この記事では、yolov5 ニューラル ネットワークの構造を簡単に説明するだけです。具体的な理論的な知識については、ご自身でニューラル ネットワークを学習してください。(コンピューターの読書体験の方が優れています)
目次
yolo ファイルを解析する前に、yolov5 のネットワーク構造がどのようなものかを理解する必要があります。
yolov5s.yaml:
(このファイルは実際には、モデルの構築をガイドする構成ファイルの単なる説明です。参考までに、このファイルを参照して独自のモデル ファイルを構成できます)
まず、図に示す yolov5 ネットワーク構造を理解します。
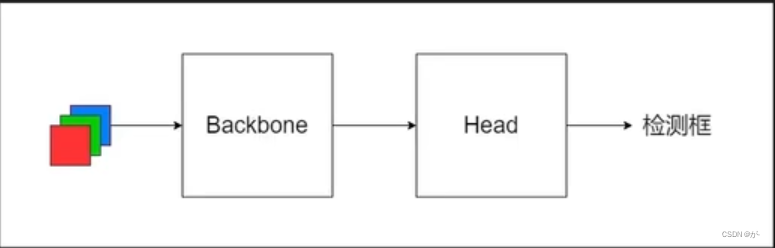
まず、中央の Backone、Head とは何かを理解しましょう。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
バックボーン:数字の意味だけを表す
#0-P1/2 1階
from: -1 は入力が前の層から渡されることを意味し、[-1, 6] は入力が 11 番目と 6 番目の層から渡されることを意味します
数値: モジュール構造の数を示します。数値>1 の場合、数値=数値*深さ_多重になります。
module: モジュール構造 (Conv、C3 など)、畳み込み層構造、( common.py )で定義
args: 受信パラメータ。各パラメータの意味を判断するには、共通の各ネットワーク層モデル カテゴリに問い合わせる必要があります。
P1:1階
/2: ステップ サイズは 2 で、ピクチャの長さと幅は 2 で割られます (ピクチャの解像度で長さと幅が 32 の倍数である必要があるのはこのためです)。
#1-P2/4 2階:
層ごとに
head: ここもバックボーンと同様、さまざまなネットワーク層で構成されています
nn.Upsample : アップサンプリング層
Concat : 各層の送信機能を合成するネットワーク層
検出: 推論検出層
ここには合計 24 のニューラル ネットワーク層があることがわかりましたが、これらの 24 層はどのように互いに重ね合わされるのでしょうか? 単純に層ごとに重ね合わされているのでしょうか?
答えは明らかにそうではありません。実際のネットワーク構造は次のとおりです: (インターネット上の多くの場所にあるネットワーク構造解析のバックボーンは上から下に重ねて表示されます。ここでは B ステーションから上に向かって 480920279 を下から上に学習しました。ネットワーク構造)
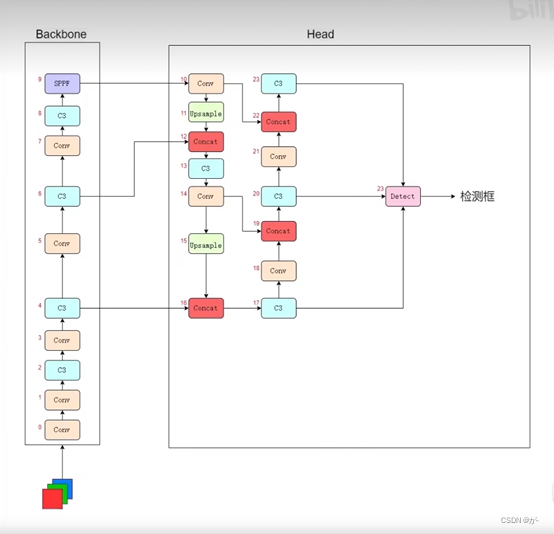
この図の意味は、RGB 3 チャネルの画像をニューラル ネットワークに渡し、Backbone10 層のネットワークを通過した後、ヘッドに入り、アップサンプリング、包括的な特徴処理などを行い、最後に 3 つの C3 ネットワーク層を経ます。 3 つの C3 レイヤーは、上から下まで、高レベル フィーチャ レイヤー、中レベル フィーチャ レイヤー、および低レベル フィーチャ レイヤーと呼ばれるものです。
これらのフィーチャ レイヤーの違いは、低レベルは小さなターゲットを検出し、中レベルは中サイズのターゲットを検出し、高レベルは大きなターゲットを検出し、これらを組み合わせてターゲットを予測することです。
# Parameters
nc: 6 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32nc:(クラス数)対象カテゴリ番号
アンカー: 3 つのレイヤーが異なる機能レベルに対応します
[10,13, 16,30, 33,23] 下層のアンカー 3 個、10×13、16×30、33×23
[30,61,62,45,59,119]中間層のアンカー3本
Depth_multiple: モデルの深さの倍数、モデル作成時の数値* Depth_multiple
width_multiple: チャネル倍数、各レイヤのチャネルパラメータ * width_multiple=送信チャネル数、深さと幅パラメータの乗算は整数ではないため切り捨てられます
Depth_multiple、width_multiple はモデルの複雑さを決定します。値が大きいほど、精度が複雑になり、時間がかかります。
さまざまなモデル ファイルの精度: n<s<m<l<x (精度が高いほど時間がかかります) (これらのファイルの違いは深さの倍数とチャネルの倍数のみです)
したがって、このマニュアルを参照して、モデル構成ファイルを自分で作成することができます。
ニューラル ネットワークの構造を理解したら、yolo.pyに移動して、ニューラル ネットワークがどのように実装されているかを確認しましょう。
yolo.py:
__nameの場合:
モデルの作成: yolov5 モデルを作成します
(ここにはいくつかの書き方があるかもしれません):
最初:
# Create model
im = torch.rand(opt.batch_size,3,640,640).to(device)
model = Model(opt.cfg).to(device)2 番目のタイプ:
# Create model
model = Model(opt.cfg).to(device)
model.train()
# Profile
if opt.profile:
img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
y = model(img, profile=True)im(g): 画像をランダムに定義します
y=model: モデルを定義します ( -->Model )
(オプション):
モデル:
init: ネットワーク構造を構築する
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg, encoding='ascii', errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dictcfg: 設定ファイル (yolov5s.yaml)
ch: 入力映像チャンネル番号
super().init: 設定ファイルをロードします。
入力が文字列かどうかを判断する
self.yaml_file はファイル名を取得します
with: ファイルのロードを開始すると、主要な要素が辞書の形式で保存されます。
モデルの定義: モデルを定義します。
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']: # 判断该值和yaml中的值是否一样
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
self.inplace = self.yaml.get('inplace', True)ch: チャンネル数を定義します
nc、アンカー: 修正クラスの数
.model: モデルを構築します ( ——> parse_model )
.names: カテゴリ名
.inplace: キーワードを読み込みます
建てる:
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward:[8, 16, 32]
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run onceモデルの上位層が検出層であるかどうかを判断する
m.stride: s*s ピクチャを予測用の低-中-高の特徴レベルに配置し、元のサイズを予測レイヤーのサイズで割ってステップ サイズを取得します。
m.anchors /=: アンカーをステップ サイズで割った値
check_anchor: 受信アンカーの順序を確認します。
forward: 入力画像を予測します
解析モデル:
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out.info: 情報を印刷します
yaml パラメータを取得します。
na: アンカーの数
no: 出力チャネル、nc(80)、5 (長方形ボックス内の 4 つの点 + 信頼度)、値は 255 です。
レイヤー (作成されたネットワークの各レイヤーのストレージ)、保存 (保存されるフィーチャ レイヤーの統計)
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
# 获取模型,这里主要是作者防止格式错误而不采取直接赋值
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
# 同理防止格式错误而不直接赋值
args[j] = eval(a) if isinstance(a, str) else a # eval strings, [64, 6, 2, 2]
except NameError:
passモデルと引数を取得します。作成者が書式設定エラーを防止し、直接代入を使用していないため、これがここに書かれている可能性があります。
次のステップでは、現在のネットワーク層が畳み込み層であるか、アップサンプリング層、検出層などであるかを判断し、それに応じて異なる処理を実行します。
# n>1就乘以深度倍数
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]] # args[3, 32, 6, 2, 2]
if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]m の場合: 構造体のタイプを決定します
畳み込み層: チャネル数が 255 であるかどうかを判断し、それ以外の場合はチャネルの倍数を乗算し、それが 8 の倍数であるかどうかを判断します (8 の倍数は GPU 計算に適しています)。
C3層:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)save.extend: 必要なフィーチャ レイヤー [4、6、10、14、17、20、23] を保存します。
ch.append(c2): 各レイヤーのチャンネル数を保存し、上位レイヤーの出力チャンネルをそのレイヤーの入力チャンネルとして使用します
共通.py:
簡単に理解するために Conv を例に挙げます。
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))コンバージョン:
初期化:
c1: このレイヤーのチャンネル数を入力します
c2: この層のチャンネル数を出力します。
k=1: コンボリューションカーネルのサイズ
s=1: 畳み込み層のスライディングのステップ サイズ
C3:
私の才能も知識も乏しいので、読者の皆様が記事の内容に誤りを発見された場合は、ご一報いただければ幸いです。