データの準備
まずボストンの住宅価格データセットをロードする必要があります。このデータセットには、住宅の特徴情報と、対応する住宅価格ラベルが含まれています。
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
print("数据集大小:{}".format(data.shape))
print("标签大小:{}".format(target.shape))
データ部門
次に、データセットをトレーニング セットとテスト セットに分割します。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data, target, random_state=8)
正規方程式法
正規方程式は線形回帰問題の閉形式の解であり、反復を行わずにパラメータの最適解を直接計算します。このクラスを使用してLinearRegressionモデルをトレーニングし、トレーニング セットとテスト セットのスコア、パラメーター、切片を出力します。
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
print("正规方程训练集得分:{:.3f}".format(lr.score(X_train, y_train)))
print("正规方程测试集得分:{:.3f}".format(lr.score(X_test, y_test)))
print("正规方程参数:{}".format(lr.coef_))
print("正规方程截距:{:.3f}".format(lr.intercept_))
モデルの評価
モデルのパフォーマンスを評価するには、平均二乗誤差と二乗平均平方根誤差を使用します。
from sklearn.metrics import mean_squared_error
y_pred = lr.predict(X_test)
print("正规方程均方误差:{:.3f}".format(mean_squared_error(y_test, y_pred)))
print("正规方程均方根误差:{:.3f}".format(np.sqrt(mean_squared_error(y_test, y_pred))))
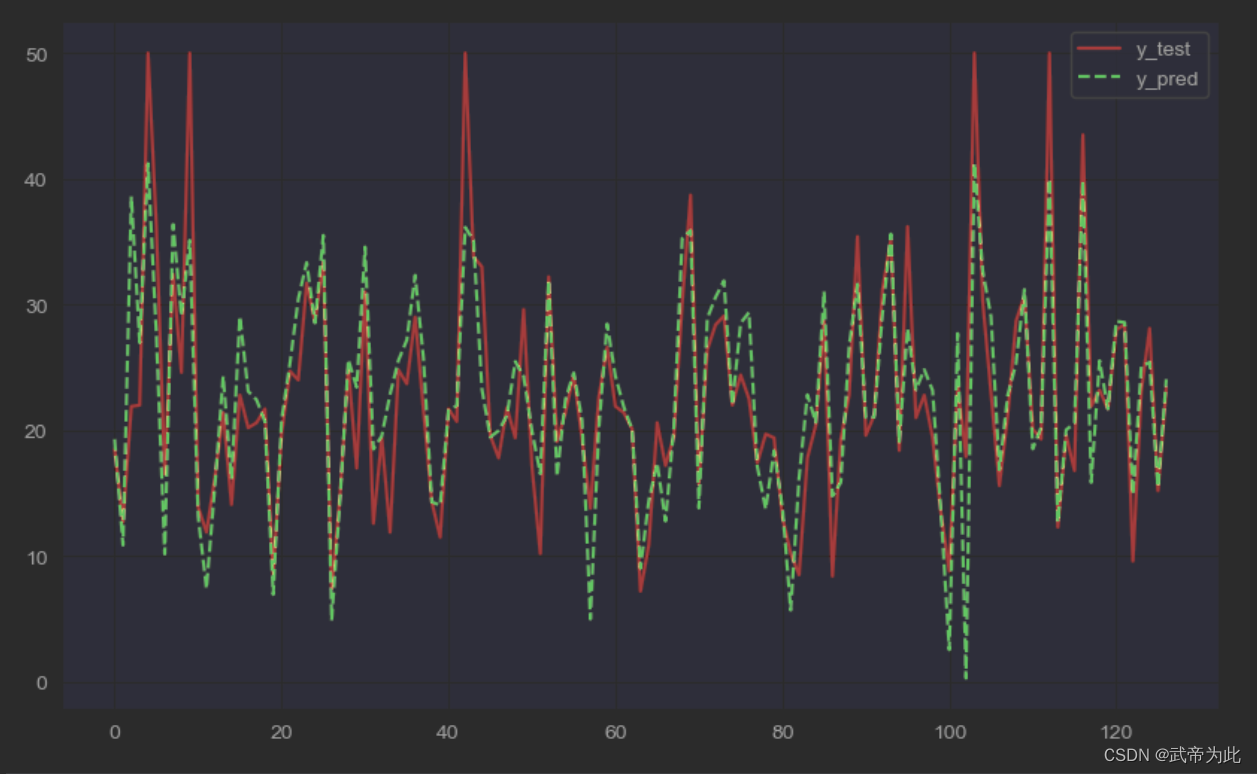
視覚化
最後に、真の値と予測値を視覚的に比較して、モデルがどの程度適合しているかをより直感的に理解します。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(range(len(y_test)), y_test, "r", label="y_test")
plt.plot(range(len(y_pred)), y_pred, "g--", label="y_pred")
plt.legend()
plt.show()