1.事務(筆記試験と面接で試験されることが多い)
1.1 取引の概要
- MySQL データベースでは、InnoDB および BDB ストレージ エンジンのみがトランザクションをサポートし、MyISAM ストレージ エンジンはトランザクションをサポートしません。デフォルトのストレージ エンジンは InnoDB です。
- トランザクションとは、一連の SQL ステートメントを同じバッチで実行することです。
- SQL ステートメントが失敗すると、バッチ内のすべての SQL がキャンセルされます。
- トランザクションは、データの整合性と正確性、操作の原子性、同時アクセス時のデータの分離を保証するために使用されます。
- トランザクションは、INSERT、UPDATE、DELETE などの DML ステートメントを管理するために使用されます。
- トランザクションは手動でオープン、コミット、ロールバックする必要がありますが、自動的にコミットすることもできます。
- トランザクションのスコープは SESSION (セッション制御) であり、1 つの SESSION 内に複数のトランザクションが存在する可能性があります。Common SESSION: JDBC の Connection オブジェクト、つまりスレッド。コマンド ライン ウィンドウも SESSION です。
- トランザクションにはセキュリティ ポイントがあり、これは大きなトランザクションを小さなトランザクションに分割し、ロールバックするときにすべてのデータをロールバックするのではなく、対応するセキュリティ ポイントにのみロールバックするものとして理解できます。
1.2 物事の 4 つの特性 (ACID) (強調)
原子性:
- トランザクションは操作の最も基本的な単位であり、データの追加、変更、削除はすべて実行されるか、まったく実行されず、途中の特定のリンクで終了することはありません。
- トランザクションがコミットされると、トランザクション中のデータへのすべての追加、変更、削除を実行する必要があります。
- トランザクションがロールバックされると、トランザクション中のデータへのすべての追加、変更、削除をロールバックする必要があります。追加されたデータは削除する必要があり、変更されたデータは復元する必要があり、削除されたデータはトランザクションが一度も実行されなかったかのように返される必要があります。
- SESSION、つまりセッション中、トランザクションはコミットもロールバックもされず、セッションが終了してもデータは変更されません。
隔離:
- データベースでは、複数のトランザクションが同じデータを同時に読み取り、変更できます。分離により、複数のトランザクションが同時に実行されるときの相互実行によって引き起こされるデータの不整合を防ぐことができます。トランザクションが 2 つある場合、それらは同時に実行され、同じものが実行されます。トランザクション分離機能により、システム内の各トランザクションが、このトランザクションのみがシステムを使用していると認識されるようになります。このプロパティはシリアル化と呼ばれることもあります。トランザクション操作間の混乱を避けるために、リクエストは一度に 1 つのリクエストのみが同じデータに対して行われるようにシリアル化するか、シリアル化する必要があります。
持続性 (耐久性):
- トランザクションが完了すると、データの変更は永続的になり、システムに障害が発生しても失われることはありません。トランザクションが完了すると、トランザクションによってデータベースに加えられた変更はデータベースに永続的に保存され、保存されなくなります。ロールバックされました。
一貫性のある:
- データベース データの整合性は、トランザクションの開始前もトランザクションの終了後も損なわれていません。
- これは、書き込まれるデータが、データの精度、連続性など、事前に設定されたすべてのルールに完全に準拠する必要があり、後続のデータベースはスケジュールされた作業を自発的に完了できることを意味します。(例: A が B にお金を送金します。A がそのお金を差し引くことは不可能ですが、B はそれを受け取りません。) つまり、複数の同時トランザクションがある場合、システムはシリアル トランザクションとしても動作する必要があります。その最大の特徴は保護と不変性(不変性の保持)であり、送金の場合を例に取ると、口座が 5 つあり、各口座の残高が 100 元であると仮定すると、5 つの口座の合計は 500 元となります。これらの 5 つのアカウントでは、アカウント A と B の間で 5 元の送金、アカウント C と D の間で 10 元の送金、アカウント B とアカウント D の間で 15 元の送金など、アカウント間の数に関係なく、同時に複数の送金が行われます。 E. 5 つの口座の合計金額は 500 元でなければなりません。これは保護と不変です。
- 原子性、分離性、永続性により一貫性が実現されます。
1.3 更新と喪失
複数のトランザクションが同時に 1 つのデータを変更します。各トランザクションは他のトランザクションの存在を知らない、最後の更新が他のトランザクションによる更新をカバーして更新が失われるという問題が発生します。
アップデートが失われる問題には 2 つのタイプがあります
1. トランザクション A のロールバックにより、トランザクション B のコミットされたデータが上書きされます。
それは間違いであり、避けなければなりません。MySQL は解決されました。心配しないでください。2 つのトランザクションが主キー ID に従って同時にデータを更新すると、1 つのトランザクションは意図された排他ロック (IX)、排他ロック (X ロック)、およびレコード ロック (レコード ロック) を取得します。 )、X ロックは排他的であり、現在のトランザクションはコミットまたはロールバックされず、他のトランザクションは現在のデータを操作できません。
2. トランザクション A の送信により、トランザクション B によって送信されたデータが上書きされます。
これはエラーではなく、特定のビジネス状況に応じて判断する必要があります。MySQL は、デフォルトの分離レベル (RR) では 2 番目のタイプの更新損失に対処しません。
1.4 トランザクション制御文
-- 查询全局、以及当前会话的事务隔离级别
SELECT @@global.tx_isolation, @@tx_isolation;
-- 0表示禁止自动提交,1表示自动提交事务
SET AUTOCOMMIT= 0;
-- 显式地开启一个事务
START;
-- 提交事务,并使已对数据库进行的所有修改成为永久性的
COMMITT;
-- 回滚会结束用户的事务,并撤销正在进行的所有未提交的修改
ROLLBACK;
-- SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT
-- 这对于复杂的大事务非常有帮助,例如批量新增1000万的数据,如果中间某一条失败,需要将1000万数据全部回滚吗;如果业务需求,只能全部回滚;如果不需要,可以设置一些保存点,将发生错误时,回滚到最近的保存点上,而不是回滚所有数据
SAVEPOINT identifier;-- 设定保存点,就像游戏关卡保存一样
-- 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常
RELEASE SAVEPOINT identifier;
-- 把事务回滚到标记的保存点
ROLLBACK TO identifier;
-- 设定事务的隔离级别
SET TRANSACTION ISOLATION LEVEL 隔离级别;
-- GLOBAL,设置全局事务隔离级别;SESSION,设置当前会话的隔离级别
-- 如果GLOBAL和SESSION都不设置,表示修改的事务隔离级别将应用于当前session内的下一个还未开始的事务
場合:
/*A在线买一款价格为500元商品,网上银行转账.
A的银行卡余额为2000,然后给商家B支付500.
商家B一开始的银行卡余额为10000
创建数据库shop和创建表account并插入2条数据
*/
CREATE DATABASE `shop`CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `shop`;
CREATE TABLE `account` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(32) NOT NULL,
`cash` DECIMAL(9,2) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO account (`name`,`cash`)
VALUES('A',2000.00),('B',10000.00)
-- 转账实现
SET autocommit = 0; -- 关闭自动提交
START TRANSACTION; -- 开始一个事务,标记事务的起始点
UPDATE account SET cash=cash-500 WHERE `name`='A';
UPDATE account SET cash=cash+500 WHERE `name`='B';
COMMIT; -- 提交事务
# rollback;
SET autocommit = 1; -- 恢复自动提交
1.5 トランザクション分離レベル (フォーカス)
分類:
- Read uncommitted (Read uncommitted) : ダーティリード/ノンリピータブルリード/ファントムリードが可能
- コミットされた読み取り (略して RC) : ダーティ読み取りは不可能ですが、反復不可能な読み取り/ファントム読み取りは可能です
- リピータブルリード(RRと呼ばれるリピータブルリード):ノンリピータブルリード/ダーティリード不可、ファントムリード可
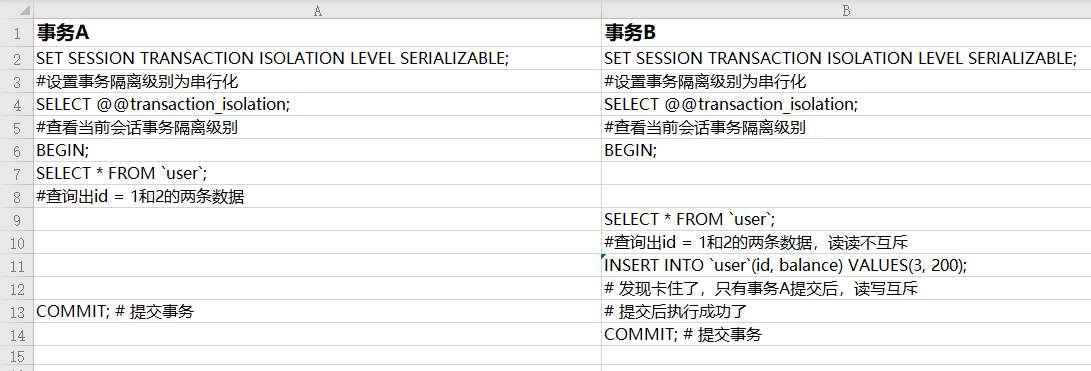
- Serializable : ダーティ リード、ノンリピータブル リード、ファントム リードは不可能です。MySQL のトランザクション分離レベルがシリアル化可能である場合、テーブルはロックされるため、ファントム リードは発生しません。この分離レベルでは同時実行性が非常に低く、開発ではめったに使用されません。
ダーティ リード: トランザクション A は、トランザクション B によって変更されたがまだコミットされていないデータを読み取り、このデータに基づいて動作します。このとき、トランザクション B がロールバックされると、A によって読み取られたデータは無効となり、整合性要件を満たしません。
Non-Repeatable Reads : トランザクションは、データを読み取った後、ある時点で以前に読み取ったデータを読み取りますが、読み取ったデータが変更されているか、一部のレコードが削除されていることがわかります。この現象は非反復読み取りと呼ばれ、トランザクション A はトランザクション B によって送信された変更されたデータを読み取りますが、分離性を満たしていません。
ファントム リード: トランザクションが同じクエリ条件に従って以前に取得したデータを再読み込みした後、他のトランザクションによってクエリ条件を満たす新しいデータが挿入されていたことが判明するこの現象は「ファントム リード」と呼ばれます。
トランザクション分離レベルの表示
- 「transaction_isolation」のような変数を表示します。
- @@transaction_isolation を選択します。
InnoDB ストレージ エンジンのデフォルトのトランザクション分離レベルは反復読み取り (反復読み取り) であり、MVCC + Next-Key Lock によりファントム読み取りの問題を解決できます。
1.6 トランザクション分離レベルのデモ
1.6.1 テストデータ
-- UNSIGNED代表无符号数,不能是负数
CREATE TABLE `user`
( `id` int(11) NOT NULL AUTO_INCREMENT,
name varchar(20) DEFAULT NULL,
balance decimal(10,2) unsigned DEFAULT NULL,
PRIMARY KEY (id))
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入数据
INSERT INTO `user` VALUES (1, '张三', 200), (2, '李四', 200);
1.6.2 コミットされていない読み取り、ダーティ読み取りが発生する
SQL実行処理: ダーティ リードは一貫性に違反するため、回避する必要があります。

1.6.3 コミットされた読み取り、ダーティ読み取りと反復不可能な読み取りを回避する
他のトランザクションによってコミットされたトランザクションのみを読み取ることができますが、同じ SQL ステートメントを介して複数の読み取りを行うと、異なるデータが読み取られる可能性があります。他のトランザクションが UPDATE および DELETE ステートメントを実行している可能性があり、反復不可能な読み取りはエラーではありません。これはビジネスで許可されるかどうか、ビジネスで決定する必要があります。Oracle データベースのデフォルトの分離レベルは読み取りコミットです。。

1.6.4 リピータブルリード、ダーティリード、ノンリピータブルリードを回避できますが、ファントムリードが発生する可能性があります
反復可能な読み取り SQL 実行プロセス:
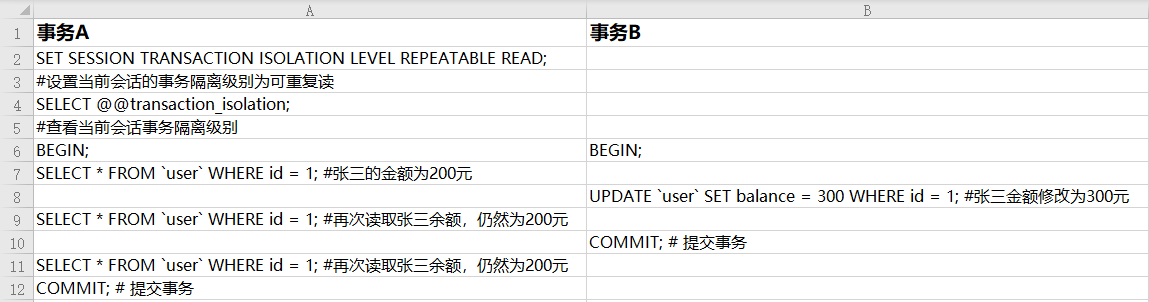
ファントム読み取り SQL 実行プロセスが発生します: MySQL のデフォルトのトランザクション分離レベルは反復読み取りです

1.6.5 ダーティ リード、反復不能リード、ファントム リードを回避するためのシリアル化 (開発ではほとんど使用されません、理解してください)
リレーショナル データの ACID と分散理論の CAP の違いは何ですか?
- ACID の C は一貫性であり、トランザクションでは、データに対して複数の操作を行った後でも、データは依然として正しく、突然増加したり、減少したり、消滅したりすることはありません。
- CAP の C も整合性です。これは主に、分散システムにおいて、複数のサービス間で 1 つのデータを同期する必要があることを意味します。データの同期には時間がかかり、データのレプリケーションが失敗する可能性があり、複数のサービス間のデータの整合性を確保する必要があります。一般的なものは、強い一貫性、弱い一貫性、および最終的な一貫性です。
- 両者は目的が異なるため、得られる効果も異なります。ACID は単一データの正確性と整合性をより重視しますが、CAP は複数のサービス間のデータの一貫性をより重視します。
2. 索引
2.1 インデックスの概要
- インデックスは本質的にはソートされたデータ構造であり、実際のものであり、物理ディスク ファイルに保存されます。
- MySQL がデータを迅速に取得し、ランダム IO をシーケンシャル IO に変換し、データ クエリを高速化できるようにします。
- 指定した列または複数の列に追加のデータ構造を追加すると、検索が高速になり、追加、変更、削除にかかる時間が短縮される可能性があります。
- 特別な指示がない場合、一般的に、インデックスは B ツリーまたは B+ ツリーを指します。
- これは本の先頭にある目次として理解でき、目次から対応するページ番号をすばやく見つけることができるため、検索プロセスが高速化されます。ディレクトリがない場合は、データを最初からたどって見つける必要があります。
2.2 インデックスの長所と短所
アドバンテージ:
- クエリ速度を大幅に向上させることができます。
- クエリ内のグループ化と並べ替えの時間を大幅に短縮できます ** (クエリ時間の短縮) **;
- テーブル間の接続を高速化できます。
- 一意のインデックスを作成すると、データの各行の一意性が保証されます。
欠点:
- インデックスを作成するときはテーブルをロックする必要がありますが、テーブルのロック中に他のデータ操作に影響を与える可能性があります。
- インデックスにはストレージ用のディスク領域が必要です。1 つのテーブルに対して多数のインデックスが作成されると、データ ファイルよりも早くサイズ制限に達する可能性があります。
- テーブル内のデータを追加、変更、または削除すると、インデックスのメンテナンスもトリガーされ、インデックスのメンテナンスに時間がかかるため、データ操作のパフォーマンスが低下し、実行時間が長くなる可能性があります。
2.3 インデックスの分類
**主キーインデックス:** を使用します主キーフィールドのインデックスは主キー インデックスで、その他は補助インデックス (1 つだけ) です。
**補助インデックス: **補助インデックスは非で始まります主キーフィールド生成されるインデックスは補助インデックスと呼ばれ、セカンダリ インデックス、セカンダリ インデックス (複数存在する場合もあります) とも呼ばれます。
**クラスター化インデックス: **Innodb ストレージ エンジンでのみサポートされており、主キー、空でない一意キー、またはデフォルトの row_id をインデックスとして使用します。
非クラスター化インデックス (非クラスター化インデックス):テーブルのストレージ エンジンがInnoDBの場合、主キー、非 null の一意キー、または row_id を除く他のフィールドは、インデックス列としての非クラスター化インデックスです。テーブルはMyISAMで、使用されるインデックスはすべて非クラスター化インデックスです。
**一意のインデックス (一意の制約の追加): **一意のインデックスを形成するために、一意の制約を使用して 1 つ以上のフィールドが追加されます。
フルテキスト インデックス: (あまり使用されません) MyISAM タイプのデータ テーブルにのみ使用でき、大規模なデータ セットに適した CHAR、VARCHAR、TEXT データ列タイプにのみ使用できます。
2.4 インデックスのガイドラインとデータ構造:
ガイドライン:
- インデックスはできるだけ多くありません。
- 頻繁に変更されるデータにインデックスを付けないでください。
- 少量のデータを含むテーブルにはインデックスを追加しないことをお勧めします。
- インデックスは通常、検索条件のフィールドに追加する必要があります。
**データ構造:**B ツリー インデックス (B ツリーおよび B+ ツリー)、ハッシュ インデックス、R インデックス (空間インデックス)、全文インデックス (転置インデックス、あまり使用されません)。
-- 不同的存储引擎支持的索引类型也不一样 InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引; NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引; Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
2.5 面接でよくある質問の索引付け
B ツリーと B+ ツリーの違いは何ですか? MySQL がインデックスの基礎となるデータ構造として B+ ツリーを使用するのはなぜですか?
MyISAM と InnoDB が B+ ツリー インデックスを使用する方法
クラスター化インデックスと非クラスター化インデックスの違いは何ですか