propagation method between its layers is :

The feature matrix x in the figure below is equivalent to H in the formula (the initial feature matrix is given data or obtained by vectors such as tf-idf):

In this formula:
A wave=A+I, I is the identity matrix, which is equivalent to the adjacency matrix of the undirected graph G plus self-connection (that is, each vertex and itself plus an edge)
In this way, when the message is aggregated, not only the messages from other nodes can be aggregated, but also the messages of the node itself can be aggregated.

D wave is the degree matrix of A wave, and the formula is D wave ii=∑j A wave (in an undirected graph, the degree of a node is the number of edges connected to the node.)
H is the feature of each layer. For the input layer, H is X (given initially)
σ is a nonlinear activation function like Softmax, ReLU
W is the parameter of each layer model, which is the weight multiplied by the model to the node features. This is the parameter that the model needs to train, that is, the weight matrix
The operation between them is to multiply each matrix, and part of the content looks like this:


In fact, what we need to focus on is the part of the red line above, that is, the symmetrically normalized Laplacian matrix. The Laplacian matrix is a symmetric matrix that can perform eigendecomposition (spectral decomposition)


Going back to the original question, this formula will take into account the degree of node B, so A will not be assigned many features of B, because A is just one of thousands of friends to B, and the denominator will become larger.
Summarize
GCN is based on the average method, adding normalization for each node degree.
Each layer of GCN multiplies the adjacency matrix A and the feature matrix H(l) to obtain a summary of the characteristics of each vertex neighbor, and then multiplies a parameter matrix W(l), plus the activation function σ to perform a nonlinear transformation to obtain Aggregate the matrix H(l+1) of adjacent vertex features.
The reason why an identity matrix I is added to the adjacency matrix A is because we hope that the characteristic information of the vertices themselves will be preserved when the information is propagated. The normalization operation D^(-1/2)A*D on the neighbor matrix A wave is to maintain the original distribution of the feature matrix H in the process of information transmission, and prevent some high-degree vertices and low-degree vertices from There is a large difference in the feature distribution.
In short, GCN has designed a very subtle formula, which can be used to extract the characteristics of graph data well.
The extracted features can be used for node classification, node relationship prediction and other work.