遺伝的アルゴリズムは非常に古典的なインテリジェント アルゴリズムであり、主に最適化問題を解決するために使用されます。この記事では主にいくつかの原則を簡単に紹介し、同時に実数内の最適化問題を解くための Python に基づくテンプレートを提供します。
この記事の参考文献:
原則:遺伝的アルゴリズムの詳細な紹介 - プログラマーが求めたもの
簡単な紹介
遺伝的アルゴリズムとは、生物学における遺伝学のことです。まず、いくつかの集団を生成し、その中にいくつかの個体、つまり解を作ります。異なる解に対して適応度を設定し、演算子を使って新しい解を生成します。優れた遺伝子は継続的に生成されます。集団内で継承され、最終的に最適化が達成されるという目標です。
つまり、最終的にはいくつかのグループが存在し、その中の個人は比較的優秀な者ばかりで、良くない者は排除されることになります。
関連概念
以下は基本的な概念であり、上記リンクを参照させていただきましたが、その一部を抜粋してメモしたものですので、詳細はご自身でご理解いただければと思います。
① 染色体:染色体は遺伝子型個体(個人)とも呼ばれ、一定数の個体が集団を形成し、集団に含まれる個体の数を集団サイズといいます。
②ビット列(Bit String):個人の表現。遺伝学における染色体に相当します。
③ 遺伝子(Gene):遺伝子とは、染色体の要素であり、個人の特性を表すために使用されます。たとえば、S=1011という文字列(つまり染色体)があった場合、1、0、1、1の4つの要素を遺伝子と呼びます。
④ 特徴量(Feature):整数を文字列で表現する場合、遺伝子の特徴量は二進数の重みと一致します(例:文字列 S=1011 では、遺伝子の位置 3 の 1)。遺伝子特徴値は 2、遺伝子位置は 1 のうち 1、遺伝子固有値は 8 です。
⑤ 適応度(Fitness):各個体の環境への適応力を適応度といいます。染色体の適応性を反映するために、問題内の各染色体を測定できる適応度関数と呼ばれる関数が導入されています。この関数は通常、グループ内で個人が使用される確率を計算するために使用されます。
⑥ 遺伝子型 (Genotype):または遺伝型。遺伝的特性と性能を定義するゲノムを指します。GA のビット文字列の場合。
⑦ 表現型:特定の環境における生物の遺伝子型の性能特性。GA のビット列のデコードされたパラメータに対応します。
染色体は個体であり、具体的な計算ではn次元空間の解となる
ビット文字列は、個人をエンコードした表現です。
遺伝子は染色体に含まれる特徴、つまりコード化されたビットです
特性値は、このエンコード規則でのこのビットの意味を示します。
適合度は、計算プロセスで使用される確率を示します。これは、一般に、解の品質が高い状態です。
遺伝子型表現エンコードされた文字列
表現型はデコードされたパラメータを表します
遺伝的ステップ
-
エンコードとデコードのルール
この 2 つのプロセスは逆のプロセスであり、エンコーディングは一般にバイナリ エンコーディングを使用してシーケンスをシーケンスにデコードすることであり、デコードはその逆です。
-
初期値を生成する
このプロセスは、必要な変数を生成するためのものです
最大進化代数 T、集団サイズ M、交叉確率 Pc、突然変異確率 Pm を設定し、初期集団 P0 として M 個の個体をランダムに生成します。
-
フィットネスを変える
これは主に、各個人の適応度を変更して、適応度が均等になるのを防ぐために使用されます。そうすれば、適者生存がなくなります。
一般に、アルゴリズムの反復のさまざまな段階を指します。個人の適応度を適切に変更することで、グループ間の適応度が類似することによって引き起こされる競争の弱体化を回避し、集団を局所的な最適解に収束させることができます。 。
線形、非線形など、さまざまな方法があります...
-
遺伝的オペレーター
-
選ぶ
選抜とは、古い集団(複数の個体を含む)の中から優秀な個体を選抜し、その中で繁殖させることにより、優れた出生と優れた生殖能力を実現することである。
ルーレットが一般的で、個体の適応度を集団の全体の適応度で割った個体の選択確率であり、適応度が高ければ選択される確率も高く、優秀な子孫が得られる。
-
クロス
交叉とは、新しい解を生成する操作を完了するために、2 つの染色体間に何らかの交換を生成することです。一般的に使用される1 点交叉など...
-
突然変異
突然変異とは、バイナリを少し変更するなど、一定の確率でそれ自体が変化することを意味し、これにより新しい解も生成されます。
-
このプロセスには主に、新しい解決策を生成する、異なる解決策を一緒に解放する、または自分自身で新しい解決策を生成するために使用される 3 種類があり、これらのプロセスは、必ずしも上記のものに限定されず、さまざまな方法で提示することもできます。だけでなく、さまざまな問題に対しても、さまざまな解決策があります。
注意点
遺伝的アルゴリズム y には通常、事前に設定する必要がある 4 つの動作パラメータがあります。
M : 人口規模
T : 遺伝的アルゴリズムの終端進化代数
Pc: 交叉確率、通常 0.4~0.99
Pm: 突然変異確率、通常 0.001~0.1
コード
以下は、具体的なコードの実装です。私が使用するコーディング方法は、浮動小数点数を直接生成することです。選択操作では、毎回設定された割合の個人が保持されます。クロスオーバー操作では、毎回2 セットのパラメーターを選択して、特定のパラメーターと交換します。新しい個体を生成する確率突然変異操作各値について、一定の確率でパラメータを再値化し、突然変異操作をシミュレートします。
記録されたパラメーターには 3 つのグループがあり、各ラウンドの最適な適合性、最適な結果と対応する最適なパラメーター、および最終的な描画です。
コード
import warnings
from math import log2
import matplotlib.pyplot as plt
import pandas as pd
warnings.filterwarnings('ignore')
import heapq
import itertools
from random import randint, random, uniform
import numpy as np
def select_op(fitness,op,select_rate,best_keep_rate):
ans_list = []
# 先选择保留部分
keep_num = int(best_keep_rate * len(op)*select_rate)
index_list = list(map(list(fitness).index, heapq.nlargest(keep_num, fitness)))
for index in index_list:
ans_list.append(op[index])
# 保留的
p =fitness/sum(fitness) # 计算每个个体占比
p = np.array(list(itertools.accumulate(p))) # 计算累积密度函数
# 采用轮盘赌方式选择
for i in range(int(len(op)*select_rate)-keep_num): # 再产生这么多个
r = random()
index = np.argmax(p>r) # 找到第一个大于随机的值
if index == 0 and p[0] < r: # 可能第一个并不大于这个数,可能是没找到,也是返回0
continue
ans_list.append(op[index])
return ans_list
def cross_op(op,cross_rate,num):
ans_list = []
num_op = len(op) # 当前数量
while num > 0:
max_ = 5 # 最多找5次,如还是相同就用相同的,就说明这个基因很多
while max_>0:
n1 = randint(0,num_op-1)
n2 = randint(0,num_op-1) # 不允许相同个体杂交
max_ -= 1
if op[n1] != op[n2]:
break
father = op[n1]
mother = op[n2]
if random() < cross_rate:
location = randint(0,len(father)-1) # 随机产生交叉位置
tmp = father[0:location+1] + mother[location+1:len(father)]
ans_list.append(tmp)
num -= 1
return ans_list
def variation_op_10(new_op,variation_rate,low,high):
for index,it in enumerate(new_op): # 一定概率变异
if random() < variation_rate:
location = randint(0, len(it) - 1)
it = uniform(low[location],high[location]) # 随机产生数字
new_op[index][location] = it
return new_op
# 生成随机初始值
def ini_op(low_paras, high_paras, max_op_size):
# 计算出每个参数应该占的位数
st = 0
ed = -1 # 为了保证st为-1
para_range = []
for i in range(len(low_paras)):
low_it = low_paras[i]
high_it = high_paras[i]
num = int(log2(high_it - low_it + 1)) + 1 # 计算二进制位数
st = ed + 1
ed += num
para_range.append((st, ed)) # 加入每个参数的范围,包括起始点和终点(在序列中的)
op = []
for i in range(max_op_size):
tmp = [uniform(low_paras[k], high_paras[k]) for k in range(len(low_paras))]
op.append(tmp)
return op, para_range
def cal_fitness(op):
ans_list = np.zeros((len(op), 1))
for index, it in enumerate(op): # 取出每个参数对应的数字
if un_suit(it): # 如果不满足约束条件
ans_list[index] = 1000000000 # 给一个很大的值,最后要统一处理
continue
y = func(it)
ans_list[index] = y
ans_list = func_fitness(ans_list)
return ans_list
# 自定义适应度函数计算
def func_fitness(ans_list):
if model_dir == 'min':
for index, it in enumerate(ans_list):
ans_list[index] = 1 / it
return ans_list
def un_suit(x): # 定义参数不满足的约束条件
# 参数范围约束
for i in range(len(low_paras)):
if x[i] < low_paras[i] or x[i] > high_paras[i]:
return True
# ...自行添加
return False
# 定义计算函数
def func(x):
return x[0] ** 2 + x[1] ** (3 / 2) + x[2] + x[3] ** (1 / 2)
# ---配置参数
paras_name = ['x1', 'x2', 'x3', 'x4']
high_paras = [60,60,40,30] # 参数范围上限
low_paras = [10, 21,3,10] # 参数范围下限
model_dir = 'min' # max表示越大越好,min表示越小越好
# ---配置遗传算法参数
max_op_size = 200 # 种群大小,这里也是考虑一个种群的优化问题
max_epochs = 200 # 迭代次数,也就是进化次数
cross_rate = 0.8 # 杂交率,选出两个个体之后以这个概率杂交(各取部分基因产生后代)
select_rate = 0.4 # 选择率,也就是选择保留占总的个数(这里实际是利用随机数抽取,而不是按照排序)
variation_rate = 0.1 # 变异率,产生新的个体以这个概率变异(一位重新赋值)
best_keep_rate = 0.1 # 每次选择必定保留的比例(排序靠前的部分)
# ---遗传算法求解
if __name__ == '__main__':
data = np.array(pd.read_excel('../static/test.xlsx')) # 读入数据
op, para_range = ini_op(low_paras, high_paras, max_op_size) # 初始化种群,返回种群和每个参数的位置范围[(l1,r1),(l2,r2)...]
best_ans_history = [] # 记录最优答案历史
best_para_history = [] # 记录最优对应参数
best_fitness_history = [] # 记录最优适应度
for i in range(1, max_epochs + 1):
if i % 50 == 0:
print('epoch:', i)
# 计算适应度
fitness = cal_fitness(op) # 计算适应度
index = np.argmax(np.array(fitness)) # 为什么已经保留了最佳适应度,最后的图还是会上下跳动
best_fitness_history.append(fitness[index])
best_para_history.append(op[index])
best_ans_history.append(func(op[index]))
op = select_op(fitness, op, select_rate, best_keep_rate) # 选择个体,选择比例为
# 交叉,产生后代
new_op = cross_op(op, cross_rate, max_op_size - len(op)) # 后一个参数为需要产生的个数
# 变异
new_op = variation_op_10(new_op, variation_rate,low_paras,high_paras) # 变异
op.extend(new_op) # 把新的个体加入群落
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
index = np.argmax(best_ans_history)
print('最优结果为:', best_ans_history[index])
print('最优参数如下')
for name,index in zip(paras_name,best_para_history[index]):
print('{}={}'.format(name,index))
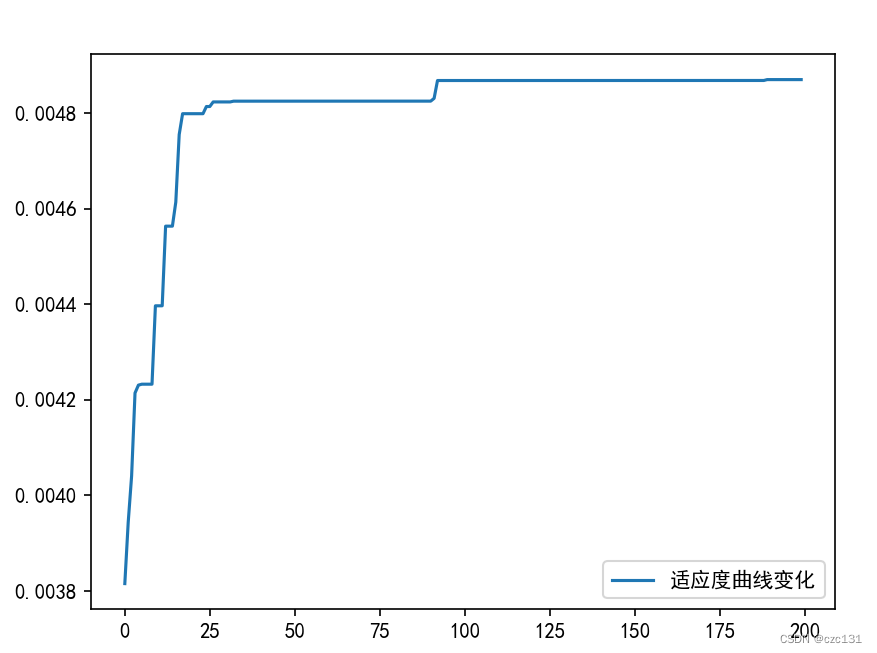
plt.plot(best_fitness_history, label='适应度曲线变化')
plt.legend()
plt.show()
例
単調関数を例に挙げます。
x1 ** 2 + x2 ** (3 / 2) + x3 + x4 ** (1 / 2)
設定範囲は以下の通りです。
high_paras = [60,60,40,30] # 参数范围上限
low_paras = [10, 21,3,10] # 参数范围下限200 回の反復後に停止し、結果を出力します
最优结果为: 262.08470155055244
最优参数如下
x1=10.92155546612619
x2=22.81339324058242
x3=30.588146368196167
x4=10.573758934746433最適な適応度変化曲線を出力します。