前に書かれている:
このブログでは主に、Baidu Feizhi の yolov3 モデルを使用して水中の小さなターゲット (ウニ、ヒトデなど) を検出する方法を紹介しています。 現在の mAP 値は 47% に達しており、トレーニング ラウンドの数が増えるにつれて増加する可能性があります。このブログでは主にSSR画像の補正、PaddleDetectionの導入、yolov3の利用、モデルの評価と予測を行っています。
記事で使用されている一部のリソースはパッケージ化され、アップロードされています:
(元のデータ セット、SSR 処理後の画像セット、現在の PaddleDetection 圧縮パッケージ、mAP 値 47% の best_model を含む)

リンク:
https://pan.baidu.com/ s /11T4zwqtvkfbiK3VFATt6MA
抽出コード: n2ik
リンク:
https://aistudio.baidu.com/aistudio/datasetdetail/171095
(SSR 処理後のデータセットはチラシで直接使用できます。いいね、ありがとうございます)
本文は次のように始まります。
SSR画像処理
SSR の紹介:レティネックス理論はランドとマッキャンによって始まりました。その基本的な考え方は、人間が知覚する点の色と明るさは、その点で人間の目に入る絶対的な光に依存するだけでなく、色にも関係するというものです。そして周りの明るさ。その基本的な内容は、物体の色は、反射光の絶対値ではなく、長波 (赤)、中波 (緑)、短波 (青) の光を反射する物体の能力によって決まるというものです。色は照明の不均一性の影響を受けず、一貫性を持っています。つまり、Retinex は色の一貫性 (色の恒常性) に基づいています。
つまり、指定された画像 S(x,y) は、反射画像 R(x,y) と輝度画像 L(x,y) の 2 つの異なる画像に分解できます。Retinex アルゴリズムが行う必要があるのは、削除または削減することです。オブジェクトの元の外観を取得するための L(x,y) の効果。
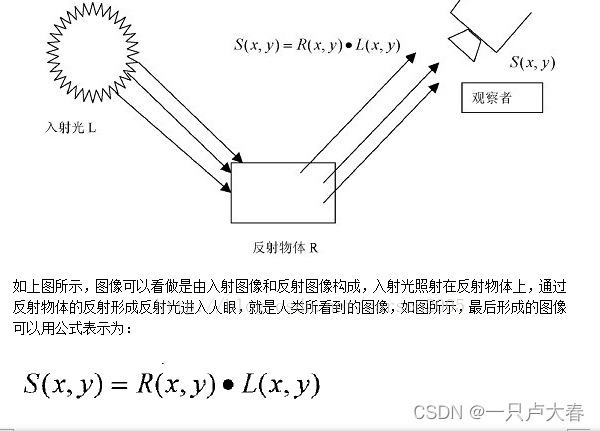
シングルスケール Retinex アルゴリズムとして、SSR は最も基本的で最も単純な Retinex アルゴリズムです。
実装プロセスは次のとおりです。

Matlab コードの実装:
**********************matlab代码*****************************
clear;clc
Input_path = '***'; %图片输入路径
Output_path='***'; %图片输出路径
namelist = dir(strcat(Input_path,'*.jpg')); %获得文件夹下所有的 .jpg图片
len = length(namelist);
for i = 1:len
name=namelist(i).name; %namelist(i).name; %这里获得的只是该路径下的文件名
I=imread(strcat(Input_path, name)); %图片完整的路径名
R = I(:, :, 1);
[N1, M1] = size(R);
R0 = double(R);
Rlog = log(R0+1);
Rfft2 = fft2(R0); %二维傅里叶变换
sigma = 250;
F = fspecial('gaussian', [N1,M1], sigma); %对图像进行高斯滤波 sigma指定滤波器的标准差
Efft = fft2(double(F));
DR0 = Rfft2.* Efft; %低通滤波图像D(x,y)=S(x,y)*F(x,y) S为原图像 F为高斯滤波函数
DR = ifft2(DR0); %二维离散傅里叶逆变换
DRlog = log(DR +1);
Rr = Rlog - DRlog; %高频增强图像G(x,y)=logS(x,y)-logD(x,y)
EXPRr = exp(Rr); %对G(x,y)取对数,得到增强后的图像R(x,y)
MIN = min(min(EXPRr));
MAX = max(max(EXPRr));
EXPRr = (EXPRr - MIN)/(MAX - MIN); %归一化
EXPRr = adapthisteq(EXPRr); %直方图均衡
%重复其他两个通道的变换,过程同上
G = I(:, :, 2);
G0 = double(G);
Glog = log(G0+1);
Gfft2 = fft2(G0);
DG0 = Gfft2.* Efft;
DG = ifft2(DG0);
DGlog = log(DG +1);
Gg = Glog - DGlog;
EXPGg = exp(Gg);
MIN = min(min(EXPGg));
MAX = max(max(EXPGg));
EXPGg = (EXPGg - MIN)/(MAX - MIN);
EXPGg = adapthisteq(EXPGg);
B = I(:, :, 3);
B0 = double(B);
Blog = log(B0+1);
Bfft2 = fft2(B0);
DB0 = Bfft2.* Efft;
DB = ifft2(DB0);
DBlog = log(DB+1);
Bb = Blog - DBlog;
EXPBb = exp(Bb);
MIN = min(min(EXPBb));
MAX = max(max(EXPBb));
EXPBb = (EXPBb - MIN)/(MAX - MIN);
EXPBb = adapthisteq(EXPBb);
result = cat(3, EXPRr, EXPGg, EXPBb); %联结数组
imwrite(result,[Output_path,num2str(i,'%06d'),'.jpg']); %完整的图片存储的路径名 处理为六位数字
end
以下は SSR 処理後の写真の比較です.



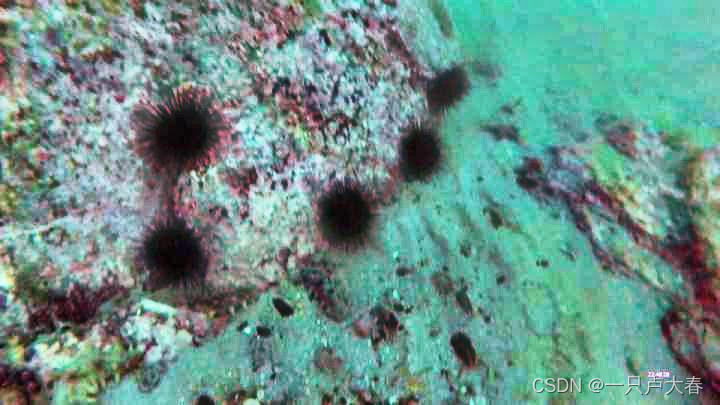
SSR 効果は水中画像の処理に依然として非常に優れていることがわかります, これは Retinex 理論とも一致しています: カラー画像強調、画像曇り除去に優れた効果があります。 、およびカラー画像の復元。
PaddleDetection の導入
はじめに: PaddleDetection は、PaddlePaddle に基づくエンドツーエンドのターゲット検出スイートであり、30 を超えるモデル アルゴリズムと 250 を超える事前トレーニング済みモデルが組み込まれており、ターゲット検出、インスタンス セグメンテーション、追跡、キー ポイント検出などをカバーします。サーバーおよびモバイル高精度、軽量の産業レベルの SOTA モデル、チャンピオン ソリューション、学術最先端のアルゴリズムを提供し、構成可能なネットワーク モジュール コンポーネント、10 種類以上のデータ拡張戦略と損失関数、その他の高レベルの最適化サポートと複数の機能を提供します。展開ソリューション: 処理、モデル開発、トレーニング、圧縮、展開のプロセス全体に基づいて、アルゴリズム業界のアプリケーションを加速するための豊富な事例とチュートリアルを提供します。

PaddleDetection の詳細については、https://gitee.com/paddlepaddle/PaddleDetection
導入プロセスを参照してください。
(次のコードは、Baidu Flying Aistudio で実行する必要があります。または、プロジェクト リンクに直接アクセスし、「いいね!」をクリックして、ありがとうございますあなた)
step1: プロジェクトを作成する
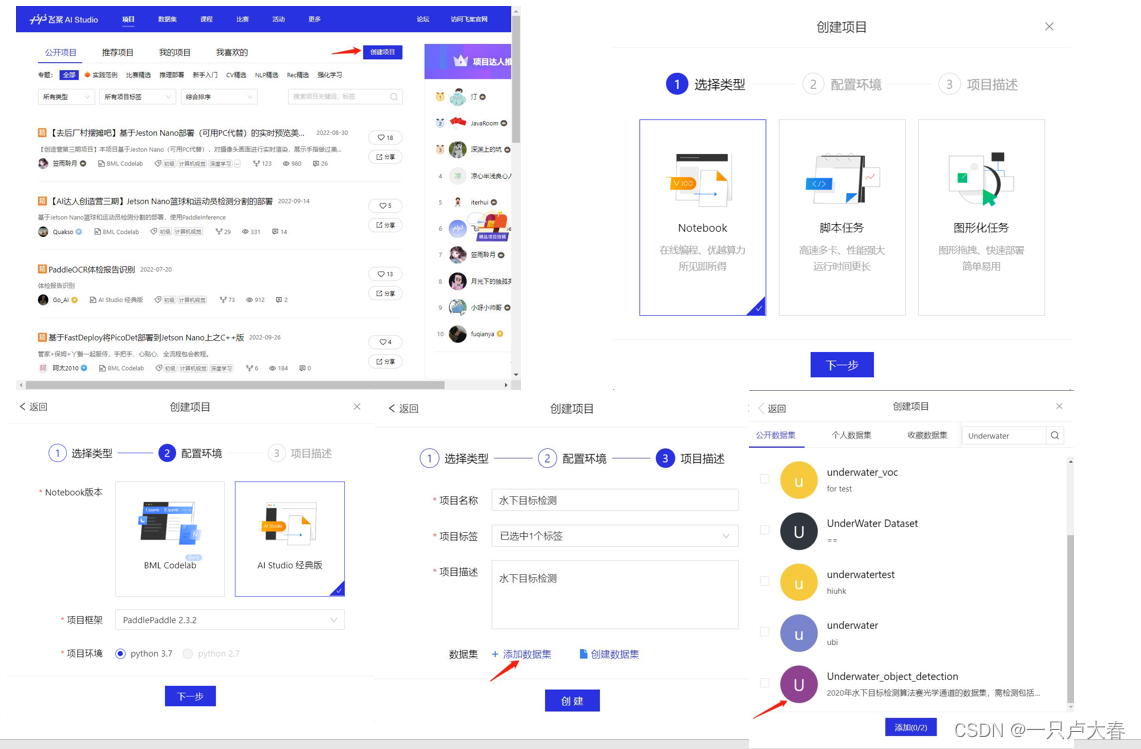
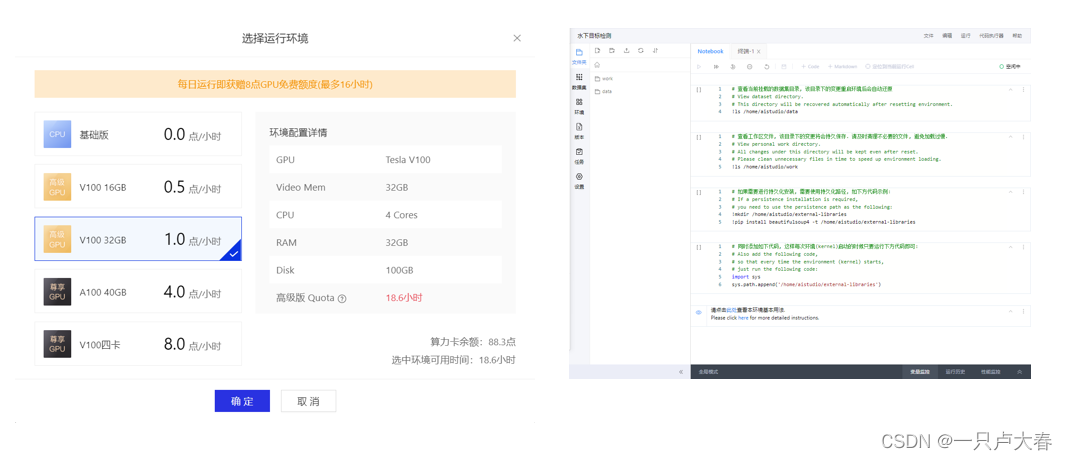
このようなプロジェクトが作成され (画像の処理に GPU が使用され、プロジェクトを飛行するときにプロジェクトがギフトとして与えられます)、プロジェクト内の初期コードの最初の 4 つの部分を実行する必要はなく、実行することもできます。削除される。
ステップ 2: PaddleDetection をデプロイする
gitee で PaddleDetection インストール パッケージをダウンロードし、作業中のフォルダーに解凍します。コードは次のとおりです。
%cd ~/work/
! git clone https://gitee.com/paddlepaddle/PaddleDetection.git
Feijiang の PaddleDetection インストール パッケージは時々更新されますが、私が実行していたときのインストール パッケージが必要な場合は、最初の Baidu ネットワーク ディスクに移動できます。
ヒント:初期の 2 つのフォルダー data と work は、Feijiang によってプロジェクトが作成された後に与えられます。data はデータを保存するためのもので、work はアルゴリズムを書くための作業領域であると考えるのが簡単だと思います。
デプロイメントが完了すると、作業中の PaddleDetection フォルダーが表示されます。他の環境構成については、以下の yolov3 の使用法を参照してください。
yolov3の使用
yolov3 の原理と説明については他のブログを参照してください。2018 年に登場して以来、それを非常にわかりやすく教えているコースが数多くあります。ここでは PaddleDetection での yolov3 モデルの使用についてのみ説明します。抜けや間違いがあれば追加してください。
yolov3 を使用する場合は、まずデータ セットを処理する必要があります。データ セットが処理された後、VOC と COCO の 2 つの形式に分割できます。形式の説明は次のとおりです:
1. VOCフォーマットの数の紹介
VOCデータ形式の物標検出データとは、各画像ファイルが同名のxmlファイルと、そのxmlファイル内のマーキング対象枠の座標やカテゴリなどの情報に対応していることを意味する。
Pascal VOC コンペティションでは、ターゲット オブジェクトが遮蔽されているかどうか、切り詰められているかどうか、検出が困難なオブジェクトであるかどうかなど、ターゲット検出タスクにマークを付けます。ユーザー定義データの場合、これらのフィールドは実際の状況に応じてマークできます。
├── annotations
│ ├── road0.xml
│ ├── road100.xml
│ ...
├── images
│ ├── road0.png
│ ├── road100.png
│ ...
├── label_list.txt
├── train.txt
└── valid.txt
XML ファイルには次のフィールドが含まれています。
- filename、イメージ名を示します。
<filename>road650.png</filename>
- サイズは画像サイズを示します。含まれるもの: 画像の幅、画像の高さ、画像の深さ
<size>
<width>300</width>
<height>400</height>
<depth>3</depth>
</size>
- オブジェクトフィールドは各オブジェクトを表します。含む
name: 目标物体类别名称
pose: 关于目标物体姿态描述(非必须字段)
truncated: 目标物体目标因为各种原因被截断(非必须字段)
occluded: 目标物体是否被遮挡(非必须字段)
difficult: 目标物体是否是很难识别(非必须字段)
bndbox: 物体位置坐标,用左上角坐标和右下角坐标表示:xmin、ymin、xmax、ymax
label_list.txt ファイルには、識別する必要があるカテゴリが保存されます。train.txt
および valid.txt ファイルには、トレーニングと検証用の部門ラベルが保存されます。形式は次のとおりです。
./images/road839.png ./annotations/road839.xml
./images/road363.png ./annotations/road363.xml
./images/road148.png ./annotations/road148.xml
...
2. COCO 形式の数値の概要
COCO データ形式は、すべてのトレーニング画像の注釈を json ファイルに保存することを指します。データはネストされた辞書の形式で保存されます。
annotations/
├── train.json
└── valid.json
images/
├── road0.png
├── road100.png
json ファイルに保存されるinfo licenses images annotations categories情報:
-
info: 注釈ファイルの注釈時間、バージョン、その他の情報を保存します。
-
ライセンス: データ ライセンス情報を保存します。
-
画像:リストを保存し、すべての画像の画像名、ダウンロード アドレス、画像の幅、画像の高さ、データ セット内の画像の ID およびその他の情報を保存します。
-
注釈: リストを保存し、すべての画像内のすべてのオブジェクト領域の注釈情報を保存し、ターゲット オブジェクトごとに次の情報をマークします。
{ 'area': 899, 'iscrowd': 0, 'image_id': 839, 'bbox': [114, 126, 31, 29], 'category_id': 0, 'id': 1, 'ignore': 0, 'segmentation': [] }このデータ処理では 2 つのデータ形式を紹介した後、等間隔サンプリング (つまり、一定の間隔でサンプリング) を使用し、0.8:0.2 で除算する VOC データ形式を使用します。コードは次のとおりです。
#将数据集解压到dataset下,data171095处的路径要改
%cd ~/work/PaddleDetection/dataset/
! pwd
!unzip -oq ~/data/data171095/train.zip
#生成label_list.txt train.txt valid.txt文件
import random
import os
#生成train.txt和val.txt
# random.seed(2020)
#路径要改
xml_dir = '/home/aistudio/work/PaddleDetection/dataset/train/annotations'#标签文件地址
img_dir = '/home/aistudio/work/PaddleDetection/dataset/train/images'#图像文件地址
path_list = list()
for img in sorted(os.listdir(img_dir)):
img_path = os.path.join(img_dir,img)
xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml'))
path_list.append((img_path, xml_path))
# random.shuffle(path_list)
ratio = 10
#路径要改
train_f = open('/home/aistudio/work/PaddleDetection/dataset/train/train.txt','w') #生成训练文件
val_f = open('/home/aistudio/work/PaddleDetection/dataset/train/valid.txt' ,'w')#生成验证文件
for i ,content in enumerate(path_list):
img, xml = content
text = img + ' ' + xml + '\n'
#取名称末尾是1或者2的,相当于0.8:0.2划分数据集
if i%ratio==1 or i%ratio==2:
val_f.write(text)
else:
train_f.write(text)
train_f.close()
val_f.close()
#生成标签文档
label = ['holothurian','echinus','scallop','starfish','waterweeds'] #设置你想检测的类别
with open('./train/label_list.txt', 'w') as f:
for text in label:
f.write(text+'\n')
次のステップは、PaddleDetection で yolov3 の設定を続行することです。この段階では、これについてあまり詳しくありません。少し大雑把な内容であることをご了承ください。理解が深まったら、もう一度追加します。
いくつかの必要な環境のインストール:
%cd /home/aistudio/work/PaddleDetection/
!pip install -r requirements.txt
!pip install pycocotools
!pip install paddledet
画像の学習には GPU を使用するので、GPU を設定しましょう。
!with fluid.dygraph.guard(place=fluid.CUDAPlace(0)) #设置使用GPU资源训神经网络,默认使用服务器的第一个GPU卡。"0"是GPU卡的编号,比如一台服务器有的四个GPU卡,编号分别为0、1、2、3。
import paddle
print(paddle.device.get_device())
モデル yolov3_mobilenet_v3_large_ssld_270e_voc.yml を使用して、モデル内のパラメーターを変更します。

ファイルを変更する前に、各依存ファイルの機能について説明します。
'_base_/optimizer_270e.yml',主要说明了学习率和优化器的配置,以及设置epochs。在其他的训练的配置中,学习率和优化器是放在了一个新的配置文件中。
'../datasets/voc.yml'主要说明了训练数据和验证数据的路径,包括数据格式(coco、voc等)
'_base_/yolov3_reader.yml', 主要说明了读取后的预处理操作,比如resize、数据增强等等
'_base_/yolov3_mobilenet_v3_large.yml',主要说明模型、和主干网络的情况说明。
'../runtime.yml',主要说明了公共的运行状态,比如说是否使用GPU、迭代轮数等等
変更が必要な箇所 (赤い線が描かれている部分) をいくつか紹介します。
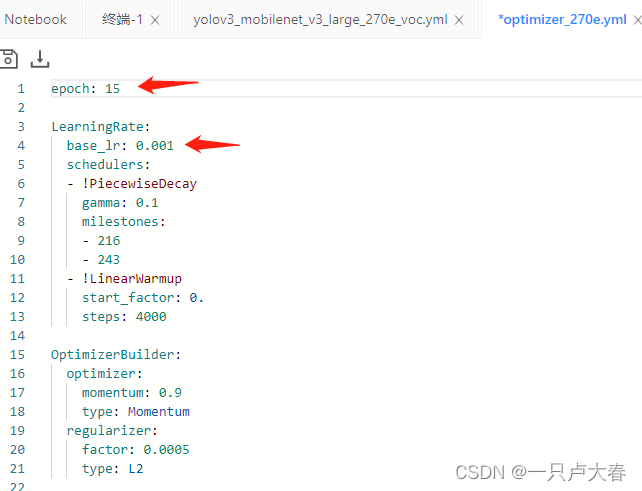
上の図の最初の矢印はトレーニング ラウンドの数で、より良い結果を達成するためにトレーニング回数を増やすことができます。は学習率で、自分のニーズに合わせて2か所を調整して変更することができます。

名前は VOC 形式で記述する必要があることに注意してください。
yolov3 は、データのトレーニングに K-means クラスタリング アルゴリズムを使用してアンカー ボックスのサイズを取得します
#K-means聚类
# -c 参数表示指定使用哪个配置文件
# -n 9 生成 9 组尺寸
# -s 608 指定图像训练尺寸
# -m v2 使用默认的 v2 版本方法
# -i 1000 迭代次数
!python tools/anchor_cluster.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -n 9 -s 608 -m v2 -i 1000
次のステップはモデルをトレーニングすることです
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
# --eval 参数表示边训练边评估,最后会自动保存一个名为best_model.pdparams的模型
# --use_vdl=True 配置开启深度学习可视化,可以看一些 loss 曲线,可视化训练过程中关键指标的变化
# 最后模型文件输出在output中
!python tools/train.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml --eval --use_vdl=True --vdl_log_dir="./output"
トレーニング プロセス中に、エポック ロス値などの出力があり、次のようにこれに従ってトレーニングの進行状況と残り時間を確認できます。

モデルの評価と予測
モデルを評価します。
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
!python -u tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams
次に、画像にアクセスしてその効果を確認します。
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
# --infer_img 指定要测试的图像
!python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_ssld_270e_voc/best_model.pdparams --infer_img=/home/aistudio/work/PaddleDetection/dataset/train/images/000111.jpg
画像がwork/PaddleDetection/outputパスに配置され、その効果は次の図のようになります。

先行者たちの共有に感謝します。この記事は次を参照しています:
https://blog.smslit.cn/2021/04/15/paddle-detection-train-log/
https://aistudio.baidu.com/aistudio/projectdetail /3460363?チャンネルタイプ= 0&チャンネル=0