データの次元削減と特徴抽出は、データの前処理で使用される一般的な手法であり、データの次元を削減してモデルのパフォーマンスを向上させたり、計算の複雑さを軽減したりすることを目的としています。ただし、その目標とアプローチは若干異なります。
-
データの次元削減:
-
目標: データの次元削減の目的は、元の情報をできるだけ保持しながらデータの特徴次元を削減し、データをより効率的に処理および分析できるようにすることです。
-
方法: 一般的に使用されるデータの次元削減方法には、主成分分析 (PCA)、線形判別分析 (LDA) などが含まれます。PCA は、データを表すためにデータ内で最も支配的な方向 (主成分) を見つけようと試み、それによってデータを低次元空間に投影します。LDA は教師あり学習の次元削減手法であり、カテゴリ情報を考慮して、さまざまなカテゴリを最もよく区別できる低次元空間にデータをマッピングします。
-
適用可能なシナリオ: データの次元削減は、データの次元が高くても情報が冗長である場合に適しており、コンピューティング リソースのコストを削減し、モデルのトレーニング効率を向上させ、モデルの過剰適合のリスクを軽減することができます。
-
-
特徴抽出:
-
目標: 特徴抽出は、モデリングと予測のために元のデータを新しい特徴空間に変換することにより、より識別可能な特徴を見つけることです。
-
方法: 一般的に使用される特徴抽出方法には次のものがあります。統計に基づく方法 (平均、分散、相関係数など)、周波数領域に基づく手法(フーリエ変換など)、情報理論に基づいて方法(相互情報、情報獲得など)など。
-
適用可能なシナリオ: 特徴抽出は通常、元の特徴に多くのノイズや冗長な情報が含まれており、ターゲット タスクにとってより有用な特徴を除外することが期待される場合に使用されます。
-
違いの概要:
- データの次元削減の目的は、可能な限り多くの情報を保持しながら、データの次元を削減して計算の複雑さを軽減したり、視覚化を容易にしたりすることです。
- 特徴抽出の目的は、元の特徴からタスクにとってより意味のある特徴または識別力のある特徴を抽出して、モデルのパフォーマンスを向上させることです。
両方の手法は、モデリングと分析のためのデータをより適切に準備するために、現実世界のタスクでよく一緒に使用されます。
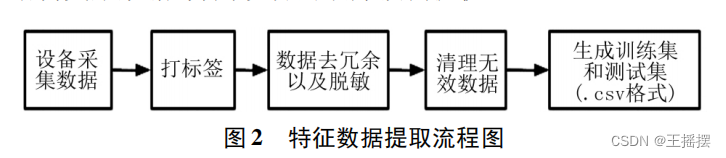
従来のデータ前処理プロセス