記事ディレクトリ
序文
- この記事はダークホースから学び、同時に著者の実践を組み合わせています。
- この記事の一部の写真は、原理とプロセスをよりわかりやすく示すために動画形式で表示されています。
- 内容の一部の説明では、ダークホースの例の図と実践記録の図を組み合わせているため、ホスト IP が完全に一致しないという問題が発生します。読者の皆様はご理解ください。
スタンドアロン Redis の問題
-
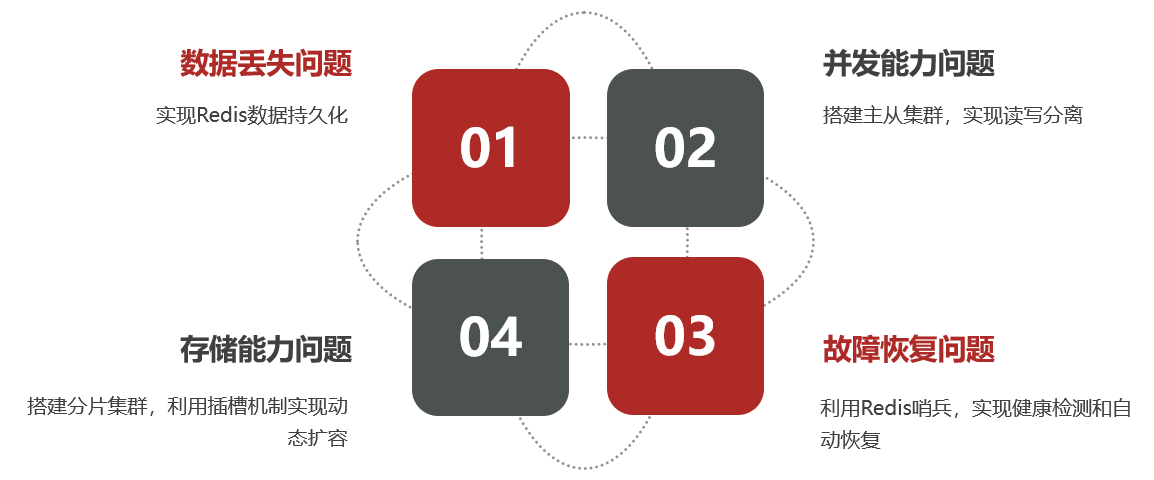
スタンドアロン Redis には 4 つの大きな問題があります。




-
解決:
2 つの Redis のインストール
- Redis 学習の概要 [2] の第 4 セクションの内容を参照してください。
3 つの Redis 永続性
Redis には 2 つの永続化スキームがあります。
- RDBの永続性
- AOF の永続性
3.1 RDB の永続化
- RDB の正式名は Redis データベース バックアップ ファイル (Redis データ バックアップ ファイル) で、Redis データ スナップショットとも呼ばれます。簡単に言えば、メモリ内のすべてのデータはディスクに記録されます。Redis インスタンスに障害が発生して再起動したら、ディスクからスナップショット ファイルを読み取り、データを復元します。スナップショット ファイルは RDB ファイルと呼ばれ、デフォルトでは現在の実行ディレクトリに保存されます。
- RDB の永続化は、次の 4 つの状況で実行されます。
- 保存コマンドを実行する
- bgsaveコマンドを実行する
- Redis がダウンしている場合
- RDB条件がトリガーされたとき
3.1.1 トリガー条件
- save コマンド
RDB をすぐに実行するには、次のコマンドを実行します。
 save コマンドにより、メイン プロセスが RDB を実行し、このプロセス中は他のすべてのコマンドがブロックされます。データ移行中にのみ使用できます。
save コマンドにより、メイン プロセスが RDB を実行し、このプロセス中は他のすべてのコマンドがブロックされます。データ移行中にのみ使用できます。
- bgsave コマンドは、

コマンドの実行後に独立したプロセスを開始して RDB を完成させます。メイン プロセスは影響を受けることなくユーザー リクエストの処理を続行できます。
- Redis がダウンすると
、RDB の永続性を実現するために保存コマンドが実行されます。
- トリガーRDB条件
- Redis には RDB をトリガーするメカニズムがあり、これは redis.conf ファイルにあり、形式は次のとおりです。
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB save 900 1 save 300 10 save 60 10000- RDB の他の構成も redis.conf ファイルで設定できます。
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱 rdbcompression yes # RDB文件名称 dbfilename dump.rdb # 文件保存的路径目录 dir ./
3.1.2 RDBの原理
- bgsave の開始時に、メイン プロセスが子プロセスを取得するためにフォークされ、子プロセスはメイン プロセスのメモリ データを共有します。フォークが完了すると、メモリ データが読み取られ、RDB ファイルに書き込まれます。
- fork はコピーオンライト技術を使用します。
- メインプロセスが読み取り操作を実行するとき、共有メモリにアクセスします。
- メインプロセスが書き込み操作を実行すると、データのコピーがコピーされて書き込み操作が実行されます。

3.1.3 概要
- RDB モードでの bgsave の基本プロセス:
- メインプロセスをフォークして子プロセス、共有メモリ空間を取得します。
- 子プロセスはメモリ データを読み取り、新しい RDB ファイルに書き込みます。
- 古い RDB ファイルを新しい RDB ファイルに置き換えます
- RDBのデメリット
- RDB の実行間隔が長く、2 回の RDB 書き込みの間にデータが失われるリスクがあります。
- 子プロセスをフォークし、圧縮し、RDB ファイルを書き出すには時間がかかります
3.2 AOF の永続性
3.2.1 AOFの原理
- AOF の正式名称は Append Only File (追加ファイル) です。Redis によって処理されるすべての書き込みコマンドは AOF ファイルに記録され、コマンド ログ ファイルとみなすことができます。

3.2.2 AOF 構成
-
AOF はデフォルトで無効になっています。AOF を有効にするには、redis.conf 構成ファイルを変更する必要があります。
# 是否开启AOF功能,默认是no appendonly yes # AOF文件的名称 appendfilename "appendonly.aof" -
AOF コマンド記録の頻度は、redis.conf ファイルを通じて構成することもできます。
# 表示每执行一次写命令,立即记录到AOF文件 appendfsync always # 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案 appendfsync everysec # 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘 appendfsync no -
3 つの戦略の比較:
| 構成アイテム | ブラッシングのタイミング | アドバンテージ | 欠点がある |
|---|---|---|---|
| いつも | 同期ブラシディスク | 信頼性が高く、データがほとんどない | パフォーマンスへの影響 |
| 毎秒 | ブラシ/秒 | 中程度のパフォーマンス | 最大 1 秒間のデータ損失 |
| いいえ | オペレーティングシステムの制御 | 最高のパフォーマンス | 信頼性が低く、大量のデータが失われる可能性がある |
3.2.3 AOFファイルの書き換え
- 記録コマンドであるため、AOF ファイルは RDB ファイルよりもはるかに大きくなります。また、AOF は同じキーに対する複数の書き込み操作を記録しますが、意味があるのは最後の書き込み操作だけです。bgrewriteaof コマンドを実行すると、AOF ファイルを書き換えて、最小限のコマンドで同じ効果を得ることができます。

- Redis は、しきい値がトリガーされると、AOF ファイルを自動的に書き換えます。しきい値は redis.conf で構成することもできます。
# AOF文件比上次文件 增长超过多少百分比则触发重写 auto-aof-rewrite-percentage 100 # AOF文件体积最小多大以上才触发重写 auto-aof-rewrite-min-size 64mb
3.3 RDBとAOFの比較
- RDBとAOFはそれぞれ一長一短ありますが、データのセキュリティ要件が高い場合には実際の開発では組み合わせて使用されることが多いです。
| RDB | AOF | |
|---|---|---|
| 持続性 | メモリ全体のスナップショットを定期的に取得します。 | 実行されたすべてのコマンドをログに記録します |
| データの整合性 | 不完全、バックアップ間で失われた | ブラッシング方法にもよりますが、比較的完成度が高い |
| ファイルサイズ | 圧縮が行われるため、ファイルサイズは小さくなります | コマンドを記録すると、ファイル サイズが非常に大きくなります |
| マシンの回復速度 | すぐ | 遅い |
| データ復旧の優先順位 | データの整合性が AOF ほど良くないため、低い | データの整合性が高いため高 |
| システムリソースの使用量 | CPU とメモリの消費量が多くて重い | 少ない、主にディスク IO リソースですが、AOF は再書き込み時に多くの CPU リソースとメモリ リソースを消費します。 |
| 使用するシーン | 数分間のデータ損失にも耐え、起動速度の高速化を追求 | より高度なデータセキュリティ要件が一般的です |
4 つの Redis マスター/スレーブ クラスター
4.1 マスター/スレーブ アーキテクチャの構築
- シングルノード Redis の同時実行能力には上限があり、Redis の同時実行能力をさらに向上させるには、マスター/スレーブ クラスターを構築して読み取りと書き込みの分離を実現する必要があります。

4.2 マスター/スレーブクラスターの構築
4.2.1 クラスター構造
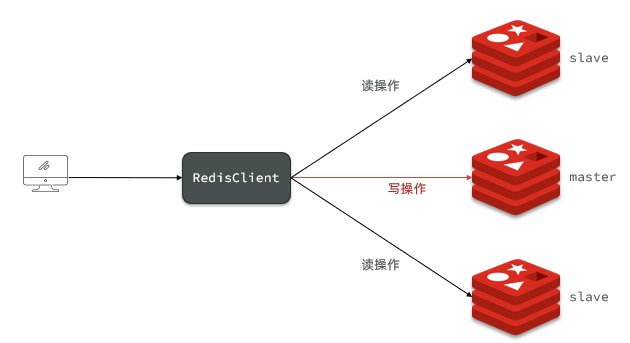
- 1 つのマスター ノードと 2 つのスレーブ ノードの合計 3 つのノードが含まれます
- 同じ仮想マシン内で 3 つの Redis インスタンスを開き、マスター/スレーブ クラスターをシミュレートします。情報は次のとおりです [IP は自分の仮想マシンの IP です]:
| IP | ポート | 役割 |
|---|---|---|
| 192.168.188.112 | 7001 | マスター |
| 192.168.188.112 | 7002 | 奴隷 |
| 192.168.188.112 | 7003 | 奴隷 |
4.2.2 インスタンスと構成の準備
- 同じ仮想マシン上で 3 つのインスタンスを起動するには、3 つの異なる設定ファイルとディレクトリを用意する必要があり、設定ファイルが配置されているディレクトリは作業ディレクトリでもあります。
- 「cluster」という名前のフォルダーを作成し、そのディレクトリーの下に 3 つのサブフォルダー 7001、7002、および 7003 を作成します。
# 进入/tmp目录 cd /tmp # 创建目录 mkdir cluster mkdir 7001 7002 7003 - 元の構成を復元する
- redis-7.0.8/redis.conf ファイルを変更し、永続モードをデフォルトの RDB モードに変更し、AOF をオフのままにします。
# 开启RDB# save ""save 3600 1 save 300 100 save 60 10000 # 关闭AOF appendonly no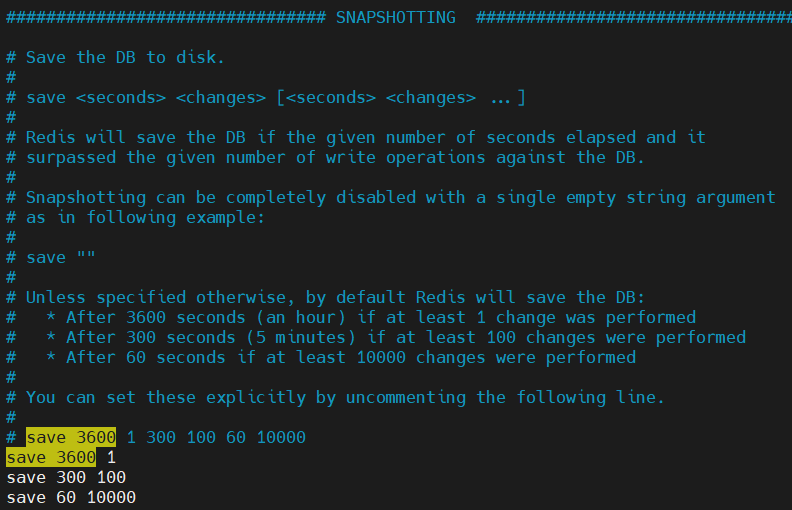
- 構成ファイルを各インスタンス ディレクトリにコピーする
- 次に、redis-7.0.8/redis.conf ファイルを 3 つのディレクトリ [7001、7002、7003] にコピーします。
- 各インスタンスのポートと作業ディレクトリを変更します。
- 各フォルダー内の設定ファイルを変更し、ポートをそれぞれ 7001、7002、7003 に変更し、rdb ファイルの保存場所を独自のディレクトリに変更します (/tmp/cluster ディレクトリで次のコマンドを実行します)
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf - 各インスタンスの宣言された IP を変更する
- 仮想マシン自体には複数の IP があります。/将来の混乱を避けるために、redis.conf ファイルで各インスタンスのバインド IP 情報を指定する必要があります。形式は次のとおりです。
# redis实例的声明 IP replica-announce-ip 192.168.xxx.xxx- 各ディレクトリを変更する必要がありますが、ワンクリックで変更を完了できます (/tmp/cluster ディレクトリで次のコマンドを実行します)。
# 逐一执行 sed -i '1a replica-announce-ip 192.168.xxx.xxx' 7001/redis.conf sed -i '1a replica-announce-ip 192.168.xxx.xxx' 7002/redis.conf sed -i '1a replica-announce-ip 192.168.xxx.xxx' 7003/redis.conf # 或者一键修改 printf '%s\n' 7001 7002 7003 | xargs -I{ } -t sed -i '1a replica-announce-ip 192.168.xxx.xxx' { }/redis.conf - 起動
#/tmp/cluster目录下 # 第1个 redis-server 7001/redis.conf # 第2个 redis-server 7002/redis.conf # 第3个 redis-server 7003/redis.conf - ストップ
printf '%s\n' 7001 7002 7003 | xargs -I{ } -t redis-cli -p { } shutdown
4.2.3 マスター/スレーブ関係を開く
- これで、3 つのインスタンスは互いに関係がなく、マスター/スレーブを構成するには、replicaof または smileof (5.0 より前) コマンドを使用できます。
- 一時モードと永続モードの 2 つのモードがあります。
- 構成ファイルを変更します(永続的)
- redis.conf に構成の行を追加します。
slaveof <masterip> <masterport> - redis-cli クライアントを使用して redis サービスに接続し、slaveof コマンドを実行します (再起動後に失敗します)。
slaveof <masterip> <masterport>
- redis.conf に構成の行を追加します。
- 注意:コマンドreplicaofは5.0以降に追加されており、salveofと同じ効果があります。
- デモ
- redis-cli コマンドを使用して 7002 に接続し、次のコマンドを実行します。
# 连接 7002 redis-cli -p 7002 # 执行slaveof slaveof 192.168.188.112 7001- redis-cli コマンドを使用して 7003 に接続し、次のコマンドを実行します。
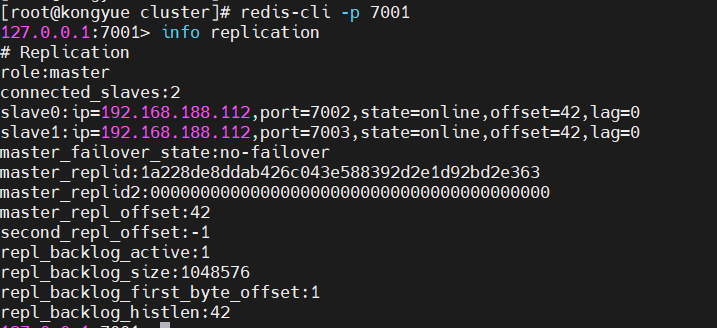
# 连接 7003 redis-cli -p 7003 # 执行slaveof slaveof 192.168.188.112 7001- 次に、ノード 7001 に接続してクラスターのステータスを表示します。
# 连接 7001 redis-cli -p 7001 # 查看状态 info replication
4.2.4 テスト
- マスターノード 7001 のみが書き込み操作を実行でき、2 つのスレーブノード 7002 および 7003 は読み取り操作のみを実行できます。
127.0.0.1:7001> set num 111 OK127.0.0.1:7002> set num 111 (error) READONLY You can't write against a read only replica.127.0.0.1:7003> set num 111 (error) READONLY You can't write against a read only replica.
4.3 マスターとスレーブのデータ同期原理
4.3.1 完全同期
マスターとスレーブが初めて接続を確立すると、完全な同期が実行され、マスター ノードのすべてのデータがスレーブ ノードにコピーされます。プロセス:

マスターは、スレーブが初めて接続していることをどのようにして認識しますか? 判断の基礎として使用できる重要な概念がいくつかあります。
- レプリケーション ID : Replid の略で、データ セットのマークであり、同じ ID は同じデータ セットであることを意味します。各マスターには固有の応答があり、スレーブはマスター ノードの応答を継承します。
- offset : repl_baklog に記録されるデータが増加するにつれて徐々に増加するオフセット。スレーブは同期を完了すると、現在の同期オフセットも記録します。スレーブのオフセットがマスターのオフセットより小さい場合、スレーブ データがマスターより遅れているため、更新する必要があることを意味します。
したがって、データ同期の場合、マスターがどのデータを同期する必要があるかを判断できるように、スレーブは独自のレプリケーション ID とマスターへのオフセットを宣言する必要があります。
- スレーブは元々独自のリプライとオフセットを持つマスターであるため、初めてスレーブとなってマスターと接続を確立する際、送信されるリプライとオフセットは自身のリプライとオフセットになります。マスターは、スレーブから送信された replid が自身の replid と矛盾していると判断し、これが新しいスレーブであることを示し、完全な同期を行う必要があることを認識します。マスターは応答とオフセットをスレーブに送信し、スレーブは情報を保存します。将来的には、スレーブのレプリッドはマスターのレプリッドと同じになります。
- したがって、マスターがノードが初めて同期されたかどうかを判断する基準は、Replid が一貫しているかどうかを確認することです。

完全なプロセスの説明:
-
スレーブノードは増分同期を要求します
-
マスターノードはReplidを判断し、不整合を発見し、増分同期を拒否します
-
マスターは完全なメモリデータを含む RDB を生成し、RDB をスレーブに送信します
-
スレーブはローカルデータをクリアし、マスターのRDBをロードします。
-
マスターは、RDB 期間中のコマンドを repl_baklog に記録し、ログ内のコマンドを継続的にスレーブに送信します。
-
スレーブは受信したコマンドを実行し、マスターとの同期を維持します。
4.3.2 増分同期
- 完全同期では、最初に RDB を作成し、次にネットワーク経由で RDB ファイルをスレーブに転送する必要がありますが、これにはコストがかかりすぎます。したがって、最初の完全同期を除いて、スレーブとマスターはほとんどの場合、増分同期を実行します。
- 増分同期: スレーブとマスター間で異なる一部のデータのみを更新します。

4.3.3 repl_backlog の原則
マスターはスレーブとそれ自体のデータの違いをどのようにして知るのでしょうか?
- これは完全同期中の repl_baklog ファイルに関するものです。このファイルは固定サイズの配列ですが、配列は循環的です。つまり、添え字が配列の末尾に達すると、再び 0 から読み取りと書き込みが開始されます。そのため、先頭のデータは配列は上書きされます。Repl_baklog は、マスターの現在のオフセットとスレーブがコピーしたオフセットを含む、Redis によって処理されたコマンド ログとオフセットを記録します。

- スレーブとマスターのオフセットの差は、スレーブが増分コピーする必要があるデータです。データの書き込みが続くと、マスターのオフセットが徐々に増加し、スレーブはマスターのオフセットに追いつくためにコピーを続けます。

- 配列がいっぱいになるまで:

-
この時点で、新しいデータが書き込まれると、配列内の古いデータは上書きされます。ただし、古いデータが緑色である限り、データはスレーブに同期されているため、上書きされても影響はありません。赤い部分だけが同期していないからです。
-
スレーブにネットワークが輻輳している場合、マスターのオフセットはスレーブのオフセットをはるかに超えます。

- マスターが新しいデータの書き込みを続けると、スレーブの現在のオフセットも上書きされるまで、そのオフセットが古いデータを上書きします。

- 茶色のボックス内の赤い部分は、同期されていないが上書きされたデータです。このとき、スレーブが回復した場合は同期する必要がありますが、オフセットがなくなっていることがわかり、増分同期を完了できません。完全同期のみ可能です。
4.4 マスタ/スレーブ同期の最適化
マスターとスレーブの同期により、マスターとスレーブのデータの一貫性が確保されますが、これは非常に重要です。Redis マスター/スレーブ クラスターは、次の側面から最適化できます。
-
マスターで repl-diskless-sync yes を構成してディスクレス レプリケーションを有効にし、完全同期中のディスク IO を回避します。
-
RDB による過剰なディスク IO を削減するには、Redis 単一ノードのメモリ使用量が大きすぎないようにする必要があります。
-
repl_baklog のサイズを適切に増やし、スレーブダウン時にできるだけ早く障害回復を実現し、完全同期を可能な限り回避します。
-
マスター上のスレーブ ノードの数を制限します。スレーブが多すぎる場合は、マスター-スレーブ-スレーブ チェーン構造を使用してマスターへの負担を軽減できます。
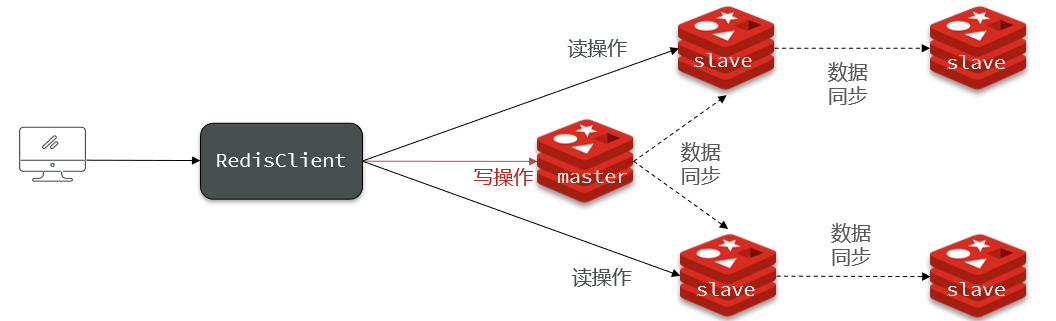
- マスター/スレーブのアーキテクチャ図:
4.5 概要
- 完全同期と増分同期の違いを簡単に説明してください。
- 完全同期: マスターは完全なメモリ データを含む RDB を生成し、その RDB をスレーブに送信します。後続のコマンドは repl_baklog に記録され、1 つずつスレーブに送信されます。
- インクリメンタル同期: スレーブは独自のオフセットをマスターに送信し、マスターは repl_baklog 内のオフセットの後のコマンドをスレーブに取得します。
- 完全同期をいつ実行するか?
- スレーブノードが初めてマスターノードに接続するとき
- スレーブ ノードが長時間切断されていたため、repl_baklog 内のオフセットが上書きされました
- 増分同期はいつ実行されますか?
- スレーブ ノードが切断されて復元され、オフセットが repl_baklog で見つかる場合
5 つの Redis センチネル
スレーブ ノードがダウンタイムから回復すると、マスター ノードを見つけてデータを同期できます。マスター ノードのダウンタイムはどうなりますか?
- Redis は、マスター/スレーブ クラスターの自動障害回復を実現するための Sentinel メカニズムを提供します。
5.1 センチネルの原則
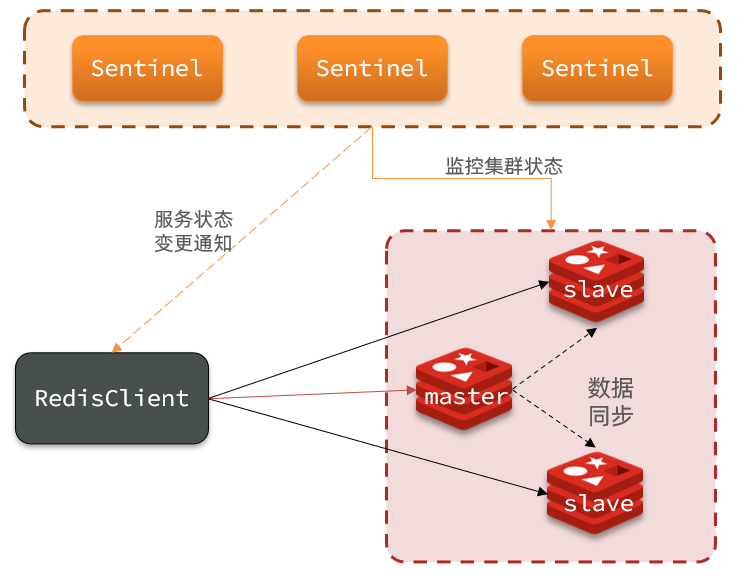
5.1.1 クラスターの構造と機能
- Sentinel の構造を次の図に示します。

監視員の役割は次のとおりです。
- モニタリング: Sentinel は、マスターとスレーブが期待どおりに動作していることを常にチェックします。
- 自動障害回復: マスターに障害が発生した場合、Sentinel はスレーブをマスターに昇格させます。障害のあるインスタンスが回復すると、新しいマスターがメインになります。
- 通知: Sentinel は Redis クライアントのサービス検出ソースとして機能し、クラスターがフェールオーバーすると、最新の情報を Redis クライアントにプッシュします。
5.1.2 クラスター監視の原則
Sentinel はハートビート メカニズムに基づいてサービス ステータスを監視し、クラスターの各インスタンスに ping コマンドを 1 秒ごとに送信します。
-
主観的オフライン: センチネル ノードは、指定された時間内にインスタンスが応答しないことを検出した場合、そのインスタンスは主観的にオフラインであるとみなします。
-
客観的オフライン: 指定された数 (クォーラム) を超えるセンチネルがインスタンスが主観的にオフラインであると考える場合、インスタンスは客観的にオフラインになります。クォーラム値は、Sentinel インスタンスの数の半分より大きいことが望ましいです。

5.1.3 クラスタ障害回復の原則
マスター障害が見つかったら、センチネルはスレーブの 1 つを新しいマスターとして選択する必要があります。選択基準は次のとおりです。
- まず、スレーブノードとマスターノード間の切断時間を判定し、規定値(ダウンアフターミリ秒 * 10)を超えた場合、スレーブノードを除外します。
- 次に、スレーブノードのスレーブ優先度の値を判断し、優先度が小さいほど優先度が高く、0 の場合は選挙に参加しません。
- スレーブ優先度が同じ場合、スレーブノードのオフセット値を判定し、値が大きいほどデータが新しく、優先度が高くなります。
- 最後はスレーブノードの実行IDのサイズを判断し、優先度が小さいほど優先度が高くなります。
新しいマスターが選択された場合、切り替えプロセスは次のようになります。
- Sentinel は、slaveof no one コマンドを候補のスレーブ 1 ノードに送信して、ノードをマスターにします
- Sentinel は、slaveof 192.168.188.112 7002 コマンドを他のすべてのスレーブに送信して、これらのスレーブを新しいマスターのスレーブ ノードにし、新しいマスターからのデータの同期を開始します。
- 最後に、センチネルは障害が発生したノードをスレーブとしてマークし、障害が発生したノードが回復すると、自動的に新しいマスターのスレーブ ノードになります。

5.1.4 概要
Sentinel の 3 つの機能とは何ですか?
- モニター
- フェイルオーバー
- 通知する
Sentinel は Redis インスタンスが正常かどうかをどのように判断しますか?
- 1秒ごとにpingコマンドを送信し、一定時間通信がない場合は主観的オフラインとみなされます
- ほとんどの監視員が主観的にインスタンスがオフラインであると考える場合、サービスはオフラインであると判断されます
フェイルオーバーの手順は何ですか?
- まず新しいマスターとしてスレーブを選択し、誰のスレーブも実行しないでください
- 次に、すべてのノードが新しいマスターのスレーブを実行できるようにします。
- 障害のあるノード構成を変更し、新しいマスターのスレーブを追加します
5.2 センチネルクラスターの構築
- 以前の Redis マスター/スレーブ クラスターを監視するために、3 つのノードで形成される Sentinel クラスターを構築します。図に示すように:
- 3 つのセンチネル インスタンスの情報は次のとおりです。
| ノード | IP | ポート |
|---|---|---|
| s1 | 192.168.188.112 | 27001 |
| s2 | 192.168.188.112 | 27002 |
| s3 | 192.168.188.112 | 27003 |
- インスタンスと構成を準備する
- 同じ仮想マシン上で 3 つのインスタンスを起動するには、3 つの異なる設定ファイルとディレクトリを用意する必要があり、設定ファイルが配置されているディレクトリは作業ディレクトリでもあります。
- 親フォルダーに
cluster-sentinel3 つのフォルダーを作成し、それぞれに名前を付けますs1、s2、s3。
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir cluster-sentinel
cd cluster-sentinel
mkdir s1 s2 s3
- 次に、s1 ディレクトリに Sentinel.conf ファイルを作成し、次の内容を追加します。
port 27001
sentinel announce-ip 192.168.188.112
sentinel monitor mymaster 192.168.188.112 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/cluster-sentinel/s1"
- 解釈:
port 27001: は現在のセンチネル インスタンスのポートですsentinel monitor mymaster 192.168.188.112 7001 2: マスターノード情報を指定しますmymaster: マスターノード名、ユーザー定義、任意の書き込み192.168.188.112 7001: マスターノードのIPとポート2: mast:er を選択するときのクォーラム値
- 次に、s1/sentinel.conf ファイルを s2 および s3 ディレクトリにコピーします (cluster-sentinel ディレクトリで実行)。
# 方式一:逐个拷贝 cp s1/sentinel.conf s2 cp s1/sentinel.conf s3 # 方式二:管道组合命令,一键拷贝 echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf - 2 つのフォルダー s2 と s3 内の構成ファイルを変更し、ポートをそれぞれ 27002 と 27003 に変更します。
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
- 起動
- ログを簡単に表示するために、3 つの SSH ウィンドウを開き、それぞれ 3 つの Redis インスタンスを起動して、コマンドを開始します。
# 第1个 redis-sentinel s1/sentinel.conf # 第2个 redis-sentinel s2/sentinel.conf # 第3个 redis-sentinel s3/sentinel.conf
-
Sentinel クラスターのフェイルオーバー テスト [参考のみ]
redis-cli -p 7001 shutdown
-
マスター ノード 7001 をシャットダウンしてみて、センチネル ログを確認してください。
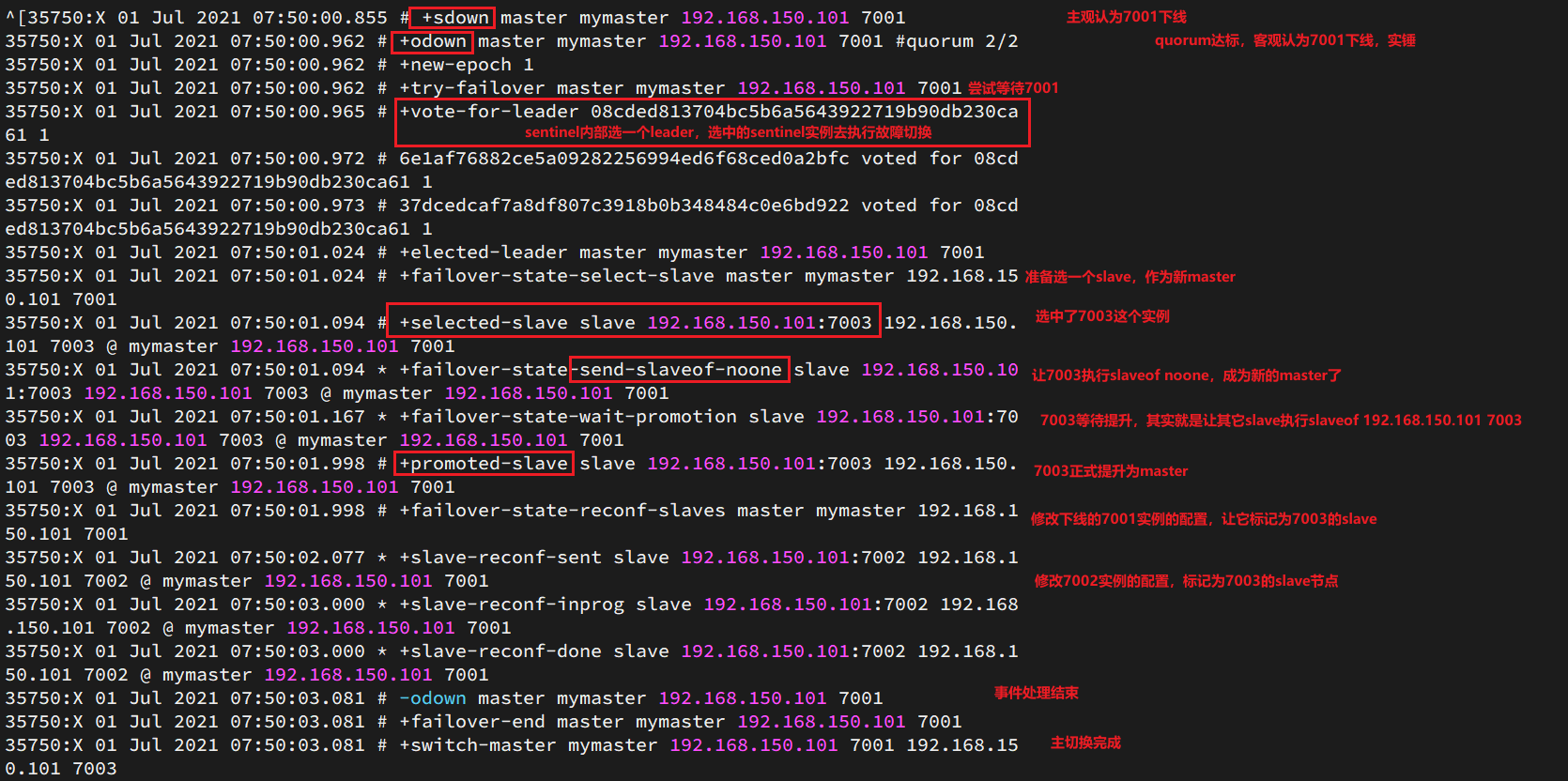
-
練習の結果:

-
クラスター構造を表示する
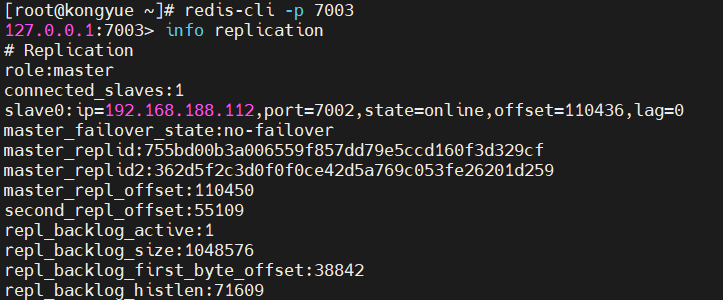
-
停止したノードを再起動します
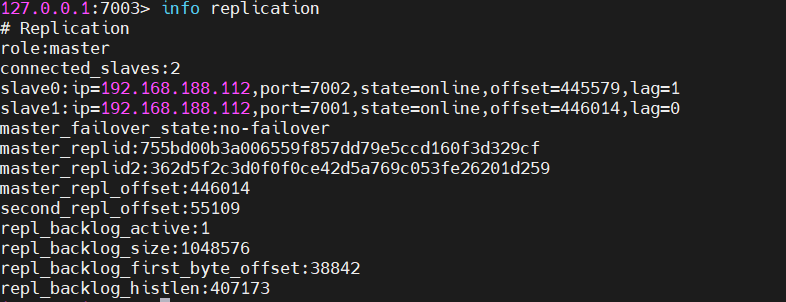
5.3 RedisTemplateのセンチネルモード
- Sentinel クラスターの監視下にある Redis マスター/スレーブ クラスターでは、自動フェイルオーバーによりノードが変更され、Redis クライアントはこの変更を認識し、適時に接続情報を更新する必要があります。Spring の RedisTemplate の基礎となる層は、レタスを使用してノードの認識と自動切り替えを実現します。
- プロジェクトの pom ファイルに依存関係を導入します。
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
- Redisアドレスを構成する
- Redis のセンチネル関連情報を構成ファイル application.yml に指定します。
spring: redis: sentinel: master: mymaster nodes: - 192.168.188.112:27001 - 192.168.188.112:27002 - 192.168.188.112:27003
- 読み取りと書き込みの分離を構成する
- プロジェクトのスタートアップ クラスに、新しい Bean を追加します。
@Bean public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){ return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED); }
Bean で設定されるのは、次の 4 つのタイプを含む読み取りおよび書き込み戦略です。
- MASTER: マスターノードから読み取ります
- MASTER_PREFERRED: 最初にマスター ノードから読み取り、マスターが使用できない場合はレプリカを読み取ります。
- REPLICA: スレーブ (レプリカ) ノードから読み取ります
- REPLICA _PREFERRED: 最初にスレーブ (レプリカ) ノードから読み取ります。すべてのスレーブはマスターを読み取ることができません
- テスト


6 つの Redis シャード クラスター
6.1 Redis 断片化クラスターの概要
マスター/スレーブとセントリーは、高可用性と高同時読み取りの問題を解決できます。しかし、まだ未解決の問題が 2 つあります。
-
大容量データストレージの問題
-
同時書き込みが多い場合の問題
上記の問題は、シャード クラスターを使用することで解決できます。シャード クラスターの特徴は次のとおりです。
-
クラスター内には複数のマスターがあり、各マスターは異なるデータを保存します
-
各マスターは複数のスレーブ ノードを持つことができます
-
マスターは ping を通じて互いの健康状態を監視します。
-
クライアント要求はクラスター内の任意のノードにアクセスでき、最終的には正しいノードに転送されます。

6.2 シャードクラスターの構築
- クラスター構造
- シャード クラスターには多数のノードが必要です。ここでは、3 つのマスター ノードを含む最小限のシャード クラスターを構築します。各マスターにはスレーブ ノードが含まれます。構造は次のとおりです: 同じ仮想マシンで 6 つの Redis インスタンスを起動し、断片化クラスターをシミュレートします
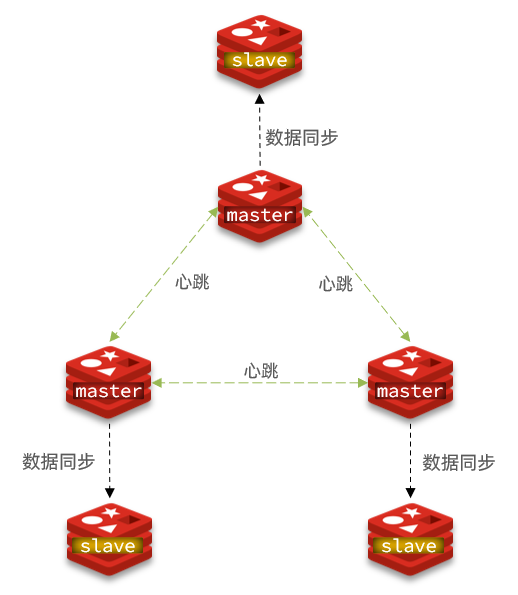
。 、情報は次のとおりです。
- シャード クラスターには多数のノードが必要です。ここでは、3 つのマスター ノードを含む最小限のシャード クラスターを構築します。各マスターにはスレーブ ノードが含まれます。構造は次のとおりです: 同じ仮想マシンで 6 つの Redis インスタンスを起動し、断片化クラスターをシミュレートします
| IP | ポート | 役割 |
|---|---|---|
| 192.168.188.112 | 7001 | マスター |
| 192.168.188.112 | 7002 | マスター |
| 192.168.188.112 | 7003 | マスター |
| 192.168.188.112 | 8001 | 奴隷 |
| 192.168.188.112 | 8002 | 奴隷 |
| 192.168.188.112 | 8003 | 奴隷 |
- インスタンスと構成を準備する
- ディレクトリを作成する
# 进入/tmp目录 cd /tmp # 创建目录\ mkdit cluster-sharding cd cluster-sharding mkdir 7001 7002 7003 8001 8002 8003- /tmp/cluster-sharding の下に次の内容の新しい redis.conf ファイルを準備します。
port 6379 # 开启集群功能 cluster-enabled yes # 集群的配置文件名称,不需要我们创建,由redis自己维护 cluster-config-file /tmp/cluster-sharding/6379/nodes.conf # 节点心跳失败的超时时间 cluster-node-timeout 5000 # 持久化文件存放目录 dir /tmp/cluster-sharding/6379 # 绑定地址 bind 0.0.0.0 # 让redis后台运行 daemonize yes # 注册的实例ip replica-announce-ip 192.168.188.112 # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 logfile /tmp/cluster-sharding/6379/run.log- このファイルを各ディレクトリにコピーします。
# 进入/tmp目录 cd /tmp/cluster-sharding # 执行拷贝 echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf- 各ディレクトリの redis.conf を変更し、ディレクトリと一致するように 6379 を変更します。
# 进入/tmp目录 cd /tmp # 修改配置文件 printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{ } -t sed -i 's/6379/{}/g' { }/redis.conf
-
起動
- バックグラウンド起動モードが構成されているため、サービスを直接起動できます。
# 进入/tmp目录 cd /tmp/cluster-sharding # 一键启动所有服务 printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{ } -t redis-server { }/redis.conf- PS 経由でステータスを表示します。
ps -ef | grep redis
- すべてのプロセスを閉じたい場合は、次のコマンドを実行できます。
またps -ef | grep redis | awk '{print $2}' | xargs killprintf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{ } -t redis-cli -p { } shutdown
- クラスターを作成する
- サービスは開始されていますが、現在は各サービスが連携せずに独立しています。コマンドを使用してクラスターを管理します。
redis-cli --cluster create --cluster-replicas 1 192.168.188.112:7001 192.168.188.112:7002 192.168.188.112:7003 192.168.188.112:8001 192.168.188.112:8002 192.168.188.112:8003- コマンドの説明:
redis-cli --clusterまたは./redis-trib.rb: クラスタ操作コマンドを表しますcreate: クラスターの作成を表します--replicas 1または--cluster-replicas 1: クラスター内の各マスターのコピー数が 1 であることを指定し、节点总数 ÷ (replicas + 1)この時点でマスターの数が取得されます。したがって、ノード リストの最初の n がマスターとなり、他のノードはすべてスレーブ ノードとなり、異なるマスターにランダムに割り当てられます。
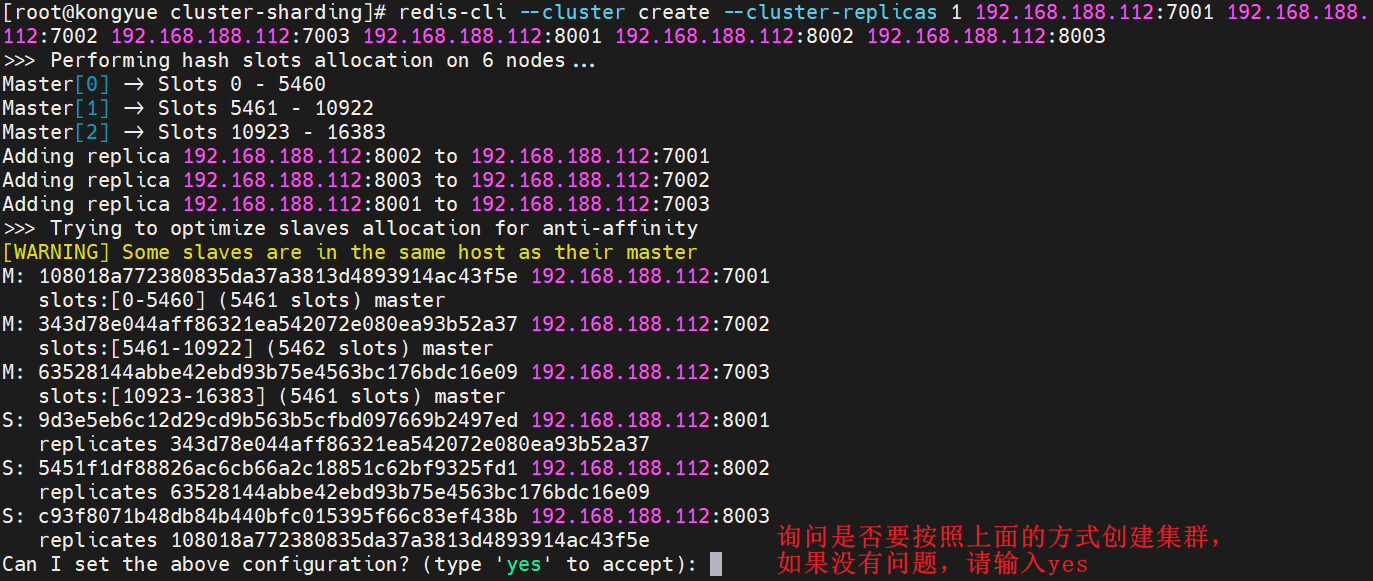
- 「yes」と入力すると、クラスターの作成が開始されます。
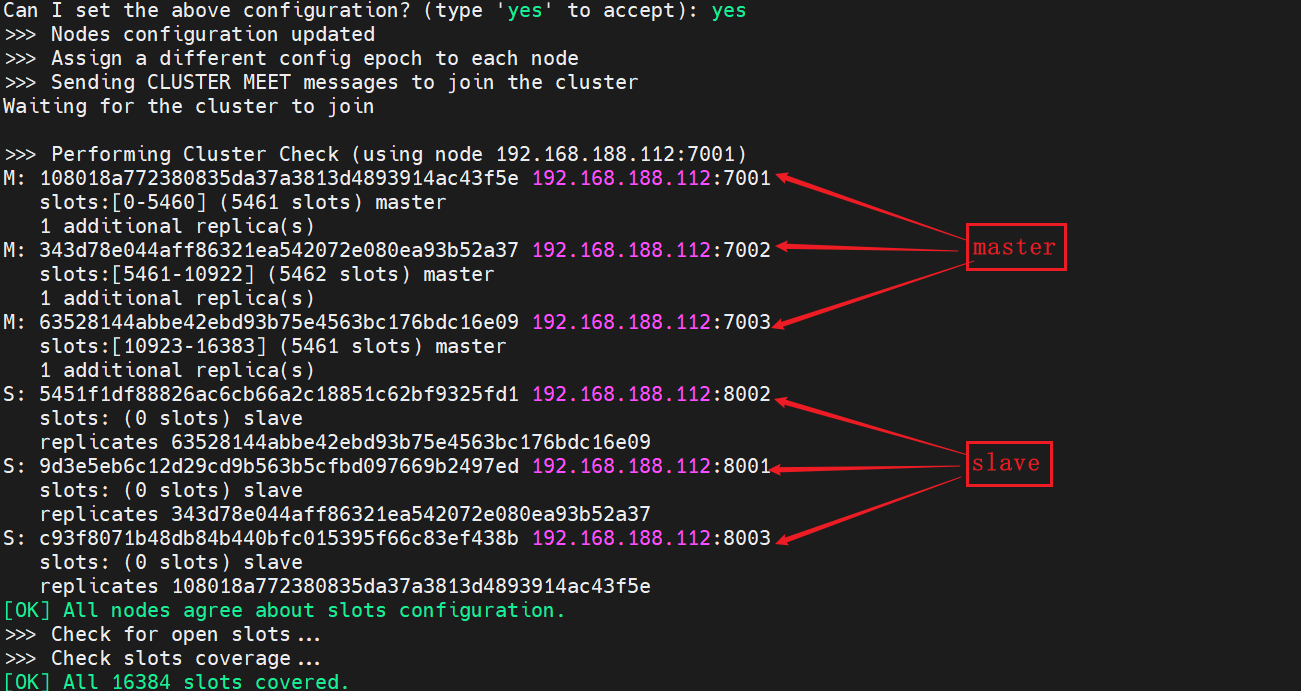
- 次のコマンドを使用してクラスターのステータスを表示できます。
redis-cli -p 7001 cluster nodes
- テスト
- クラスタ運用

redis-cli- クラスタリングする場合、パラメータを追加する必要があります-c: -c:クラスタ モードを有効にする (-ASK および -MOVED リダイレクトに従って) [クラスタ モードを有効にする (-ASK および -MOVED リダイレクトに従って)。】

6.3 ハッシュスロット
6.3.1 スロットの原理
- Redis は各マスター ノードを 0 ~ 16383 の範囲の合計 16384 スロット (ハッシュ スロット) にマップします。これはクラスター情報を表示すると確認できます。
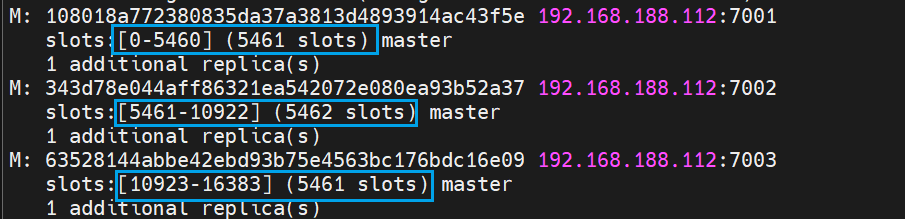
- データキーはノードにバインドされず、スロットにバインドされます。Redis は、次の 2 つの場合に、キーの有効部分に基づいてスロット値を計算します。
- キーに「{}」が含まれており、「{}」に少なくとも 1 文字が含まれており、「{}」内の部分が有効な部分です
- キーには「{}」が含まれていません。キー全体が有効な部分です
6.3.2 概要
- Redis はキーをどのインスタンスに配置するかをどのように決定しますか?
- 16384 スロットを異なるインスタンスに割り当てる
- キーの有効部分に従ってハッシュ値を計算し、16384 の余りを取得します
- 残りはスロットとして使用されます。スロットが配置されているインスタンスを見つけるだけです。
- 同じ種類のデータを同じ Redis インスタンスに保存するにはどうすればよいですか?
- このタイプのデータは同じ有効部分を使用します。たとえば、キーにはすべて {typeId} という接頭辞が付けられます。
6.4 クラスターのスケーリング
- redis-cli --cluster は、クラスターを操作するための多くのコマンドを提供します。これらのコマンドは、次の方法で表示できます。
redis-cli --cluster help
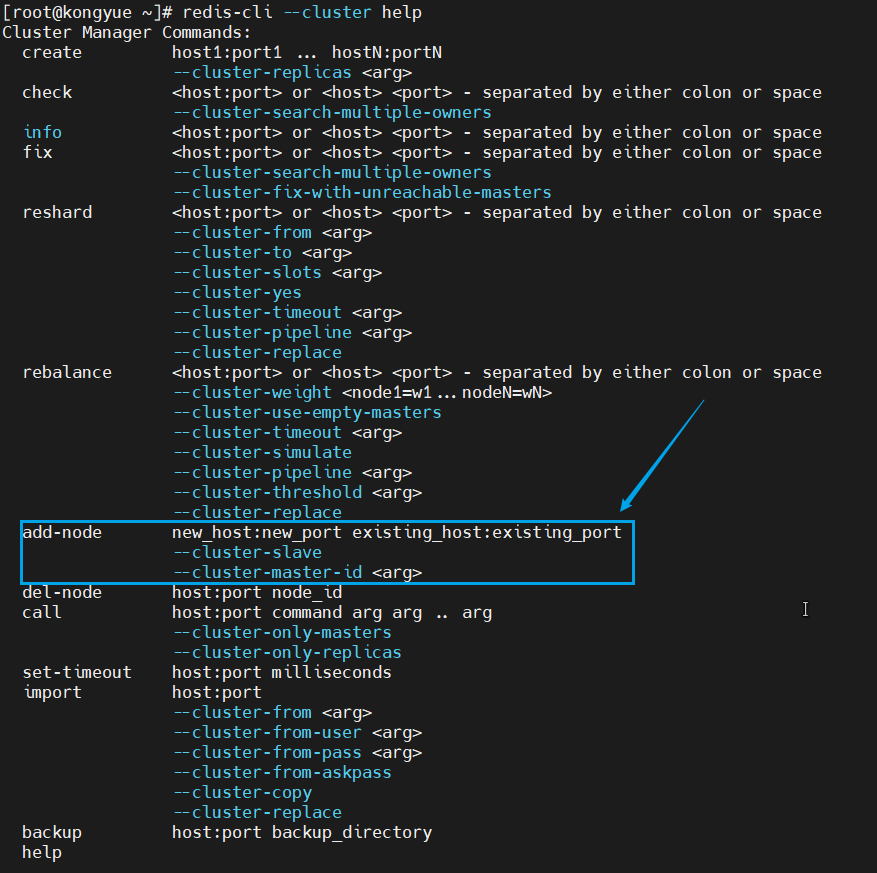
6.5 クラスターのスケーリングのデモ
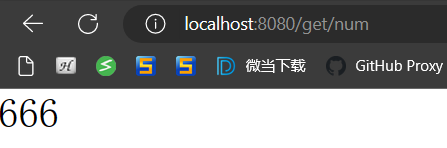
要件: 新しいマスター ノードをクラスターに追加し、そこに num = 666 を格納します。
- ポート 7004 で新しい Redis インスタンスを開始します。
- 7004 を前のクラスターに追加し、マスター ノードとして機能します
- キー番号を 7004 インスタンスに保存できるように、スロットを 7004 ノードに割り当てます。
2 つの新しい関数:
- クラスターにノードを追加する
- いくつかのスロットを新しいスロットに割り当てます
- 新しい Redis インスタンスを作成する
- redis-sharding の下にフォルダーを作成します
mkdir 7004- 設定ファイルをコピーします。
cp redis.conf 7004- 構成ファイルを変更します。
sed -i s/6379/7004/g 7004/redis.conf- 起動
redis-server 7004/redis.conf
- 新しいノードを Redis に追加する
- 注文の実行:
redis-cli --cluster add-node 192.168.188.112:7004 192.168.188.112:7001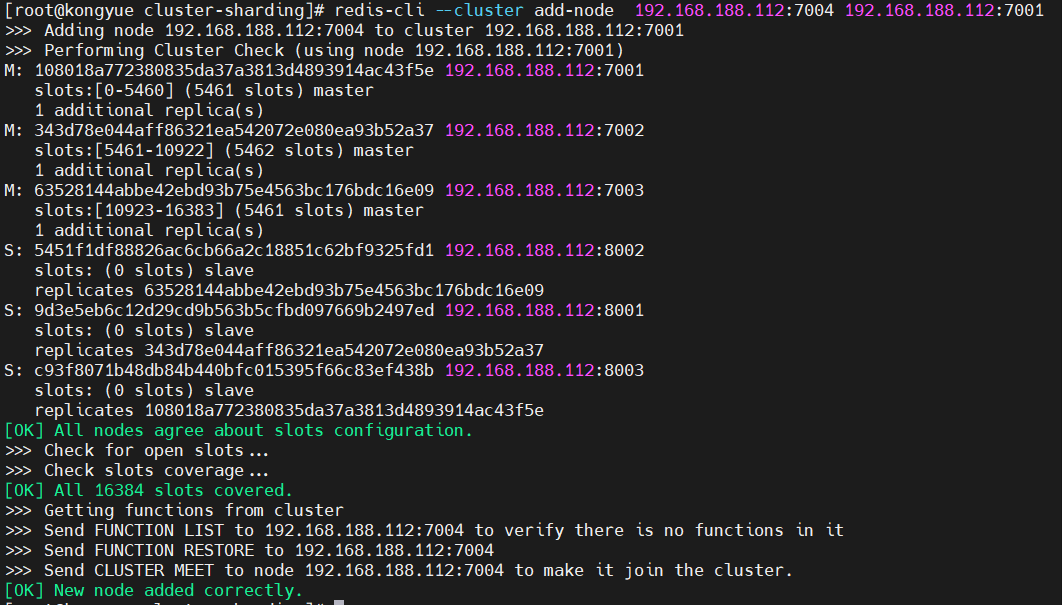
- 次のコマンドを使用してクラスターのステータスを確認します。
redis-cli -p 7001 cluster nodes
- 7004 ノードのスロット数は 0 であるため、7004 ノードにはデータを保存できないことがわかります。
- 転送スロット
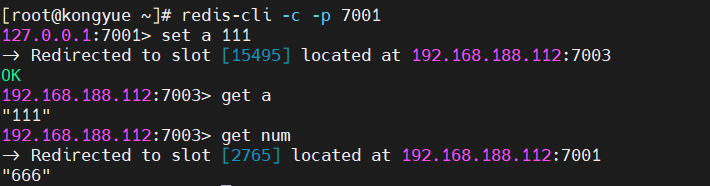
- num をノード 7004 に保存するため、最初に num のスロットを確認する必要があります。num のスロットは 2765 です。

- 0 ~ 3000 のスロットを 7001 ~ 7004 に転送できます。コマンドの形式は次のとおりです。
- 具体的なコマンドは次のとおりで、接続を確立し、移動するカード スロットの数を入力します。
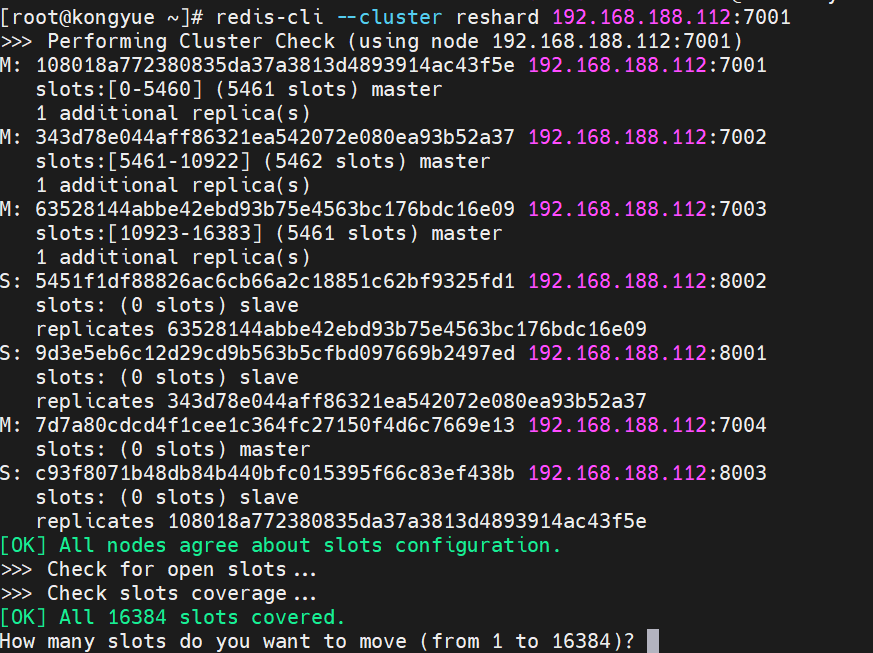
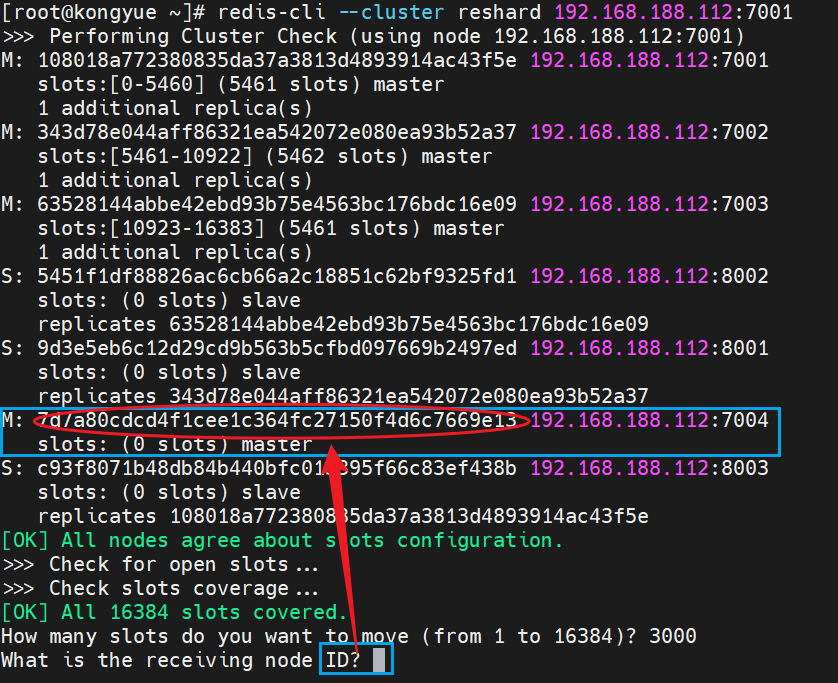
- num をノード 7004 に保存するため、最初に num のスロットを確認する必要があります。num のスロットは 2765 です。
- ここで質問してください。あなたのスロットはどこから移動しましたか?
- all: すべてを表します。つまり、3 つのノードのそれぞれが一部を転送します。
- 特定の ID: ターゲット ノードの ID
- 完了:もうだめ
- 7001から取得するには7001のIDを入力します


- 「yes」と入力してカード スロットの割り当てを完了します
Do you want to proceed with the proposed reshard plan (yes/no)? yes- コマンドで結果を表示する
redis-cli -p 7001 cluster nodes

6.6 フェイルオーバー
- クラスターの初期状態は次のようになります。 7002 がマスター ノードであることがわかります。

- このうち7001、7002、7003はマスターであり、7002はシャットダウンする予定です
6.6.1 自動フェイルオーバー
- Redis インスタンス (7002 など) を直接停止します。
redis-cli -p 7002 shutdown
- まず、インスタンスは他のインスタンスとの接続を失い、その後ダウンしていると考えられます。

- 最後に、オフラインになり、スレーブを新しいマスターに自動的に昇格させることが決定されます。

- 7002が再起動するとスレーブノードになります

6.6.2 手動フェイルオーバー
-
クラスター フェイルオーバー コマンドを使用すると、クラスター内のマスターを手動でシャットダウンし、マスターの ID をクラスター フェイルオーバー コマンドを実行するスレーブ ノードに切り替えて、非認識データ移行を実現できます。プロセスは次のとおりです。
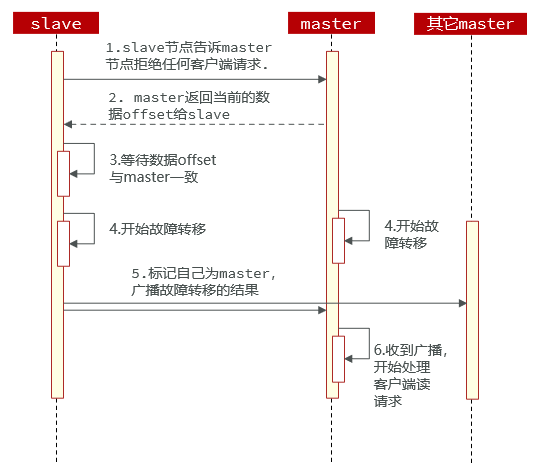
このフェイルオーバー コマンドでは 3 つのモードを指定できます。- デフォルト: 図 1~6 の手順に示すデフォルトのプロセス
- 強制: オフセットの整合性チェックを省略します。
- takeover: データの整合性、マスターステータス、その他のマスターの意見を無視して、ステップ 5 を直接実行します。
-
デモ
- スレーブ ノード 7002 で手動フェイルオーバーを実行して、マスターのステータスを回復します。
-
次のように進めます。
- redis-cli を使用してノード 7002 に接続します
- クラスターフェイルオーバーコマンドを実行します。

-
結果:

6.7 RedisTemplate アクセス断片化クラスター
- RedisTemplate の最下層は、レタスに基づく断片化されたクラスターのサポートも実装しており、使用される手順は基本的にセンチネル モードと同じです。
- Redis のスターター依存関係を導入する
- シャードクラスタアドレスを構成する
- 読み取りと書き込みの分離を構成する
- センチネル モードと比較すると、次のように、断片化されたクラスターの構成のみが若干異なります。
spring: redis: cluster: nodes: - 192.168.188.112:7001 - 192.168.188.112:7002 - 192.168.188.112:7003 - 192.168.188.112:8001 - 192.168.188.112:8002 - 192.168.188.112:8003 - 結果: