最近は検出関連の仕事をしていて、数年前にはfaster-rcnnのコードと論文を解析しました。それでは、最新かつ最速のモデルyolov5を整理してみましょう。このシリーズでは、Yolo の開発の歴史から始まり、損失関数、mAP の概念、そして最後にカスタマイズされたデータ セットをコード レベルでトレーニングする方法について説明します。さて、始めましょう~
1. YOLO(You Only Look Once)の開発経緯
この部分の内容は主に、Technology Beast @Zhihu が Zhihu に投稿した記事から借用したもので、ここでは簡略化して詳しく説明します
[1-3]。
1.1 YOLO v0
YOLO v0 のアイデアは、CNN の基本的なアイデアを分類タスクから検出まで拡張することから生まれました。そこで、まず、検出タスクと分類タスクの違いを見てみましょう。
- 検出: ネットワークの出力は、境界ボックス (長方形のボックス)の座標である必要があります (少なくとも 4 つの数値で表され、共通する数値は 2 つあります: (x1, y1, x2, y2)、(x1, y1, w、 h))。なぜ長方形のフレームが使用されるかというと、円や他の多角形と比較して、長方形のフレームの幾何学的特性により、追加の冗長コストを最小限に抑えてターゲット オブジェクトをフレーム化するのに適しているためです。

- 分類: 最も基本的な単一分類タスクを例に挙げます。単一分類とは、オブジェクトが 1 つのカテゴリにのみ属することを意味します。このタスクの特徴は、入力が画像で出力がそのカテゴリであることです。入力画像の場合、通常は Tensor を使用して表現し、その形状は [N, C, H, W] です。出力結果については、通常、ワンホット ベクトルを使用して次のように表します: [0, 0, 0, 1] [0, 0, 0, 1][ 0 ,0 、0 、1 ] (次元が 1) は、画像がどのカテゴリに属するかを表します。
さて、分類と検出の基本的な違いを理解した後、検出タスクをエルゴーディックな分類タスク(つまり、複数のターゲットの検出。画像内の 1 つのターゲット検出に最大 1 つのターゲットがあると判断される場合) とみなすことができます。は分類に似ています。ネットワーク設計とタスクの出力は似ていますが、最終的な完全接続層の活性化関数が異なります。
では、どうやってそれを横断するのでしょうか?RCNN クラス メソッドは、スライディング ウィンドウを通じて画像のすべての位置をトラバースし、各ボックスを分類します。
しかし、この方法には問題があり、トラバースの不完全さが精度に大きく影響します。トラバースが正確であればあるほど、検出器の精度は高くなりますが、同時にコストも高くなります。これは、画像全体をトラバースするために異なるスケールの bbox を考慮する必要があり、非常にコストがかかるためです。。。
例: たとえば、入力画像サイズは(320, 320) (320, 320)です。( 3 2 0 、3 2 0 )つまり、320 × 320 = 102, 400 320 \times 320 = 102, 4003 2 0×3 2 0=1 0 2 、400ポジション. _ 最小ウィンドウは(1, 1) (1, 1)( 1 、1 )、最大(320 × 320) (320 \times 320)( 3 2 0×3 2 0 )なので、走査回数は無限です。疑似コードを見てみましょう。
つまり、本質的にはバイナリ分類器をトレーニングしていることになります。このバイナリ分類子の入力はボックスの内容であり、出力は (前景/背景) です。
そして、さらに 2 つの疑問が生じます。
- ①フレームのサイズが異なる サイズの異なるフレームが同じ二分類器に入力されていませんか?
この状況に対処する必要があります。通常の方法は、2 つの分類器への入力を同じ固定サイズに変更することです。これは明らかに大きな問題を引き起こします。たとえば、2 つの分類器の固定入力テンソルの高さと幅は次のようになります。 64 . × 64 64 \times 646 4×6 4、フレームをスライドさせた後、一部のフレームのサイズは200 × 200 200 \times 200 に2 0 0×2 0 0、一部は10 × 10 10 \times 101 0×1 0 、これらの Bbox のサイズを64 × 64 64 \times 64に変更する必要があります。6 4×6と 4の bbox のみが2 つの分類器を入力できます。
- ②背景画像が多く前景画像が少なく、2分類サンプルのバランスが崩れている。
このスライディング ウィンドウ分類方法は非常に時間がかかり、クラスの不均衡の問題は深刻です。
これまでのところ、検出器は分類アルゴリズムを使用して設計されています。さまざまな問題があります。ここで最適化を行います (その後、正式に YOLO シリーズの手法に入ります)。
YOLO の作者は当時次のように考えました。分類器の場合、最後の完全に接続された層はワンホット ベクトルを出力し、それを (x, y, w, h, c) に置き換えます。c は信頼度を表します。したがって、問題を回帰問題に変換し、境界ボックスの位置を直接返す方がよいでしょうか?
さて、モデルは次のとおりです。

では、トレーニングをどのように組織するか? 自分で点データにラベルを付けます。ラベルを( 1 , x ∗ , y ∗ , w ∗ , h ∗ ) (1, x^*, y^*, w^*, h^*) に設定します。( 1 、バツ∗、y∗、w∗、h∗ )。こちら*** はグラウンド トゥルース (つまり、実際のラベル) を表します。データとラベルを使用してトレーニングを実行できます。
この方法は、先ほどのスライディング ウィンドウ分類方法よりもはるかに簡単であることがわかります。このバージョンのアイデアは、You Only Look Once の最も単純なバージョンであるため、YOLO v0 と呼ばれます。
1.2 YOLO v1
YOLO v1 は、YOLO v0 に基づいていくつかの問題を解決します。
- ① YOLO v0 は単一ターゲットの検出しか実行できないため、早急に拡張する必要があります。
YOLO v1 のソリューションのアイデアは、(c, x, y, w, h) を使用して、画像の特定のサブエリアのターゲットの入力を担当することです。
つまり、YOLO v0 の画像では (x、y、h、w、c) が 1 つだけ取得されますが、YOLO v1 では n (x、y、h、w、c) が取得されます。 x, y 
) , h, w, c) 欲しいリックとモーティの顔を手に入れるのはどうですか? ここで、YOLO v1 の作成者は NMS (非最大抑制) を使用して bbox をフィルタリングします。具体的なアルゴリズムは次のとおりです[1]。
NMS は、グラフ内にターゲットがいくつあるかわからないという問題を自動的に解決します。
- ② YOLO v0 は単一カテゴリの検出しか実行できないため、早急に拡張する必要があります。
一般的な検出タスクでは、多くのコンテンツを検出する必要があります。たとえば、リックとモーティの顔と望遠鏡の両方を検出する必要があります。では、どうすればよいでしょうか?
例として顔と望遠鏡の 2 つのカテゴリを取り上げ、ネットワークに N * (c, x, y, w, h) から N * (c, x, y, w, h, one-hot ) までのコンテンツを予測させます。次の図に示すように、2 つのカテゴリ、ワンホットは [0,1]、[1,0] です。
- ③小型ターゲットの検出
小さなターゲットは常に検出が不十分であるため、YOLO v1 は小さなターゲットに適合するニューロンを特別に設計します。
実際のコードでは、YOLO v1 は各領域に 2 つのクインタプル (c、x、y、w、h) を使用し、1 つは大きなターゲットを返す役割を担い、もう 1 つは小さなターゲットを返す役割を担います。ベクトル、1 - Hot は [0,1],[1,0] で、どのカテゴリ (顔または望遠鏡) に属するかを示します。

YOLO v1 の核心は、v0 と比較してこれら 3 つの問題を解決することです。そのアーキテクチャ図は次のとおりです (グリッドは画像を領域に分割する状況を表します。上記の例は 4x4 ですが、YOLO v1 では実際には 7x7 になります。は 20 カテゴリです):

1.3 YOLO v2
YOLO v1 は RCNN 検出アルゴリズムよりもはるかに高速ですが、予測フレームが不正確で、多くのターゲットが見つからないなどの問題がまだあります。
- ①YOLO v1で予測されたボックスが不正確である
この問題の主な理由は、YOLO v1 が bbox (x、y、w、h) を直接予測し、この値の範囲が非常に広いため、不正確さの問題が発生することです。CV タスクを実行するときに考えてみてください。画像処理を正規化し、一般的な 8 ビット画像 (0 ~ 255) を [0, 1] または [-1, 1] にスケールします。
YOLO v1 の位置を直接予測する戦略では、トレーニングの開始時にニューラル ネットワークが不安定になりますが、オフセットを使用するとトレーニング プロセスがより安定し、パフォーマンス指数が約 5% 向上します。
したがって、このアイデアと RCNN タイプのアイデアから学んでください。YOLO v2 は、bbox 座標を直接予測するのではなく、グリッドベースのオフセットとアンカーベースのオフセットを予測する方法を提案しています。
著者はこれを位置予測と呼んでいます。
-
グリッドに基づくオフセットとは、アンカーの位置が固定であることを意味し(アンカーは、データセット作成時にデータセット全体をクラスタリングして得られる固定アンカーである)、オフセット=対象位置-アンカー位置となる。
-
アンカーベースのオフセットは、グリッドの位置が固定されていることを意味し (グリッドは上記のリックとモーティの緑色のグリッドです)、オフセット = ターゲット位置 - グリッド位置です。
位置予測に関するイラスト、テクノロジー獣に関する Zhihu 記事より[2]、

上図に示すように、この画像を 9 つのグリッドに分割すると仮定すると、GT (グラウンド トゥルース) は赤枠で、アンカーは紫枠 ( ) で表示されます该Anchor是根据数据集的GT计算产生的,与目标GT的IoU最大的那个Anchor。画像内の数字は画像の実際の情報です。
YOLO v2 の予測値は、(x, y, h, w), x, y, h, w ∈ [0, 447] x, y, h, w \in [0,447]から得られます。× 、よ、h、w∈[ 0 ,4 4 7 ];变範囲tx , ty , tw , th t_x, t_y, t_w, t_ht×、tはい、tw、tふ以下に示すように、これらの値の範囲は狭いため、ネットワークの収束を検出するのに非常に役立ちます。

Ground Truth の赤い bbox の中心位置の座標は、それが配置されているグリッドの左上隅 (1, 1) と比較すると (1.543, 1.463) であることがわかります。
tx = log ( ( bboxx − cx ) / ( 1 − ( bboxx − c_x ) ) ) t_x = log((bbox_x - c_x) / (1 - (bbox_x - c_x)))t×=l o g ( ( b b o x×−c×) / ( 1−( bボックス_ _×−c×) ) )
ty = log ( ( bboxy − cy ) / ( 1 − ( bboxy − cy ) ) ) t_y = log((bbox_y - c_y) / (1 - (bbox_y - c_y)))tはい=l o g ( ( b b o xはい−cはい) / ( 1−( bボックス_ _はい−cはい) ) ) tw
= log ( gtw / pw ) t_w = log(gt_w / p_w)tw=l o g ( g tw/ pw)
th = log ( gth / ph ) t_h = log(gt_h / p_h)tふ=l o g ( g tふ/ pふ)
右下隅は YOLO v2 の改善点を具体的に示したもので、パラメータの意味は次のとおりです[2]。

-
② YOLO v1 では、マルチターゲット
やマルチカテゴリの検出では、ターゲットオブジェクトのサイズやアスペクト比が異なるため、多くのターゲットを見逃します。たとえば、歩行者は細長い箱ですが、車は四角い箱です。
これを踏まえ、YOLO v2 の作成者は、データセット内に比較的出現確率の高いバウンディングボックスをあらかじめいくつか用意し、それを予測の基礎としたのが、Anchor の本来の意図です。
具体的な方法は、YOLO v2 が画像を13 × 13 13 \times 13に分割することです。1 3×1 3 のエリア、各エリアには 5 つのアンカーがあり、各アンカーは 1 つのカテゴリに対応します。例として 2 つのカテゴリを取ると、次の式で計算されるように、ネットワークによって予測されるテンソルの最後の次元は 35 になります。 35 = 5 ×
( 5 ( c , tx , ty , tw , th ) + 2 クラス ) 35 = 5 \times (5 (c, t_x, t_y, t_w, t_h) + 2 クラス)3 5=5×( 5 ( c ,t×、tはい、tw、tふ)+2クラス)_ _ _ _ _ _- 各エリアの 5 つのアンカーはどのようにして入手されますか?
以下の図に示すように、COCO (紫色のアンカー) などのデータ セットについては、まずトレーニング セットの GT (グラウンド トゥルース) の境界ボックスをクラスター化し、それをいくつかのカテゴリにクラスター化します。実験後、著者は5 つのカテゴリの再現率と複雑さが優れていることを発見し、現在は 5 つのカテゴリにクラスタリングしています。もちろん、複雑なタスクの場合、カテゴリが多いほど、mAP が高くなり、最も包括的な予測になります。しかし、複雑さは大幅に増加します。同時に、モデルの精度はそれほど向上しません。そのため、比較的妥協的な方法を採用して 5 つのクラスターを選択します。つまり、5 つのアプリオリ ボックスが使用されます。

- 注: YOLO v2 のアンカーはデータセットの統計から取得されます (Faster-RCNN のアンカーの幅、高さ、サイズは手動で選択されます)。
- 各エリアの 5 つのアンカーはどのようにして入手されますか?
1.4 YOLO v3
この時点でYOLOの基本的な考え方は決まりましたが、YOLO v2の時点ではまだ小型ターゲットの検出に対する効果が十分ではありません(resnetがまだ出ていない…、特徴を抽出するためのネットワークが整っていません)十分ですよ〜)。
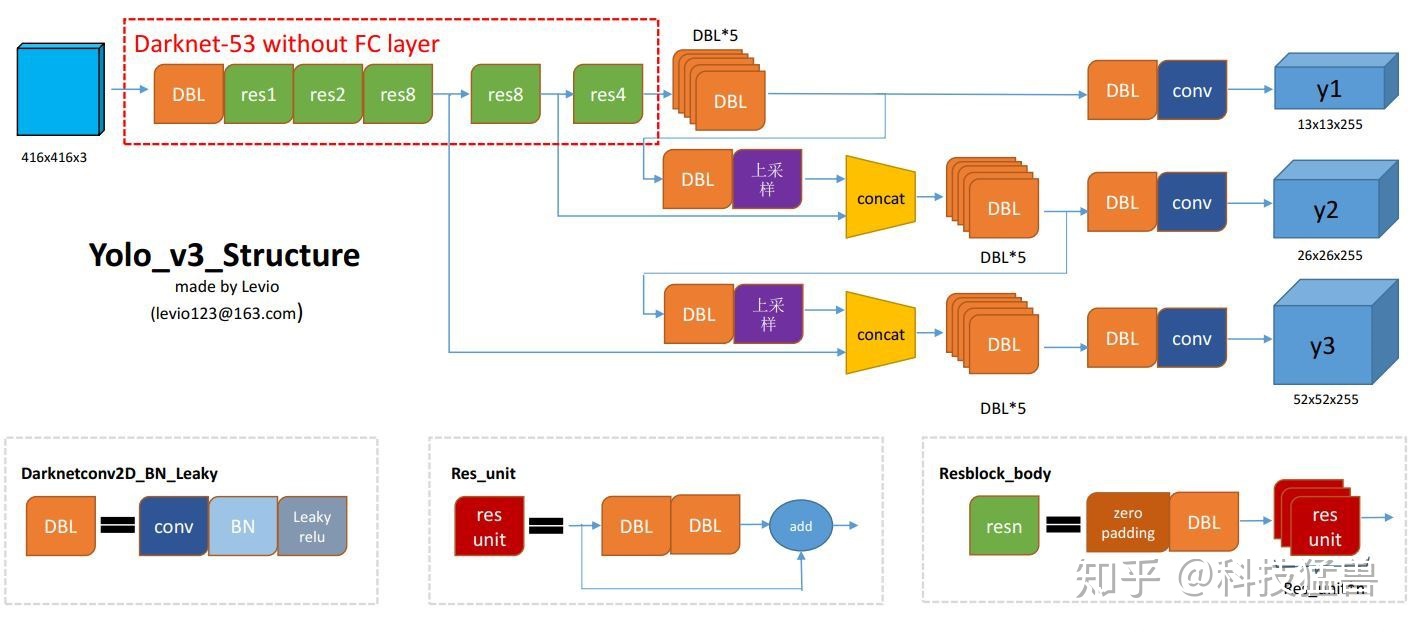
YOLO v3 の主な改善点は、マルチスケール予測の追加と、YOLO v2 のバックボーンを 19 層のダークネットから 53 層のダークネットに変更したことです[4]。
- ①マルチスケール予測
[2]
YOLO v3 検出ヘッドは分岐して 3 つの部分に分かれており、各次元には 3 つのアンカーがあります。
YOLO v3、合計 9 つのアンカー ボックスを使用します。スケールごとに 3 つ (大 3 つ、中 3 つ、小 3 つ)。独自のデータセットで YOLO をトレーニングしている場合は、K 平均法クラスタリングを使用して 9 つのアンカーを生成する必要があります。
[4]
- 13 * 13 * 3 * ( 4 + 1 + 2 ) 13*13*3*(4+1 + 2)1 3∗1 3∗3∗( 4+1+2 )
- 26 * 26 * 3 * ( 4 + 1 + 2 ) 26*26*3*(4+1 + 2)2 6∗2 6∗3∗( 4+1+2 )
- 52 * 52 * 3 * ( 4 + 1 + 2 ) 52*52*3*(4+1 + 2)5 2∗5 2∗3∗( 4+1+2 )

YOLO v2 と比較すると、YOLO v3 の予測 bbox 数は次のようになります:
(13 × 13 + 26 × 26 + 52 × 52) × 3 = 10467 (V 3) ≫ 845 (V 2) (13 × 13 × 5) ) (13 \times 13 + 26 \times 26 + 52 \times 52) \times 3 = 10467(V3) \gg 845(V2) (13 \times 13 \times 5)( 1 3×1 3+2 6×2 6+5 2×5 2 )×3=1 0 4 6 7 ( V 3 )≫8 4 5 ( V 2 ) ( 1 3×1 3×5 )
予測可能な境界ボックスがさらに多くなったことで、モデルの機能が明らかに強化されました。
公式の YOLO v3 モデルを以下に示します。
1.5 ヨーロ v4
Yolo v4 は、v3 に基づいていくつかの機能、主に 3 つの機能を追加します。
-
①単一のグラウンドトゥルースをマルチアンカーで使用する
従来のYOLO v3では、1つのGTを1つのアンカーで担当していましたが、YOLO v4では、複数のアンカーで1つのGTを担当します。メソッドは次のとおりです: GT j GT_jの場合G Tjたとえば、I o U ( anchor_i , GT j ) > しきい値 IoU(anchor_i, GT_j) > しきい値である限り、I o U (アンカー_ _ _ _ _私は、G Tj)>threshold ,就让 a n c h o r i anchor_i アンカー_ _ _ _ _私は担当してくださいGT j GT_jG Tj。
これは、アンカー ボックスの数は変わっていないが、選択されたポジティブ サンプルの割合が増加したことと同じであり、ポジティブ サンプルとネガティブ サンプルの不均衡の問題 (一般に背景が多すぎる) が軽減されます。 -
② Eliminate_grid 感度
以前の YOLO v2 のこの写真をまだ覚えていますか? YOLO v2 と YOLO v3 はすべてtx、ty、tw、th t_x、t_y、t_w、t_h を予測しますt×、tはい、tw、tふこれら 4 つのオフセット。

実はここに問題が隠れています。

-
③ CIoU Lossは
当面導入されません 詳細は技術獣ボスのZhihu記事を参照してください[2]。
1.6 YOLO v5
YOLO v5 は基本的に YOLO v3 の構造を変更します。以下の概要は、いくつかのモジュールに分かれています。
1.6.1 ネットワークモジュール
テイク(N, 3, 640, 640) (N, 3, 640, 640)( N 、3 、6 4 0 、6 4 0 )を例として、最も軽量な Yolov5s を例に挙げます。その構造は次のとおりです。

以下では、 Focus、BottleneckCSP、SPP、PANET の重要なモジュールについて詳しく説明します。このプロジェクトでは、モデルのトレーニングに YOLO v5s ネットワーク構造を使用するため、以下のネットワーク図と例はすべて YOLO v5s に基づいており、入力画像もは3x640x640です。
YOLO ネットワークは、次の 3 つの主要コンポーネントで構成されます。
1)バックボーン: さまざまな画像のきめの細かいレベルで画像特徴を集約して形成する畳み込みニューラル ネットワーク。
2)ネック: 画像の特徴を混合して結合し、画像の特徴を予測層に渡す一連のネットワーク層。(通常は FPN または PANET)
3)ヘッド: 画像の特徴を予測し、境界ボックスを生成し、カテゴリを予測します。
YOLO V5 1.0 で使用される重要なモジュールには、Focus、BottleneckCSP、SPP、PANET などがあります。モデルのアップサンプリングには、最近接 2 倍アップサンプリング補間が使用されますnn.Upsample(mode="nearest")。
YOLO V5 1.0 の COCO データ セット用にトレーニングされた Pretrained_model は、ネックとして FPN を使用していましたが、6 月 22 日以降、Ultralytics はモデルのネックを PANET に更新しました。インターネット上にある YOLO V5 のネットワーク構造紹介は FPN-NECK をベースにしたものが多いですが、本記事でのモデル学習は PANET-NECK をベースとしており、以下では PANET-NECK のみを紹介します。
YOLO V5 の場合、V5s、V5m、V5l、V5x のいずれであっても、バックボーン、ネック、ヘッドは同じです。唯一の違いはモデルの深さと幅の設定にあり、これら 2 つのパラメータを変更するだけでモデルのネットワーク構造を調整できます。V5l のパラメータはデフォルトのパラメータです。
•深さ倍数はモデルの深さを制御するために使用されます。たとえば、V5 の深さは 0.33 ですが、V5l の深さは 1 です。これは、V5l のボトルネックの数が V5 の 3 倍であることを意味します。
• width_multiple は、コンボリューション カーネルの数を制御するために使用されます。V5s の幅は 0.5 ですが、V5l の幅は 1 です。これは、V5s のコンボリューション カーネルの数がデフォルト設定の半分であることを意味します。 1.25 倍、つまり V5x に設定します。たとえば、以下の YOLO V5 の yaml ファイルのバックボーンの最初のレイヤーは [[-1, 1, Focus, [64, 3]] で、V5s の幅は 0.5 であるため、このレイヤーは実際には [[- 1、1、フォーカス、[32、3]]。
私の目標は非常に軽量な検出モデルであるため、 yolov5s のモデル定義ファイルは次のように考えるだけです: yolov5s.yaml(COCO データセットの場合)、上の図とよく一致していることがわかります。
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
Focus
下の図は、YOLO V5 の Focus インターレース サンプリング スプライシング構造を示しています。

YOLO V5 のデフォルトの入力は 3x640x640 です。フォーカス レイヤーの機能は、それを 4 つのコピーにコピーし、スライス操作によって 4 つの画像を 4 つの 3x320x320 のスライスにカットすることです。次に、concat を使用して 4 つのスライスを深さから接続します。出力は 12x320x320 で、畳み込みカーネル番号 32 の畳み込み層を通過して 32x320x320 の出力が生成され、最後に結果は、batch_norm と Leaky_relu を介して次の畳み込み層に入力されます。
フォーカス レイヤーの効果は次のとおりです: 4 × 4 4 \times 44×4の画像を例にとると、左の画像が元の入力画像、右の画像がフォーカス処理後の特徴マップです。

現時点(2020.09.28)の実装はこんな感じで[5]、YOLO v2のパススルーと同じです。

核となるのはこのコードですself.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))。x[..., ::2, ::2]それは黄色の部分、赤のx[..., 1::2, ::2]部分、緑の部分などです。x[..., ::2, 1::2]
-
BottleneckCSP
下の図は、YOLO V5 の最初の BottlenneckCSP 構造を示しています。BottlenneckCSP が 2 つの部分、 BottlenneckとCSPに分かれていることがわかります。

その中で、Bottleneckこれは古典的な残差構造です。最初に 1x1 畳み込み層 (conv+batch_norm+leaky relu)、次に 3x3 畳み込み層、そして最後に残差構造が初期入力に追加されます[6]。YOLO V5 は、深さ倍数

によってモデルの深さを制御することに注意してください。たとえば、V5s の深さは0.33ですが、V5l の深さは1です。つまり、V5l の BottlenneckCSP のボトルネックの数は次のようになります。 V5 の 3 倍 モデル内の最初の BottlenneckCSP デフォルトのボトルネック数は x3 です。V5 の場合、上の図にはボトルネックが 1 つだけあります。著者のコードは次のとおりです. eはwidth_multipleであり、現在の操作の畳み込みカーネルの数とデフォルトの数の比率を示します
[7]。

上記の BottleneckCSP コードからわかるように、分岐を次のように分割します。 2 つのブロックはブランチ y1 と y2 に分割され、
ブランチ 1 (y1) はボトルネック * N の演算を実行し、ブランチ 2 (y2) はチャネル リダクションを実行します。最後に 2 つのブランチを連結して、次の一連の演算を実行します
。 bn、act、および Conv (以下の図は、Knowledge Hufa の記事の William からのものです[6])。

-
SPP
SPP は空間ピラミッド層 (空間プーリング層) であり、入力は 512x20x20、1x1 畳み込み層後の出力は 256x20x20 で、その後、異なる kernel_size (5、9、13) の 3 つの並列 Maxpool によってダウンサンプリングされます。異なるブランチに対して注意してください。 、パディング サイズは [5,9,13]//2 です。さらに、stride=1 であるため、各プーリング後の結果は 256x20x20 となるため、結果を結合してその初期機能である出力 1024x20x20 に追加できます。最後に、512 のコンボリューション カーネルを使用して、512x20x20 に復元します (下の写真は、Technology Beast による Zhihu の記事からのものです[3])。

-
PANet
PAN 構造は、Path Aggregation Network という論文から来ています[8]。その本来の目的は、インスタンス セグメンテーション タスク (インスタンス セグメンテーション) で使用されることです。そのモデル構造は次のとおりです。この

ネットワークの特徴抽出器は、新しく強化されたボトムアップ (ボトムアップ)を採用しています。 ) パス FPN 構造により、低レベルの機能の伝播が改善されます (パート a)。3 番目のパスの各ステージは、前のステージの特徴マップを入力として受け取り、3x3 畳み込み層で処理します。出力は、横方向の接続を介してトップダウン経路の同じステージの特徴マップに追加され、これらの特徴マップは次のステージ (パート b) の情報を提供します。同時に、適応特徴プーリングを使用して、各候補領域とすべての特徴レベルの間の損傷した情報パスを復元し、各特徴レベルで各候補領域を集約し、恣意的に割り当てられるのを回避します (パート c)。
YOLO V5 は、YOLO V4 から変更された PANET 構造を借用しています。PANET は通常、適応特徴プーリングを使用して、マスク予測のために隣接するレイヤーを一緒に追加します。ただし、YOLO v4 で PANET を使用する場合、この方法は少し面倒であるため、YOLO v4 の作成者は、適応特徴プーリングを使用して隣接レイヤーを追加する代わりに、Concat 操作を実行して、予測の精度を向上させています。

YOLO V5 もカスケード動作を使用します。詳細については、モデルの大きな画像と、Netron ネットワーク図の対応する Concat 操作を参照してください。

1.6.2 データ処理の改善
以下の内容は、 Technology Beast による
[3]Zhihu の記事からの転載です
- モザイクデータの強化
[3]

CutMix はスプライシングに 2 つのピクチャのみを使用しますが、モザイク データ エンハンスメントでは、ランダム スケーリング、ランダム クロッピング、およびランダムな配置により、スプライシングに 4 つのピクチャを使用します。
その主な利点は次のとおりです。
①データセットを強化する: 4 枚の画像をランダムに使用し、それらをランダムにスケーリングし、それらをランダムに分配してスプライシングすることで、検出データセットが大幅に強化されます。特に、ランダムスケーリングにより、多数の小さなターゲットが追加され、ネットワークがより堅牢になります。
② GPU 使用量の削減: ランダム スケーリングや通常のデータ強化もできるという人もいるかもしれませんが、著者は多くの人が GPU を 1 つしか持たない可能性があると考えているため、Mosaic 強化トレーニング中に 4 枚の画像のデータを直接計算できます。 Mini の作成 - バッチ サイズはそれほど大きくする必要はなく、GPU を使用するとより良い結果が得られます。
- 適応型アンカーフレーム計算
[3]
Yolo アルゴリズムでは、さまざまなデータセットに対して、最初に設定された長さと幅を持つアンカー ボックスが存在します。
ネットワークのトレーニング中、ネットワークは最初のアンカー フレームに基づいて予測フレームを出力し、それを実際のフレームのグランド トゥルースと比較し、2 つの差を計算して、ネットワーク パラメーターを反復して逆に更新します。
したがって、最初のアンカー ボックスも重要な部分です。たとえば、Yolov5 によって Coco データ セットに最初に設定されたアンカー ボックスです。Yolov3

と Yolov4 では、異なるデータ セットをトレーニングするときに、最初のアンカー ボックスの値は別のメソッドを通じて計算されます。プログラムです。
ただし、Yolov5 はこの関数をコードに埋め込み、各トレーニング中に異なるトレーニング セットで最適なアンカー ボックスの値を適応的に計算します。
もちろん、計算されたアンカー ボックスの効果があまり良くないと思われる場合は、コード内でアンカー ボックス関数の自動計算をオフにすることもできます[9]。
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
- 適応型画像スケーリング
[3]
一般的なターゲット検出アルゴリズムでは、画像ごとに長さと幅が異なるため、一般的な方法は、元の画像を標準サイズに均一に拡大縮小してから、検出ネットワークに送信することです。
たとえば、416 × \times はYolo アルゴリズムでよく使用されます。× 416,608× \回たとえば、 × 608 および他のサイズでは、図に示すように、以下の 800*600 の画像を拡大縮小します。 ただし、

これは Yolov5 コードで改善されており、Yolov5 の推論速度を高速化する優れたトリックでもあります。
実際にプロジェクトを使ってみると、アスペクト比の異なる写真が多く、拡大縮小して塗りつぶした後の両端の黒縁の大きさが異なり、さらに塗りつぶすと情報の冗長性が生じてしまうのではないかと筆者は考えています。推論速度に影響します。
そこで、図に示すように、元の画像に最小限の黒エッジを適応的に追加するようにYolov5コードdatasets.pyの関数を修正しました。画像高さの両端の黒エッジが減少し、計算量も減少します。推論時の誤差が軽減され、ターゲットの検出速度が向上します。letterbox

この単純な改善により、推論速度が 37% 向上しており、明らかな効果があると言えます。
Yolov5 の塗りつぶしは灰色、つまり (114, 114, 114) であり、同じ効果があり、黒いエッジを減らす方法はトレーニング中に使用されませんが、従来の塗りつぶし方法が使用されます。つまり、次のようにスケーリングされます。 416*416サイズ。モデル推論をテストして使用する場合にのみ、ターゲットの検出と推論の速度を向上させるために黒エッジを削減する方法が使用されます。
- 陽性サンプルが増加
[3]
これは、YOLO v4 の「単一のグラウンド トゥルースにマルチアンカーを使用する」と同じです。

2. まとめ
下の図はYOLOシリーズの各世代の特徴を筆者がまとめたものですが、このうちLoss部分についてはシリーズ3で取り上げます。

参考記事
[1]こんなにわかりやすいYOLOシリーズ(v1からv5まで)のモデル解釈(前編) [2]
こんなにわかりやすいYOLOシリーズ(v1からv5まで)は見たことがないv5) モデルの解釈 (その 2)
[3]こんなにわかりやすい YOLO シリーズ (v1 から v5 まで) のモデルの解釈 (その 2)
[4] YOLO v3 の新機能
[5]フォーカスYOLO v5 のレイヤー
[6] YOLO V5 を使用して自動運転目標検出ネットワークをトレーニング
[7] YOLO v5 のボトルネックレイヤー
[8]インスタンスセグメンテーションのためのパス集約ネットワーク: CVPR2018
[9] YOLO v5 コード train.py