序章
序文
記事ディレクトリ
データはシステム自体よりも長持ちする貴重なものです。
基本的なデータ構成とデータ処理の方法:
- 各種データの論理構造記述。
- さまざまなデータのストレージ構造表現。
- さまざまなデータ構造の操作定義。
- 操作を実装するためのアルゴリズムを設計します。
- アルゴリズムの効率を分析します。
学習目標
- データ構造の基本的な概念、原則、方法をマスターします。
- データの論理構造、ストレージ構造、基本操作の実装プロセスをマスターします。
- アルゴリズムの基本的な時間計算量と空間計算量の解析手法を習得し、問題を解決するための効率的なアルゴリズムを設計できるようになります。
勉強法
- さまざまなデータ構造の論理プロパティと記憶構造の設計を理解します。
- 各種データ構造のアルゴリズム設計の基本手法をマスターします。
- さまざまなデータ構造を使用して実際的な問題を解決します。
- 演繹と帰納を組み合わせます。
A. データ構造とは何ですか
1.データ:
コンピュータに入力し、コンピュータで処理できるすべてのシンボルの集合。
2.データ項目:
データの最小単位であるデータ要素を記述するために使用されます。
3.データ オブジェクト:
同じ性質を持つ複数のデータ要素のコレクション。たとえば、整数データ オブジェクトはすべての整数のコレクションです。
4.データ構造:
構造化されたデータ要素の組み合わせを指します。
データ構造 = データオブジェクト + 構造
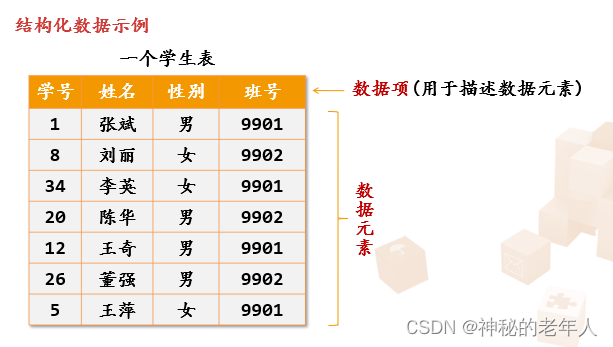
データ構造で説明する要素関係は、主に隣接関係または隣接関係を指します。
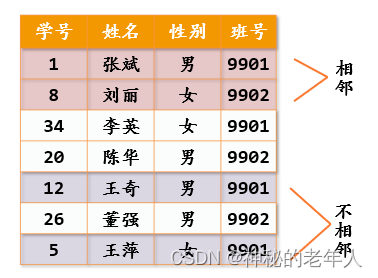
データ構造の構成
論理構造 + 記憶構造 + データ操作
-
論理構造:
データ要素間の論理関係。
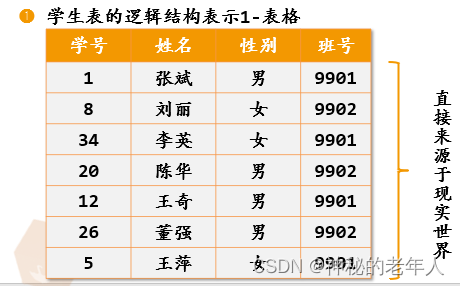
Student テーブルの論理構造は 2 タプルの配列で表現されており、一般的な論理構造の表現方法です。

-
ストレージ構造:
データ要素とその関係をコンピューターのメモリに保存する方法。 -
データ操作:
データに適用される操作。
1. データの論理構造表現
それぞれの関係は、いくつかのシーケンス ペアで表されます。
シーケンス ペア<x,y>(x,y ∈ \in∈ D)⇒ \Rightarrow⇒ x は最初の要素、y は 2 番目の要素です。
x は y の先行要素であり、y は x の後続要素です。
要素に先行要素がない場合、その要素は開始要素であり、要素に後続要素がない場合、その要素は終了要素です。
シーケンスペア <x, y> は x、y が方向付けられていることを意味し、シーケンスペア (x, y) は x、y が単一であることを意味します。



2. データストレージ構造の表現
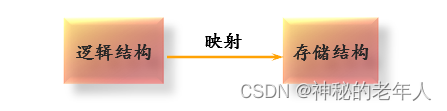
このようなストレージ構造のマッピングを設計するには、次の 2 つの要件を満たす必要があります。
- すべての要素を保存する
- データ間の関係を保存する
1. Student テーブルのストレージ構造 1 - 構造配列

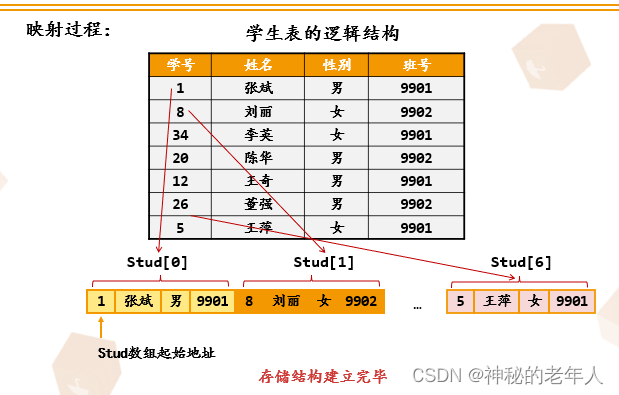
このことから、論理的に隣接する 2 つの要素には隣接する記憶スペースがあることがわかります。
このストレージスペース構造(シーケンシャルストレージ構造)の特徴は次のとおりです。
- すべての要素はメモリ空間のブロック全体を占有します。
- 論理的に隣接する要素は物理的にも隣接します。
2. Student テーブルのストレージ構造 2 - リンクされたリスト

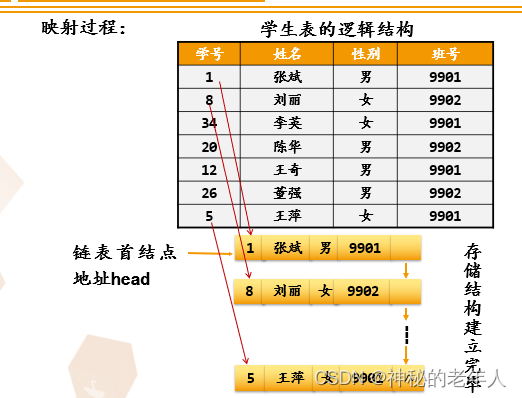
このストレージ構造 (チェーンストレージ構造) の特徴:
- 論理要素はノードに格納され、各ノードは個別に割り当てられ、すべてのノードのアドレスは連続しているとは限りません。
- ポインタを使用して論理関係を表します。
3. データ操作
データ操作は、
操作記述と操作実現の 2 つのレベルに分かれています。


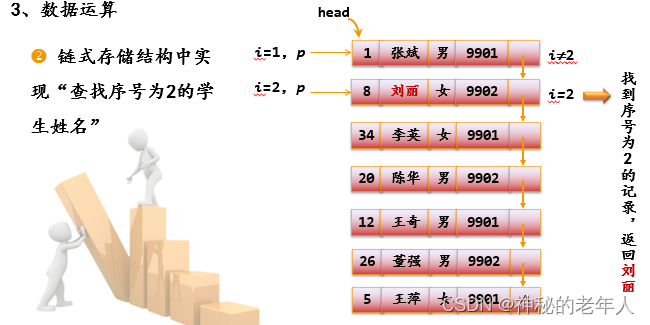
結論は:
- 同じ論理構造は複数のストレージ構造に対応できます。
- 同じ操作でも、ストレージ構造が異なれば、その実装プロセスも異なります。
1. 論理構造の種類
1.コレクション
要素間の関係:なし
特徴:データは同じコレクションに属します。

2. 線形構造
要素間の関係: 1 対 1
特徴: 開始要素と終了要素は一意であり、残りの要素は 1 つの先行要素と 1 つの後続要素のみを持ちます。

3. ツリー構造
要素間の関係:1対多
特徴:先頭要素は一意であるが、終端要素は一意ではない。さらに、各要素には 1 つ以上の後続要素 (終端要素を除く) があり、各要素には 1 つだけの先行要素 (開始要素を除く) があります。
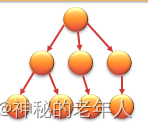
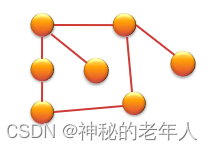
4. グラフィック構造
要素間の関係: 多対多
特徴: すべての要素は複数の先行要素と複数の後続要素を持つことができます。
2. ストレージ構造のタイプ
- シーケンシャルストレージ構造
- チェーンストレージ構造
- インデックスストレージ構造
- ハッシュストレージ構造
データ型と抽象データ型
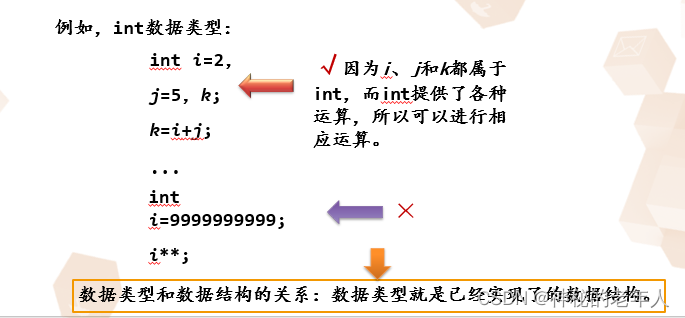
1. データ型:
値の集合と、この集合に対して定義される演算の集合の総称です。
2. 抽象データ型 (ADT):
コンピュータの動作を考慮せず、問題を解決するための数理モデルから抽象化されたデータ構造と演算を指します。
抽象データ型 = 論理構造 + 抽象操作

B. アルゴリズムとは何ですか
ストレージ構造に基づく操作によって実装されるステップまたはプロセスは、通常、アルゴリズムと呼ばれます。
1. アルゴリズムの 5 つの重要な特徴
- 有限性: 有限数のステップが終了すると、アルゴリズムは停止できます。
- 確実性: 曖昧さはありません。
- 実現可能性: 基本操作の限られた回数の実行によって実現可能、つまり、各動作を機械的に実行できます。
- 入力: 0 個以上の入力。
- 出力: 1 つ以上の出力。
2. アルゴリズムとプログラムの違い
プログラムとは、特定のコンピューター言語でのアルゴリズムの特定の実装とその実行方法を指します。アルゴリズムは、問題を解決するための方法、つまり何をすべきかを記述することに重点を置いています。アルゴリズムをコンピュータ言語で記述してプログラムを得る。
3. アルゴリズムの説明
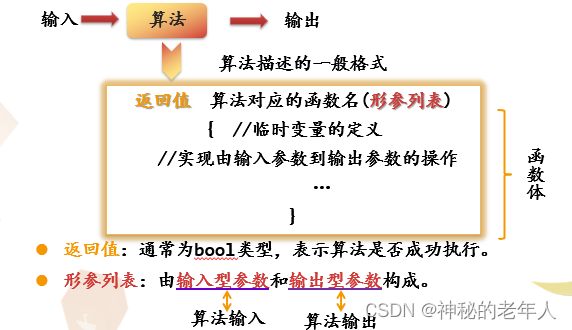
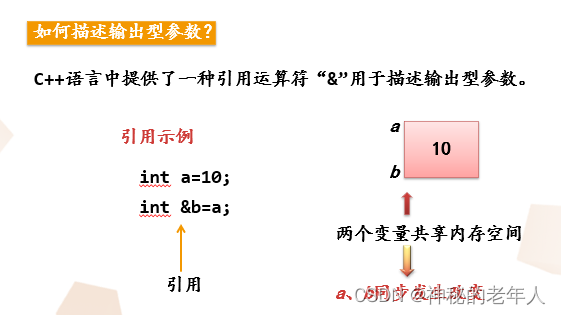
パラメーターの受け渡し:
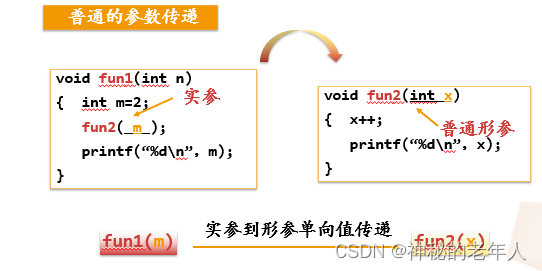
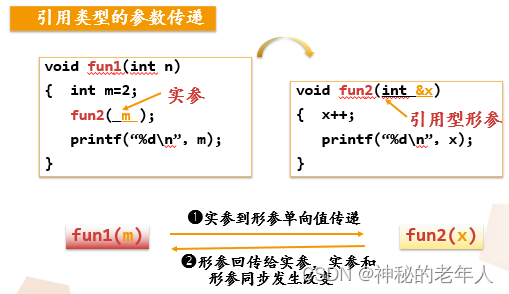
たとえば、アルゴリズム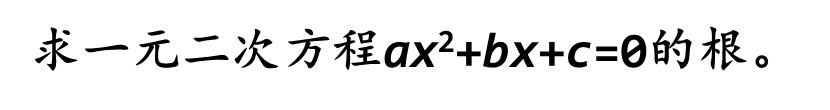
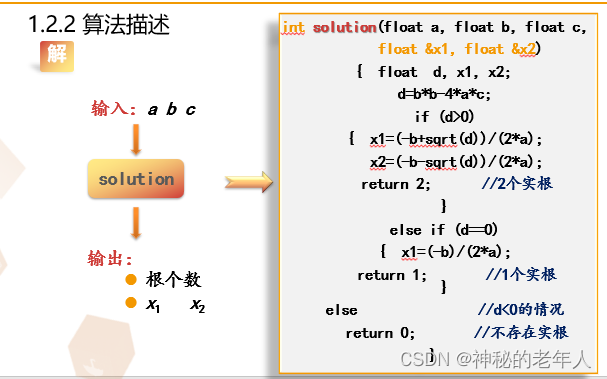
コードの実装を設計します。
#include<iostream>
#include<cmath>
using namespace std;
void solution(float a, float b, float c, float& x1, float& x2);
int main()
{
float a, b, c,m,x1,x2;
cout << "请输入a,b,c的值:" << endl;
cout << "a=";
cin >> a;
cout << "b=";
cin >> b;
cout << "c=";
cin >> c;
cout << "求得的方程的根为:";
solution(a, b, c, x1, x2);
return 0;
}
void solution(float a, float b, float c, float& x1, float& x2)
{
float d;
d = b * b - 4 * a * c;
if (d > 0)
{
x1 = (-b + sqrt(d)) / (2 * a);
x2 = (-b - sqrt(d)) / (2 * a);
cout << x1 << " " << x2 << endl;
}
else if (d == 0)
{
x1 = (-b) / (2 * a);
cout << x1 << endl;
}
else
cout << "该方程无实根!";
}
4. アルゴリズム解析
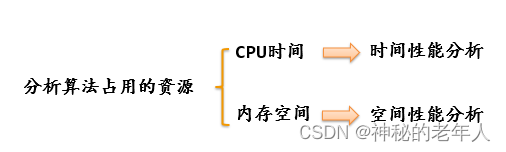
アルゴリズム分析の目的:
アルゴリズムのパフォーマンスを向上させるために、アルゴリズムの時空間効率を分析すること。
1. アルゴリズムの時間計算量分析
アルゴリズムは、制御構造(シーケンス、分岐、ループ) と基本操作で構成されます。

シーケンシャル構造: 説明されている順序で処理します。
分岐構造:判定条件に応じて実行フローを変更する
ループ構造:条件が真の場合、与えられた処理を繰り返し実行する。
元の演算: +、-、*、/、++、- などの固有のデータ型の演算を指します。
アルゴリズムの実行時間は、この 2 つの効果の組み合わせによって異なります。
例えば:

アルゴリズム解析手法
1. 事後分析および統計手法:
アルゴリズムに対応するプログラムを作成し、その実行時間をカウントします。

2. 事前推定と分析方法:
上記の要因はさておき、アルゴリズムの実行時間は問題サイズ n の関数であると考えられます。
アルゴリズムの実行時間の分析
- アルゴリズムの元のすべての演算の実行回数 (頻度とも呼ばれます) を求めます。これは、問題サイズ n の関数であり、T(n) で示されます。
- アルゴリズムの実行時間はおおよそ = 元の演算に必要な時間 * T(n) となります。したがって、T(n) はアルゴリズムの実行時間に比例します。この目的のためのアルゴリズムの実行時間を T(n) とします。
- さまざまなアルゴリズムの T(n) サイズを比較すると、アルゴリズムの実行時間のパフォーマンスがわかります。
T(n) は、n 個のレコードの並べ替えなど、解の問題のサイズを表す正の整数です。
例: 次数 n の 2 つの正方行列の加算 C=A+B を求めるアルゴリズムは次のとおりであり、その時間計算量が分析されます。
疑似コード:
#define NAX=28
voidmatrixadd(int n,int A[MAX][MAX],int B[MAX][MAX],int C[MAX][MAX])
{
int i,j;
for(i=0;i<n;i++) //1
for(j=0;j<n;j++) //2
C[i][j]=A[i][j]+B[i][j]; //3
}
変数定義ステートメントに加えて、アルゴリズムには 3 つの実行可能ステートメント 1、2、および 3 が含まれています。
1. 頻度は n+1 で、ループ本体は n 回実行されます。
2. 周波数は n*(n+1) です。
3. 周波数は n*n です。
したがって、すべてのステートメントの頻度の合計は次のようになります。
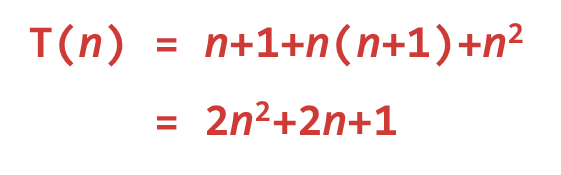
アルゴリズムの実行時間は時間計算量で表されます。
アルゴリズムの実行時間 T(n) は、問題サイズ n の特定の関数 f(n) が記録されます。
T(n)=O (f(n))
「O」は、問題サイズ n の増加に伴うアルゴリズム実行時間の増加率が f(n) の増加率と同じであることを意味します。
"O" の形式は次のように定義されます:
T(n)=O(f(n)) は正の定数 c が存在することを意味し、n>=n0 の場合、次の条件が満たされます: |
T(n)|< =|c(f (n)|
f(n) は T(n) の上限です。
通常、

T(n) の最高次数のみが取得され、その下位項目と定数係数は次のようになります。 T(n) を簡素化できるように無視する n が非常に大きい場合、計算はアルゴリズムの時間パフォーマンスを客観的に反映できます
。
- ループを使用しないアルゴリズムの実行時間は、問題のサイズ n (定数順序とも呼ばれる 0(1) で示される) には依存しません。
- 1 サイクルのみのアルゴリズムの実行時間は、問題サイズ n (0(n) で示される) の増加に伴って直線的に増加します。これは線形順序とも呼ばれます。

さまざまなアルゴリズムの時間計算量の比較関係は次のとおりです。

アルゴリズム時間パフォーマンスの比較:
同じ問題に対して 2 つのアルゴリズム A と B がある場合、アルゴリズム A の平均時間計算量が 0(n) である場合、平均時間計算量は 0(n) です。アルゴリズム B の複雑さは次数が 0(n*n) です。
一般に、アルゴリズム A の時間パフォーマンスはアルゴリズム B よりも優れていると考えられます。
簡略化されたアルゴリズムの時間計算量分析
アルゴリズムの基本操作は、通常、最も深いループ内の基本的な操作です。
アルゴリズム実行時間の概略 = 基本演算に必要な時間 * 演算数
アルゴリズム解析では、T(n) を計算するときに基本演算の演算数のみが考慮されます。
最良、最悪および平均時間複雑さの分析
定義: アルゴリズムの入力サイズを n とします。Dn はすべての入力、任意の入力 I ∈ \inの集合です。∈ Dn,P(I) は I が出現する確率であり、∑ \displaystyle\sum∑ P(I)=1、T(I) はアルゴリズム入力 I での実行時間であり、アルゴリズムの平均時間計算量は次のようになります。 たとえば、1 から 10 までの 10 個の整数シーケンスが増分的にソートされます
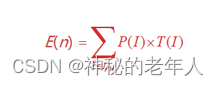
。(n=10):

考えられる初期シーケンスはすべて m 個あり、m=10! ⇒ \Rightarrow⇒ P(I)=1/m。


解決策:
アルゴリズムの主な時間は要素の比較に費やされます。
- i の値の範囲は 1 ~ n で、合計 n 通りあります。
- 等確率の場合(各場合の確率は1/n)。
- 最初の i 要素の最大値 (max=a[0]) を見つける場合は、それを a[1...i-1] 要素と比較します。比較回数 = (i-1)-1+1=i-1 回。

- i=1 の場合、比較回数は 0 ⇒ \Rightarrow⇒アルゴリズムの最高の複雑さは B(n)=0(1) です。
- i=nの場合、比較回数はn-1 ⇒ \Rightarrow⇒アルゴリズムの最悪の複雑さ W(n)=0(n)。
2. アルゴリズム空間の複雑性の解析
空間複雑度:
アルゴリズムが動作中に一時的に占有するメモリ空間のサイズを測定するために使用されます。
一般に、これは問題サイズ n の関数としても使用され、次のように記録される大きさの順序で記述されます。
S(n)=0(g(n))
アルゴリズムの空間複雑度が0(1) の場合、アルゴリズムはインプレース ワークまたはワークインプレース アルゴリズムと呼ばれます。
スペースの複雑さは、一時的に占有されるストレージスペースを考慮します

