1. ナンバとは
python - numba
numba.cuda
numba は、Python による動的コンパイル (JIT) の実行を支援します。numba.cuda の助けを借りて、GPU の動的コンパイルを実現し、CUDA API を実現できます。Python で CUDA を実行する方法は数多くありますが、NVIDIA は CUDA Python を正式に開始しました
2. コードの実装
この記事のコードはGiteeでホストされています
プログラムがインポートする必要がある Python パッケージ (プロジェクト コードのrequirements.txt を通じてバッチでインストールできます)
import time
from math import floor
import cv2 as cv
import numpy as np
from numba import cuda
以下はJITコードです
@cuda.jit
def kernel(pic):
x = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x
y = cuda.threadIdx.y + cuda.blockIdx.y * cuda.blockDim.y
for i in range(pic.shape[2]):
pic[y, x][i] = (x + y) % 256 + i * 50
CUDA コードと CPU 側コードの最大の違いは、GPU 側コードがスレッド数を計算して CPU 側コードのループ操作をオフセットし、高度な並列化を実現することです。 GPU 側は Python に付属する time パッケージを通じて計算されます
。具体的なコードは次のとおりです。
start = time.time()
kernel[(floor((w + 32 - 1) / 32), floor((h + 32 - 1) / 32)), (32, 32)](tmp)
end = time.time()
上の図には、関数の開始と構成の問題が含まれていますが、一般的に、CUDA プログラミングでは、割り当てが少ないよりも割り当てが多い方が好ましいという原則に従って、切り上げられています。
3. 実験結果

読者はカーネル関数のコードを変更することで画像のスタイルを変更できます。
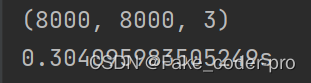
8000 8000 3 のピクチャを読み込んで修正するのに 0.304 秒かかりますが、CPU 側を計算に使用すると負荷が高くなります。このことから、CUDA によるコードの並列化によってもたらされる大きな利点がわかります。CUDA の SIMD 形式が完全に表現されています