1. アルゴリズムの概要
PageRank の Page は、実際には創設者のラリー・ペイジの姓に由来しており、このアルゴリズムの目的は、さまざまな Web ページ (ページ) をランク付けして、どの Web ページを最前面に表示するかを取得することです。
1.1 用語
1. 节点(node), 指的是图(graph)上的单个点,在谷歌的网页排名里节点可以看做是一个网页
2. PR值(Page Rank value),指某个节点的得分权重,值越高,其重要性越大,在网页中排名越靠前,相应地就会显示在搜索结果的前几位
3. 阻尼系数d(damping factor),指从当前节点到其指向的下一个节点的衰减系数,后面算法流程中会讲到
4. 槽节点(sink node),指没有出度只有入度的节点,其不指向任何其他节点
1.2 アルゴリズム処理
Google のページ ランキングを例にとると、各 Web ページの PR 値は、サーファーが Web ページに滞在する確率の値と見なすことができるため、インターネット サーフィンの過程で、サーファーが次に訪問する Web サイトは次の 2 つの方法を介して行われる可能性があります。
- 現在のウェブサイトのリンクから指される次のページ(リンク)
- 任意の Web ページに転送するその他の方法
次に、これら 2 つの方法をそれぞれどのように計算するか、このとき減衰係数 d が役に立ちます。d は現在の Web ページからその Web ページが指す次の Web サイトにジャンプする確率と考えることができます。計算されるノードが j であると仮定すると、最初の方法で得られる PR 値の寄与は次のようになります。 {ノード\スペース指向\スペース ノードj}}{\frac {PR_{old}(node_k)} {番号\スペースの\スペース送信\スペース リンク\スペース の\スペース ノードk } }PR _j1 _=d×k ∈ノードポイントノード_ _ _ _ _ _ _ _ _ _ _ _ _ _ j∑いいえ。_ ノードのリンクが見つかりません_ _ _ _ _ _ _ _ _ _ _ _ _ _ kPR _古い_ _(ノード_ _ _k)
つまり、ノードjを指すすべてのノードkの PR 値の寄与合計に減衰係数が乗算され、2 番目の方法の PR 値は比較的簡単に計算されます。PR j 2 = ( 1 − d ) × 1 n PR_{j2} = (1 - d) \times \frac 1 nPR _j2 _=( 1−d )×n1
ここで、nはノードの総数です。ノードjの必要な値は、2 つの部分の合計ですPR j = PR j 1 + PR j 2 PR_j = PR_{j1} + PR_{j2}PR _j=PR _j1 _+PR _j2 _
このメソッドを使用して各ノードを計算し、収束するまで PR 値を更新します。
下の図 1 は、PR 値の計算方法を直感的に理解するための比較的簡単な例です。
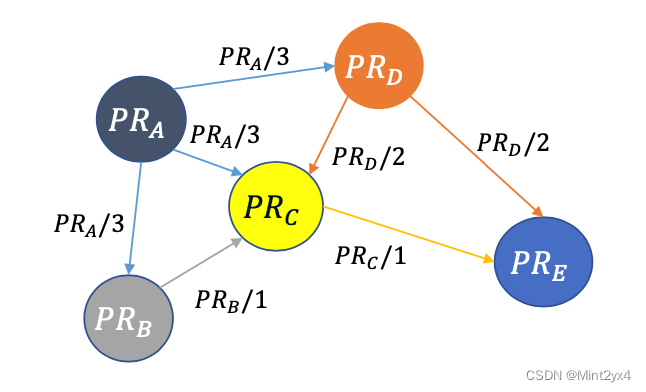
2. よくある質問
2.1 アルゴリズムが収束する時期
この記事の実装では、特定の設定値 ( ϵ = 0.01 \epsilon = 0.01)未満である各更新の前後の PR 値を合計する反復手法を採用しています。ϵ=0 . 0 1 ) は反復を停止することを意味し、公開表現は次のとおりです∑ j ∣ PR new (nodej ) − PR old (nodej ) ∣ ≤ ϵ \sum _j {|{PR_{new}{(node_j)} - PR_{old}(node_j)}| \le \epsilon}j∑∣ PR _新しい_ _(ノード_ _ _j)−PR _古い_ _(ノード_ _ _j) ∣≤ϵ
2.2 シンクノード
スロットノードとは、どのノードも指さないアウト次数のないノードを指します。これにより、次の図の簡単な例に示すように、すべての PR 値の合計が 1 未満になり、最終的にはすべての PR 値の合計が 0 になる傾向があるという問題が発生します。
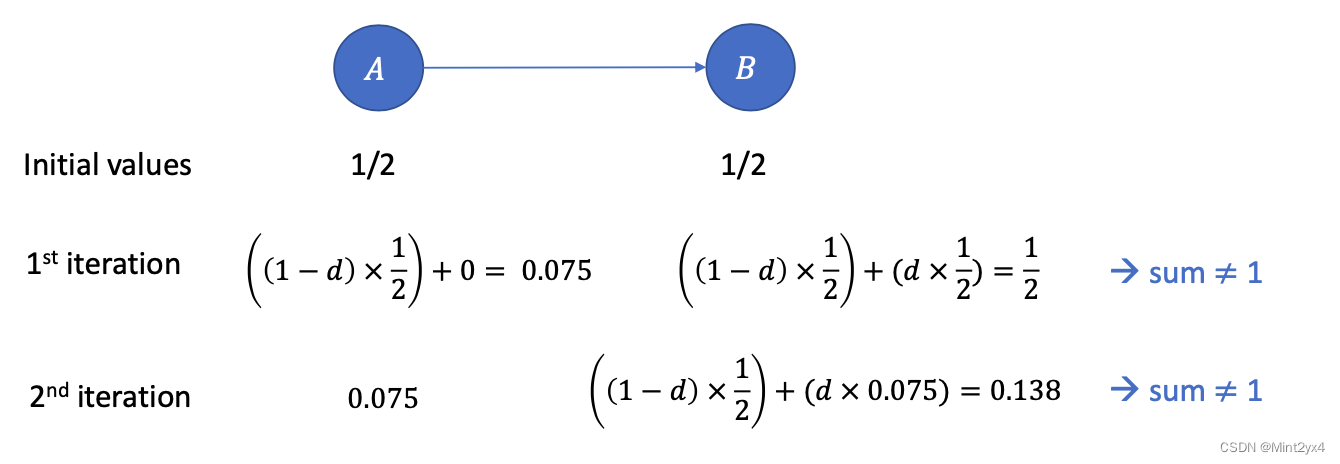
解決策は、上の図 1 に示すように、スロット ノードごとに他のすべてのノード (それ自体を含む) へのリンクを追加することです。E ノードはスロット ノードであり、他のノードにエッジを追加した結果を下の図に示します。
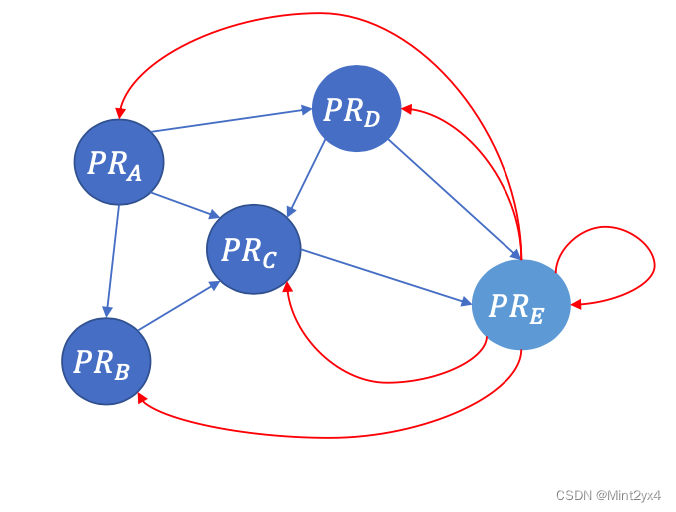
2.3 PRの初期値の設定方法
各ノードの初期値は同じです。PR init = 1 ノード数 PR_{init} = \frac 1 {number\space of\space ノード}PR _そうではない=ノードの数_ _ _ _ _ _ _ _ _ _ 1
3. アルゴリズムの実装
PageRank アルゴリズムを他の言語で実装している例はインターネット上にたくさんありますので、ここでは繰り返しませんが、SQL を使用した実装を自分で載せます。
まず、データソースのDDLは以下の通りです。
/* 节点表,主要是一个id, 和一个title */
CREATE TABLE node
(
paperid INTEGER NOT NULL,
papertitle VARCHAR(100) NOT NULL,
PRIMARY KEY (paperid)
);
/* 边表,起始边为paperid, 终边为citedpaperid */
CREATE TABLE edge
(
paperid INTEGER NOT NULL,
citedpaperid INTEGER NOT NULL,
PRIMARY KEY (paperid)
);
次に実装を開始します
page_rank テーブルと一時的な t_page_rank テーブルを作成する
/* create a page_rank table, and a temprary page_rank table for updating the old one */
DROP TABLE IF EXISTS page_rank;
CREATE TABLE page_rank
(
paperid INTEGER NOT NULL,
pr_val FLOAT NOT NULL,
out_links INTEGER NOT NULL,
PRIMARY KEY (paperid)
);
DROP TABLE IF EXISTS t_page_rank;
CREATE TABLE t_page_rank
(
paperid INTEGER NOT NULL,
n_pr_val FLOAT NOT NULL
);
page_rankテーブルを初期化し、各ノードの初期値を1/nに設定します。
/* init page_rank table, set each node the page_rank_value as 1 / (number of nodes) */
CREATE OR REPLACE FUNCTION
init_page_rank()
RETURNS VOID AS
$$
DECLARE
row_data RECORD;
cnt INTEGER;
init_pr FLOAT;
BEGIN
init_pr = 1.0 / (select count(*) from node);
TRUNCATE TABLE page_rank;
FOR row_data in SELECT * FROM node LOOP
cnt = (select count(*) from edge where edge.paperid = row_data.paperid);
INSERT INTO page_rank(paperid, pr_val, out_links)
VALUES (row_data.paperid, init_pr, cnt);
END LOOP;
raise notice 'init page rank table success';
END;
$$
LANGUAGE plpgsql;
ノードの新しい PR 値を計算するには 2 つの方法があります。
- すべてのシンク ノードの新しいエッジがエッジ テーブルに追加されるため、この方法はノード ノードやシンク ノードがあまり多くない状況に適しています。
- PR 値に対するすべてのシンク ノードの寄与を個別に計算します。これは、∑シンク _ ノード PR oldn \sum_{sink\_node} \frac {PR_{old}} {n}です。∑シンク_ノード_ _ _ _ _ _nPR _古い_ _
2つ目の考え方はこちら
/* a function to calculate the new pr_val of one particular node */
/* pid denotes the paperid of the node, sink_donation denotes the page_rank_value donation from sink nodes */
/* ret_val_1 denotes the first part of new page_rank_value,
ret_val_2 denotes the second part which is from the incoming nodes
*/
CREATE OR REPLACE FUNCTION
calculate_one(pid INTEGER, sink_donation FLOAT)
RETURNS FLOAT AS
$$
DECLARE
dprob FLOAT;
node_cnt INTEGER;
ret_val_1 FLOAT;
ret_val_2 FLOAT;
BEGIN
dprob = 0.85;
node_cnt = (select count(*) from node);
ret_val_1 = (1 - dprob) / node_cnt;
ret_val_2 = (SELECT SUM(out2.donation)
FROM (
SELECT (pr.pr_val / pr.out_links) as donation
FROM page_rank as pr
WHERE pr.paperid
IN (select edge.paperid FROM edge WHERE edge.citedpaperid = pid)
) as out2);
IF (select ret_val_2) is NULL THEN
ret_val_2 = 0;
END IF;
RETURN ret_val_1 + (ret_val_2 + sink_donation) * dprob;
END;
$$
LANGUAGE plpgsql;
すべてのノードの PR 値を更新します
/* the function for unpdating the page_rank_value for all nodes */
/* delta denotes the sum of the new-old pr_value of each nodes
epislon denotes the threshold whether to update page_rank table
*/
CREATE OR REPLACE FUNCTION
update_page_rank()
RETURNS FLOAT AS
$$
DECLARE
delta FLOAT;
row_data RECORD;
new_pr_val FLOAT;
epislon FLOAT;
sink_donation FLOAT;
BEGIN
delta = 0;
epislon = 0.01;
sink_donation = 0;
/* sink_donation is the pr_value of sink nodes all add up and divided by the counts */
sink_donation = (SELECT sum(page_rank.pr_val) from page_rank where page_rank.out_links = 0);
sink_donation = sink_donation / (select count(*) from node);
FOR row_data in select * from page_rank LOOP
new_pr_val = calculate_one(row_data.paperid, sink_donation);
INSERT INTO t_page_rank(paperid, n_pr_val)
VALUES (row_data.paperid, new_pr_val);
delta = delta + ABS(new_pr_val - row_data.pr_val);
END LOOP;
raise notice 'delta %', delta;
IF delta > epislon THEN
raise notice 'before update';
FOR row_data in select * from page_rank LOOP
UPDATE page_rank
SET pr_val =
(select n_pr_val from t_page_rank where t_page_rank.paperid = row_data.paperid)
WHERE paperid = row_data.paperid;
END LOOP;
raise notice 'after update';
END IF;
TRUNCATE TABLE t_page_rank;
RETURN delta;
END;
$$
LANGUAGE plpgsql;
反復を開始する
/* the main iteration function, no input and output */
CREATE OR REPLACE FUNCTION
begin_iteration()
RETURNS VOID AS
$$
DECLARE
epislon FLOAT;
delta FLOAT;
iterator INTEGER;
BEGIN
epislon = 0.01;
iterator = 0;
LOOP
delta = update_page_rank();
IF delta < epislon THEN
EXIT;
ELSE
raise notice 'iterator %, delta %', iterator, delta;
END IF;
iterator = iterator + 1;
END LOOP;
END;
$$
LANGUAGE plpgsql;
上記のプロセスはすべて関数の形式で記述されているため、最終的なメインプロセスは次のように非常に簡潔になります。
/* main process */
SELECT * FROM init_page_rank();
SELECT * FROM begin_iteration();
/* show result */
SELECT a.paperid, a.papertitle, b.pr_val as pv
FROM node as a
INNER JOIN page_rank as b
ON a.paperid = b.paperid
ORDER BY pv DESC
LIMIT 10;
試してみる簡単なテスト ケースを作成する
TRUNCATE TABLE node;
TRUNCATE TABLE edge;
/* test checked and answer is same as expected */
INSERT INTO node(paperid, papertitle) VALUES
(1, 'aaa'),
(2, 'bbb'),
(3, 'ccc'),
(4, 'ddd'),
(5, 'eee');
INSERT INTO edge(paperid, citedpaperid) VALUES
(1, 2),
(1, 3),
(1, 4),
(2, 3),
(3, 5),
(4, 3),
(4, 5);
SELECT * FROM init_page_rank();
SELECT * FROM begin_iteration();
/* show the result */
SELECT a.paperid, a.papertitle, b.pr_val as pv
FROM node as a
INNER JOIN page_rank as b
ON a.paperid = b.paperid
ORDER BY pv DESC
LIMIT 10;
結果は次のとおりです
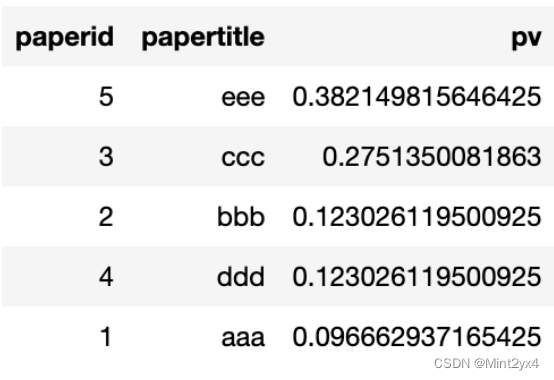
4. まとめ
反復アルゴリズムの速度はまだ若干遅いです。スタンドアロン テストでは 10k 程度のノードの page_rank を更新するのに約 10 秒かかります。将来的には行列演算の使用を検討して高速化することを検討してください。