紙の上で得られることは浅いですが、詳細にやらなければならないことはわかっています
背景の紹介
この 2 日間で、クラスメート Q のアムウェイの下で、私は機械学習のピットにうまく (shi) 成功し (bai)、Tianchi のデータ マイニング エントリー コンテストの勉強を始めました。まずは中古車取引価格予測のご連絡です。当初は比較的単純なプロジェクトだと考えていました。Keras のモデルを適用してボストンの住宅価格の回帰予測を解き、単純なニューラル ネットワークを作成してデータを入力しました。それだけです。
そこで私は、ディープラーニングの基本ステップは、
(1) データ準備
(2) モデル選択&モデル開発
(3) モデル評価 (evaluate)
(4) モデル予測
(5) モデルチューニング (パラメータ調整) であると常々考えてきました。
意外なことに、この中古車取引価格予測、正確に予測するためには、基本的な機械学習手法を最適化する必要がある。個人的には、機械学習はディープラーニングに比べて難しすぎると感じていますが、最下層がすべて数学であることが難点です。プロセス全体には以下が含まれます:
(1) データ分析
(2) 特徴エンジニアリング
(3) モデル トレーニング
(4) モデル チューニング
特徴量エンジニアリングには多くのデータ処理方法が含まれており、その主な目的は、モデルにとってより有用な形式でデータを表現し、モデルのパフォーマンスを向上させることです。
keras の父である François Cholet の「Python Deep Learning」という本を読んだのですが、特徴量エンジニアリングの定義は次のとおりです。
「特徴量エンジニアリングとは、データと機械学習アルゴリズム (ニューラル ネットワークを含む) に関する独自の知識を使用して、データをモデルにフィードする前に (モデルによって学習されていない) ハードコーディングされた変換をデータに適用して、モデルのパフォーマンスを向上させることを指します。 」
理解するために大きな図を借りてみましょう。

ほとんどの場合、機械学習モデルは完全に任意のデータ(前処理なし) から学習することはできません。たとえば、時計の画像を予測し、ポインタが指すものに基づいて画像内の時間を分析したい場合は、次のようになります。各針先の対応する位置が (x, y) 座標に変換されるため、複雑な画像認識プログラムを作成しなくても、単純な機械学習アルゴリズムで時間を予測できます。
最も難しいのはこの特徴量エンジニアリングにあります。データバケットや箱ひげ図など、数理統計の一部の概念がよくわからないので、Tianchi が提供するコードを見ても理解できません。科学研究に接して以来、これほど詳細なデータ処理の問題に遭遇したのは初めてのような気がします。段階的なアプローチを採用し、最初からコードを 1 行ずつ分析する必要がありました。
関連ライブラリをインポートする
皆さん、心配しないでください。私が投稿したコードは、組み合わせると間違いなく機能します。
もちろん、最初のステップは必要なパッケージをインポートすることです。それぞれについて説明しましょう。
(1) numpy: numpy は誰もがよく知っているはずです。これは Python でカプセル化された行列演算ライブラリです。行列間の演算を完了できます。あらゆる面で matlab の行列型と非常によく似ています。
(2) pandas: pandas は numpy をベースとした構造化データツールであり、numpy よりも上位であることが理解できますが、最も単純な例として、pandas の DataFrame 型は numpy の配列行列よりも構造化されています。
(3)seabornとmatplotlib: この 2 つは Python 描画ツール ライブラリで、このうち seaborn は matplotlib をベースにしており、描画がより高度です。Seaborn と matplotlib の関係は、pandas と numpy の関係と同じです。
(4) missingno: 名前が示すように、欠番です。missingno は、無効なデータまたは欠損データの欠損の影響を視覚化できる欠損値視覚分析モジュールです。ところで、このライブラリは非常に強力ですか?
(5) scipy: scipy は科学計算ライブラリであり、主に統計解析、線形代数計算、微積分計算を担当します。たとえば、コードで使用します。scipy.statsこれには、さまざまな確率分布の確率変数が含まれており、使いやすいです。
(6) time: 処理時間。ソースデータに時間が存在するため、その時間を後で処理します。time は、ティック以降の現在時刻を浮動小数点として秒単位で返します。
(7) xgboost: パッケージ化された機械学習モデルはトレーニング中に直接呼び出すことができます。より公式に言うと、XGBoost は最適化された分散勾配拡張ライブラリであり、現在、多くの Kaggle プレイヤーがデータ マイニング コンテストに XGBoost を選択しています。
(8) sklearn: 同様に、Python でプリパッケージされた機械学習ツール ライブラリでもあり、NumPy、SciPy、Pandas、Matplotlib 上に構築されており、多くの機械学習モデル メソッドが実装されており、呼び出すことができます。とても初心者のような私にぴったりです。
import numpy as np
import pandas as pd
import seaborn as sns
import missingno as msno
import matplotlib.pyplot as plt
from scipy import stats
import time
import xgboost as xgb
from sklearn.metrics import roc_auc_score,mean_absolute_error
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score,train_test_split
import sklearn.preprocessing as preprocessing
また、上記のコードから、これらのパッケージが、おなじみの mae (回帰問題の評価指標である平均絶対誤差) であるランダム フォレストfrom sklearn importなど、機械学習で使用されるツール/モデル/コンポーネントであることもわかります。RandomForestClassifiermean_absolute_error
データセットをロードする
次にデータの読み込みです。
pandas を使用して、Tianchi によって提供されたデータ セットをロードし、代表的なトレーニング セットとテスト テスト セット マトリックスdata_trainを接続してdata_test、後続の処理を容易にします。
data_train=pd.DataFrame(pd.read_csv(r'F:/kaggle天池/used_car_train_20200313.csv',sep=' '))
data_test=pd.DataFrame(pd.read_csv(r'F:/kaggle天池/used_car_testB_20200421.csv',sep=' '))
data_train['type']='train' #定义一个type属性便于区别训练集测试集
data_test['type']='test'
print(data_train.info(verbose=True,null_counts=True))
print(data_test.info(verbose=True,null_counts=True))
print(data_train.head())#打印表的前几行
print(data_test.head())
print(data_train.shape)#查看矩阵的尺寸形状
print(data_test.shape)
data_all=pd.concat([data_train,data_test],axis=0,ignore_index=True,sort=False)#按行连接训练集和测试集
以下にいくつかの重要な方法を示します。
head()データ テーブルが比較的大きいが、その一般的な状況を確認したい場合、どうすればよいでしょうか。このとき、head() を使用できます。head() はデフォルトでテーブルの最初の 5 行を出力するため、データを全体的に理解することができます。最初の 10 行を入力したい場合は、head(10) と書くだけです。
info(): この関数は、インデックスのデータ型 dtype や列のデータ型 dtype、null 以外の値の数、メモリ使用量など、DataFrame に関する情報を示す、DataFrame の簡単な概要を出力するために使用されます。verboseこのパラメータは中国語で「長い」と翻訳され、完全な概要を印刷するかどうかを決定します。
pd.concat(): この関数は 2 つの行列を連結します。内側の軸の値は接続の次元を表し、axis=0これは 2 つの行列を垂直方向に接続する (行を下に接続)、axis=12 つの行列を水平方向に接続する (列を右に接続する) ことを意味します。
pd.DataFrame(): Pandas 独自のメソッドで行列 (配列) を pandas 固有のDataFrame形式に変換できます。DataFrame最大arrayの違いは、DataFrame がヘッダー (文字列または数値) を持つ行列であることです。詳細については、以下の図を参照してください。

図中、index は行インデックス、column は列インデックス、values は数値を表します。使い方はDataFrame後ほどお話します。より具体的なDataFrame例は次のとおりです。
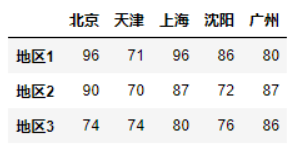
ただし、行列が numpyarray型の場合、行列は次のようになります。
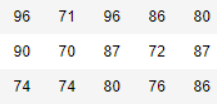
したがって、最も直感的な違いは、DataFrame にヘッダーがあることです。そのため、ExcelやCSVの操作が直感的で便利です。