MySQL データベース - 高度なクエリ ステートメント
1. データベースクエリ
データベースは、データの保存、更新、クエリに使用されるツールであり、データのクエリはデータベースの中核機能です。データベースは情報の伝達に使用され、情報は分析と表示に使用されます。したがって、より洗練されたクエリ方法を習得する必要があります。この記事では、データの高度なクエリ ステートメントに焦点を当てます。
2. 効率的なクエリ方法
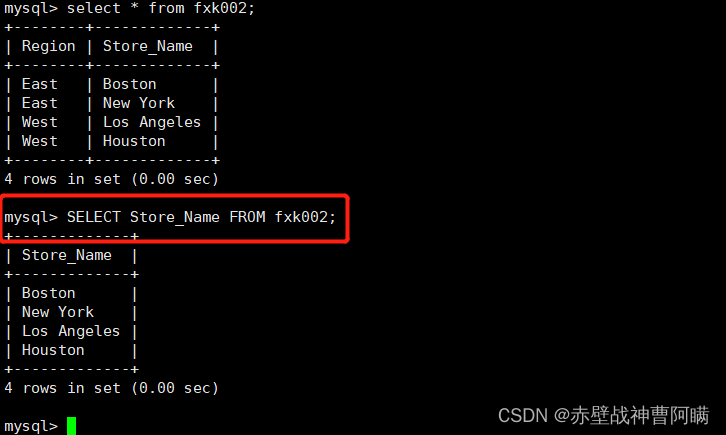
1. クエリするフィールドを指定します - SELECT
構文:SELECT "字段" FROM "表名";
例: SELECT Store_Name FROM fxk002;
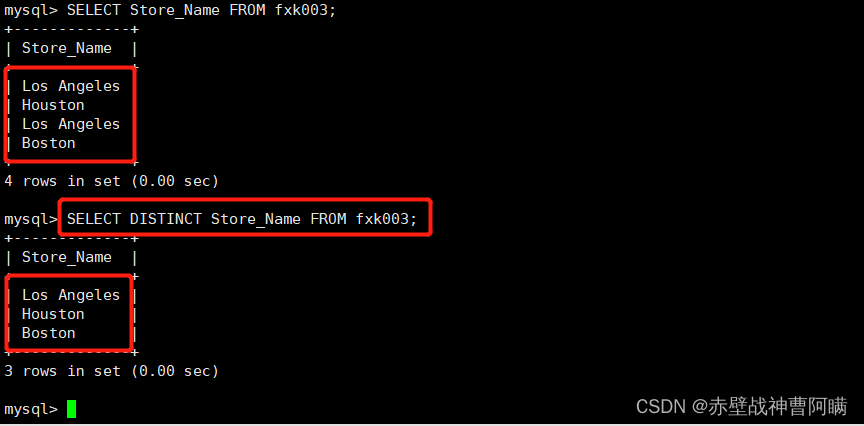
2. フィールドに対して重複排除クエリを実行します - DISTINCT
構文:SELECT DISTINCT "字段" FROM "表名";
例: SELECT DISTINCT Store_Name FROM fxk003;
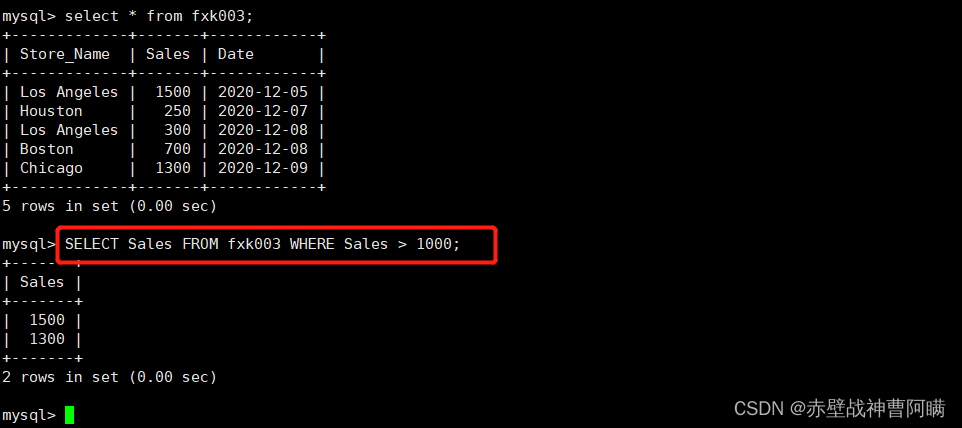
3. 条件クエリ - ここで
構文:SELECT "字段" FROM "表名" WHERE "条件";
例: SELECT Store_Name FROM fxk002 WHERE Sales > 1000;
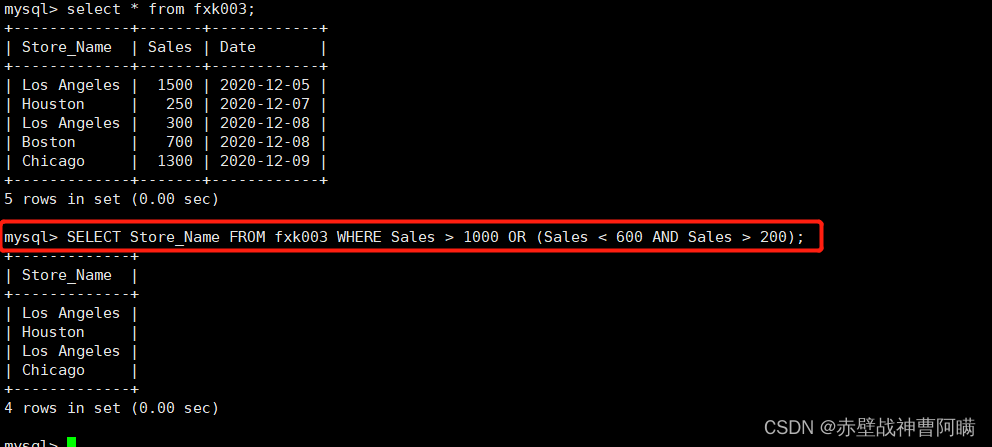
3. 論理関係のクエリを増やす - and and or
语法:SELECT "字段" FROM "表名" WHERE "条件1" {[AND|OR] "条件2"}+ ;
例:SELECT Store_Name FROM fxk003 WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);
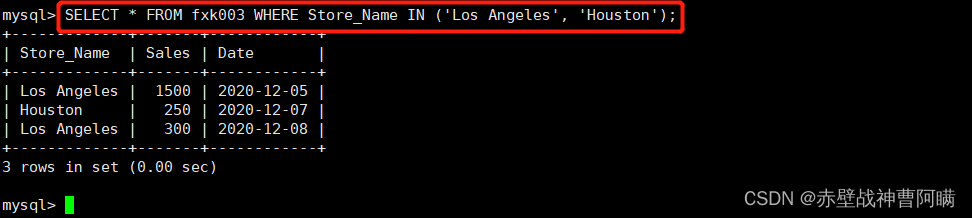
4. 既知の値のデータ レコード クエリ - IN
语法:SELECT "字段" FROM "表名" WHERE "字段" IN ('值1', '值2', ...);
例:SELECT * FROM fxk003 WHERE 店舗名 IN ('ロサンゼルス', 'ヒューストン');
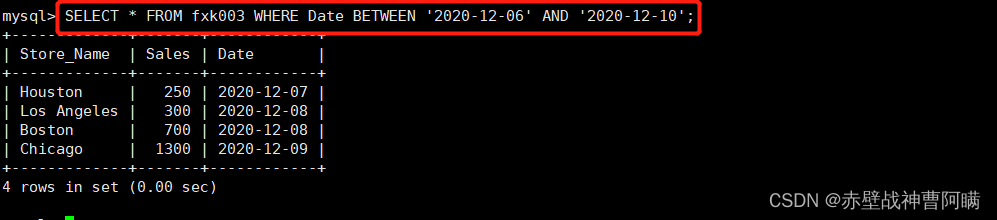
5. 範囲内のデータレコードクエリ - BETWEEN
構文:SELECT "字段" FROM "表名" WHERE "字段" BETWEEN '值1' AND '值2';
例: SELECT * FROM fxk003 WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';
6. ワイルドカードクエリ
通常、ワイルドカードは LIKE と一緒に使用されます。
| ワイルドカード | 説明する |
|---|---|
| % | パーセント記号はゼロ、1 つ以上の文字を意味します |
| _ | アンダースコアは単一の文字を表します |
LIKE - パターンに一致して、必要なデータ レコードを検索します
。 構文:SELECT "字段" FROM "表名" WHERE "字段" LIKE {模式};
例: SELECT * FROM fxk003 WHERE Store_Name like '%on%';

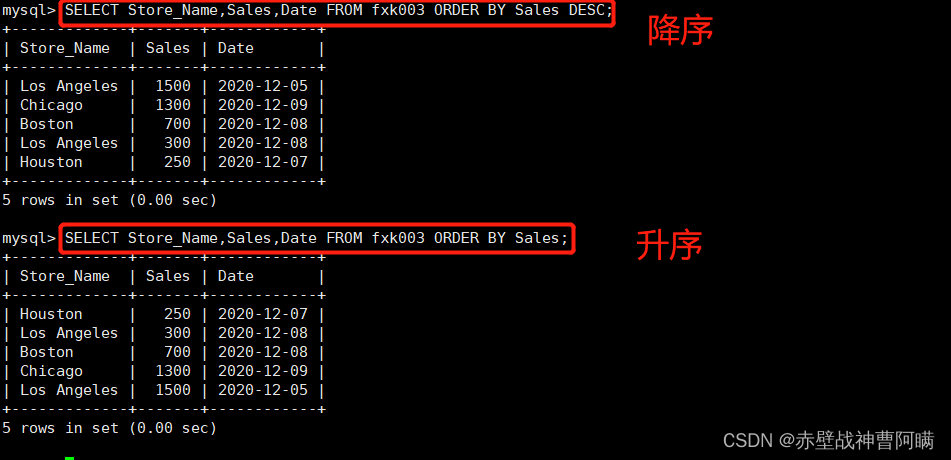
7. キーワードソートクエリ - ORDER BY
语法:SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
ASC 是按照升序进行排序的,是默认的排序方式。
DESC 是按降序方式进行排序。
例:fxk003 から店舗名、売上、日付を選択し、売上の DESC で注文します。
3. 関数クエリ
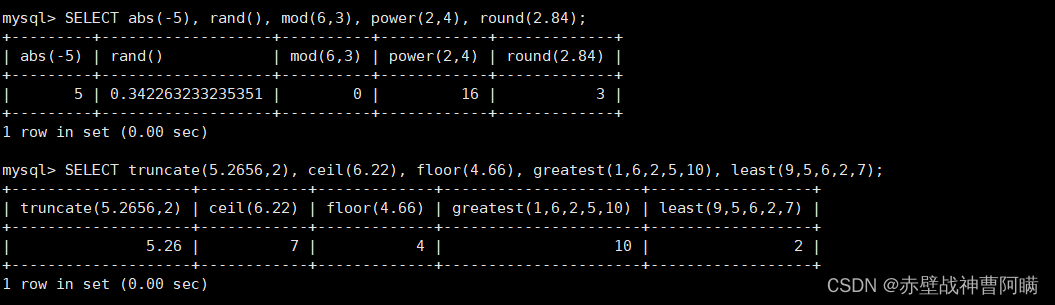
1. データベースで一般的に使用される数学関数
| 数学関数 | 効果 |
|---|---|
| 腹筋(x) | x の絶対値を返します |
| ランド() | 0 から 1 までの乱数を返します |
| mod(x,y) | xをyで割った余りを返します。 |
| べき乗(x,y) | x の y 乗を返します |
| ラウンド(x) | xに最も近い整数を返します |
| ラウンド(x,y) | x を小数点以下 y 桁に丸めた値 |
| sqrt(x) | x の平方根を返します |
| 切り捨て(x,y) | 数値 x を小数点以下 y 桁に切り捨てた値を返します。 |
| 天井(x) | x 以上の最小の整数を返します |
| 床(x) | x以下の最大の整数を返します |
| 最大(x1、x2…) | コレクション内の最大値を返します。また、複数のフィールドの最大値を返すこともできます |
| 最小(x1、x2…) | コレクション内の最小値を返します。また、複数のフィールドの最小値を返すこともできます。 |
2. 集計関数:
| 集計関数 | 効果 |
|---|---|
| 平均() | 指定された列の平均を返します |
| カウント() | 指定された列内の NULL 以外の値の数を返します |
| 分() | 指定された列の最小値を返します。 |
| 最大() | 指定された列の最大値を返します。 |
| 合計(x) | 指定された列のすべての値の合計を返します |

3. 文字列関数:
| 文字列関数 | 効果 |
|---|---|
| トリム() | 指定された形式を削除した値を返します |
| concat(x,y) | 指定されたパラメータ x と y を文字列に連結します。 |
| 部分文字列(x,y) | 文字列 x の y 番目の位置から始まる文字列を取得します。これは substring() 関数と同じ効果があります。 |
| substr(x,y,z) | 文字列 x の位置 y から始まる長さ z の文字列を取得します。 |
| 長さ(x) | 文字列 x の長さを返します。 |
| replace(x,y,z) | 文字列 x の文字列 y を文字列 z に置き換えます。 |
| 上(x) | 文字列 x のすべての文字を大文字に変換します |
| 下(x) | 文字列 x のすべての文字を小文字に変換します |
| 左(x,y) | 文字列 x の最初の y 文字を返します。 |
| 右(x,y) | 文字列 x の最後の y 文字を返します。 |
| 繰り返し(x,y) | 文字列を x y 回繰り返します |
| スペース(x) | x 個のスペースを返します |
| strcmp(x,y) | x と y を比較すると、戻り値は -1、0、1 になります。 |
| 逆(x) | 文字列 x を反転します |
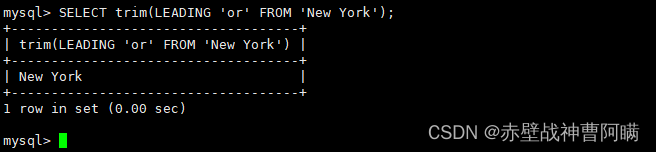
1. 文字のトリミングを削除する
1.去除字符 trim
语法格式:SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
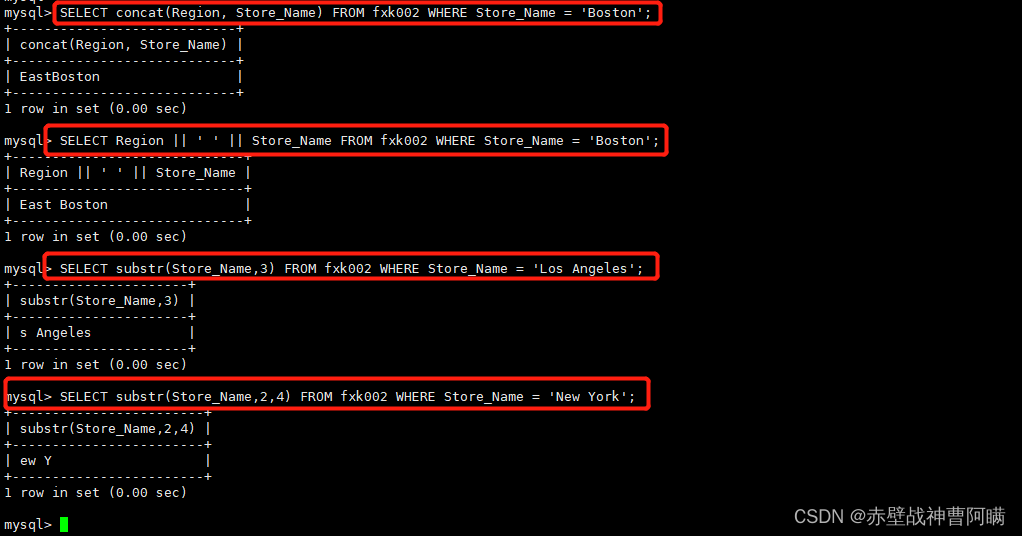
2. 截取 substr
语法格式:SELECT substr(x,y) #截取x字符串 从第y个开始,截取到末尾
3.字段拼接 concat
语法格式: select concat(字段1,字段2) from 表名;
使用 || 符号
将info表中,name字段值和height字段值拼接在一起。
语法格式: select 字段1 || 字段2 from 表名;
将info表中,name字段值和height字段值拼接在一起,且中间加空格。
语法格式: select 字段1 || ' ' || 字段2 from 表名;
4.返回字符长度 length
语法格式: select length(字段1) from 表名;
5.替换 replace
select replace(字段1,'替换前字符段','替换后字符段') from 表名;
4. 高度なクエリ文
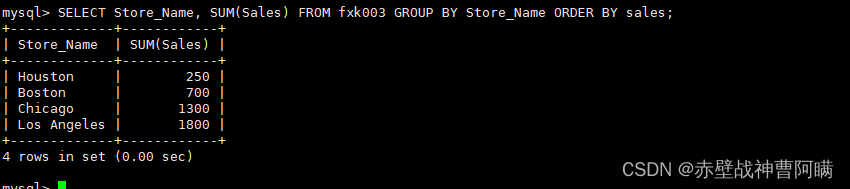
1. グループ化と要約 - GROUP BY
GROUP BY の背後にあるフィールドのクエリ結果を要約してグループ化します。これは通常、集計関数と組み合わせて使用されます。GROUP
BY には、GROUP BY の後に表示されるすべてのフィールドが SELECT の後に表示される必要があるという原則があります。SELECT および の後に
表示されるすべてのフィールドは、集計関数に出現しないフィールドは、GROUP BY の後に出現する必要があります。
语法:SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1";
例:SELECT Store_Name, SUM(Sales) FROM fxk003 GROUP BY Store_Name ORDER BY sales;
2.过滤——HAVING
用来过滤由 GROUP BY 语句返回的记录集,通常与 GROUP BY 语句联合使用
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
语法:SELECT "字段1", SUM("字段2") FROM "表格名" GROUP BY "字段1" HAVING (函数条件);
例:SELECT Store_Name, SUM(Sales) FROM fxk003 GROUP BY Store_Name HAVING SUM(Sales) > 1500;

3.别名设置
----字段別名 表格別名
语法:SELECT "表格別名"."字段1" [AS] "字段別名" FROM "表格名" [AS] "表格別名";
例:SELECT A.Store_Name Store, SUM(A.Sales) “Total Sales” FROM fxk003 A GROUP BY A.Store_Name;

4.子查询
连接表格,在WHERE 子句或 HAVING 子句中插入另一个 SQL 语句
语法:SELECT "字段1" FROM "表格1" WHERE "字段2" [比较运算符] 外查询
(SELECT "字段1" FROM "表格2" WHERE "条件"); 内查询
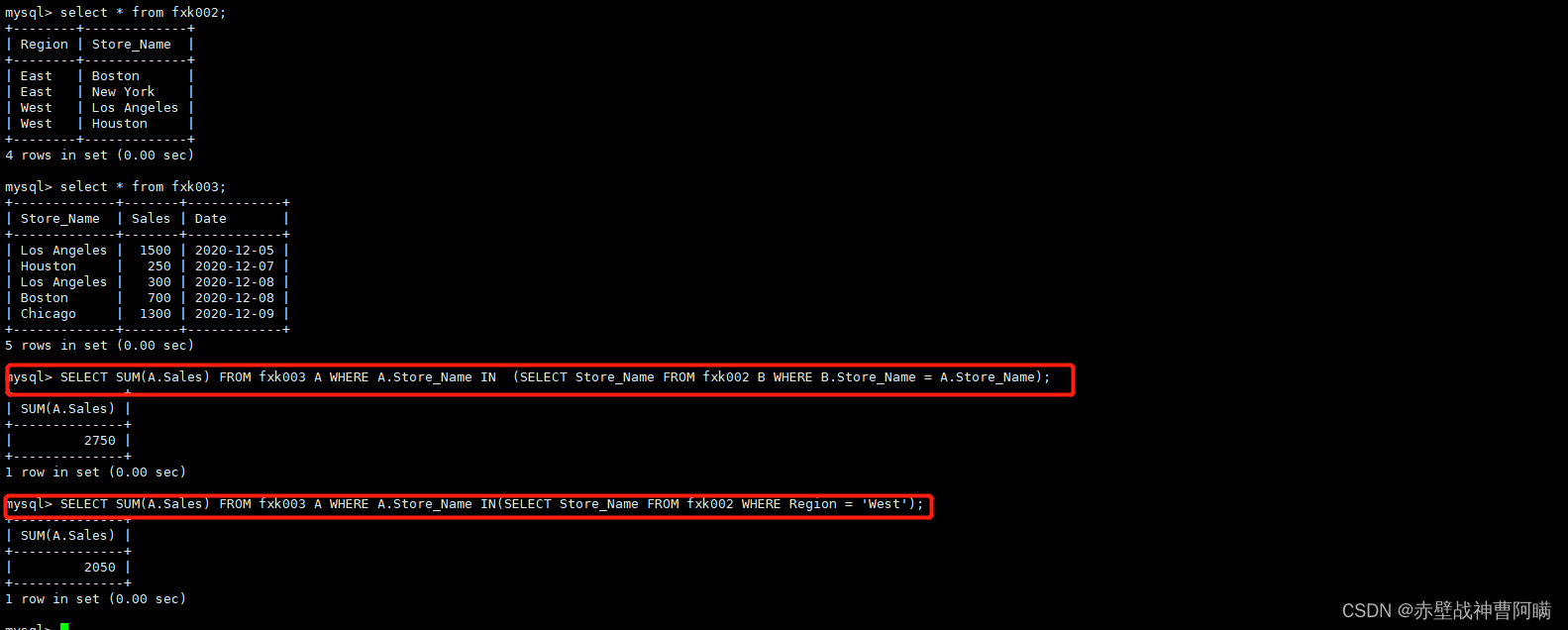
5.EXISTS
用来测试内查询有没有产生任何结果,类似布尔值是否为真
#如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果。
语法:SELECT "字段1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
例:SELECT SUM(Sales) FROM fxk003 WHERE EXISTS (SELECT * FROM fxk002 WHERE Region = ‘West’);

五、表连接查询
MYSQL数据库中常用的表连接有三种
1.inner join(内连接)
只返回两个表中联结字段相等的行
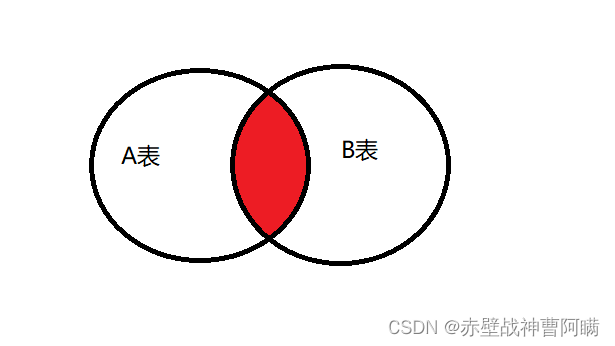
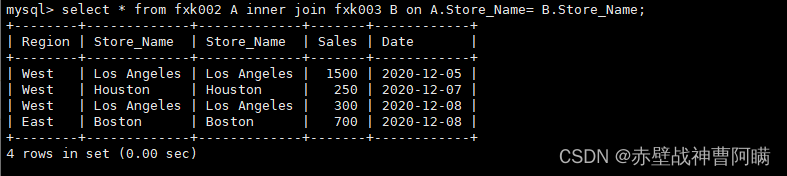
语法:select * from 表1 A inner join 表2 B on A.字段 = B.字段;
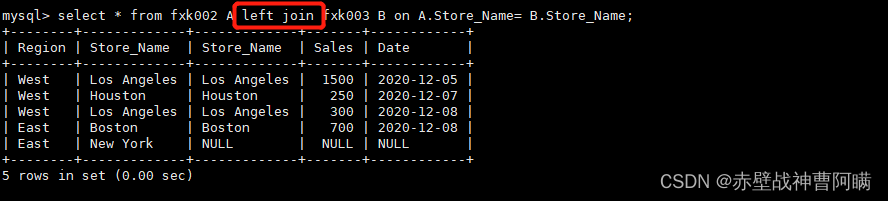
2.left join(左连接)
返回包括左表中的所有记录和右表中联结字段相等的记录

语法:select * from 表1 A left join 表2 B on A.字段 = B.字段;
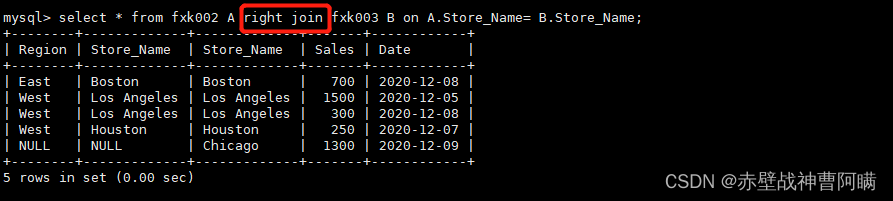
3.right join(右连接)
:返回包括右表中的所有记录和左表中联结字段相等的记录
语法:select * from 表1 A right join 表2 B on A.字段 = B.字段;
六、视图的运用—— view
视图:可以被当作是虚拟表或存储查询。
- 视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
- 临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
- 视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
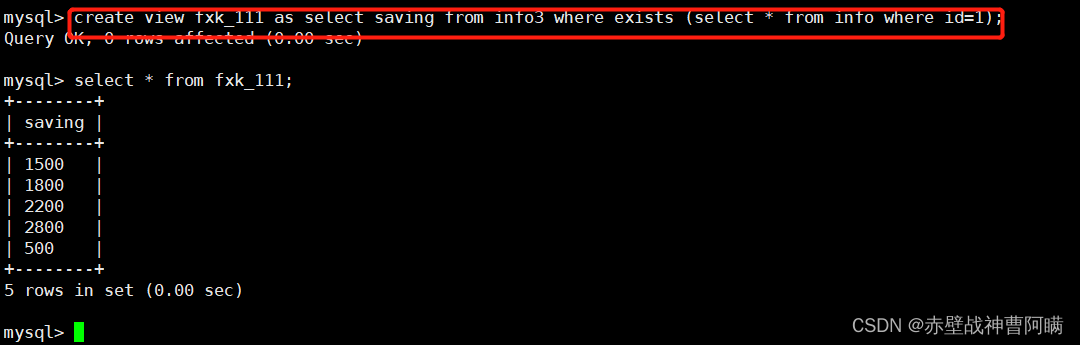
语法格式:
创建视图表:CREATE VIEW "视图表名" AS "SELECT 语句";
删除视图表: DROP VIEW "视图表名";
七、联级——UNION
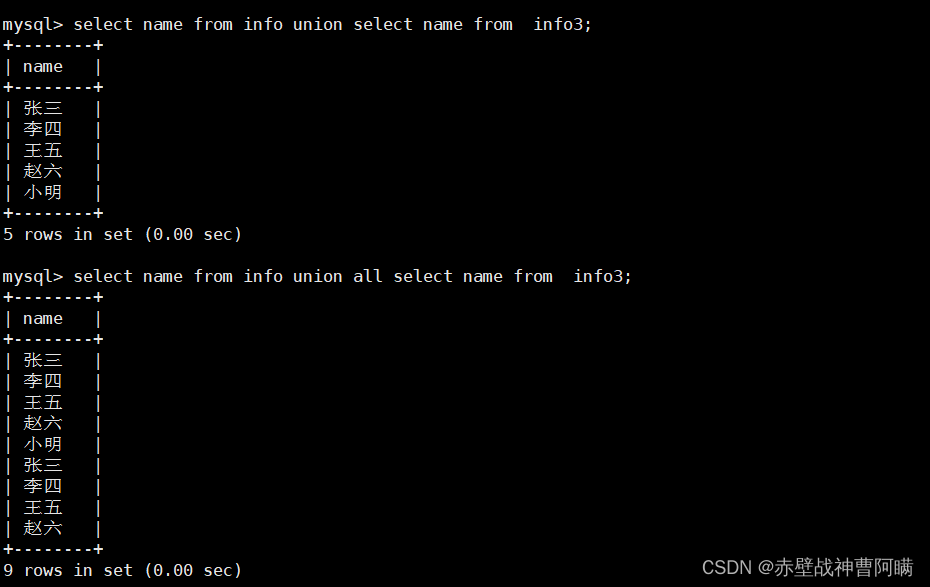
记录种类
UNION :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
UNION ALL :将生成结果的数据记录值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
八、交集值 ----取两个SQL语句结果的交集
1.联级视图求交集值
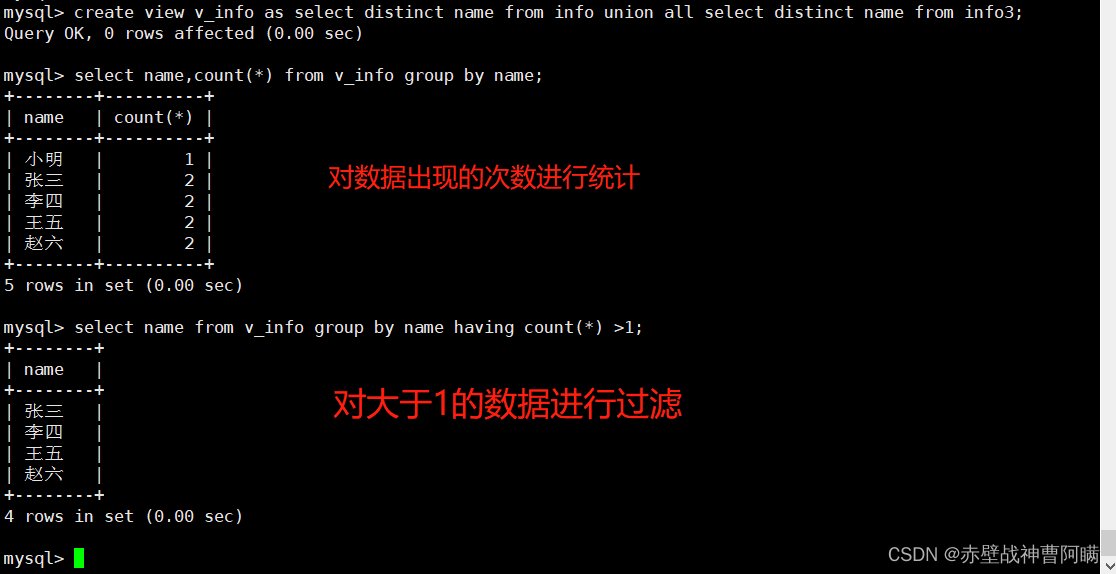
create view v_info as select distinct name from info union all select distinct name from info3;
select name,count(*) from v_info group by name;
select name from v_info group by name having count(*) >1;
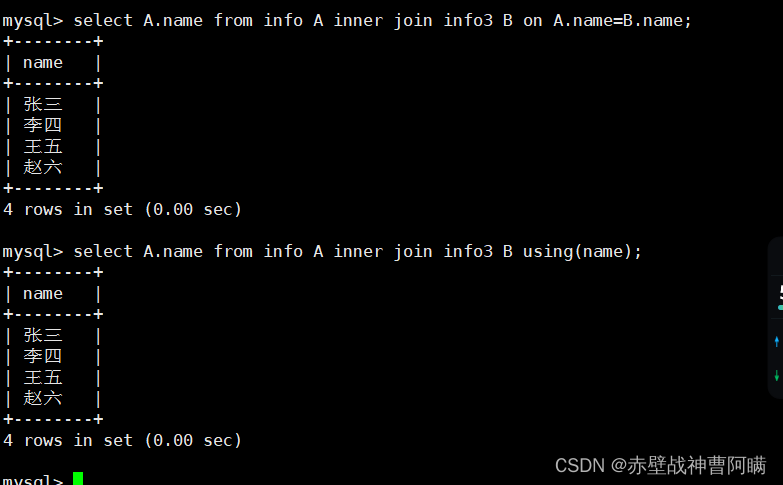
2.内连接求交集值
select A.name from info A inner join info3 B on A.name=B.name;
select A.name from info A inner join info3 B using(name);
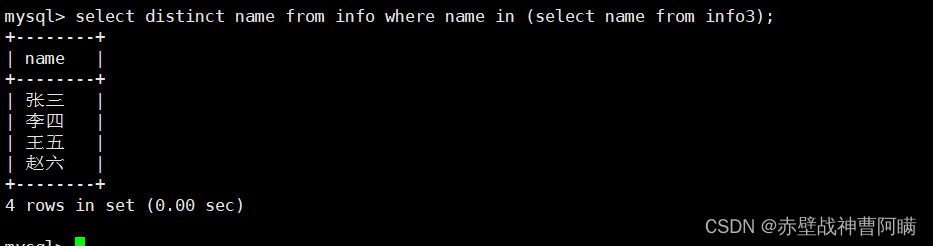
3.使用子查询的方式求交集值
4.取非交集值
- 联级方法中 count(*)<=1
- 左右内连接 将is not null 改为 is null
- 子查询 外连接查询 not in (内连接查询)
九、case 条件选择查询语句
SELECT CASE ("字段名")
WHEN "条件1" THEN "结果1"
WHEN "条件2" THEN "结果2"
[ELSE "结果N"]
END
FROM "表名";
# "条件"可以是一个数值或是公式。ELSE子句则并不是必须的

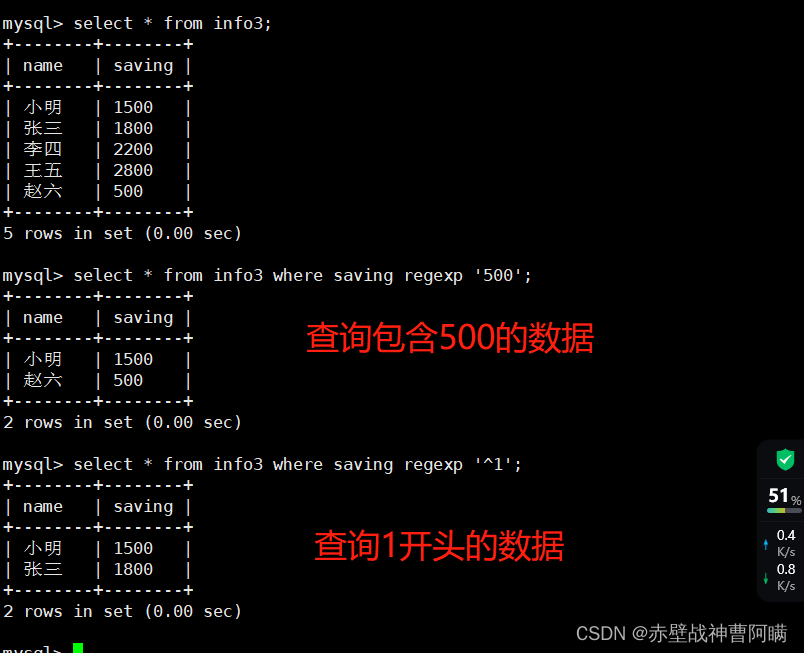
十、正则表达式
| 匹配模式 | 描述 | 实例 |
|---|---|---|
^ |
匹配文本的开始字符 | ‘^bd’ 匹配以 bd 开头的字符串 |
$ |
匹配文本的结束字符 | ‘qn$’ 匹配以 qn 结尾的字符串 |
. |
匹配任何单个字符 | ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串 |
* |
先行する 0 個以上の文字と一致します | 'fo*t' は、任意の o が前にある t と一致します。 |
+ |
前の文字と 1 回以上一致します | 「hom+」は、ho で始まり、その後に少なくとも 1 つの m が続く文字列と一致します。 |
字符串 |
指定された文字列と一致します | 「clo」は clo を含む文字列と一致します |
p1丨p2 |
p1 または p2 に一致します | 「bg丨fg」は bg または fg と一致します |
[...] |
文字セット内の任意の文字と一致します | '[abc]' は a、b、または c に一致します |
[^...] |
括弧内にない任意の文字と一致します | '[^ab]' は、a または b を含まない文字列と一致します。 |
{n} |
前の文字列と n 回一致します | 'g{2}' は 2 g を含む文字列と一致します |
{n,m} |
前の文字列と少なくとも n 回、最大で m 回一致します | 'f{1,3}' は f に少なくとも 1 回、最大 3 回一致します |
文法:SELECT "字段" FROM "表名" WHERE "字段" REGEXP {模式};