1.リカレントニューラルネットワークと自然言語処理の概要
目標
- 知token和tokenization
- Nグラムの概念と機能を知る
- テキストのベクトル化表現方法を知る
1.1 テキストのトークン化
1.1.1 概念とツールの概要
トークン化は一般に単語の分割と呼ばれ、各単語のトークンをトークンと呼びます。
次のような一般的な単語分割ツールが多数あります。
- Jieba 分詞: https://github.com/fxsjy/jieba。
- 清華大学の単語分割ツール THULAC:
https://github.com/thun1p/THULAC-Python
1.1.2 中国語と英語の単語分割方法

1.2 N-garmの発現方法
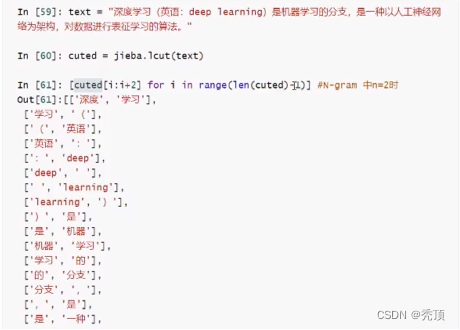
先ほど、文は 1 つの単語または複数の単語で表現できると述べましたが、場合によっては、2 つ、3 つ、またはそれ以上の単語を使用して N グラム単語のグループを表すこともできます。N は、一緒に使用される単語の数を意味します
。
例えば:

1.3 ベクトル化

1.3.1 ワンホットエンコーディング

1.3.2 単語の埋め込み
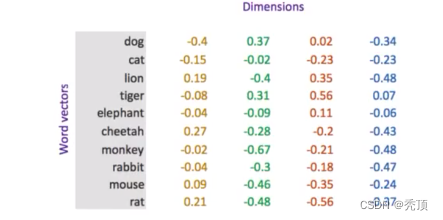
単語埋め込みは、深層学習でテキストを表現するために一般的に使用される方法です。ワンホット部分コードとは異なり、ワード埋め込みでは浮動小数点の密行列を使用してトークンを表します。辞書のサイズに応じて、ベクトルは通常、100、256、300 などの異なる次元を使用します。方向の各値はハイパーパラメータであり、その初期値はランダムに生成され、トレーニング プロセス中に学習されます。
テキストに 20,000 の単語がある場合、ワンホット エンコーディングを使用すると、20,000 20,000 の行列が得られ、そのほとんどは 0 ですが、単語の埋め込みを使用して表現する場合、必要な次元は 20,000 のみです。 20000*300 の
画像の表現は次のとおりです。

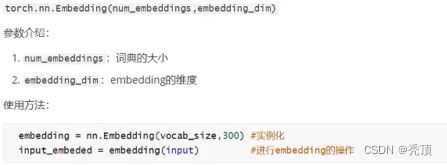
1.3.3 単語埋め込み API

1.3.4 データ形状の変更
思考: 各バッチの各文には 10 個の単語があります。形状 [20, 4] で単語を埋め込んだ後、元の文はどのような形状になりますか? 各単語は長さ 4 のベクトルで表されるため、最終的な文は [ になります
。 [batch_size,10,4] 形状。ディメンションを追加しました。このディメンションには dim が埋め込まれています
2. テキストの感情分類
目標
- テキスト処理の基本的な方法を理解する
- データを使用して感情分類を実現する機能
2.1 事例紹介

2.2 思考分析
まず、上記の問題は分類問題として定義でき、感情スコアを1~10の10カテゴリーに分けます(回帰問題としても理解できますので、ここでは分類問題とします)。以前の経験に基づいて、私たちの一般的なプロセスは次のとおりです。
- データセットの準備
- モデルを構築する
- 水平トレーニング
- モデルの評価
アイデアを理解したら、上記の手順を段階的に実行してみましょう
2.3 データセットの準備

2.3.1 基本データセットの準備


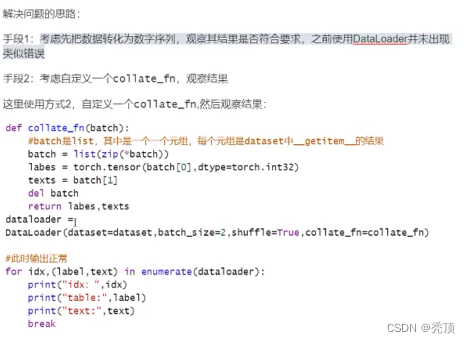
2.3.2 テキストのシリアル化
単語の埋め込みを再度導入したときに、テキストは直接ベクトルに変換されるのではなく、最初に数値に変換され、次にベクトルに変換されると言いましたが、このプロセスをどのように実現するか? ここでは、各単語のテキストとその単語を考慮することができ
ます。対応する数値が辞書に格納され、辞書を通じて文を数値を含むリストにマッピングするメソッドが実装されます。
テキストのシリアル化を実装する前に、次の点を考慮してください。
- 辞書を使って単語を数字にマッピングする方法
- 異なる言語の出現数は同じではない、高頻度単語または低頻度単語をフィルタリングする必要があるかどうか、および単語の総数を制限する必要があるかどうか
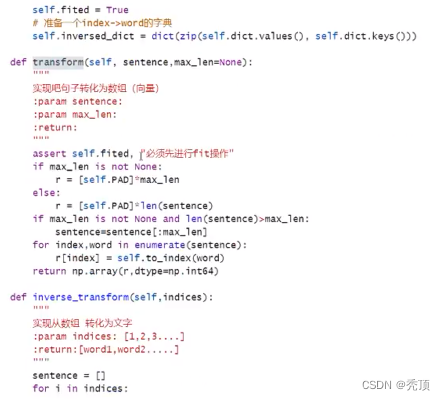
- 辞書を入手したら、文章を数字の列に変換する方法と、数字の列を文章に変換する方法
- サブの長さが異なると、各バッチの文を同じ長さに構築する方法 (短い文は特殊文字で埋めることができます)
- 新しい単語が辞書に載っていない場合の対処法 (特殊文字を代用として使用できます)
アイデア分析: - すべての文に参加する
- 単語を辞書に登録し、回数に応じて単語をフィルタリングし、回数をカウントします
- 文字から数字へのシーケンスを実現する方法
- デジタルシーケンスをテキストに変換するメソッドを実装する





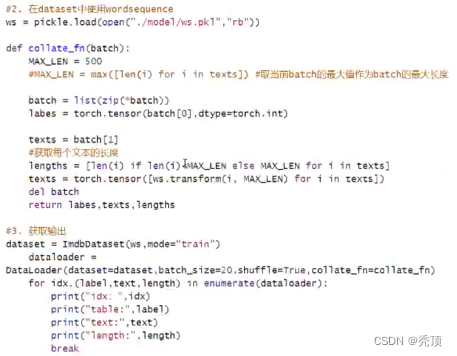

2.4 モデルの構築

2.5 モデルのトレーニングと評価


3.リカレントニューラルネットワーク
目標
- ノットループニューラルネットワークの概念と機能を説明できる
- リカレントニューラルネットワークの種類と応用シナリオを理解できる
- LSTMの機能と原理を説明できる
- GRUの機能と原理を説明できる
3.1 リカレント ニューラル ネットワークの概要
ニューラル ネットワークがあるのに、リカレント ニューラル ネットワークが必要なのはなぜですか?
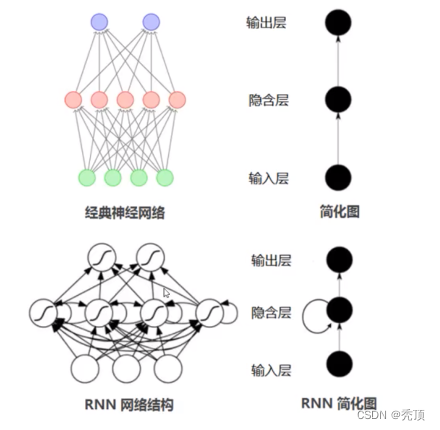
通常のニューラル ネットワークでは、情報の送信は一方向です。この制限により、ネットワークの学習が容易になりますが、ニューラル ネットワーク モデルがある程度弱くなることもあります。程度、能力。特に現実世界の多くのタスクでは、ネットワークの出力は現時点の入力に関連するだけでなく、過去のある期間の出力にも関連します。また、通常のネットワークでは映像、音声、テキストなどの時系列データを処理することが困難です。時系列データの長さは一般に固定ではありませんが、フィードフォワードニューラルネットワークでは入出力の次元が一定である必要があります。したがって、この種のタイミング関連の問題に対処する場合は、より有能なワイアット タイプが必要になります。
リカレント ニューラル ネットワーク (RNN) は、短期記憶機能を備えたニューラル ネットワークの一種です。リカレントニューラルネットワークでは、ニューロンは他のニューロンから情報を受け取るだけでなく、自分自身からも情報を受け取ることができ、ループ状のネットワーク構造を形成します。言い換えれば、ニューロンの出力は、次のタイム ステップでそれ自体に (入力として) 直接作用することができます。
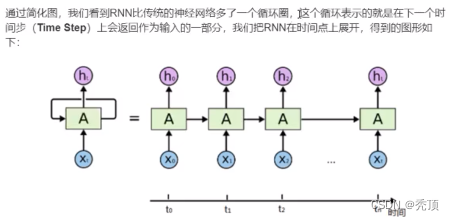
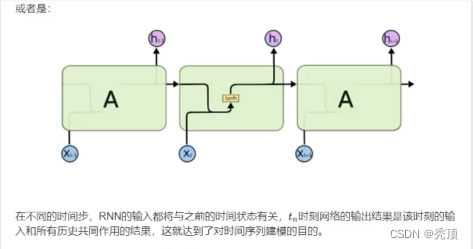
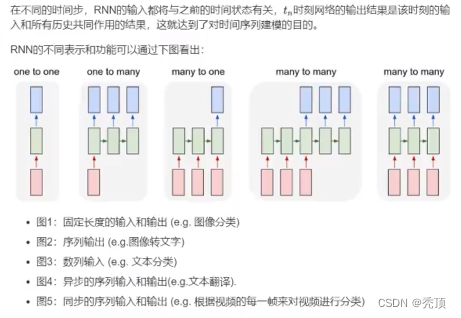
3.2 LSTM と GRU
3.2.1 LSTM の基本的な紹介
今そのような必要がある場合は、既存のテキストを掘り出して次の単語を予測します。たとえば、空に浮かぶ雲など、遠くない位置を尋ねることでその単語が空であると予測できますが、他のいくつかの文については、最初の 100 単語よりも前に単語を予測する必要がある場合があります。この時点では間隔が非常に大きいため、間隔が増加するにつれて、結果に対する実際の予測値の影響が非常に小さくなり、予測できなくなる可能性があります。 (RNN における長期依存関係の問題 (長期依存関係)) 次に、
この問題を解決するために、LSTM (Long Short-Term Memory network)
LSTM は長期依存関係情報を学習できる特別なタイプの RNN です。多くの問題に関して、LSTM は大きな成功を収め、広く使用されています。
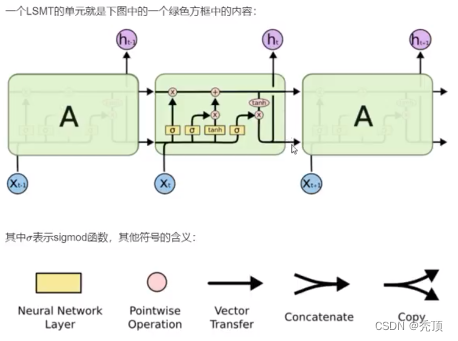
3.2.2 LSTM のコア
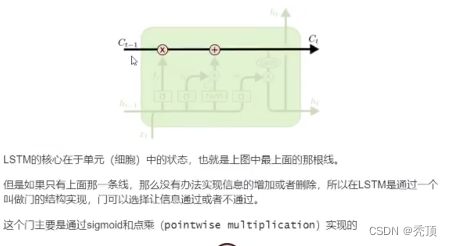
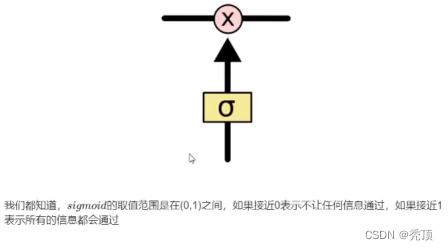
3.2.3 LSTM を徐々に理解する
3.2.3.1 忘れゲート
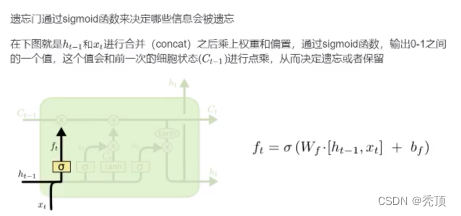
3.2.3.2 入力ゲート
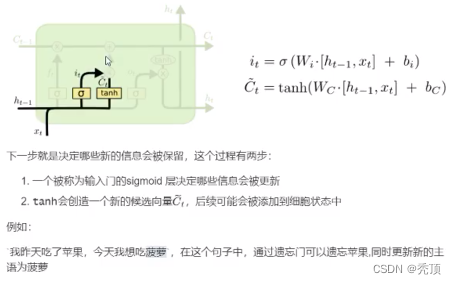
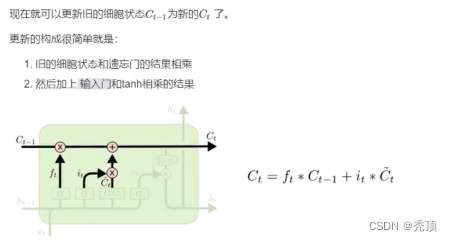
3.2.3.3 出力ゲート

3.2.4 GRU、LSTM の変形
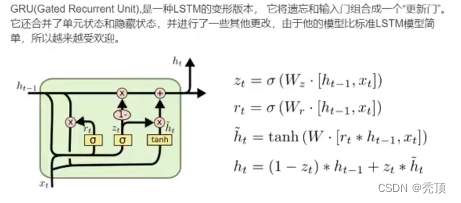
LSTM コンテンツ参照アドレス: https://colah.github.ioposts/2015-08-Understanding:LSTMs/
3.3 双方向LSTM
一方向 RNN は、前の情報に基づいて次のことを推測しますが、前の単語だけを見るだけでは不十分な場合があり、予測する必要がある単語が次の内容に関連している場合もあるため、メカニズムが必要になります。このとき必要となるのは、モデルが前から後ろまで記憶できる人だけではなく、後ろから前まで記憶する必要があることです。現時点では、双方向 LSTM がこの問題の解決に役立ちます。
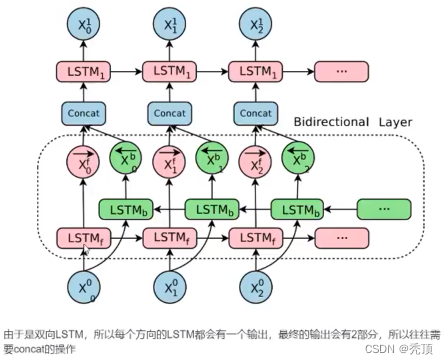
4.リカレントニューラルネットワークで感情分類を実現
目標
- LSTM と GRU の使用方法と入出力の形式を理解する
- LSTM と GRU を適用してテキスト感情分類を実現できます
4.1 Pytorch での LSTM および GRU モジュールの使用
4.1.1 LSTM の概要


4.1.2 LSTMの使用例
データマイニング入力が入力され、その形状が [10,20] であると仮定し、埋め込みの形状が [100,30] であると仮定します。
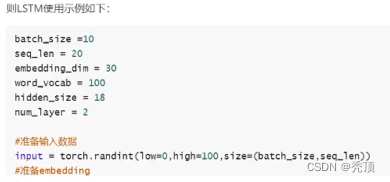
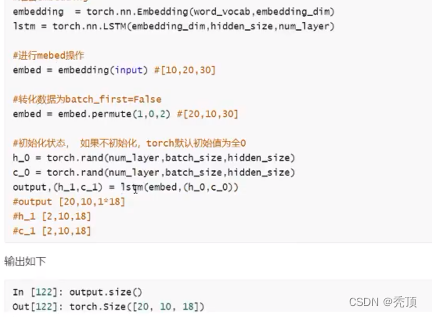

4.1.2 LSTM および GRU の使用に関する注意事項

4.2 LSTM を使用してテキスト感情分類を完了する
以前は単語埋め込みを使用しておもちゃレベルのテキスト感情分類を実装していました。そのため、現在は分類効果を観察するために LSTM レイヤーをこのモデルに追加しています。
より良い結果を達成するために、以前のモデルを次のように変更しました。
- MAX_LEN = 200
- データセットを構築するプロセスで、データは 2 カテゴリの問題に変換されます。pos は 1、neg は 0 です。そうでない場合、25,000 サンプルではデータを 10 のカテゴリに分割するのに十分ではありません。
- LSTM をインスタンス化するときに、dropout=0.5 を使用します。model.eval0 のプロセスで、dropout は自動的に 0 になります。
5. Pytorch のシリアル化コンテナ
目標
- 勾配消失と勾配爆発の原理と解決策を理解する
- nn.sequentia1 を使用してモデルの構築を完了できます
- nn.BatchNormld の使用方法を理解する
- nn.Dropout の使用方法を理解する
5.1 勾配の消失と勾配の爆発
pytorch でシリアル化されたコンテナーを使用する前に、勾配消失と勾配海の爆発の一般的な問題を見てみましょう
5.1.1 勾配の消失
4 つの層からなる最小限のニューラル ネットワークがあるとします。各層にはニューロンが 1 つだけあります。
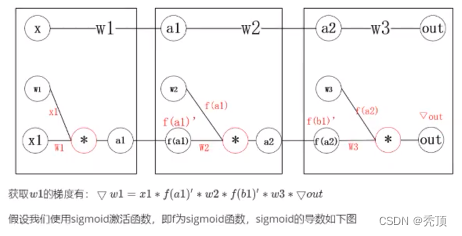
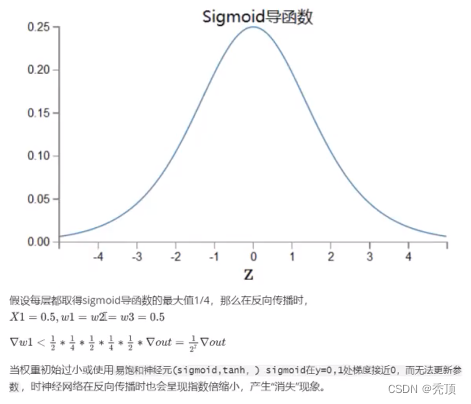
5.1.2 勾配爆発

5.1.3 勾配消失または勾配爆発を解決した経験

5.2nn.シーケンシャル
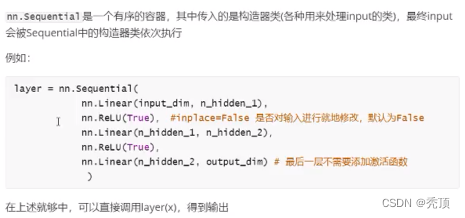

5.3 nn.BatchNormld
バッチ正規化は中国語ではバッチ正規化として翻訳されます。つまり、各バッチトレーニングのプロセスでパラメータが正規化され、トレーニング速度を高速化する効果が得られます。
シグモイド活性化関数を例にとると、逆送信の過程では、値が 0、1 の場合、勾配が 0 に近くなり、パラメータの更新が少なくなり、学習速度が遅くなります。しかし、データを正規化すると、データが[0-1]の範囲にできるだけ引き下げられるため、パラメータの更新範囲が広くなり、学習速度が向上します。
通常、batchNorm はアクティベーション関数の後に配置されます。つまり、入力は、batchNorm に入る前にアクティベートされます。

5.4 nn.ドロップアウト
