ノート
1. LLM のコンテキスト長を拡張する
1. 一般的な方法
実際には、LLM にはかなりの数の拡張コンテキスト長がありますが、サンプルの長いコンテキストのほとんどは、検索や要約を組み合わせることで短縮されます。、アンリミフォーマーなど。長いコンテキストは直接処理されないため、通常は詳細な読解を行うことは不可能であり、これらのソリューションは、多くの場合、後で既存の LLM モデルにプラグアンドプレイするのではなく、トレーニング段階で考慮する必要があります。
2.PCW方式
以前は、微調整せずにコンテキストの長さを拡張できるスキームは、論文「大規模言語モデルのための並列コンテキスト ウィンドウ」と「構造化プロンプティング: コンテキスト内でのスケーリング」からの並列コンテキスト ウィンドウ (以下、PCW) でした。 Learning to 1,000 Examples」の 2 つの論文は、同じ時期に異なる著者が執筆したものですが、提案された手法にわずかな違いがあるだけです。
PCW はセルフ アテンション モデルに適しており、主な変更には位置エンコーディングとアテンション マスクが含まれます。

2.NBCE法
単純ベイジアン アプローチを使用します。

ランダム サンプルの効果を改善するには、プーリング方法を変更して、不確実性が最も低い分布を直接出力します。
[ log p ( T ∣ S ) ] = log p ( T ∣ S k ) k = arg min { H 1 , H 2 , ⋯ , H n } H i = − ∑ T p ( T ∣ S i ) log p ( T ∣ S i ) \begin{array}{r} {[\log p(T \ Mid S )]=\log p\left(T \mid S_k\right)} \\ k=\arg \min \left\{H_1, H_2, \cdots, H_n\right\} \\ H_i=-\sum_T p\ left(T \mid S_i\right) \log p\left(T \mid S_i\right) \end{array}[ログ_p ( T∣S )]=ログ_p( T∣Sk)k=arg _分{
H1、H2、⋯、Hん}H私は=−∑Tp( T∣S私は)ログ_p( T∣S私は)
3. RoPE法
RoPE の目標:
( R mq ) ⊤ ( R nk ) = q ⊤ R m ⊤ R nk = q ⊤ R n − mk \left(\mathbf{R}_m \mathbf となるような位置依存の射影行列を構築すること{q }\right)^{\top}\left(\mathbf{R}_n \mathbf{k}\right)=\mathbf{q}^{\top} \mathbf{R}_m^{\top} \mathbf {R}_n \mathbf{k}=\mathbf{q}^{\top} \mathbf{R}_{nm} \mathbf{k}( Rメートルq )⊤( Rんk )=q⊤R _メートル⊤Rんk=q⊤R _n − mk
- 位置をエンコードする変換は位置補間と呼ばれます。このステップでは、 [ 0 , L ′ ) \left[0, L^{\prime}\right)からの位置にインデックスを付けます。[ 0 ,L' )から[ 0 , L ) [0, \mathrm{~L})[ 0 , L ) を使用して、RoPE を計算する前に元のインデックス範囲と一致させます。
- したがって、RoPE への入力として、任意の 2 つのマーカー間の最大相対距離はL ' L^{\prime}から始まります。L' LLに縮小L._ _ 拡張の前後で位置インデックスと相対距離の範囲を調整するため、コンテキスト ウィンドウの拡張によるアテンション スコアの計算への影響が軽減され、モデルの適応が容易になります。
- この点をさらに証明するために、次の定理は、補間された注意スコアが優れた特性を持っていることを示しています。

たとえば、回転位置エンコーディングは chatGLM (次のモジュール) でも使用されGLMBlockますSelfAttention。
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(word_embeddings): Embedding(130528, 4096)
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(attention): SelfAttention(
(rotary_emb): RotaryEmbedding()
(query_key_value): QuantizedLinear(in_features=4096, out_features=12288, bias=True)
(dense): QuantizedLinear(in_features=4096, out_features=4096, bias=True)
)
(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(mlp): GLU(
(dense_h_to_4h): QuantizedLinear(in_features=4096, out_features=16384, bias=True)
(dense_4h_to_h): QuantizedLinear(in_features=16384, out_features=4096, bias=True)
)
)
)
(final_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=4096, out_features=130528, bias=False)
)
具体的なロータリー エンコーディング クラス コードは次のとおりです。
class RotaryEmbedding(torch.nn.Module):
def __init__(self, dim, base=10000, precision=torch.half, learnable=False):
super().__init__()
inv_freq = 1. / (base ** (torch.arange(0, dim, 2).float() / dim))
inv_freq = inv_freq.half()
self.learnable = learnable
if learnable:
self.inv_freq = torch.nn.Parameter(inv_freq)
self.max_seq_len_cached = None
else:
self.register_buffer('inv_freq', inv_freq)
self.max_seq_len_cached = None
self.cos_cached = None
self.sin_cached = None
self.precision = precision
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,
error_msgs):
pass
def forward(self, x, seq_dim=1, seq_len=None):
if seq_len is None:
seq_len = x.shape[seq_dim]
if self.max_seq_len_cached is None or (seq_len > self.max_seq_len_cached):
self.max_seq_len_cached = None if self.learnable else seq_len
t = torch.arange(seq_len, device=x.device, dtype=self.inv_freq.dtype)
freqs = torch.einsum('i,j->ij', t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
if self.precision == torch.bfloat16:
emb = emb.float()
# [sx, 1 (b * np), hn]
cos_cached = emb.cos()[:, None, :]
sin_cached = emb.sin()[:, None, :]
if self.precision == torch.bfloat16:
cos_cached = cos_cached.bfloat16()
sin_cached = sin_cached.bfloat16()
if self.learnable:
return cos_cached, sin_cached
self.cos_cached, self.sin_cached = cos_cached, sin_cached
return self.cos_cached[:seq_len, ...], self.sin_cached[:seq_len, ...]
def _apply(self, fn):
if self.cos_cached is not None:
self.cos_cached = fn(self.cos_cached)
if self.sin_cached is not None:
self.sin_cached = fn(self.sin_cached)
return super()._apply(fn)
4、FlashAttentionメソッド
- 新たにリリースされたChatGLM2-2Bでは、この手法を利用してコンテキスト長(Context Length)をChatGLM-6Bの2Kから32Kに拡張し、対話フェーズで8Kのコンテキスト長トレーニングを使用することで、より多くの対話ラウンドを可能にしている。
- ハッシュ対応テクノロジーを使用すると、入力シーケンス内の要素をその類似性に応じて異なるバケットに割り当てることができます。このように、モデルはシーケンス全体ではなく、バケット要素間のアテンションの重みを計算するだけで済みます。
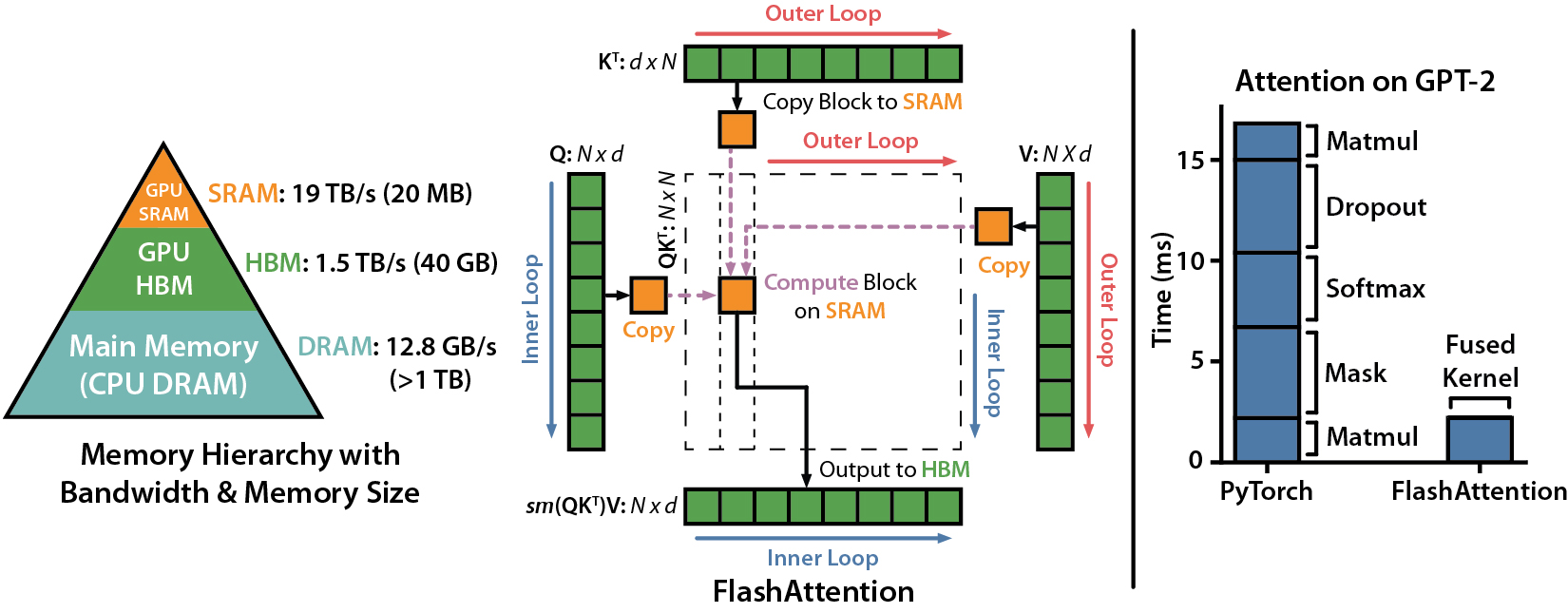
参照
[1]トランスフォーマーのアップグレード パス: 10. RoPE は β-ary コードです。Su Jianlin
[2] NTK-Aware Scaled RoPE により、微調整や混乱の低下を最小限に抑えながら、LLaMA モデルのコンテキスト サイズを拡張 (8k+) できるようになります
[ 3 ]バイアス項目の魔法の効果: RoPE + バイアス = より良い長さの外挿
[4] NBCE: 単純ベイジアンを使用して LLM のコンテキスト処理長を拡張. Su Jianlin
[5] 数兆のトークンから取得することによる言語モデルの改善 . DeepMind の RETRO アプローチ (以前は、LLM にテキスト チャンクを順次提供していましたが、これは一時的なアプローチにすぎません)
[6] [自然言語処理] [大規模モデル] ChatGLM-6B モデル構造コード解析 (スタンドアロン版)
[7] https:// Huggingface.co/THUDM/chatglm-6b/blob/main/modeling_chatglm.py
[8]また、langchain 大規模モデル プラグインのナレッジ ベース質問応答システムのコア コンポーネントについても説明します。複雑な非構造化テキストをより適切に解析してセグメント化する方法
[ 9] Tian Yuandong チームの新作: 位置補間による大規模言語モデルのコンテキスト ウィンドウの拡張
[10] RoPE は、LLM 時代の Resnet である可能性があります。Liu Jun は
[12] flash-attention: https://github.com/Dao-AILab/flash-attention (chatglm2-6b は、より長いコンテキストをサポートするためにこの実装を使用します)
[ [13] https://huggingface.co/THUDM/chatglm2-6b
[14] NBCE: 単純ベイジアンを使用して LLM のコンテキスト処理長を拡張する