目的
前処理機能を含む字句解析プログラムを設計・実装し、コンパイル時の字句解析プロセスへの理解を深めます。
実験要件
1. 前処理機能の実現
ソースプログラムには、プログラムの実行に意味のないシンボルが含まれている場合があり、それらを削除する必要があります。
まず、ソースプログラムの入力処理をコンパイルし、キーボード、ファイル、またはテキストボックスから数行の文を入力し、入力バッファ(文字データ)に順次格納し、改行を削除する前処理サブルーチンをコンパイルし、テキストを編集します。改行やタブなど、複数の空白を 1 つに結合し、コメントを削除します。
2.字句解析機能の実現
入力: 指定された文法のソース プログラム文字列。
出力: 2 つのタプルのシーケンス (syn、トークン、または合計)。ここで、
syn は単語の分類コードです。
トークンとは、格納されている単語そのものの文字列です。
Sum は整数定数です。
特定の実装中に、単語の 2 つのタプルを構造体で処理できます。
3. 解析対象の C 言語サブセットの形態 (それ自体を拡張することも、C 言語の語彙定義に従って定義することもできます)
1) キーワード キーワードは
main if then while do static int double struct break else long switch case typedef char return const float short continue for void default sizeof do
すべて小文字です。
2) 演算子と区切り文字
+ - * / : := < <> <= > >= = ; ( ) #
3) その他のタグ ID と NUM は、
次の形式で他のタグを定義します:
ID→letter(letter|digit)*
NUM→digit digit*
letter→a|…|z|A|…|Z
digit→0|…|9…
4) スペースは空白、タブ、改行で構成されます。
スペースは通常、ID、NUM、特殊記号、キーワードを区切るために使用されます。分析フェーズは通常無視されます。
4. 各種単語記号に対応するカテゴリーコード
タイトルで提供されているカテゴリ コードにいくつかの誤りがあります。実際の要件は、自分で定義できることです。参考情報は次のとおりです。
keyword = {
'main':1,'if':2,'then':3,'while':4,'do':5,
'static':6,'int':7,'double':8,'struct':9,
'break':10,'else':11,'long':12,'switch':13,
'case':14,'typedef':15,'char':16,'return':17,
'const':18,'float':19,'short':20,'continue':21,
'for':22,'void':23,'ID':25,'NUM':26,'default':39,
'sizeof':24,'stdio.h':40,'include':44,'scanf':48,'printf':49}
operator = {
'+':27,'-':28,'*':29,'/':30,':':31,':=':32, '<':33,
'<>':34,'<=':35,'>':36,'>=':37,'=':38,';':41,'(':42,
')':43,'#':0,'{':46,'}':47}
5.字句解析プログラムの主なアルゴリズムの考え方
このアルゴリズムの基本的なタスクは、文字列によって表されるソース プログラムから独立した意味を持つ単語シンボルを識別することであり、その基本的な考え方は、スキャンされた単語シンボルの最初の文字の種類に従って、対応する単語シンボルをスペルアウトすることです。
このプログラムはtest.txtから分析対象のデータを読み込みます。
コード:
import re
def pre(file):
data = file.read()
out =[]
data = re.sub(re.compile('/\*{1,2}[\s\S]*?\*/'),"",data)
data = re.sub(re.compile('//[\s\S]*?\n'), "", data)
data = data.split("\n")
for i in data:
i = i.strip(' ').replace('\t', '')
i = ' '.join(str(i).split())
if(i!=''):
out.append(i)
return out
keyword = {
'main':1,'if':2,'then':3,'while':4,'do':5,
'static':6,'int':7,'double':8,'struct':9,
'break':10,'else':11,'long':12,'switch':13,
'case':14,'typedef':15,'char':16,'return':17,
'const':18,'float':19,'short':20,'continue':21,
'for':22,'void':23,'ID':25,'NUM':26,'default':39,
'sizeof':24,'stdio.h':40,'include':44,'scanf':48,'printf':49}
operator = {
'+':27,'-':28,'*':29,'/':30,':':31,':=':32, '<':33,
'<>':34,'<=':35,'>':36,'>=':37,'=':38,';':41,'(':42,
')':43,'#':0,'{':46,'}':47}
with open('test.txt', 'r') as file:
data = pre(file)
#print(data)
for i in range(len(data)):
pattern1 = re.compile('[a-zA-Z.0-9]+')
line = re.findall(pattern1,data[i])
for j in line:
if j in keyword:
print(j+' -> '+str(keyword[j]))
elif str(j).isdigit():
print("'"+str(j)+"' -> 26")
else:
j = str(j).strip('.')
print("'"+j+"' -> 25")
line2 = re.sub(pattern1," ",data[i])
line2=line2.split(" ")
for j in line2:
if j in operator:
print(j+' -> '+str(operator[j]))
テストテキスト:
#include<stdio.h>
struct student
{
int id;
long int counts;
/*
asfagsaf
*/
/* data */
};
student stu[2000000];
int main(){
for(long int i=0;i<2000000;i++){
stu[i].id=i;
stu[i].counts=0;
}
long int n,m;
int a;
scanf("%d",&n);
for(long int i=0;i<n;i++){
scanf("%ld",&a);
stu[a].counts++;
}
scanf("%ld",&m);
for(long int i=0;i<m;i++){
scanf("%d",&a);
if(stu[a].counts==0){
printf("NO\n");
}
else{
printf("YES\n");
}
}
return 0;
}
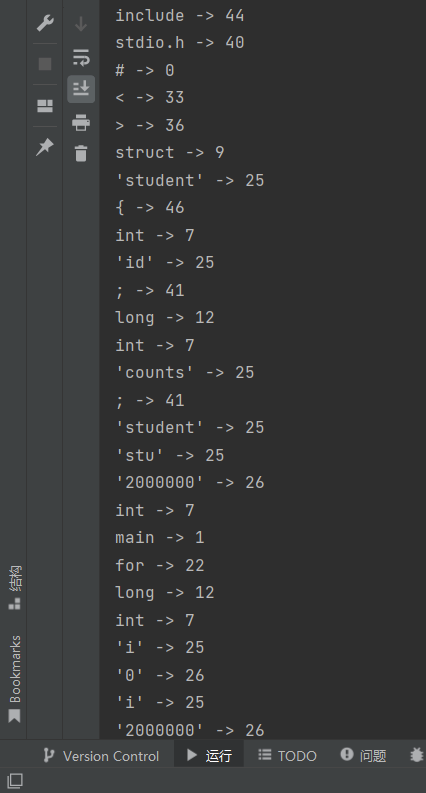
出力:
include -> 44
stdio.h -> 40
# -> 0
< -> 33
> -> 36
struct -> 9
'student' -> 25
{ -> 46
int -> 7
'id' -> 25
; -> 41
long -> 12
int -> 7
'counts' -> 25
; -> 41
'student' -> 25
'stu' -> 25
'2000000' -> 26
int -> 7
main -> 1
for -> 22
long -> 12
int -> 7
'i' -> 25
'0' -> 26
'i' -> 25
'2000000' -> 26
'i' -> 25
( -> 42
= -> 38
; -> 41
< -> 33
; -> 41
'stu' -> 25
'i' -> 25
'id' -> 25
'i' -> 25
= -> 38
; -> 41
'stu' -> 25
'i' -> 25
'counts' -> 25
'0' -> 26
= -> 38
; -> 41
} -> 47
long -> 12
int -> 7
'n' -> 25
'm' -> 25
; -> 41
int -> 7
'a' -> 25
; -> 41
scanf -> 48
'd' -> 25
'n' -> 25
for -> 22
long -> 12
int -> 7
'i' -> 25
'0' -> 26
'i' -> 25
'n' -> 25
'i' -> 25
( -> 42
= -> 38
; -> 41
< -> 33
; -> 41
scanf -> 48
'ld' -> 25
'a' -> 25
'stu' -> 25
'a' -> 25
'counts' -> 25
} -> 47
scanf -> 48
'ld' -> 25
'm' -> 25
for -> 22
long -> 12
int -> 7
'i' -> 25
'0' -> 26
'i' -> 25
'm' -> 25
'i' -> 25
( -> 42
= -> 38
; -> 41
< -> 33
; -> 41
scanf -> 48
'd' -> 25
'a' -> 25
if -> 2
'stu' -> 25
'a' -> 25
'counts' -> 25
'0' -> 26
( -> 42
printf -> 49
'NO' -> 25
'n' -> 25
} -> 47
else -> 11
{ -> 46
printf -> 49
'YES' -> 25
'n' -> 25
} -> 47
} -> 47
return -> 17
'0' -> 26
; -> 41
} -> 47
注意点:
- ファイルを前処理した後、データから単語や記号を抽出するプロセスでは正規表現が使用されますが、ここには論理的な抜け穴と見なさ
[a-zA-Z.0-9]+れる小さなバグが存在するためです。解決策は、出力時にそれを削除することです。stu[i].counts=0;...counts. - 前処理ファイルで使用される正規表現:
/\*{1,2}[\s\S]*?\*/、目的は複数行コメントを削除すること、//[\s\S]*?\n目的は単一行コメントを削除することです。 - 現在の出力はキーワードの順序ではなく、最初にキーワード、次に記号の順序になっているようですが、これは改善される必要があります。
正しい:
後期では中間処理に若干の補足や改良が加えられ、解析の出力シーケンスが順次実行されるようになった。
import re
def pre(file):
data = file.read()
out =[]
data = re.sub(re.compile('/\*{1,2}[\s\S]*?\*/'),"",data)
data = re.sub(re.compile('//[\s\S]*?\n'), "", data)
data = data.split("\n")
for i in data:
i = i.strip(' ').replace('\t', '')
i = ' '.join(str(i).split())
if(i!=''):
out.append(i)
return out
keyword = {
'main':1,'if':2,'then':3,'while':4,'do':5,
'static':6,'int':7,'double':8,'struct':9,
'break':10,'else':11,'long':12,'switch':13,
'case':14,'typedef':15,'char':16,'return':17,
'const':18,'float':19,'short':20,'continue':21,
'for':22,'void':23,'ID':25,'NUM':26,'default':39,
'sizeof':24,'stdio.h':40,'include':44,'scanf':48,'printf':49}
operator = {
'+':27,'-':28,'*':29,'/':30,':':31,':=':32, '<':33,
'<>':34,'<=':35,'>':36,'>=':37,'=':38,';':41,'(':42,
')':43,'#':0,'{':46,'}':47}
with open('test2.txt', 'r') as file:
data = pre(file)
print("\n文本预处理后的内容:\n")
print(data)
print()
for i in range(len(data)):
line = re.split(r"([a-zA-Z.0-9]+)",data[i])
for j in line:
if j == '' or j == ' ':
continue
if j == '\\' and line[line.index(j) + 1] == 'n':
line[line.index(j) + 1] = ''
continue
if j in keyword:
print('('+str(keyword[j])+','+j+')')
elif str(j).isdigit():
print("(26,'"+str(j)+"')")
elif j in operator:
print('(' + str(operator[j])+','+j+')')
elif j.isalpha():
j = str(j).strip('.')
print("(25,'"+j+"')")
else:
temp = str(j)
for t in temp:
if t in operator:
print('(' + str(operator[t])+','+t+')')
主な操作は正規表現の使用を変更することで、当初は抽出に式を使用していましたが、文字列を分割するために式を使用するようになり、効果が向上しました。
出力:
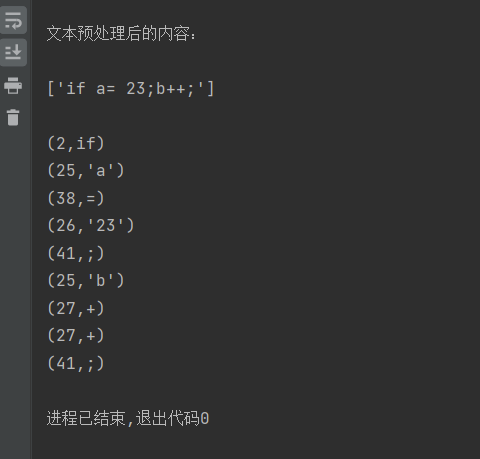
サンプル 1:
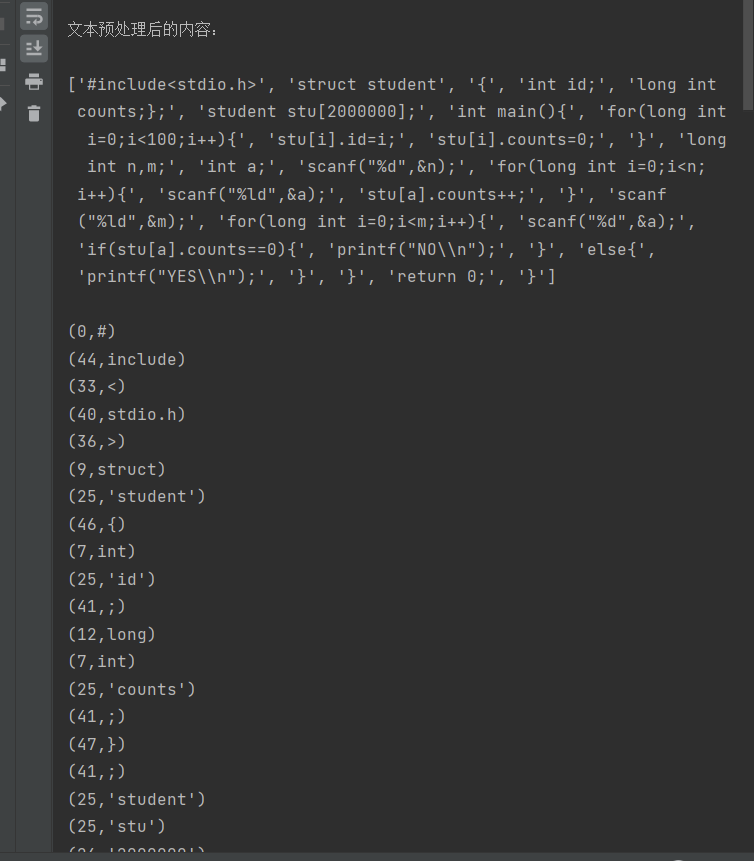 サンプル 2:
サンプル 2: