慢性疾患診断のための特徴選択、次元削減および分類のレビュー-慢性疾患診断のための特徴選択、次元削減および分類のレビュー
まとめ
慢性疾患の早期診断は、死亡率を下げるために初期段階で疾患を検出する必要がある医療コミュニティおよび生物医学において重要な役割を果たしています。この論文では、慢性疾患の予測と診断における特徴選択、次元削減、分類技術の応用について調査します。属性を正しく選択することは、診断システムの分類精度を向上させる上で重要な役割を果たします。さらに、次元削減技術により、機械学習アルゴリズムの全体的なパフォーマンスが効果的に向上します。分類技術は、慢性疾患データベース上でインテリジェントで適応性のある自動システムを開発することにより、効果的な予測結果を提供します。この論文では、分類プロセスを促進し、計算と時間を改善するために、慢性疾患診断における並列適応分類技術の適用についても分析します。このレビュー記事では、特徴選択、次元削減、分類手法の概要と、それらの固有の長所と短所を説明します。
インデックス項目
適応分類、慢性疾患、次元削減、特徴選択、並列分類。
I.はじめに
ここ数十年、慢性疾患は人命に対する最大の脅威となっており、死亡率を下げる前に慢性疾患の診断と予測が重要です。主な慢性疾患としては、パーキンソン病、心臓病、肺がん、肝炎、乳がん、慢性腎臓病などが挙げられます。医療分野では、慢性疾患に関連するいくつかの特徴や診断を含む臨床データベースを維持することが重要なタスクです [1]。医療データベースに保存されるデータは冗長データと欠損値で構成されているため、データ マイニング アルゴリズムを使用する前にデータを削減する必要があります。データに一貫性がありノイズがなければ、慢性疾患の診断がより簡単かつ迅速になります。特徴選択と次元削減は、データの次元を削減する効果的なデータ前処理手法です [2]。医療の分野では、慢性疾患に関連するリスクファクターを見つけることが非常に重要です。相関特徴診断は、慢性疾患データベース内の冗長な属性や無関係な情報を削除して、迅速かつ正確な予測結果を得るのに役立ちます。診断および分類手法では、トレーニング データを使用してモデルを構築し、対応するモデルをテスト データに適用して、より良い予測結果を取得します。慢性疾患の早期診断のために、疾患データセットに対して多くの分類手法が使用されています [3]。医療データには、薬局、医師の処方箋、個人の臨床検査および診断検査レポート、ソーシャル メディアの投稿などに関連する情報が含まれます。したがって、診断プロセスを簡素化し、迅速化する新しい慢性疾患診断分類子を開発することが重要です。慢性疾患診断システムは、疾患を管理し、医療専門家や臨床医が年中無休で医療を提供できるようにし、患者の健康状態を効果的に監視するためのツールとして使用されています。
この調査資料は次のようにして作成されました。
セクション 2 では、慢性疾患の診断に使用されるデータベースを簡単に紹介します。
セクション 3 では、慢性疾患診断のための特徴選択と次元削減方法を紹介します。この表では、さまざまな機能選択手法を、その特性、利点、欠点などを含めて検討します。
セクション 4 では、慢性疾患に対する従来の、並行した、適応的な診断分類技術を概説します。
セクション 5 では、慢性疾患の診断に使用されるパフォーマンス指標について簡単に説明します。
セクション 6 では、調査報告書の結論を示します。
II. 慢性疾患の診断に利用できるデータベース
慢性疾患は、ここ数十年にわたって人間の健康に大きな影響を与えている長期的な疾患です。最も一般的な慢性疾患は、高脂血症性関節炎、冠状動脈疾患、結腸がん、喘息、心臓病、血友病、慢性腎臓病、慢性呼吸器疾患などです[4]。慢性疾患の一因となるリスク行動には、高血圧(血圧の上昇)、喫煙、コレステロールの上昇、不健康な食事、身体活動の不足、有害なアルコールの使用が含まれます。慢性疾患のリスク行動を図 1 に示します。
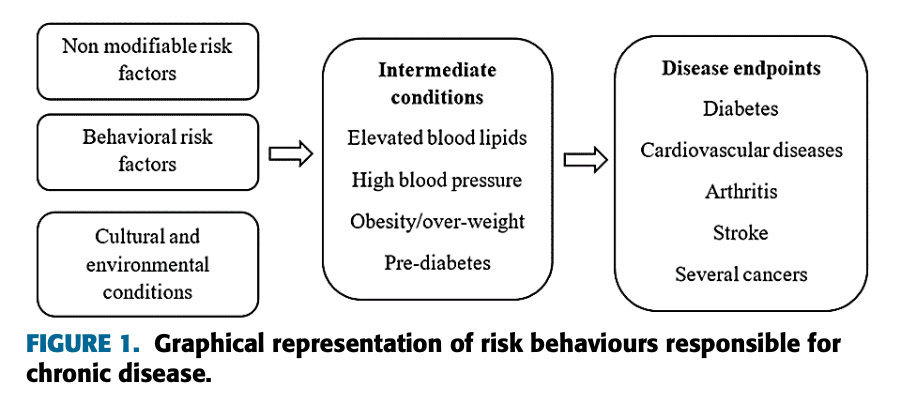
図1。慢性疾患のリスク行動をグラフで表現。
慢性疾患の正確な診断により、医学界および生物医学において死亡率が大幅に減少しました。ここ数十年で、慢性疾患の診断にいくつかのデータベースが利用できるようになりました。人気のあるデータベースのいくつかを表 1 に示します。目的の操作 (特徴の選択または次元削減と分類) は選択したデータベースに依存するため、データベースの選択は適切である必要があります。
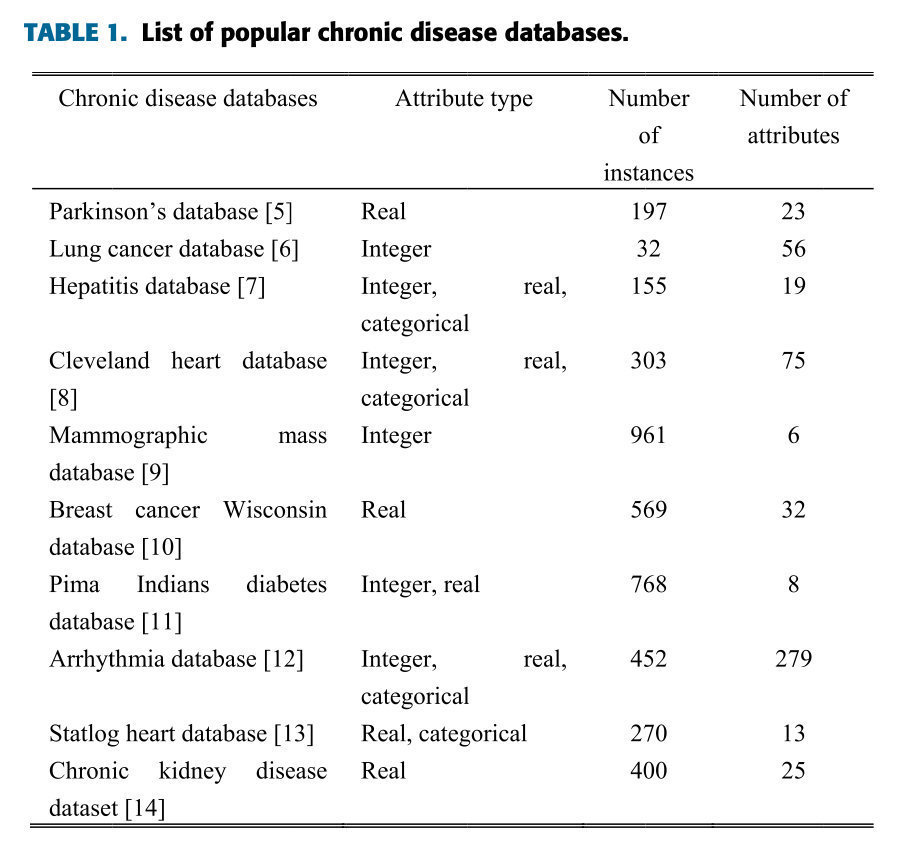
表1。人気のある慢性疾患データベースのリスト。
II. 慢性疾患診断における特徴選択と次元削減技術
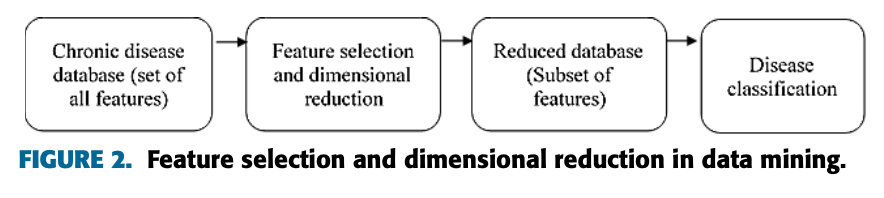
データ マイニングでは、特徴選択と次元削減が、データベース内の無関係な属性を削減してデータを最小化するために最も一般的に使用される前処理手法です。また、データの視覚化が容易になり、データの理解が向上し、慢性疾患の診断における分類技術のトレーニング時間を最小限に抑えることができます。しかし、慢性疾患の診断は、サラセミア、糖尿病、心臓病、高血圧、脳卒中などの多くの状態で発生します[2]。データマイニングにおける特徴選択技術は、埋め込み技術、ラッパー技術、フィルタリング技術、ハイブリッド技術の 4 つのカテゴリに大別されます [15]。特徴選択技術は、元のデータベースから重複した特徴や無関係な特徴を削除して、分類の精度を向上させます。データ マイニングにおける特徴選択プロセスを図 2 に示します。
A. フィルタリング技術
フィルタリング技術は、データベースから特徴を個別に選択します。フィルタリングは最も古いプロセスの 1 つであり、分類技術に依存しないため、特定の評価基準に基づいて属性を分類します。フィルタリング技術は、冗長、不変、反復、無関係、相関関係のある特徴を削除するのに適しています。それにもかかわらず、選択された特徴は、計算コストが低いため、あらゆる機械学習手法で使用されます。現在、一変量と多変量の 2 種類のフィルタリング手法が利用可能です。単変量フィルタリング技術は、特定の基準に基づいて個々の特徴をランク付けし、特徴空間内で各特徴を独立して処理します。最後に、基準に従って最高ランクの特徴が選択されます。単変量手法では、単変量手法で主に関心のある特徴間の関係が考慮されない冗長な変数が選択されます。
一方、多変量手法は特徴空間全体を評価し、冗長な特徴、繰り返しの特徴、および相関のある特徴を処理できます。Battiti [16] は、相互情報量の概念に基づいた特徴選択手法を実装しました。この研究では、特徴選択技術により相互情報量が最大の特徴を抽出します。さらに、Bennasar ら [17] は、Joint Mutual Information Maximization (JMIM) と Normalized JMIM (NJMIM) と呼ばれる 2 つの新しい非線形特徴選択技術を開発し、これら 2 つの技術は「相互基準最大値」を利用して UCI リポジトリ データベースから特徴を抽出します。
Chormunge と Jena [18] は、データ マイニング タスクにおける次元の問題を軽減するために、相関とクラスタリングに基づく新しい特徴選択手法を実装しました。まず、k-means クラスタリング アルゴリズムを使用して無関係な特徴を削除し、次に各クラスターに対して相関測定を実行して、冗長でない特徴を選択します。次に、ナイーブ ベイズをマイクロアレイとテキスト データベースの分類に適用します。Cigdem et al. [19] は、相関に基づく特徴選択手法を利用して特徴をランク付けし、フィッシャーの基準を使用して上位にランク付けされた特徴を選択します。次に、双極性障害は、さまざまな分類手法を使用して 3D 磁気共鳴画像法で分類されました。
B. ラッパーテクニック
ラッパー技術は、分類子のパフォーマンスに基づいて関連する特徴を抽出します。これは実際の最適化問題を大幅に解決しますが、フィルタリング手法に比べて計算コストが高くなります。ラッパー手法は貪欲な検索アルゴリズムに基づいて機能し、すべての機能の組み合わせが評価され、機械または深層学習アルゴリズムにより良い結果を提供するものが選択されます。ラッパー手法には、(i) 特徴の最適なサブセットを効率的に見つけ、(ii) 変数間の相互作用を検出するという 2 つの主な利点があります。一般に、ラッパー技術はフィルタリング技術に比べて予測精度が向上します。特徴選択に関して、ラッパー技術は、徹底的な特徴選択、前方および後方特徴選択の 3 つのカテゴリに分類されます。Lee ら [20] は、ラッパーベースの特徴選択技術を使用して、医療システムによって生成された大量の多次元データを効率的に処理しました。この論文では、ヘルスケア領域における臨床意思決定のために、バギング C4.5 アルゴリズムに基づく新しいバギング特徴選択方法を提案します。Jadhav et al. [21] は、情報利得に基づいて特徴をランク付けし、遺伝的アルゴリズムを使用して上位の特徴を選択する、情報利得指向の特徴選択技術と呼ばれる新しい特徴選択技術を実装しました。Apolloni et al. [22] は、マイクロアレイ データの次元を削減するために、バイナリ差分進化アルゴリズムに基づくパックされた特徴選択技術を導入しました。
Sawhney et al. [23] は、ペナルティ関数をバイナリ Firefly アルゴリズムの既存の適合関数と組み合わせて、特徴セットを削減しました。選択された最適な特徴のサブセットにより、子宮頸がん、乳がん、子宮頸がん、肝臓がん、および肝細胞がんに対するランダム フォレスト分類器の分類精度が効果的に向上しました。Mafarja と Mirjalili [24] は、クジラ最適化アルゴリズムを利用して、入力特徴の次元を最小化します。実験結果は、開発されたアルゴリズムが、粒子群最適化 (PSO) [25]、[26] や遺伝的アルゴリズム [27] などの他の既存の技術と比較して、より良い結果を提供することを示しています。さらに、Shen ら [28] と Balasubramanian および Marichamy [29] は、ミバエ最適化アルゴリズムを使用して、特徴の次元を最小限に抑えました。実験結果は、このアルゴリズムがより適切なモデル パラメーターを取得し、分類精度が高いことを示しています。ショウジョウバエの最適化アルゴリズムは、医療上の意思決定のための効果的なツールとして認識されています。
C. 埋め込み技術
組み込み技術では、特徴選択は、ラッパー技術とフィルタリング技術の品質を組み合わせた学習アルゴリズムの一部として統合されます。埋め込み手法の一般的な例は、過学習の問題を軽減する組み込みのペナルティ関数を備えたなげなわ回帰とリッジ回帰です。ラッソ回帰手法は L1 正則化を実行し、係数のサイズに等しいペナルティを追加します。ただし、リッジ回帰手法では L2 正則化が実行され、係数サイズの 2 乗に等しいペナルティが追加されます。[30] は、教師なし特徴選択のための効率的な近傍埋め込み手法を実装しました。まず、局所線形埋め込みアルゴリズムを使用して特徴重み行列が取得されます。次に、L1 正規化手法を採用して、データセット内のノイズと外れ値の影響を抑制します。広範な実験により、この手法が既存の教師なし特徴選択手法よりもベンチマーク データセットで優れたパフォーマンスを達成することが示されています。
Tao et al. [31] は、L2 正規化、追跡ノルム、および l ノルム正則化を介して特徴選択に関連情報を利用する新しいマルチソース適応埋め込み技術を導入しました。さらに、開発された適応埋め込み技術は、ドメイン内の外れ値やノイズの存在に対して堅牢であり、スパース回帰法と L1 および L2 ノルム最小化によるグラフ埋め込みを適用することにより、元の幾何学的構造情報を保存します。Wang と Zhu [32] は、スパース性の保持と近傍埋め込み特徴選択技術を使用して、大量のデータを処理しました。開発された特徴選択手法は、機械学習リポジトリで公開されている 8 つのデータセットで研究されました。広範な実験により、開発された技術は最先端技術と比較して特徴選択において優れたパフォーマンスを達成することが示されています。
D. ハイブリッド技術
ハイブリッド技術は、ここ数十年間、特徴選択のために研究者によって広く使用されてきました。ハイブリッド手法では、2 つ以上の特徴選択手法を組み合わせて最良の結果を実現します。一般に、ハイブリッド手法はフィルタリング手法よりも計算効率が高く、ラッパー手法や埋め込み手法よりも分類精度が高くなります。Baliarsingh et al. [33] は、コウテイペンギン オプティマイザーとソーシャル エンジニアリング オプティマイザーを組み合わせて、肺がん、卵巣がん、結腸がん、および白血病に関連する属性を選択しました。次に、サポート ベクター マシン (SVM) 分類器を使用して、関連する遺伝子を分類しました。さらに、AlMuhaideb と Menai [34] は、人工ミツバチコロニー (ABC) とアリコロニーオプティマイザー (ACO) を組み合わせて医療データを最適化しました。リアルタイム データベースとベンチマーク データベースの実験結果は、ハイブリッド手法の有効性を示しています。ハイブリッド技術の助けにより、分類モデルはより優れた予測精度を達成しました。
Jayaraman と Sultana [35] は、粒子群最適化アルゴリズムと重力カッコー探索アルゴリズム (GCSA) を組み合わせて、心臓病分類システムに存在する特徴を管理しました。まず、心臓データベースの UCI リポジトリからデータが収集されました。収集されたデータは高次元で処理が難しく、心臓病診断システムの効率が低下します。したがって、PSO と GCSA の動作により、データの次元が削減されます。選択された特徴は、データ分類のために連想メモリ分類器に供給されます。Khourdifi と Bahaj [36] は、PSO アルゴリズムと ACO アルゴリズムを組み合わせて、心臓病分類の品質を向上させました。選択された特徴は、データ分類のためにさまざまな分類器に供給されます。広範な実験により、ハイブリッド最適化技術により医療データベースの診断精度が大幅に向上することが示されました。
Bharti と Mittal [37] は、肝超音波画像を肝硬変、正常、肝細胞癌、慢性の 4 つのカテゴリーに分類するための最適な特徴サブセットを生成するハイブリッド特徴選択に基づく特徴融合システムを開発しました。ハイブリッド特徴選択により、重複した無関係な特徴サブセットが排除され、分類パフォーマンスが大幅に向上します。Jain と Singh [38] は、慢性疾患を診断するための新しい適応型分類システムを導入しました。まず、reliefF と主成分分析 (PCA) を使用して特徴の最適化が実行され、SVM 分類器を使用してデータ分類が実行されます。この研究では、より高い分類精度を得るために、効果的なパラメータ最適化手法を SVM 分類器に適用しました。システムのパフォーマンスを評価するために、よく知られた疾患データベース (卵巣がん、前立腺がん、白血病、肺がん、結腸データセット、心臓病) が医療診断に使用されました。表 2 は、慢性疾患診断のための特徴選択技術の長所と短所を示しています。

E. 寸法縮小技術
次元削減技術は、高次元データ空間を低次元データ空間に変換します。高次元データ空間を扱う場合、通常、元のデータはスパースであるため、「次元の呪い」問題と計算上の困難が生じます。次元削減技術は、医学、バイオインフォマティクスなどの分野で広く使用されており、主に線形次元削減と非線形次元削減の 2 つのカテゴリに分類されます。慢性疾患の診断で最も一般的に使用される技術は、PCA、線形判別分析 (LDA)、一般化判別分析 (GDA) などです。Muhammad et al. [39] は、糖尿病のさまざまな分類に PCA 技術を使用しました。医療分野では慢性疾患の診断は困難な作業であり、意思決定にはさまざまなデータマイニング技術が使用されます。Banu [40] は、甲状腺機能低下症を分類するために LDA 技術を応用しました。Shahbazi と Asl [41] は、特徴空間内の特徴の数とサンプルの重複を最小限に抑えるための特徴選択手法として GDA を使用しました。さらに、心臓病分類における特徴セットのパフォーマンスは、K 最近傍 (KNN) を使用して分析されます。
IV. 慢性疾患の診断に使用される分類技術
データ マイニングでは、分類には人工知能、数学、確率分布、統計に基づく教師なし手法と教師あり手法が含まれます [3]。通常、分類技術はデータ項目の記述分析を表し、効果的な意思決定のためにデータ項目のグループ メンバーシップを予測するために使用されます。
データマイニングでは、より良い診断精度と診断結果を得るために、慢性疾患の診断にさまざまな分類手法を使用する研究者もいます。SVM [42]、[43]、ランダム フォレスト [44]、KNN [45]、Adaboost [46] およびその他の分類器は、慢性疾患の診断と予後のために使用されます。図 3 は、予測結果を達成するために医療データを前処理するために適用される分類プロセスを示しています。
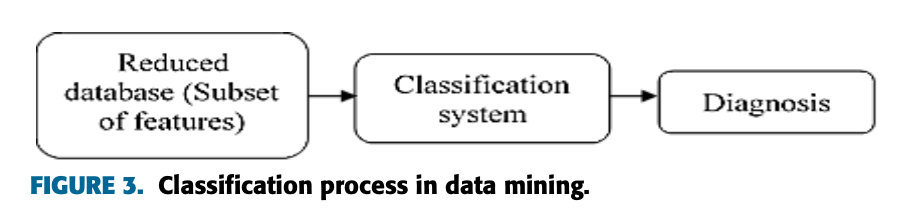
ほとんどの科学アプリケーションでは、肺がん、肝炎、慢性腎臓病、パーキンソン病などの慢性疾患をより適切に診断および診断するには、自動化された理解しやすいシステムが必要です。従来のシステムのほとんどは非効率的で成功率が低下し、計算量が増加します。時間または決断の時間。したがって、慢性疾患の診断には、疾患を正確に予測できる適応型分類技術が必要です。さらに、診断結果を向上させるために並行分類技術も使用されます。表 3 は、慢性疾患の診断に使用される分類手法の長所と短所を示しています。
Mohapatra et al. [47] は、カッコー検索と極限機械学習 (EML) 技術を使用して、肝炎、糖尿病、ブパ、乳がんの 4 つのベンチマーク データセットを分類しました。実験結果は、このモデルが感度、f スコア、特異性、全体的な精度、Gmean、混同行列、および正規化値の点で有効であることを示しています。Polat [48] は、心臓、パーキンソン病、ピマ インディアン、胸部外科の医療データベースのデータの前処理と分類に属性重み付け技術を使用しました。クラス内の分散値を減らすために、この研究では 3 つのクラスタリング アルゴリズム (平均シフト、K 平均、およびファジー C 平均) が使用されました。不均衡な医療データベースは、属性重み付け処理の後、サポート ベクター マシン、KNN、ランダム フォレスト、LDA を使用して分類されました。広範な実験により、開発された属性重み付け技術がランダム サブサンプリング技術と比較してより高い分類精度を達成することが示されています。Seera と Lim [49] は、ランダム フォレスト、回帰ツリー、ファジー ミニマックス ニューラル ネットワークに基づいたハイブリッド インテリジェント医療データ分類システムを開発しました。開発されたスマート システムのパフォーマンスは、肝疾患、ピマ インディアンの糖尿病、ウィスコンシンの乳がんのデータベースで分析されました。
Jaganathan と Kuppuchamy [50] は、平均選択、ニューラル ネットワーク、半選択などの特徴選択手法を使用して、クリーブランド心臓、スタットログ、ウィスコンシン乳がん、肝炎、およびピマのインド糖尿病データセットの必要な特徴における冗長性、関連性のなさ、無関係性を削減しました。 。次に、選択された最適な特徴が放射基底関数に入力されて、医療データが分類されます。Nalband et al. [51] は、遺伝的アルゴリズムとアプリオリ アルゴリズムを使用して、抽出された特徴ベクトルから重要な特徴を選択しました。次に、ランダム フォレストおよび最小二乗サポート ベクター マシン (LS-SVM) 分類技術を適用して、異常な振動マッピング信号と正常な振動マッピング信号を正確に区別しました。さらに、Cheruku et al. [52] は、BAT 最適化アルゴリズムとラフセット理論に基づいた新しいハイブリッド意思決定支援システムを導入しました。ハイブリッド システムは、ファジー ルールを生成することにより、冗長な機能を効果的に削減します。次に、選択された特徴がファジー ルールベースの分類手法に入力され、疾患が分類されます。この論文では、ウィスコンシン乳がん、ピマ・インディアン糖尿病、虹彩、クリーブランド心臓病のデータセットに対する開発されたシステムのパフォーマンスを、g 値、精度、感度、特異度の観点から調査しています。
A. 慢性疾患の診断に使用される並行分類技術
従来の分類手法は、大量の医療データや非構造化医療データを処理する場合には効果がありません。したがって、既存の医療システムの構造はデータ分析を使用して改善されます。現在、ビッグデータ分析は、Hadoop、マップリデュースプログラミングなど、さまざまな技術やツールを使用して行われています。ただし、並列分類技術には、診断システムの予測精度を向上させる大きな可能性があります。並行分類技術は、慢性疾患の臨床意思決定に効果的です。図 4 は、Ostrom と Koch [5] によって提案された、より良い予測結果を達成するために前処理されたデータに適用される並列分類手法を示しています。
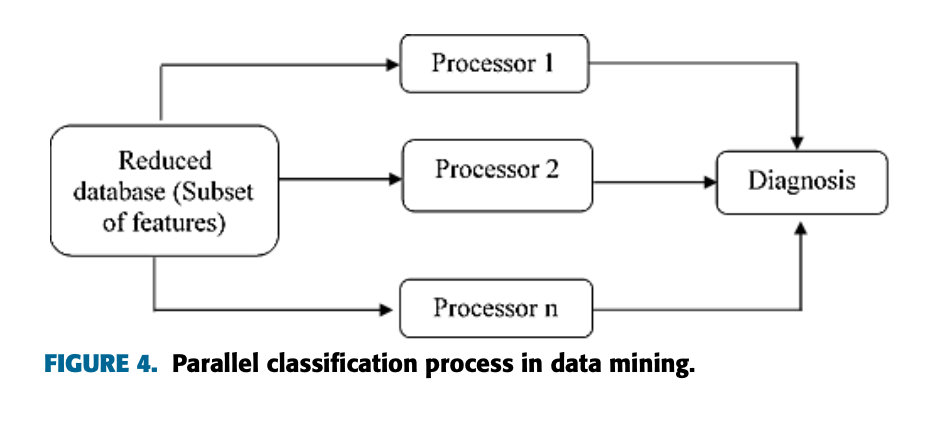
この論文では、誤った決定の可能性を減らすために 2 つのニューラル ネットワークが使用されています。最終的な決定のために、各ニューラル ネットワークの出力がルールベースのシステムを使用して分析されます。開発された並列ネットワークは、慢性疾患診断の堅牢性を効果的に向上させます。シミュレーション結果は、並列ネットワークにより、単一の固有ネットワークと比較してパーキンソン病の診断が 8.4% 向上することを示しています。さらに、Shrivastava et al. [53] は、調査データベースでヒトの糖尿病発症の確率を予測するための並列サポート ベクター マシン技術を開発しました。この研究論文は、人が将来糖尿病を発症する可能性を予測します。調査データは高次元であるため、従来のサポート ベクター マシンは効果がありません。多数のパラメータを扱うために,本稿では並列サポートベクターマシンの概念を導入した。並列 SVM はパラメータをさまざまなマシンに分散するため、処理能力、計算の複雑さ、ストレージ容量が削減されます。シミュレーション結果は、従来の SVM テクノロジーと比較して、並列 SVM により計算時間が 1/3 に短縮されることを示しています。
B. 慢性疾患の診断に使用される適応的分類技術
最近では、分類技術を高度なバージョンで使用して、医療データセット内の属性の分類を生成し、より適切に分類できるようになりました。適応分類器の高度なバージョンは、クラスタリング技術と分類技術を組み合わせたものです。適応システムは成功率を大幅に高め、医療スタッフや医師が慢性疾患の診断において効果的な臨床上の意思決定を行うのに役立ちます。
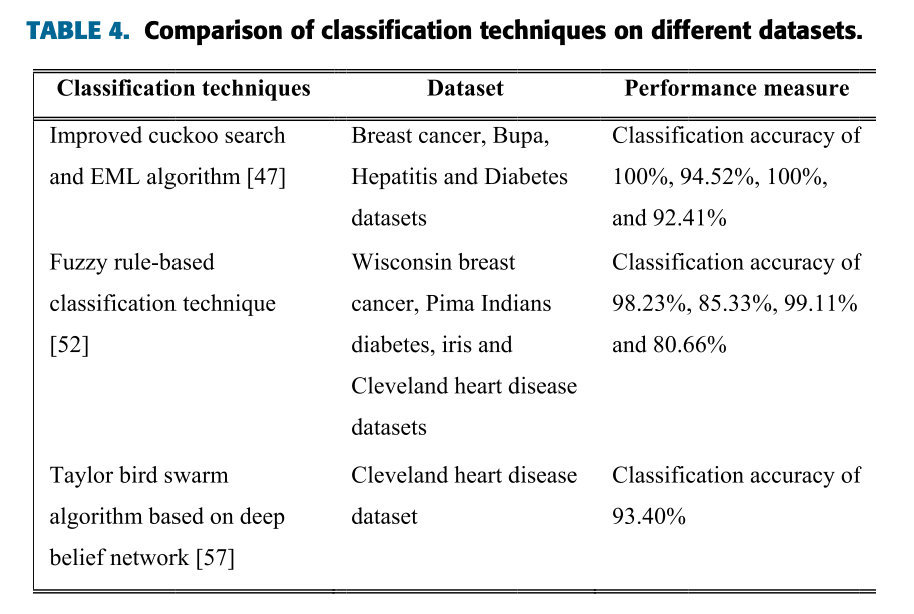
Jain と Singh [38] は、慢性疾患を診断するための適応型 SVM 分類技術を開発しました。この論文では、ハイブリッド PCA および ReliefF 技術を SVM のパラメータ最適化に使用して、高い分類精度を取得します。開発されたシステムのパフォーマンスを研究するために、9 つの慢性疾患データセットが医療診断に使用されます。広範な実験により、開発されたシステムはデータベースの次元を大幅に削減し、分類器の有効性を向上させ、計算時間とコストを削減することが示されました。Yu et al. [54] は、マイクロアレイ データ分類のためのハイブリッド適応アンサンブル学習 (HAEL) システムを導入しました。開発されたシステムは、KEEL およびリアルタイム マイクロアレイ データベースで良好に機能しました。Dennis と Muthukrishnan [55] は、適応遺伝的ファジー システムを使用して、医療データ分類プロセスのメンバーシップ関数とルールを最適化しました。さらに、Chandra と Kaur [56] は肝硬変とリンパ節の診断に適応型 KNN 分類技術を使用しました。Alhassan と Zainon [57] は、医療意思決定のための医療データ分類法である、心臓診断のための深層信念ネットワークに基づく新しいアプローチである Taylor の鳥群アルゴリズムを提案しました。この方法の分類精度率は93.4%です。実験によると、SVM、NB、DBN 手法と比較して、Taylor BSA-DBN はデータベースの次元を大幅に削減し、分類器の有効性を向上させ、計算時間とコストを削減します。リアルタイム医療データベースにおけるこの方法の分類精度は 90% に達し、従来の KNN 方法よりも優れています。従来の分類技術、並列分類技術、および適応型分類技術を比較すると、並列分類技術には慢性疾患診断システムの予測精度を向上させる大きな可能性があります。さまざまなデータセットでの分類手法の比較を表 4 に示します。
V. 慢性疾患の分類に使用されるパフォーマンス尺度
医療診断システムでは、分類のパフォーマンスは、精度、再現率、f 値、精度、特異性、フォークス マローズ指数 (FMI) などのさまざまなパフォーマンス尺度を使用して分析されます。通常、これらのパフォーマンス メトリックは、さまざまな分類モデルのパフォーマンスを分析するために使用されます。
精度:偽陽性と真陽性の合計に対する真陽性の比率として決定されます。すべての予測された肯定的な観測値のうち、正確に予測された肯定的な観測値の比率が精度です。精度の数式は式 (1) で定義されます。
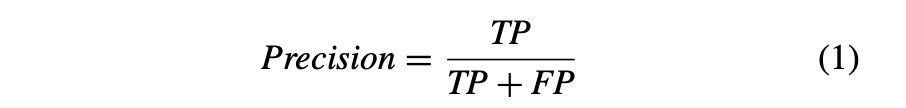
再現率: これは、式 (2) で数学的に表される、偽陰性と真陽性の合計に対する真陽性の比率として定義されます。
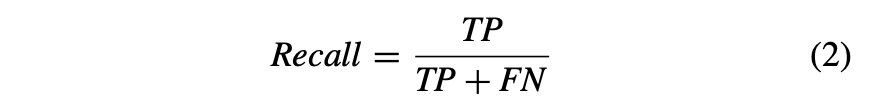
F 値: 式 3 で説明されているように、精度と再現率の加重調和平均として定義されます)
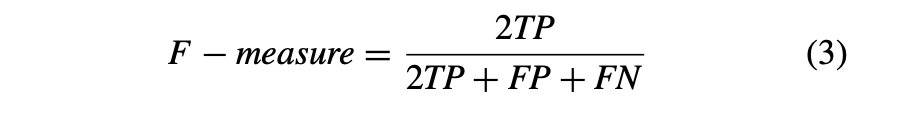
精度: これは慢性疾患の診断で使用される最も直観的なパフォーマンス指標であり、全観察のうち正しく予測された観察の割合です。精度の数式は式 (4) で定義されます。

特異性:正しく特定された陰性の割合として定義されます。特異度は真陰性率とも呼ばれ、数式(5)で表されます。
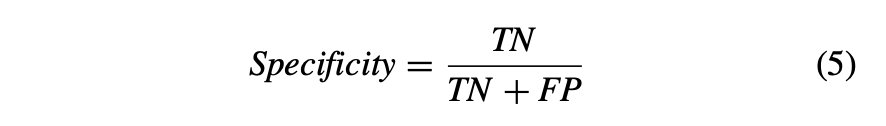
FMI:再現率と適合率の幾何平均として定義されます。FMI は式 (6) で数学的に表されます。
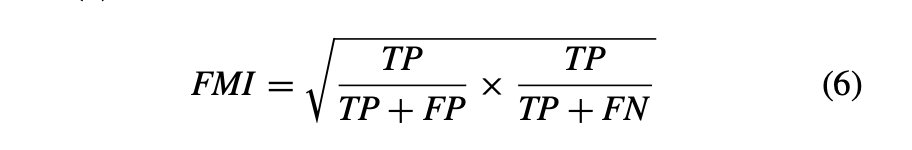
このうち、TP は真、TN は真陰性、FP は偽陽性、FN は偽陰性を表します。
VI. 結論
この論文では、慢性疾患を効率的に診断するための現在の特徴選択、次元削減、および分類器について概説します。医療診断システムにおける分類器のパフォーマンスを評価するためのパフォーマンス指標もレビューされます。さらに、この論文では、いくつかの特徴選択、次元削減、分類手法の長所と短所を比較しています。さらに、このペーパーでは、データ マイニング タスク、検索戦略、および評価基準に従って特徴選択手法を分類します。特徴選択技術に関する研究では、フィルタリング技術がラッパー技術や埋め込み技術よりも効率的で、最適な特徴サブセットを特定する際に優れたパフォーマンスを発揮することが示されています。この調査記事は、現在の特徴選択の強みがハイブリッド技術であることを明らかにしています。ハイブリッド技術は、ノイズ、冗長性、および重要でない特徴を除去するために慢性疾患データベースで使用されています。一方、慢性疾患の診断には、従来の分類器に関連するSVM、ナイーブベイズ、決定木、ニューラルネットワーク、ランダムフォレストなど多くの分類技術が使用されており、適応型並列分類技術は、慢性疾患の診断において高い価値を持っています。慢性疾患の診断の成功率と計算時間の短縮。既存の研究のほとんどは、主に伝統的な医療診断分類技術に焦点を当てています。この論文では、高い診断精度と分類精度を提供することで慢性疾患診断のパフォーマンスを大幅に向上させる適応分類技術と並列分類技術について概説します。これらの分類技術は、医療専門家、医師、内科医、臨床医が効果的な慢性疾患の診断上の決定を下すのに役立ちます。
VII. 研究ギャップ
このレビュー記事は、慢性疾患検出に関する将来の研究は、分類精度を向上させ、結果の計算効率を最適化するための新しいハイブリッド分類技術の開発に焦点を当てるべきであることを示唆しています。ここ数十年で、いくつかの分類システムが有益に研究されてきました。既存の研究は主に、従来の分類システムを使用した医療診断に焦点を当てています。