序文
Koordinator は、Alibaba Cloud がこれまで構築してきた統合スケジューリングシステムで蓄積した技術と実践経験をベースにオープンソース化した新世代のスケジューリングシステムです。Koordinator は、Kubernetes 上のさまざまなワークロードのハイブリッド スケジューリングをサポートします。その目標は、ワークロード (遅延の影響を受けやすいワークロードやバッチ タスクを含む) の実行時の効率と信頼性を向上させることです。コーディネーターは、部門が混在するシナリオに優れているだけでなく、ビッグデータや AI トレーニングなどのタスク スケジューリング シナリオもサポートしています。この記事では、Koordinator を使用して異種リソース管理およびタスク スケジューリング シナリオをサポートする実際の経験を共有します。
AI/LLM は新たな機会と新たな課題をもたらす
2022 年 11 月の ChatGPT のリリースから現在に至るまで、ChatGPT が集めた注目と影響力は、情報技術の歴史におけるほぼすべてのホットスポットを超えている可能性があります。多くの業界専門家がその虜になっており、例えば、Alibaba Cloud の CEO、Zhang Yong 氏は、「すべての業界、アプリケーション、ソフトウェア、サービスは、大規模モデルの機能に基づいてやり直す価値がある」と述べ、NVIDIA CEO の Huang Renxun 氏は次のように述べています。それはAI iPhoneの時代をもたらしました。ChatGPT は新時代の到来を告げ、国内外の企業や科学研究機関もこれに続き、自然言語処理、コンピューター ビジョンから人工知能主導の科学研究、生成に至るまで、ほぼ毎週 1 つ以上の新しいモデルが発表されています。 AIなどのアプリケーションが開花し、大型モデルが業務効率化と次の成長ポイントを拓く鍵となる。クラウド コンピューティング、インフラストラクチャ、分散システムに対する同様の需要も来ています。

数百億、数千億のパラメータによる大規模なモデルのトレーニング ニーズをサポートするために、クラウド コンピューティングとインフラストラクチャは、より強力でスケーラブルなコンピューティング リソースとストレージ リソースを提供する必要があります。大規模モデルのトレーニングが依存するコア テクノロジーの 1 つは分散トレーニングです。分散トレーニングでは、複数のコンピューティング ノード間で大量のデータを転送する必要があるため、より高い帯域幅とより低い遅延を備えた高性能ネットワークが必要です。コンピューティング、ストレージ、およびネットワーク リソースのパフォーマンスを最大化し、トレーニングの効率を確保するには、スケジューリングおよびリソース管理システムがより合理的な戦略を設計する必要があります。これに基づいて、インフラストラクチャの信頼性を継続的に強化し、トレーニング タスクの継続的な運用を保証するノード障害回復機能とフォールト トレランス機能を備えている必要があります。
大規模モデルのトレーニングは、異種コンピューティング デバイス (通常はよく知られた GPU) から切り離すことができません。GPU分野ではNVIDIAが依然として優位な地位を占めており、AMDや国内チップメーカーなど他メーカーが追い上げに苦戦している。NVIDIA を例に挙げると、その強力な製品設計能力、確かな技術力、柔軟な市場戦略により、より優れたチップを迅速に発売することができますが、製品のアーキテクチャは、NVIDIA A100 モデルと NVIDIA H100 モデル システムなど、まったく異なります。違いは非常に明らかであり、使用方法には注意が必要な詳細が多数あり、上位レベルのスケジューリング システムとリソース管理システムに多くの課題をもたらします。
Koordinator+KubeDL の強力な組み合わせ
Alibaba Cloud によってサポートされる大規模モデルのトレーニング シナリオでは、Koordinator を使用して、基本的なタスク スケジューリング要件と異種デバイス リソース管理要件を解決します。同時に、KubeDL を使用して、トレーニング ジョブのライフサイクルと、トレーニング ジョブのキューイングとスケジュールの要件を管理します。
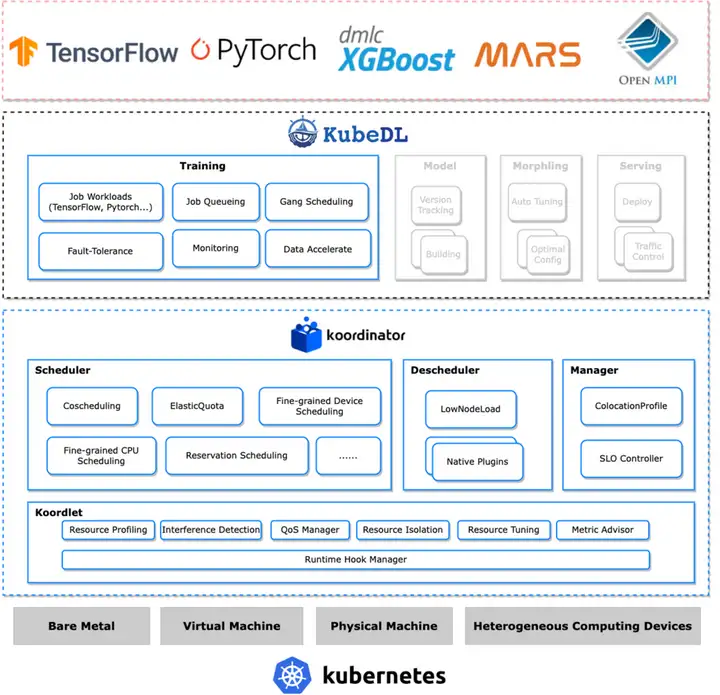
コーディネーターは、混合部門のスケジューリング シナリオに優れているだけでなく、ビッグ データおよび AI モデルのトレーニング シナリオ向けのエラスティック クォータ スケジューリングやギャング スケジューリングなどの一般的なタスク スケジューリング機能も提供します。さらに、きめ細かいリソース スケジューリング管理機能を備え、GPU の集中割り当てをサポートするだけでなく、ハードウェア システム トポロジを認識してリソースを割り当て、GPU と RDMA の共同割り当てとデバイス共有機能もサポートします。
私たちがトレーニング ジョブのライフ サイクルの管理に KubeDL を使用することを選択したのは、KubeDL が社内の AI 分野関連の多数のシナリオをサポートしているだけでなく、その優れた設計と実装、操作性、信頼性、機能の拡張性の恩恵を受けているためです。それらはすべて優れており、これらは、TensorFlow、PyTorch、Mars などのさまざまなトレーニング ワークロードをサポートできる統合コントローラーです。さらに、さまざまなスケジューラが提供する Gang スケジューリング機能にも適応できるため、すでに KubeDL プロジェクトを使用しているストック シナリオをスムーズに Koordinator に切り替えることができます。KubeDL には一般的なジョブ キュー メカニズムも組み込まれており、ジョブ自体のスケジュール設定のニーズを効果的に解決します。
Koordinator と KubeDL の強力な組み合わせにより、大規模なモデルのトレーニングのスケジュール設定のニーズを十分に解決できます。
ジョブのスケジュール設定
ジョブは、通常、特定の計算タスクまたは操作を伴う高レベルの抽象概念です。複数のサブタスクに分割して並行して完了することも、複数のサブタスクに分割して共同で完了することもできます。通常、ジョブは他のワークロードに依存せず、独立して実行できます。さらに、ジョブはより柔軟であり、時間次元、空間次元、またはリソースに関する制約が少なくなります。
ジョブキューイング
ジョブはスケジューラーによってスケジュールされる必要もあります。つまり、スケジュール時にジョブもキューに入れられる必要があります。では、なぜ並ぶ必要があるのでしょうか?あるいは、キューに入れることでどのような問題を解決できるでしょうか?
それは、システム内のリソースが限られており、予算も限られている一方で、ジョブの数やコンピューティング要件が無制限であることが多いためです。キューイングやスケジューリングを行わないと、演算要件が高いジョブや実行時間が長いジョブが大量のリソースを占有することになり、他のジョブが演算に必要なリソースを確保できなくなり、クラスタシステムがクラッシュする可能性があります。
したがって、各ジョブがリソースを公平に取得できるようにし、リソースの競合や競合を回避するには、ジョブをキューに入れてスケジュールする必要があります。
この問題を解決するために、KubeDL が提供する一般的なジョブ キューイングおよびスケジューリング メカニズムを使用します。KubeDL 自体がさまざまなトレーニング ワークロードをサポートしているため、ジョブの粒度に応じたスケジューリングを自然にサポートし、マルチテナント間の公平性保証メカニズムを備えており、ジョブ間のリソース競合や競合を軽減し、キューイングやジョブ間の競合を軽減します。スケジューリング では、KubeDL はコンピューティング要件、優先順位、リソース要件などの要素に基づいてジョブを評価して割り当て、各ジョブがコンピューティングに適切なリソースを確実に取得できるようにします。KubeDL は、フィルター プラグイン、スコア プラグインなどのさまざまな拡張プラグインをサポートしており、さまざまなシナリオのニーズを満たすために機能をさらに拡張できます。
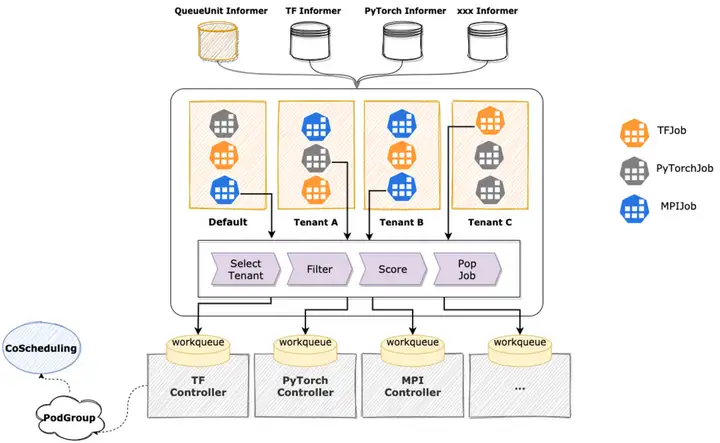
弾性クォータ
ジョブ キューによって解決すべき中心的な問題の 1 つは、リソース供給の公平性です。これは通常、スケジューリング システムの柔軟なクォータ メカニズムを通じて解決されます。
弾力的なクォータ メカニズムによって解決すべき中心的な問題がいくつかあります。まず、公平性を確保することです。これにより、特定のタスクのリソース要求が高くなりすぎて他のタスクが枯渇してしまうことはなく、ほとんどのタスクはリソースを取得できる必要があります。第二に、Elasticity は、現時点でより多くのリソースを必要としているタスクとアイドル クォータを共有でき、リソースが必要になったときに共有リソースを取り戻すことができる必要があります。つまり、柔軟な戦略が必要です。さまざまなシナリオのニーズを満たすために提供されています。
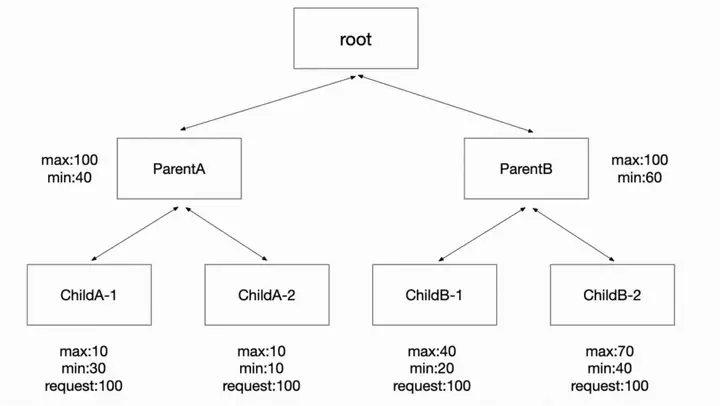
コーディネーターは、テナント間の公平性を保証できる柔軟なクォータ スケジューリング機能を実装します。設計の初めに、既存のクラスターとユーザーがスムーズに Koordinator に移行できるように、スケジューラー プラグイン コミュニティ プロジェクトで定義された ElaticQuota CRD との互換性を考慮しました。
また、ElasticQuota 本来の Namespace に応じた Quota 管理機能に対応するだけでなく、Namespace を越えたツリー構造による管理にも対応しています。この方法は、複雑な組織のクォータ管理ニーズを十分にサポートできます。たとえば、社内に複数の製品ラインがあり、各製品ラインの予算と使用状況が異なります。それらをクォータに変換して管理でき、柔軟性クォータの助けを借りて、一時的に使用されていないアイドル状態のリソースをクォータの形式で他の部門に一時的に共有します。
相互スケジュール
ジョブがキューに入れられ、スケジュールされると、ジョブ コントローラーは、ポッドのバッチである K8 に対応するサブタスクのバッチを作成します。これらのポッドは多くの場合、調整された開始と実行を必要とします。これには、スケジューラがスケジューリング中に Pod のグループに従ってリソースを割り当てることも必要です。この Pod のグループはリソースを申請できる必要があり、そうでない場合、Pod がリソースを取得できないと、スケジューリングの失敗とみなされます。これは、スケジューラが提供する必要がある All-or-Nothing スケジューリング セマンティクスです。
このようにグループに従ってスケジュールを設定しない場合、リソース スケジューリング レベルでの複数のジョブ間の競合により、リソース ディメンションでデッドロックが発生します。つまり、少なくとも 2 つのジョブがリソースを取得できなくなります。元々アイドル状態の場合 リソースがジョブの 1 つを実行するのに十分な場合、そのリソースは使用できません。
たとえば、以下の図では、ジョブ A とジョブ B が同時にバッチのポッドを作成していますが、これらが中央のスケジューリング キューに並べ替えられずにランダムにスケジュールされている場合、ジョブ A とジョブ B のポッドがそれぞれ作成されているように見えます。この時点でクラスターのリソースが不足している場合、ジョブ A とジョブ B の両方がリソースを取得できない可能性が非常に高くなります。ただし、ソート後に、いずれかのジョブのポッドが最初にリソースを割り当てようとすると、少なくとも 1 つのジョブが実行されることが保証されます。
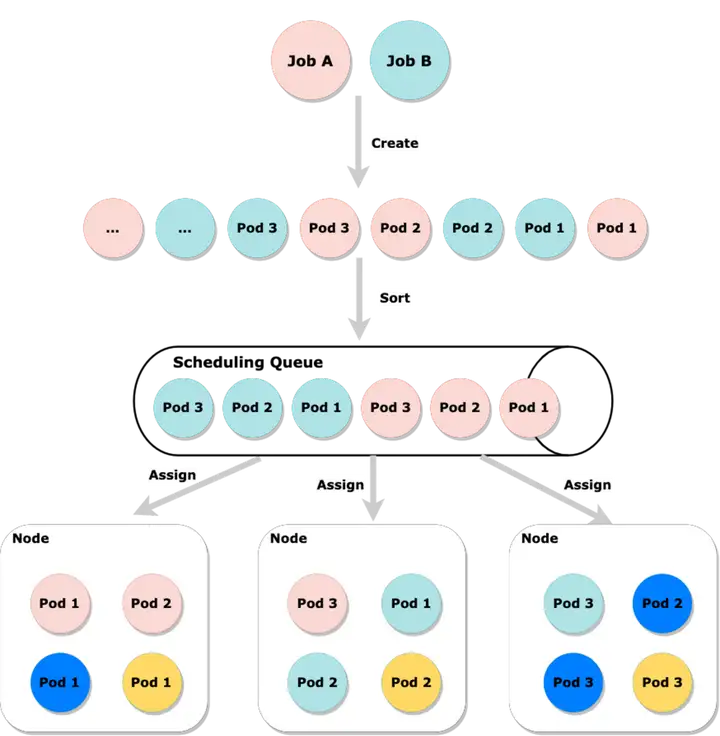
ジョブによって分割された Pod のセットが非常に大きく、クラスター内のリソースが十分でない場合、またはクォータがあまり大きくない場合、そのような Pod のセットは、実行できるサイズのより多くのサブグループに分割できます。タスクに基づいて、ジョブにはグループあたり 3 ポッドの最小分割粒度が必要であると仮定すると、この最小粒度は一般に、スケジューリング ドメインで利用可能な最小粒度と呼ばれます。
特に AI モデル トレーニングの分野では、TFJob などの一部の特殊なジョブのサブタスクには 2 つの役割があり、これら 2 つの役割も実稼働環境で利用可能な異なる最小値で設定する必要があります。異なるロールを区別するこのシナリオでは、All-or-Nothing セマンティクスに準拠しているとみなされる前に、各ロールで利用可能な最小値が満たされる必要がある場合もあります。
Koordinator には組み込みの Coscheduling スケジューリング機能があり、PodGroup CRD を定義するためのコミュニティのスケジューラー プラグイン/コスケジューリングと互換性があり、複数の PodGroup の共同スケジューリングもサポートされているため、使用可能な最小シナリオをロールごとに設定できます。Koordinator は KubeDL Gang Scheduler プラグインを実装しているため、KubeDL と統合してこのようなスケジューリング シナリオをサポートできます。
洗練された設備管理
K8s デバイス管理の制限
K8s は kubelet を介してデバイスの管理と割り当てを担当し、デバイス プラグインと対話してメカニズム全体を実装します。このメカニズムは K8s の初期には十分であり、AMD や国内チップ メーカーなどの他のメーカーもこの機会を捉えました。上。
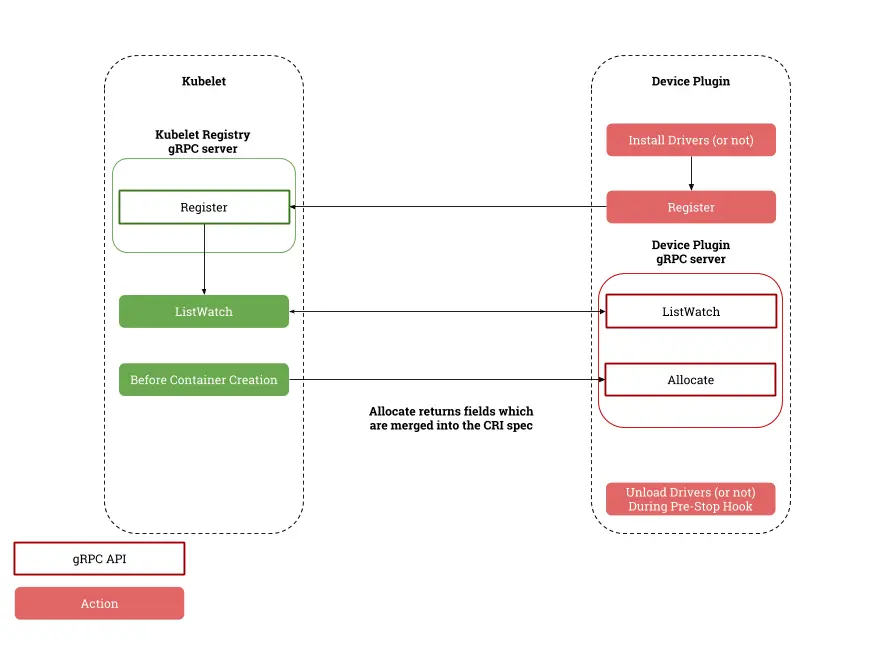
Kubelet とデバイス プラグインのコラボレーション プロセス
まず、K8sではデバイスの割り当てがkubeletでしか行えないため、全体的に最適なリソース配置が得られず、根本的にリソース効率を発揮できません。たとえば、クラスタ内に 2 つのノードがあり、どちらも同じデバイスを持ち、残りの割り当て可能なデバイス数は等しいとします。しかし、実際には、2 つのノード上のデバイスのハードウェア トポロジによって、割り当て可能なデバイスの数に大きな違いが生じます。 Pod の実行時の影響 スケジューラがない 介入の場合、この差を相殺できない可能性があります。
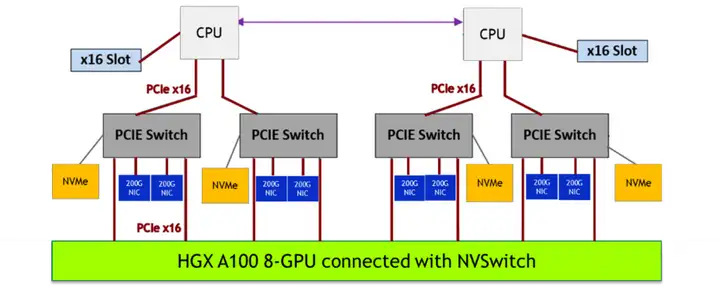
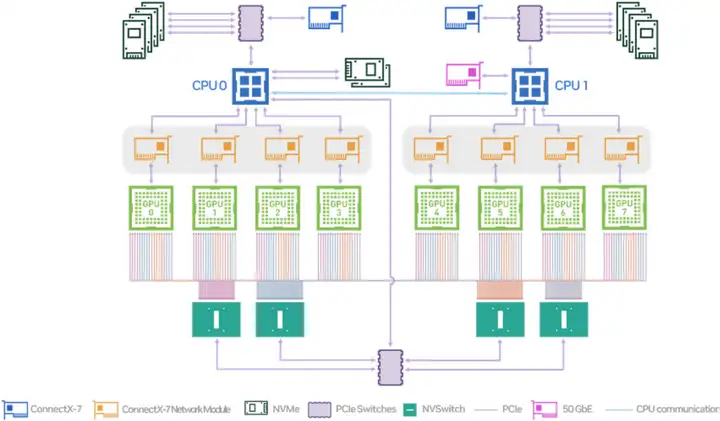
2 つ目は、GPU と RDMA を共同で割り当てる機能をサポートしていないことです。大規模なモデルのトレーニングは高性能ネットワークに依存しており、高性能ネットワークのノード間通信には、RDMA プロトコルと RDMA プロトコルをサポートするネットワーク デバイスの使用が必要です。これらのデバイスは、ノード上のシステム トポロジ レベルで GPU と緊密に連携します。上の図は、NVIDIA の A100 モデルのハードウェア トポロジです。GPU と高性能ネットワーク カードが PCIe スイッチに接続されていることがわかります。低遅延インターバルを実現するには、これら 2 つのデバイスを近くに割り当てる必要があります。 -ノード通信。ここでさらに興味深いのは、複数の GPU を割り当てる必要がある場合、複数の PCIe スイッチが関係する場合、複数のネットワーク カードを割り当てる必要があることを意味します。これは、K8 の別の制限、つまり宣言されたリソース プロトコルに関連しています。任意の変更ではなく、定量的です。つまり、ユーザーは、このポッドに必要な RDMA 対応ネットワーク カードの数を実際には知りません。ユーザーは、必要な GPU デバイスの数のみを知っており、RDMA ネットワーク カードを割り当てることを期待しています。近く。
さらに、kubelet はデバイスの初期化およびクリーニング機能をサポートしておらず、デバイス共有メカニズムもサポートしていません。後者は通常、トレーニング シナリオでは使用されませんが、オンライン推論サービスで使用されます。オンライン推論サービス自体にも明らかな山と谷の特性があり、多くの場合、完全な GPU リソースを占有する必要はありません。
K8 などのノードのデバイス管理機能は時代にある程度遅れており、最新バージョンでは DRA 割り当てメカニズム (既存の PVC スケジューリング メカニズムと同様) がサポートされていますが、このメカニズムは K8 の最新バージョンでのみサポートされています。 , しかし、実際にはまだ多数のストッククラスタが使用されており、K8sの最新バージョンへのアップグレードは簡単な問題ではないため、他の方法を見つける必要があります。
コーディネーターの洗練されたデバイス管理メカニズム
私たちは、これらの問題を解決し、きめ細かいリソース スケジューリングを実現できるコーディネーターのソリューションを提案します。
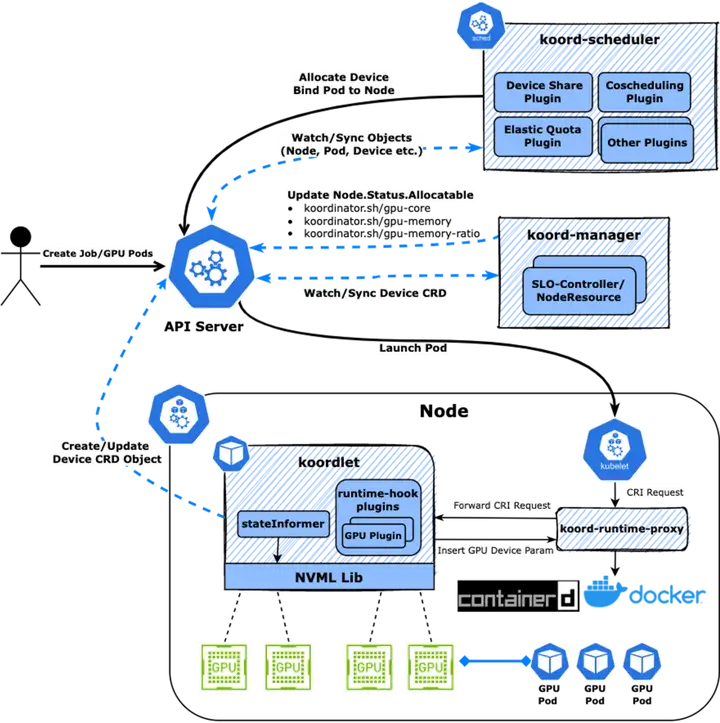
コーディネーターの洗練されたデバイス管理メカニズム
上図からわかるように、ユーザーが作成した Pod は、koordlet から報告された Device CRD に従って koord-scheduler スケジューラーによって割り当てられ、Pod Annotation に書き込まれ、Sandbox と Container が koordlet によって報告されます。中央の kubelet は、containerd/docker への CRI リクエストを開始しますが、Koordinator ソリューションでは、CRI リクエストは koord-runtime-proxy によってインターセプトされ、koordlet の GPU プラグインに転送されます。 Pod Annotation 上でデバイス割り当て結果を認識し、必要なデバイス環境変数などを生成します。情報は koord-runtime-proxy に返され、最終的に変更された CRI リクエストがcontainerd/docker に転送され、最後に kubelet に返されます。このようにして、コンテナ全体のライフサイクルにシームレスに介入して、カスタム ロジックを実装できます。
コーディネーター デバイス CRD は、デバイスのトポロジ情報を含むノードのデバイス情報を記述するために使用されます。これにより、スケジューラーはきめ細かい割り当てロジックを実装できます。
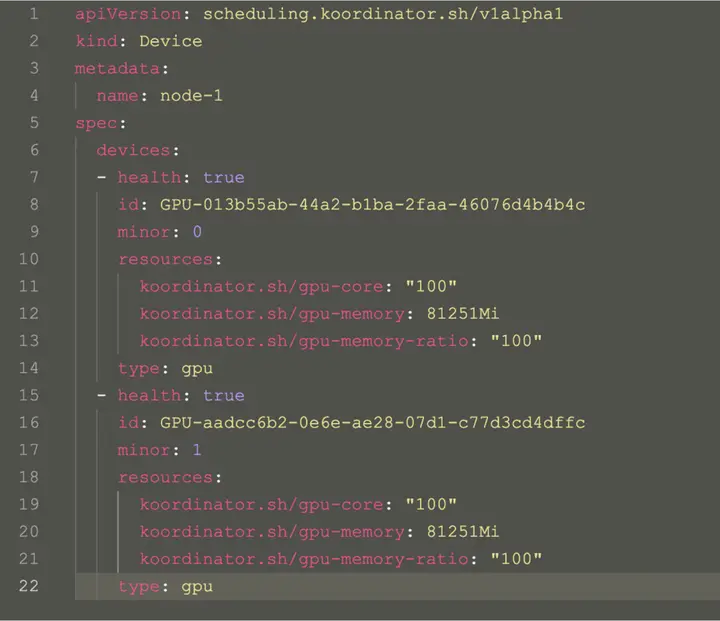
コーディネーターデバイスオブジェクト
将来:NRIモデル
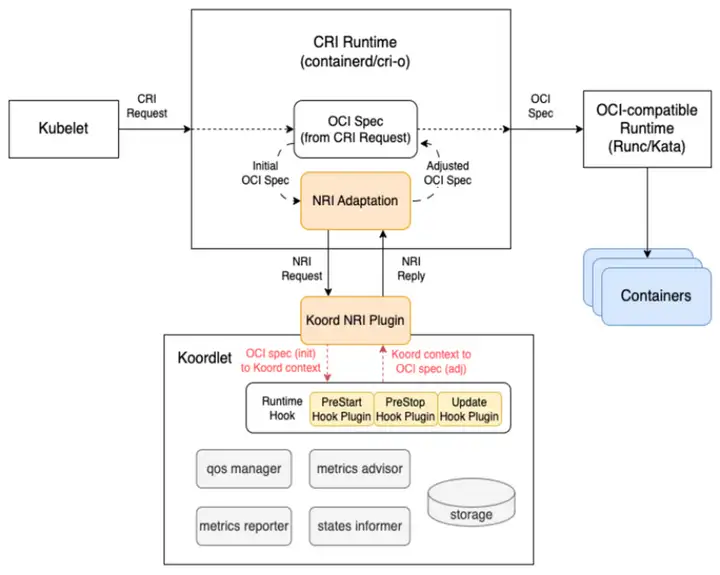
前述したように、Koordinator の単一マシン側は koord-runtime-proxy に依存して連携してデバイス情報の挿入を完了しますが、koord-runtime-proxy メソッドをクラスターに実装するのは簡単ではないことも認識しています。これには、kubelet の起動パラメーターの変更が含まれます。
したがって、コーディネーター コミュニティは、このシナリオの問題を解決するために NRI/CDI などのメカニズムを導入します。この作品は、関連するインテル チームと共同で構築されています。
NRI/CDI は、containerd によってサポートされるプラグイン メカニズムです。そのデプロイ方法はよく知られた CNI に似ており、サンドボックス/コンテナの開始前後にパラメータを変更したり、カスタム ロジックを実装したりする機会をサポートしています。これは、containerd の組み込み runtimeproxy メカニズムと同等です。
GPUとRDMAはハードウェアトポロジーに従って共同で割り当てられます
前述したように、大規模モデルのトレーニングでは GPU を使用するだけでなく、RDMA ネットワーク デバイスにも依存します。GPU と RDMA 間の遅延ができるだけ低いことを確認してください。そうしないと、デバイス間の遅延が分散トレーニング ネットワーク全体に増幅され、全体的なトレーニング効率が低下します。
これには、GPU と RDMA を割り当てるときにハードウェア トポロジを認識し、そのようなデバイスをできるだけ近くに割り当てる必要があります。同じ PCIe、同じ NUMA ノード、同じ NUMA ソケット、クロス NUMA の順に割り当てようとすると、順番に遅延が増加します。
さらに、同じハードウェア メーカーの異なる GPU モデルには異なるハードウェア システム トポロジがあり、スケジューラがこれらの違いを認識する必要があることもわかりました。たとえば、次の図は、NVIDIA A100 モデルのシステム トポロジと NVIDIA H100 の単純なデバイス接続図です。
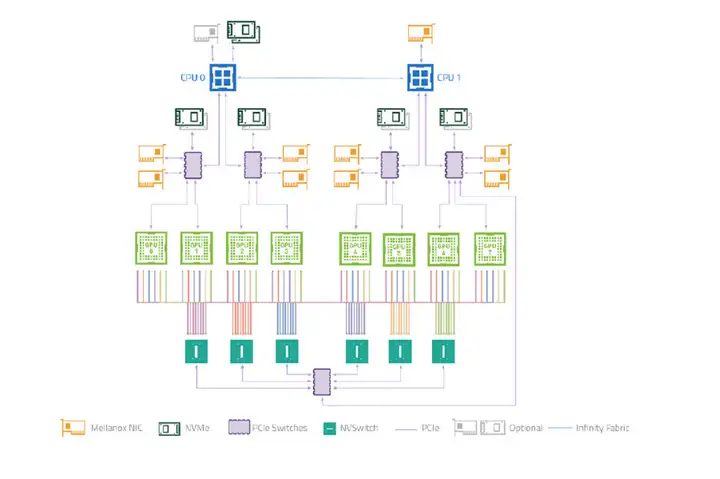
NVIDIA A100 システム トポロジ
NVIDIA A100 GPU と NVIDIA H100 モデルでは、GPU 間の NVLINK 通信方式が異なり、NVSwitch の数も異なるため、利用方法に大きな違いが生じます。
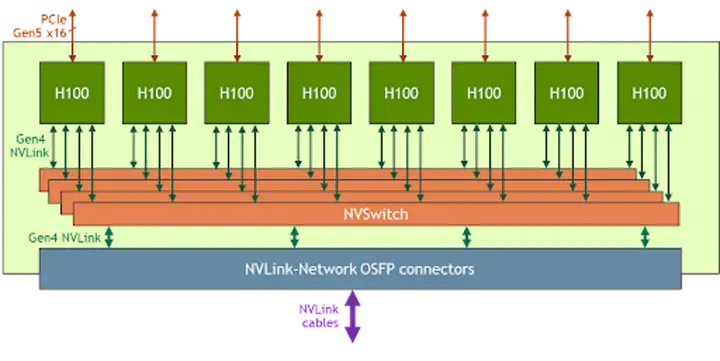
NVIDIA H100
マルチテナントモードにおけるNVIDIAベースのシステムの違い
マルチテナント VM シナリオにおける NVIDIA H100 GPU の特徴は、複数の GPU 間の通信を NVSwitch の動作によって実現する必要があることです。
マルチテナンシーのシナリオでは、NVIDIA は NVSwitch を通じて NVLink の分離ステータスを管理してセキュリティを確保し、NVSwitch の操作には信頼できるソフトウェアのみが必要です。このクレジット ソフトウェアはカスタマイズ可能です。
NVIDIA は複数のモードをサポートしていますが、その 1 つは、GPU と NVSwitch を VM のゲスト OS に直接接続するフル パススルー モードであり、減少します (原文: Reduced NVLink Bandwidth for two and four GPU VMs )。
もう 1 つは、共有 NVSwitch マルチテナント モードと呼ばれます。これは、GPU をゲスト OS に直接接続することのみを必要とし、サービス VM と呼ばれる特別な VM を通じて NVSwitch を管理し、ServiceVM を通じて NVIDIA ファブリック マネージャーを呼び出して NVSwitch をアクティブ化し、相互接続を実現します。 -GPU通信。フル パススルー モードの欠点のため、このモードは表示されませんが、使用方法は明らかに複雑です。この特殊なハードウェア アーキテクチャと使用法により、GPU を割り当てるときに追加の要件がいくつか発生します。NVIDIA は、どの GPU デバイス インスタンスを組み合わせて割り当てることができるかを定義しています。たとえば、ユーザーが 4 つの GPU の割り当てを申請した場合、規則 1、2、3、および 4 または 5、6、7、および8 を一緒にしないと、Pod が実行できなくなります。
この特別な割り当て方法の背後にある理由はわかりませんが、これらの割り当て制約を分析すると、メーカーが規定する組み合わせ関係がハードウェア システム トポロジにぴったり一致しており、期待に応えることができる割り当てであることがわかります。上記の GPU と RDMA の結合割り当ての結果。
NVIDIA H100 システム トポロジ
著者:リータオ(Lv Feng)
クリックして今すぐクラウド製品を無料で試し、クラウドでの実践的な取り組みを始めましょう!
この記事は Alibaba Cloud のオリジナルのコンテンツであり、許可なく複製することはできません。
工業情報化省: 未登録のアプリにはネットワーク アクセス サービスを提供しない Go 1.21 が正式リリースRuan Yifeng が 「 TypeScript チュートリアル」をリリース Vim の父 Bram Moolenaar 氏が病気で死去 自社開発カーネルLinus が個人的にコードをレビュー, Bcachefs ファイル システムによって引き起こされた「内紛」を鎮めることを望んでいます. ByteDance はパブリック DNS サービスを開始しました. 素晴らしい, 今月 Linux カーネル メインラインにコミットしました