目次
5. 高い同時実行性のためのベスト プラクティス ソリューション
1. 高い同時実行性
1.1. 定義
高い同時実行性とは、同時に多数のリクエストを処理できるシステムの能力を指します。ソフトウェア開発では、高い同時実行性に対処するために、通常、システム アーキテクチャの設計、コードの最適化、キャッシュ戦略などを最適化する必要があります。
1.2. 用語
高い同時実行性に関連して一般的に使用される指標には、応答時間 (Response Time)、スループット(Throughput)、1 秒あたりのクエリ レート QPS (Query Per Second)、および同時ユーザー数が含まれます。
応答時間:システムがリクエストに応答するまでにかかる時間。たとえば、システムが HTTP リクエストを処理するのに 200 ミリ秒かかり、この 200 ミリ秒がシステムの応答時間になります。
スループット:単位時間当たりに処理されるリクエストの数。TPS と QPS はスループットの一般的な定量的指標です
QPS : 1 秒あたりの応答リクエストの数。サーバーが 1 秒間に応答できるクエリの数を指しますが、インターネットの分野では、この指標とスループットの区別はそれほど明確ではありません。QPS は単なる単純なクエリ統計です。システムの全体的なパフォーマンスを説明するために QPS を使用することはお勧めできません。
TPS: 1 秒あたりのトランザクション数。トランザクションとは、クライアントがサーバーにリクエストを送信し、サーバーが応答するプロセスを指します。
トランザクションの例として単一のインターフェイスの定義を取ると、各トランザクションには次の 3 つのプロセスが含まれます。
- (1) サーバーにリクエストを送信する
- (2) サーバ自身の内部処理(アプリケーションサーバ、データベースサーバ等を含む)
- (3) サーバーは結果をクライアントに返す
1 秒間に 3 つのプロセスを N 回以上完了できる場合、TPS は N になります。
同時ユーザー数:通常のシステム機能を同時に実行しているユーザーの数。この値は、マシン内の 1 秒以内のアクセス ログの数を分析することで取得できます。
QPS と TPS の違い:
(1) クエリ インターフェイスでのプレッシャー テストであり、このインターフェイスが内部で他のインターフェイスを要求しない場合は、TPS = QPS、それ以外の場合は、TPS ≠ QPS
(2) キャパシティ シナリオの場合、N 個のインターフェイスがすべてクエリ インターフェイスであり、このインターフェイスが内部的に他のインターフェイスを要求しないと仮定すると、QPS = N * TPS
2. 同時実行性の高いシステム設計の目標は何ですか
2.1. マクロ目標
① 高いパフォーマンス:パフォーマンスはシステムの並列処理能力を反映しており、限られたハードウェア投資でパフォーマンスを向上させることはコストの削減を意味します。
② 高可用性:システムが正常に稼働できる時間を示します。1 つは年間を通じてノンストップでトラブルフリーですが、もう 1 つはオンライン事故やダウンタイムが時折発生するため、ユーザーは前者を選択する必要があります。また、システムが90%しか利用できない場合は、ビジネスの足を大きく引っ張ることになります。
③高い拡張性:システムの拡張能力を示し、トラフィックのピーク時に拡張が短期間で完了でき、ダブル 11 イベントや有名人の離婚などの注目のイベントなどのピークトラフィックをよりスムーズに処理できるかどうかを示します。
2.2. マイクロ目標
パフォーマンス指標:パフォーマンス指標は、既存のパフォーマンスの問題を測定し、パフォーマンス最適化の評価基準として機能するために使用できます。一般的に、一定期間内のインターフェースの応答時間が指標として使用されます。
①平均応答時間:最も一般的に使用されますが、欠陥は明らかであり、遅いリクエストには敏感ではありません。たとえば、リクエストが 10,000 件あり、そのうち 9900 件が 1 ミリ秒、100 件が 100 ミリ秒である場合、平均応答時間は 1.99 ミリ秒です。平均消費時間は 0.99 ミリ秒しか増加しませんが、1% のリクエストの応答時間は 1 秒増加しています。 100回。
②TP90、TP99などのパーセンタイル値:応答時間を小さい順に並べ替え、TP90は90番目のパーセンタイルでの応答時間を表し、パーセンタイル値が大きいほど、遅いリクエストに対する感度が高くなります。
③スループット:応答時間に反比例し、例えば応答時間が1msの場合、1秒間に1000回のスループットとなります。
可用性指数:高可用性とは、システムが障害なく動作する高い能力を備えていることを意味します。可用性 = 平均障害時間 / 総システム実行時間
スケーラビリティ指標: バースト トラフィックに直面すると、一時的にアーキテクチャを変更することは不可能であり、マシンを追加してシステムの処理能力を直線的に増加させるのが最も早い方法です。。
したがって、サービス クラスター、データベース、キャッシュやメッセージ キューなどのミドルウェア、負荷分散、帯域幅、依存するサードパーティなど、高いスケーラビリティを考慮する必要があります。同時実行性が特定のレベルに達すると、上記の各要素がスケーラブルになる可能性があります。ボトルネックポイント。
3. 同時実行性の高いソリューションの進化
システムの同時実行性を向上させるネットワーク分散アーキテクチャ設計には、垂直 (垂直) 拡張 (スケール アップ) と水平(水平)拡張 (スケール アウト)の 2 つの主な方法があります。
水平(水平)拡張:サーバーの数を増やし、システムのパフォーマンスを直線的に拡張します。システムアーキテクチャ設計には水平展開が必要
垂直(垂直)拡張:サーバーの処理能力、メモリ、ストレージ容量などのハードウェアリソースを増やすことで、システムのパフォーマンスと容量を向上させます。
3.1. 初期の同時実行ソリューション
垂直方向の拡張: 単一マシンの処理能力を向上させます。
垂直方向に拡張するには 2 つの方法があります。
(1) スタンドアロン ハードウェアのパフォーマンスの向上: CPU コア数 (32 コアなど) の増加、ネットワーク カードの 10 ギガビットへのアップグレード、機械式ハードディスクのソリッド ステートへのアップグレード、ハードディスク容量 (2T など) の拡張、および拡張システムメモリ、CPU が 32 ビットから 64 ビットにアップグレード、無償で Tomcat を商用 Weblogic を使用、Linux カーネルの最適化、高性能サーバーの購入など。
(2) スタンドアロン アーキテクチャのパフォーマンスの向上:キャッシュを使用して IO 時間を短縮し、非同期を使用して単一サービスのスループットを向上させ、ロックフリーのデータ構造を使用して応答時間を短縮します。
ビジネスの継続的な増加に伴い、サーバーのパフォーマンスがすぐにボトルネックに達しました
3.2. アプリケーションレベルのソリューション
1) 静的な Web ページ HTML (CMS プロジェクトのサポートが必要)
2) 画像サーバー分離(共通ソリューション)
3) キャッシュ (一般的なソリューション) 最良のポリシーは分散キャッシュです。
4) ミラーイメージ (さらにダウンロード)
スタンドアロンのパフォーマンスには常に限界があるため、最終的には水平(水平)拡張を導入する必要があります
3.3. 究極のソリューション - 分散型
既存ネットワークの各コア部分の業務量、アクセス量、データフローの急速な増大により、それに伴い処理能力や計算量も増大し、1台のサーバー装置では耐えられなくなってきています。この場合、既存の設備を廃棄してハードウェアのアップグレードを大量に行うと、既存のリソースの無駄が発生し、次の業務量の増加に直面した場合、ハードウェアのアップグレードに再び高額なコストがかかることになります。コスト投入により、たとえ優れた性能を備えた設備であっても、現在のビジネス成長のニーズを満たすことができなくなります。
この問題を解決するために、分散システムアーキテクチャを採用し、クラスタ展開により同時処理能力をさらに向上させ、異なるサーバ装置を接続して業務量の拡大に共同で取り組むことができます。同時に、負荷分散を使用してさまざまなサーバー間の負荷を分散し、システム全体のパフォーマンスと信頼性を向上させることもできます。
クラウド コンピューティング テクノロジを使用して、クラウド プラットフォーム上にサービスを展開し、実際のビジネス量の変化に応じてコンピューティング リソースを動的に拡張することもできるため、ビジネスの成長の課題により適切に対応できます。
4. システムアーキテクチャ
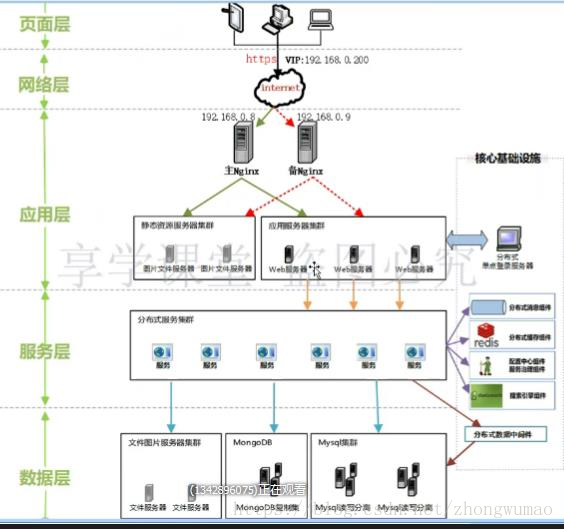
図に示すように、システムのコア層は、ページ層、ネットワーク層、アプリケーション層、サービス層、永続層に単純に分割されます。
負荷分散層が高性能 Nginx を使用している場合、Nginx の最大同時実行数は 10W+ と見積もることができ、ここでの単位は 10,000 です。
Tomcat をアプリケーション層で使用すると仮定します。Tomcat の最大同時実行数は約 800 と推定でき、ここでの単位は数百です。
永続層のキャッシュが Redis を使用し、データベースが MySQL を使用すると仮定すると、MySQL の最大同時実行数は、数千単位で約 1000 と見積もることができます。Redis の最大同時実行数は、数万単位で約 5W と推定できます。
したがって、負荷分散層、アプリケーション層、永続化層の同時実行性は異なります。では、システム全体の同時実行性とキャッシュを向上させるには、通常どのようなソリューションを採用できるでしょうか?
(1) システム拡張
システム拡張には垂直拡張と水平拡張があり、機器やマシン構成を追加するため、ほとんどのシナリオで効果的です。
(2) キャッシュ
ネットワーク IO を削減し、メモリに基づいてデータを読み取るローカル キャッシュまたは集中キャッシュ。ほとんどのシナリオで機能します。
(3) 読み出しと書き込みの分離
読み取りと書き込みの分離、分割統治を使用し、マシンの並列処理能力を向上させます。
4.1. 解決策
実際のビジネスと組み合わせることで、高い同時実行性に対処するために、対応するビジネス戦略によって補完され、垂直方向と水平方向から安定した信頼性の高いシステムを設計できます。
クライアントからデータベース層へのユーザーリクエストを層ごとに減らします。
4.1.1. ページレイヤー
- 軽いロジックと重いロジックの分離: seckill を例として、取得をアカウントから分離します。
- グラッピングは比較的軽い操作であり、在庫控除が成功すると、成功する可能性があります。
- アカウンティングは比較的重い操作であり、トランザクション操作を必要とします。
- ユーザーの誘導: 1 時間ごとのフラッシュ セール イベントを例に挙げると、1 分以内にユーザーの入り口を次々に開き、60 秒以内にすべてのユーザー リクエストを分割すると、リクエストを一桁減らすことができます。同様に、12306チケット、ダブル イレブン フラッシュ セールを購入して、瞬間的なフローをより長い期間にスムーズに分配します。これがいわゆるピーク クリッピングです。
- ページの簡素化:フラッシュセールが開始されると、ページ表示を簡素化する必要があり、現時点ではフラッシュセールに関連する機能のみが予約されています。たとえば、seckill が開始されると、ページに推奨製品が表示されない場合があります。
- ユーザーリクエストのレートを制限することで、ピーク時のアクセストラフィックが全体の時間帯にスムーズに分散され、サーバーへの負荷が軽減され、サービスの品質が向上します。
- 再試行戦略:ユーザーのスパイクが失敗した場合、頻繁に再試行するとバックエンドの雪崩が悪化します。再試行するにはどうすればよいですか? バックエンドの戻りコードの規則に従って、次の 2 つの方法があります。
- エラーの再試行は許可されていません。現時点では、UI とコピーの両方にプロンプトが必要です。再試行も許可しない
- 再試行可能なエラーには、バイナリ バックオフなどの戦略的な再試行が必要です。同時に、コピーライティングやuiにもヒントが必要です。
- UI とコピーライティング: seckill の開始前後で、すべてのユーザー例外に対して、適切に設計された UI とコピーライティング プロンプトが必要です。例: [現在のイベントは人気がありすぎるため、後でもう一度お試しください] [商品が路上でスタックしているため、後で確認してください] など。
- フロントエンドのランダムなリクエストの破棄は、ダウングレード ソリューションとして使用できます。ユーザー トラフィックがシステムの容量を大幅に超える場合、ランダムな破棄フラグが手動で発行され、ユーザーのローカル クライアントはリクエストのランダムな破棄を開始します。
4.1.2.ネットワーク層、アプリケーション層
- すべてのリクエストは法的身元を確認するために認証される必要があります
- 長いリンク サービスの場合、認証の粒度はセッション レベルにすることができますが、短いリンク サービスの場合は、キャッシュなどの大量の同時トラフィックを処理する必要があります。
- バックエンドシステムの容量に応じて、グローバル電流制限機能が必要となり、通常、次の 2 つの方法があります。
- N を設定した後、マシン配備ステータス M を動的に取得し、単一マシン電流制限値 N/M を発行します。均一なアクセスを要求し、均一にマシンを展開する必要があります。
- グローバル キーを管理し、タイムスタンプ付きのキーを作成します。ホット キーの問題がある場合は、より詳細なキーを追加するか、キーを定期的に更新できます。
- 周波数制御は、主にハッカーや悪意のあるユーザーを防ぐために、単一ユーザー/単一 IP に必要です。たとえば、seckill が条件付きの場合、資格のロックを解除するには xxx タスクを完了する必要があり、資格を取得するステップとしてセキュリティ スキャンを実行して黒人ユーザーや悪意のあるユーザーを特定できます。
4.1.3. サービス層
- ロジック層はまず、パラメータの有効性、パラメータが適格であるかどうかなどの検証ロジックに入る必要があります。ユーザーが失敗した場合は、リクエストがデータベースに突き抜けないようにすぐに戻ります。
- 非同期注文補充。すでに Lightning Deal 資格を差し引いているユーザの場合、配信が失敗した場合、通常は次の 2 つの方法があります。
- トランザクションのロールバック、この動作のロールバック、ユーザーに再試行を求めるプロンプト。このコストは特に高く、ユーザーの再試行が以前の再試行戦略と組み合わされると、ユーザー エクスペリエンスはスムーズではなくなります。
- 非同期やり直し。今回はユーザーのログを記録し、ユーザーに [配達中なので後で確認してください] とプロンプトを表示し、ピーク値の後にバックグラウンドで非同期注文補充を開始します。冪等性をサポートするサービスが必要
- 出荷された在庫については、ホットキーを処理する必要があります。通常は複数のキーを維持し、各ユーザーは特定のクエリ インベントリにアクセスします。大勢の人が赤い封筒を手に取るシーンでは、事前に赤い封筒を割り当てることができます。
4.1.4.ストレージ層DB
ビジネス モデルの場合、db の要件では次のいくつかの原則を確保する必要があります。
- 信頼性
- アクティブ/スタンバイ: アクティブ/スタンバイは相互に切り替えることができ、通常は同じ都市内のコンピューター室をまたぐ必要があります。
- 別の場所でのディザスタリカバリ:ある場所で異常が発生した場合、データをリストアし、別の場所でマスターを選択することができます
- データはディスクまたはより冷却されたデバイスに保存する必要がある
- 一貫性
- seckill の場合、厳密な一貫性が必要であり、通常、マスターとバックアップは厳密に一貫性がある必要があります。
5. 高い同時実行性のためのベスト プラクティス ソリューション
5.1. 高性能の実践スキーム1
クラスター展開:負荷分散を通じて単一マシンの負荷を軽減します。
CDN、ローカル キャッシュ、分散キャッシュなどを使用した静的データを含むマルチレベル キャッシュ、およびホットスポット キーの処理、キャッシュ ペネトレーション、キャッシュの同時実行性、キャッシュ シナリオでのデータの一貫性。
サブデータベースのサブテーブルとインデックスを最適化し、検索エンジンを利用して複雑なクエリの問題を解決します。HBase、TiDB などの NoSQL データベースの使用を検討しますが、チームはこれらのコンポーネントに精通しており、強力な運用および保守能力を備えている必要があります。
マルチスレッド、MQ、さらには遅延タスクによる二次プロセスや時間のかかる操作の非同期処理。
非同期処理: メインスレッドのブロックを回避し、システムの同時実行性を向上させるために、電子メールの送信、レポートの生成など、時間のかかる一部の操作を非同期で処理します。
電流制限については、フロントエンドの電流制限、Nginx アクセス レイヤーの電流制限、サーバー側の電流制限など、ビジネスで電流制限が許可されているかどうか (たとえば、seckill シナリオが許可されているかどうか) を検討する必要があります。トラフィックはピークシェービングとバレーフィルが行われ、MQ を通じて受け入れられます。
マルチスレッドによるシリアル ロジックの並列処理による同時処理。
赤い封筒を掴むシーンなどの事前計算では、赤い封筒の量を事前に計算してキャッシュし、赤い封筒を送るときに直接使用できます。
キャッシュの予熱、非同期タスクを通じて事前にデータをローカル キャッシュまたは分散キャッシュに予熱します。
データベースやキャッシュのバッチ読み取りおよび書き込み、RPC バッチ インターフェイスのサポート、または冗長データによる RPC 呼び出しの強制終了などの IO の数を削減します。
IO 中のパケット サイズを削減します。これには、軽量通信プロトコル、適切なデータ構造の使用、インターフェイス内の冗長フィールドの削除、キャッシュ キーのサイズの削減、キャッシュ値の圧縮などが含まれます。
実行フローを高確率でブロックする判定ロジックを前に追加したり、For ループの計算ロジックを最適化したり、より効率的なアルゴリズムを採用したりするなど、プログラムロジックの最適化。
HTTP リクエスト プール、スレッド プール (CPU 集中型または IO 集中型を考慮してコア パラメータを設定)、データベースおよび Redis 接続プールなどを含む、さまざまなプーリング テクノロジとプール サイズ設定の使用。
GC の頻度と消費時間を可能な限り削減するための、新世代と旧世代のサイズ、GC アルゴリズムの選択などのJVM の最適化。
ロックの選択については、読み取りが多く書き込みが少ないシナリオでオプティミスティック ロックを使用するか、セグメント化されたロックを通じてロックの競合を減らすことを検討してください。
5.2. 高可用性実践計画 2
ピアノードのフェイルオーバー。Nginxとサービス ガバナンス フレームワークの両方が、ノードに障害が発生した後の別のノードへのアクセスをサポートします。
ハートビート検出とマスター/スタンバイ切り替え (Redis Sentinel モードまたはクラスター モード、MySQL マスター/スレーブ切り替えなど) の実装による、非ピア ノードのフェイルオーバー。
インターフェイス レベルでのタイムアウト設定、再試行戦略、冪等設計。
縮退処理:コア サービスを保証し、非コア サービスを犠牲にし、必要に応じて融合します。コア リンクに問題がある場合は、代替リンクが存在します。
電流制限処理:システムの処理能力を超えるリクエストを直接拒否またはエラーコードを返します。MQ シナリオでのメッセージの信頼性保証。プロデューサー側の再試行メカニズム、ブローカー側の永続性、コンシューマー側の Ack メカニズムが含まれます。
グレースケール リリースでは、マシンの寸法に基づいて小規模なトラフィックの展開をサポートし、システム ログとビジネス インジケーターを観察し、動作が安定した後にフル ボリュームをプッシュできます。
監視と警報: CPU、メモリ、ディスク、ネットワークの最も基本的な監視に加え、Web サーバー、JVM、データベース、さまざまなミドルウェア、ビジネス指標の監視を含む包括的な監視システム。
災害復旧訓練:現在の「カオス エンジニアリング」と同様に、システムに対していくつかの破壊的措置を実行し、ローカルな障害がユーザビリティの問題を引き起こすかどうかを観察します。
5.3. 拡張性の高い実践ソリューション 3
合理的な階層化アーキテクチャ:たとえば、上記のインターネットの最も一般的な階層化アーキテクチャに加えて、データ アクセス層とビジネス ロジック層に従ってマイクロサービスをさらに階層化できます (ただし、パフォーマンスの評価が必要です。ネットワークには、もう 1 ホップの場合)。
ストレージ レイヤーの分割:ビジネス ディメンションに従って垂直分割し、データ機能ディメンション (サブデータベースとサブテーブル) に従ってさらに水平分割します。
ビジネス レイヤーの分割:最も一般的な分割は、ビジネス ディメンション (電子商取引シナリオにおける商品サービスや注文サービスなど) に基づくか、コア インターフェイスと非コア インターフェイスに応じて分割するか、リクエスト ソース (たとえば、 To C および To B、APP および H5)。分散トレース、フルリンク ストレス テスト、および柔軟なトランザクションはすべて考慮すべき技術的なポイントです
参考
https://mp.weixin.qq.com/s/uex9zkf2uPeTp56cfv4dHA
https://mp.weixin.qq.com/s/fDn4iHWuBEfzvNnVrWud2w
https://www.cnblogs.com/hanease/p/15863393.html
https:/ /www.cnblogs.com/sy270321/p/12503504.html
https://zhuanlan.zhihu.com/p/109742840?from_voters_page=true&utm_id=0
https://juejin.cn/post/6865202367672320014