字句解析プログラム(字句 アナライザ)要件:
- 文字で構成されるソースプログラムからの流れは左から右へスキャン
- (言葉の語彙的意味を識別する語彙素)
- 戻り単語レコード(単語クラス、単語そのもの)
- フィルタースペース
- コメントをスキップ
- 字句エラーが見つかりました
プログラムの構造:
入力:文字ストリーム(入力どのような方法、どのようなデータ構造で格納されています)
治療:
- トラバース(何トラバーサル)
- 字句のルール
出力:ワードストリーム(どのような出力形式)
- タプル
Wordのクラス:
1.識別子(10)
符号なし2(11)
3.ワード(単語1ヤード)のままにします
4.オペレータ(単語1ヤード)
5.区切り文字(ワード1ヤード)
| Wordのシンボル |
種はコーディングしません |
Wordのシンボル |
種はコーディングしません |
| ベギン |
1 |
: |
17 |
| もし |
2 |
:= |
18 |
| それから |
3 |
< |
20 |
| 同時に |
4 |
<= |
21 |
| 行う |
5 |
<> |
22 |
| 終わり |
6 |
> |
23 |
| L(リットル| D)* |
10 |
> = |
24 |
| DD * |
11 |
= |
25 |
| + |
13 |
; |
26 |
| - |
14 |
( |
27 |
| * |
15 |
) |
28 |
| / |
16 |
# |
0 |
1、コード
書式#include <stdio.hに>
する#include <string.hの>
する#include <stdlib.h>に含ま
チャーwsym [80]、ssym [ 8]; // wsym 格納するための入力配列、ssym出力配列を格納するための
チャーCHと、
INT行を、SYN、SUM、M、I、P;
[6]のchar *ワード= { "IF"、 "開始" } "次に"、 "しばらく"、 "行う"、 "終了"。
getsynボイド(){
ための(I = 0;私は<8; I ++は)
ssym [I]は= NULL; //初期化する
CH = wsym [P ++];
一方、(CH == ''){//それがブランクである場合、次いで動作せず、添字ダウン
CH = wsym [P]、
P ++;
}
IF((CH> = 'A' && CH <= 'Z')||(CH> = 'A' && CH <= 'Z') ){//メールを送るかどうかを決定する
; M = 0
=>一方((CH> = '0' && CH <=」9' )||(CH> = '' && CH <= 'Z')||(CH '' && CH <= 'Z')){
ssym [M ++] = CH;
CH = wsym [P ++];
}
ssym [M ++] = '\ 0';
P--;
SYN = 10;
(I = 0 ; I <6; Iは++){
キーが同じで決定された場合(のstrcmp(ワード[I]、ssym)== 0){//場合
SYN = I + 1、。
BREAKと、
}
}
}そうIF {//文字か否かを判定する(CH> = '0' && CH <=」9 ')
SUM = 0;
一方(CH> = '0' && CH <=' 9' ){
合計=合計* 10 +(CH-'0' )。
CH = wsym [P ++]。
}
P--。
SYN = 11。
}他のスイッチ(CH){//其它字符
場合'+':
ssym [0] CH =を、SYN = 13。
ブレーク;
ケース' - ':
ssym [0] CH =を、SYN = 14。
ブレーク;
場合'*':
ssym [0] CH =を、SYN = 15。
ブレーク;
ケース'/':
ssym [0] CH =を、SYN = 16。
ブレーク;
ケース':':
I = 0;
ssym [I ++] = CH;
CH = wsym [P ++]。
(CH == '=')であれば{
ssym [I ++] = CH。
SYN = 18。
}他{
SYN = 17。
P--;
ケース'<':
I = 0;
ssym [I ++] = CH;
CH = wsym [P ++]。
(CH == '=')であれば{
ssym [I ++] = CH。
SYN = 21。
}他( '>' == CH)であれば{
ssym [I ++] = CH。
SYN = 22。
}他{
SYN = 20。
P--;
}
ブレーク;
ケース'>':
I = 0;
ssym [I ++] = CH;
CH = wsym [P ++]。
(CH == '=')であれば{
ssym [I ++] = CH。
SYN = 24。
}他{
SYN = 23。
P--;
}
ブレーク;
ケース'=':
ssym [0] CH =を、SYN = 25。
ケース';':
ssym [0] CH =を、SYN = 26。
ブレーク;
ケース'(':
ssym [0] CH =を、SYN = 27;
;破る
ケース''):
[0] = CH ssymと、SYN = 28。
ブレーク;
ケース'#':
ssym [0] = CH; SYN = 0。
ブレーク;
ケース'\ n'は:
SYN = 100;
ブレーク;
デフォルト:
SYN = -1;
ブレーク;
}
}
メイン(){int型
; P = 0
。1 =行;
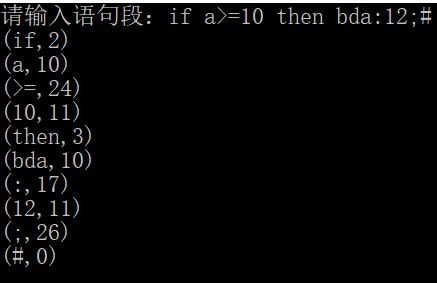
のprintf( "を入力してください文段落:");
実行{
CH = GETCHAR();
wsym [P ++] = CH;
}一方、(CH = '#'!)
P = 0;
DO {
getsyn();
スイッチ(SYN){
ケース-1:
のprintf( "エラー行の%d!"、行);
BREAK;
ケース100:
ロウ+ = 1;
BREAK;
。ケース11
のprintf ( "(%のDは、%D)\ N-"、SUM、SYN);
BREAK;
デフォルト:
のprintf( "(%S、%のD)\ N-"、ssym、SYN);
BREAK;
}
}ながら(SYN =! 0);
}
2、試験結果