CSDN ユーザーの皆さん、こんにちは。Xiaoyalan の MySQL データベース列を長い間更新していませんでした。次の期間で、Xiaoyalan は MySQL データベースの知識を更新します。さて、今日のトピックである基本的な SELECT ステートメントに入りましょう。! !!
SQLの概要
SQL言語のルールと仕様
基本的な SELECT ステートメント
テーブル構造を表示
データをフィルタリングする
SQLの概要
SQL の背景知識
1946年に世界初のコンピューターが誕生し、現在ではこのコンピューターによって発展したインターネットが独自の世界となっています。過去数十年にわたり、この分野では数え切れないほどのテクノロジーや産業が栄枯盛衰を繰り返してきましたが、依然として隆盛を極めているものもあれば、栄枯盛衰を経験したものもあります。しかし、この大きな変動の中でも、決して消えることなく、時間の経過とともにさらに強化されているテクノロジーが 1 つあります。それが SQL です。
45 年前の 1974 年に、IBM の研究者はデータベース技術を明らかにした論文「SEQUEL: 構造化英語クエリ言語」を発表しました。今日に至るまで、この構造化クエリ言語はあまり変わっていません。他の言語と比較すると、SQL の半減期は長くなります。とても長いと言われます。
フロントエンド エンジニアであろうとバックエンド アルゴリズム エンジニアであろうと、間違いなくデータを扱うことになるため、全員が必要なデータを迅速かつ正確に抽出する方法を知る必要があります。データを操作し、ビジネス上の意思決定を導くためにさまざまなレポートを作成するのが仕事であるデータ アナリストは言うまでもありません。
SQL (Structured Query Language) は、リレーショナル モデルを使用し、データを直接処理するデータベース アプリケーション言語であり、1970 年代に IBM によって開発されました。その後、米国規格協会 (ANSI) は、SQL-86、SQL-89、SQL-92、SQL-99 およびその他の標準を含む SQL 標準の策定を開始しました。
SQL には、SQL92 と SQL99 という 2 つの重要な標準があり、それぞれ 1992 年と 1999 年に公布された SQL 標準を表しており、現在でも使用されている SQL 言語はこれらの標準に従っています。
さまざまなデータベース メーカーが SQL ステートメントをサポートしていますが、それぞれに独自の内容があります。
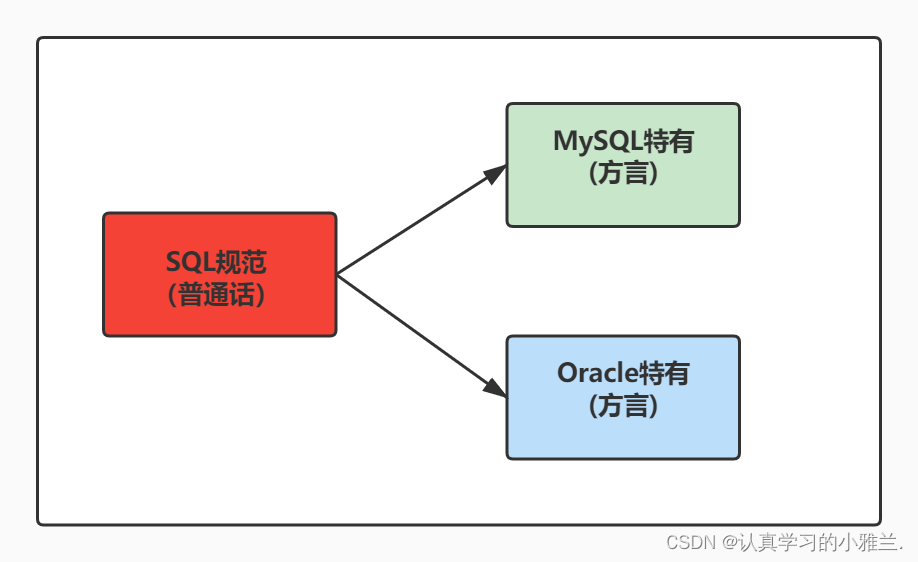
SQL言語ランキング
SQL は TIOBE プログラミング言語ランキングに参加して以来、トップ 10 内に留まり続けています。
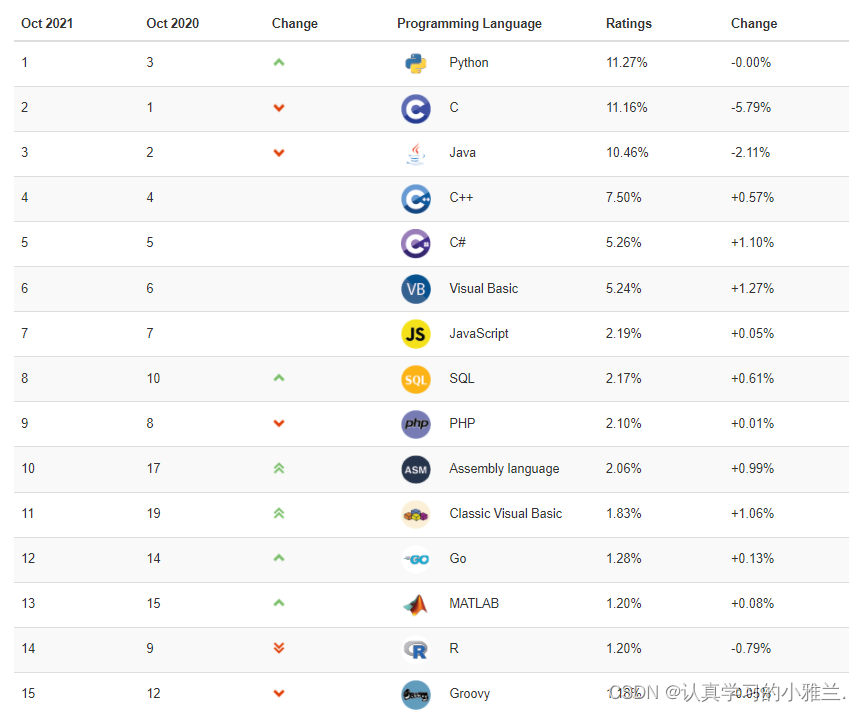
SQLの分類
SQL 言語は、機能の観点から主に 3 つのカテゴリに分類されます。
- DDL (データ定義言語、データ定義言語) に準拠したこれらのステートメントは、データベース、テーブル、ビュー、インデックスなどのさまざまなデータベース オブジェクトを定義し、データベースやデータ テーブルの構造の作成、削除、変更にも使用できます。主なステートメントのキーワードには、CREATE、DROP、ALTER などが含まれます。
- DML (データ操作言語)。データベース レコードの追加、削除、更新、クエリを実行し、データの整合性をチェックするために使用されます。主なステートメントのキーワードには、INSERT、DELETE、UPDATE、SELECT などが含まれます。SELECT は SQL 言語の基礎であり、最も重要です。
- DCL (データ制御言語) は、データベース、テーブル、フィールド、ユーザーのアクセス権とセキュリティ レベルを定義するために使用されます。主なステートメントのキーワードには、GRANT、REVOKE、COMMIT、ROLLBACK、SAVEPOINT などが含まれます。
クエリ ステートメントは非常に頻繁に使用されるため、多くの人はクエリ ステートメントを DQL (データ クエリ言語) という 1 つのカテゴリに分類します。
TCL(Transaction Control Language、トランザクション制御言語)と呼ばれる別々のCOMMITとROLLBACKもあります。
SQL言語のルールと仕様
基本原則
SQL は 1 行で記述することも、複数行で記述することもできます。
読みやすさを向上させるために、各句は別の行に記述され、必要に応じてインデントが使用されます。各コマンドは、; または \g または \G で終わります。
キーワードを省略したり、複数の行に分割したりすることはできません
句読点について
すべての ()、一重引用符、および二重引用符がペアで終わっていることを確認する必要があります。
英語では半角入力を使用する必要があります。
文字列型および日時型のデータは一重引用符(' ')を使用して表現できます。
列の別名には二重引用符 (" ") を使用するようにしてください。as を省略することはお勧めできません。
SQL ケースの仕様 (従うことを推奨)
MySQL は Windows 環境では大文字と小文字が区別されません
Linux 環境では MySQL は大文字と小文字を区別します。
データベース名、テーブル名、テーブルの別名、変数名では、大文字と小文字が厳密に区別されます。
キーワード、関数名、列名 (またはフィールド名)、列の別名 (フィールドの別名) は大文字と小文字が区別されません。
統一された記述標準を採用することが推奨されます。
データベース名、テーブル名、テーブルの別名、フィールド名、フィールドの別名などはすべて小文字です。
SQL キーワード、関数名、バインド変数などはすべて大文字で表記されます。
コメント
以下の形式のアノテーション構造が使用可能です
単一行コメント: #comment text (MySQL 固有のメソッド)
単一行のコメント: -- コメント テキスト (-- 後にスペースを含める必要があります。)
複数行コメント: /* コメントテキスト*/
命名規則
- データベース名とテーブル名は 30 文字を超えてはならず、変数名は 29 文字に制限されます。
- 合計で A ~ Z、a ~ z、0 ~ 9、_63 文字のみを含める必要があります
- データベース名、テーブル名、フィールド名などのオブジェクト名にはスペースを含めないでください。
- 同じ MySQL ソフトウェア内でデータベースに同じ名前を付けることはできません。同じライブラリ内でテーブルに同じ名前を付けることはできません。同じテーブル内でフィールドに同じ名前を付けることはできません。
- フィールドが予約語、データベース システム、または一般的なメソッドと競合しないことを確認する必要があります。どうしても使用したい場合はSQL文中で`(強調マーク)を使用してください。
- フィールド名と型の一貫性を保つ フィールドに名前を付け、データ型を割り当てるときは、必ず一貫性を確保してください。あるテーブルでデータ型が整数である場合、別のテーブルではそれを文字に変更しないでください。
例:
#以下两句是一样的,不区分大小写
show databases;
SHOW DATABASES;
#创建表格
#create table student info(...); #表名错误,因为表名有空格
create table student_info(...);
#其中order使用``飘号,因为order和系统关键字或系统函数名等预定义标识符重名了
CREATE TABLE `order`();
select id as "编号", `name` as "姓名" from t_stu; #起别名时,as都可以省略
select id as 编号, `name` as 姓名 from t_stu; #如果字段别名中没有空格,那么可以省略""
select id as 编 号, `name` as 姓 名 from t_stu; #错误,如果字段别名中有空格,那么不能省略""
データインポート手順
コマンドラインクライアントでmysqlにログインし、sourceコマンドを使用してインポートします。
mysql> ソース d:\mysqldb.sql
mysql> desc 従業員;
+-----+---------------+-----+-----+----- ----+------+
| フィールド | タイプ | ヌル | キー | デフォルト | 番外編 |
+-----+---------------+-----+-----+----- ----+------+
| 従業員 ID | int(6) | いいえ | プリ | 0 | |
| 名 | varchar(20) | はい | | NULL | |
| 姓 | varchar(25) | いいえ | | NULL | |
| メール | varchar(25) | いいえ | ユニ | NULL | |
| 電話番号 | varchar(20) | はい | | NULL | |
| 採用日 | 日付 | いいえ | | NULL | |
| ジョブID | varchar(10) | いいえ | マル | NULL | |
| 給与 | ダブル(8,2) | はい | | NULL | |
| コミッション_pct | ダブル(2,2) | はい | | NULL | |
| マネージャー ID | int(6) | はい | マル | NULL | |
| 部門ID | int(4) | はい | マル | NULL | |
+-----+---------------+-----+-----+----- ----+------+
11 行セット (0.00 秒)
基本的な SELECT ステートメント
選択する...
SELECT 1; #没有任何子句
SELECT 9/2; #没有任何子句
...から選択
文法:
SELECT は選択する列を識別します
FROM はどのテーブルから選択するかを識別します
すべての列を選択します。
選択する *
部門から。
一般に、テーブル内のすべてのフィールド データを使用する必要がない限り、ワイルドカード文字「*」を使用しないことをお勧めします。ワイルドカードを使用するとクエリ ステートメントの入力時間を節約できますが、不要な列データを取得すると、クエリや使用するアプリケーションの効率が低下することがよくあります。ワイルドカードの利点は、名前が不明な場合に必要な列を取得するために使用できることです。
運用環境では、SELECT * を直接使用してクエリを実行することはお勧めできません。
特定の列を選択します。
SELECT 部門 ID、場所 ID
部門から。
MySQL の SQL ステートメントでは大文字と小文字が区別されないため、SELECT と select の機能は同じです。ただし、多くの開発者はキーワードを大文字にし、データ列とテーブル名を小文字にすることに慣れています。読者もプログラミングの良い習慣を身に付ける必要があります。コードこのように書かれた方が読みやすく、管理しやすいです。
列の別名
列の名前を変更する
計算が簡単
列名に続いて、列名と別名の間にキーワード AS を追加することもできます。別名にスペースまたは特殊文字が含まれ、大文字と小文字が区別されるように、別名には二重引用符を使用します。
ASは省略可能
エイリアスは短く、名前の意味を理解できるようにすることをお勧めします。
例
SELECT last_name AS 名、commission_pct 通信
従業員から。

SELECT last_name "名前",給与*12 "年収"
従業員から。

![]()
重複した行を削除する
デフォルトでは、クエリは重複行を含むすべての行を返します。
部門 ID を選択します
従業員から。

![]()
重複する行を削除するには、SELECT ステートメントでキーワード DISTINCT を使用します。
SELECT DISTINCT 部門 ID
従業員から。

![]()
対象者:
SELECT DISTINCT 部門 ID、給与
従業員から;
DISTINCT は実際に後続の列名のすべての組み合わせを重複排除します。これら 74 個の部門 ID は異なり、すべてに給与属性値があるため、最終結果は 74 個のエントリであることがわかります。さまざまな部門 (部門 ID) を表示したい場合は、DISTINCT 部門 ID を記述するだけでよく、後で他の列名を追加する必要はありません。
Null値が操作に参加する
演算子または列の値が null 値に遭遇すると、操作の結果は null になります。
SELECT employee_id,salary,commission_pct,
12 * salary * (1 + commission_pct) "annual_sal"
FROM employees;ここで、MySQL では、null 値は空の文字列と等しくないことに注意してください。空の文字列の長さは 0 ですが、null 値の長さはゼロです。さらに、MySQL では、null 値がスペースを占有します。
強調
正しくない
mysql> SELECT * FROM ORDER;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that
corresponds to your MySQL server version for the right syntax to use near 'ORDER' at
line 1
正しい
mysql> SELECT * FROM `ORDER`;
+----------+------------+
| order_id | order_name |
+----------+------------+
| 1 | shkstart |
| 2 | tomcat |
| 3 | dubbo |
+----------+------------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM `order`;
+----------+------------+
| order_id | order_name |
+----------+------------+
| 1 | shkstart |
| 2 | tomcat |
| 3 | dubbo |
+----------+------------+
3 rows in set (0.00 sec)
結論は
テーブル内のフィールド、テーブル名などが予約語、データベース システム、または一般的なメソッドと競合しないようにする必要があります。本当に同じ場合はSQL文中で「」(強調マーク)を使用してください。
クエリ定数
SELECT クエリは定数をクエリすることもできます。そうです、それは SELECT クエリの結果に固定定数列を追加することを意味します。この列の値は、データ テーブルから動的に取得されるのではなく、当社によって指定されます。
なぜ定数をクエリする必要があるのかと疑問に思われるかもしれません。
SQL の SELECT 構文は、この機能を提供します。一般的に、1 つのテーブルのデータのみをクエリします。通常、固定の定数列を追加する必要はありませんが、異なるデータ ソースを統合する場合は、テーブルのテーブルとして定数列を使用します。マーク、定数をクエリする必要があります。
たとえば、従業員データ テーブルの従業員名をクエリすると同時に、企業という列フィールドを追加したいとします。このフィールドの固定値は「シリコン バレー」です。次のように記述できます。
企業として「シリコン バレー」を選択し、従業員から姓を選択します。
テーブル構造を表示
DESCRIBE または DESC コマンドを使用して、テーブル構造を示します。
DESCRIBE employees;
或
DESC employees;
mysql> desc employees;
+----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+-------------+------+-----+---------+-------+
| employee_id | int(6) | NO | PRI | 0 | |
| first_name | varchar(20) | YES | | NULL | |
| last_name | varchar(25) | NO | | NULL | |
| email | varchar(25) | NO | UNI | NULL | |
| phone_number | varchar(20) | YES | | NULL | |
| hire_date | date | NO | | NULL | |
| job_id | varchar(10) | NO | MUL | NULL | |
| salary | double(8,2) | YES | | NULL | |
| commission_pct | double(2,2) | YES | | NULL | |
| manager_id | int(6) | YES | MUL | NULL | |
| department_id | int(4) | YES | MUL | NULL | |
+----------------+-------------+------+-----+---------+-------+
11 rows in set (0.00 sec)
このうち、各フィールドの意味は次のように説明されます。
- フィールド:フィールド名を示します。
- Type: フィールドのタイプを示します。ここで、バーコードと商品名はテキスト型、価格は整数型です。
- Null: 列に NULL 値を格納できるかどうかを示します。
- キー: 列にインデックスが付けられているかどうかを示します。PRI は列がテーブルの主キーの一部であることを意味し、UNI は列が UNIQUE インデックスの一部であることを意味し、MUL は特定の値が列内に複数回出現できることを意味します。
- デフォルト: 列にデフォルト値があるかどうか、デフォルト値がある場合はその値が何かを示します。
- 追加: AUTO_INCREMENT など、取得可能な特定の列に関連する追加情報を示します。
データをフィルタリングする
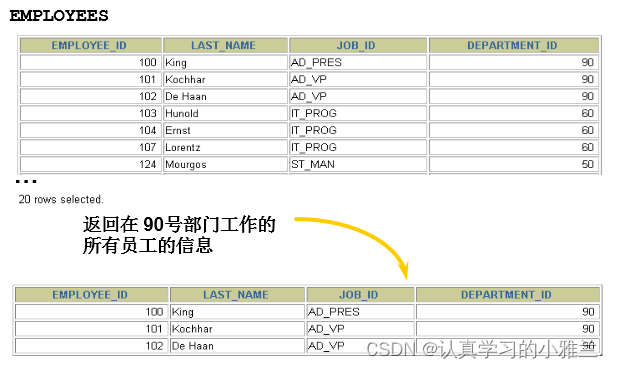
文法:
SELECT 字段1,字段2
FROM 表名
WHERE 过滤条件
WHERE 句を使用して、条件を満たさない行を除外します。
WHERE 句は FROM 句の後に続きます
例
SELECT employee_id, last_name, job_id, department_id
FROM employees
WHERE department_id = 90 ;

来て!!!
