カタログを読む
コルーチンとチャネル
まず、オペレーティング システムで学んだいくつかの概念を復習しましょう。
プロセスはプログラム実行の基本単位であり、独立したメモリ アドレス空間で実行されます。
プロセスは複数のスレッド (スレッド) で構成されます. スレッドの存在は, 複数のタスクを同時に実行し, 時間を最大限に活用し, 待機を防ぐためです. メモリアドレス空間はスレッド間で共有されます.
この点は、windows リソース マネージャーから明確にわかります。次のように、各アプリケーションはプロセスであり、Typora プログラムの下で同時に実行される 2 つのスレッドがあります。
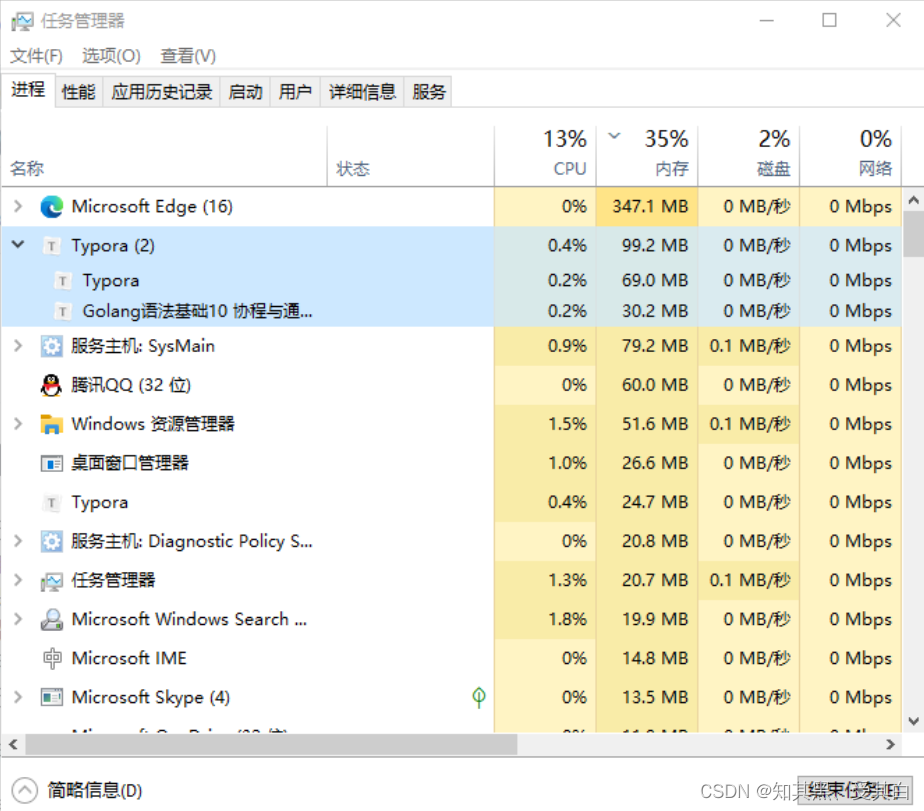
並行性はマルチスレッドに基づく概念です.CPU の実行時間を多くの小さな間隔に分割します.複数のスレッドが常に実行を切り替えています.上層からは同時に実行しているように見えますが,まだ実行中です.直線的な性質です。
並列処理とは、プログラムが特定のイベントで同時に複数の CPU で実行されることを意味し、マルチコア プロセッサは並列処理の可能性を提供します。
したがって、並行性は並列性でもあります。
コルーチン (ゴルーチン)
Go は、ゴルーチンとチャネルの概念に依存して、同時実行をネイティブにサポートします。
ゴルーチンの概念は、プロセス、スレッド、コルーチンなどの概念と区別することです。
このうち、コルーチンはコルーチンとも呼ばれ、これが従来の意味でのコルーチンであり、ゴルーチンは Go でのみ有効です。
コルーチンはスレッドよりも軽い概念であり、メモリとリソースをほとんど使用しません。
スタックを分離してメモリの使用量を動的に増加または削減します. スタックの管理も自動であり, コルーチンの終了後にスペースは自動的に解放されます.
コルーチンは複数のスレッド間またはスレッド内で実行でき、その作成は非常に安価であるため、100,000 個のコルーチンが同じアドレス空間に存在できます。
この概念は他の言語 (C#、Java など) にも存在し、次の点でゴルーチンとは異なります。
- Go コルーチンは並列 (または並列に展開できる) を意味し、コルーチンは一般的に理論的にはありません。Go コルーチンはコルーチンよりも強力です。
- Go コルーチンはチャネルを介して通信し、コルーチンは yield 操作と再開操作を介して通信します。
ゴルーチンは単純なモデルで記述されます。
これは、同じアドレス空間で他のコルーチンと同時に実行される関数です。
関数またはメソッド名の前に go キーワードを追加してコルーチンを作成および実行し、実行後に静かに (戻り値なしで) 終了します。
//并行的运行list.Sort,不等待
go list.Sort()
Go プログラムに含めなければならないmain()関数はコルーチンと見なすことができます。これは go キーワードによって開始されませんが、ゴルーチンはプログラムの初期化プロセス中に実行することもできます (init() 関数が実行されます)。
コルーチンを単純に終了するという概念は具体的ではなく、コルーチンはチャネルと連携する必要があります。
チャネル
並列プログラミングの難しい部分は、共有変数への適切なアクセスを取得することです。ミューテックスは複雑であり、Go は別のアプローチを推奨しています。
つまり、共有値はチャネルで渡されます. Unix パイプラインと同様に、チャネルは型付きデータの送信に使用されます. 任意の時点で 1 つのコルーチンのみがチャネル内のデータにアクセスできるため、コルーチン間通信が完了します.共有メモリによって引き起こされるすべての落とし穴を回避します。
チャネルを介したこの通信方法により、同期が保証され、同時にデータの所有権が転送されます。
この設計哲学は、最終的には 1 つの文に要約されます。
メモリを共有することによって通信するのではなく、通信することによってメモリを共有します。
1 宣言と初期化
チャネルを宣言する基本的な形式は次のとおりで、初期化されていない channel 値を使用しますnil。
var identifier chan datatype
チャネルは、chan intや などchan string。空のインターフェイスinterface{}や。
マップと同様に、チャネルも参照型であるため、make を使用して初期化します。2 番目のパラメータを指定して、バッファのサイズ、つまりチャネルが保持できるデータの数を指定できます。この値はデフォルトで 0 です。 、つまりバッファリングがないことを意味します。バッファリングされていないチャネルは、通信、値交換、および同期を組み合わせて、2 つのコルーチンの計算が既知の状態であることを保証します。
var ci chan string
// 无缓冲的整数通道
ci = make(chan string)
// 无缓冲的整数通道
cj := make(chan int, 0)
// 指向文件的指针的缓冲通道
cs := make(chan *os.File, 100)
2 通信事業者 ←
オペレーターはデータの転送を直感的に表します。情報は矢印の方向に流れます。
チャネルへのフロー (send) は でch <- int1表されます。これは、チャネル ch を通じて変数 int1 を送信することを意味します。
チャネルからの流出(int2 = <- ch受信、変数int2がチャネルchからデータを受信することを意味し、int2が宣言されていない場合は使用できますint2 := <- ch。
<- ch現在の値を破棄し、次のような検証に使用できるチャネルの次の値を取得することを示すために使用されます。
if <- ch != 1000 {
...
}
チャンネル名は通常、読みやすくするために chan で始まるか、chan を含みます。
チャネルの送信と受信はアトミック操作であり、互いに干渉することなく常に完了します。
次の例は、通信演算子の使用を示しています。
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan string)
go sendData(ch)
go getData(ch)
// 当前程序暂停 1 秒钟
time.Sleep(1e9)
}
func sendData(ch chan string) {
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokyo"
}
func getData(ch chan string) {
var input string
// time.Sleep(2e9)
for {
input = <-ch
fmt.Printf("%s ", input)
}
}
//Output:
Washington Tripoli London Beijing tokyo
2 つのコルーチンが通信する必要がある場合は、パラメーターとして同じチャネルを指定する必要があります。
上記の例では、2 つのコルーチンが main() 関数で開始されます。sendData
() はチャネル ch を介して 5 つの文字列を送信し、
getData() はそれらを順番に受信して出力します。
同期の詳細は次のとおりです。
1 つの main() は、2 つのコルーチンが完了するまで 1 秒間待機しました。そうでない場合 (time.Sleep(1e9) をコメントアウト)、sendData() は出力する機会がありません。
2 getData() は無限ループを使用します。sendData() が送信を完了し、ch が空になると終了します。
3 1 つまたはすべての go キーワードを削除すると、プログラムは実行できなくなり、Go ランタイムはパニックをスローします。これは、すべてのコルーチンが何か (チャネルからの読み取りまたはチャネルへの書き込み) を待っているかどうかをランタイムがチェックするためです。これはデッドロックを意味し、プログラムを続行できません。
送信チャネルと受信チャネルの順序は予測できません. 印刷ステータスを使用して出力すると、両者の時間的な遅延により、実際の発生順序と印刷の順序が異なります.
3チャンネルブロッキング
前述のように、通信はデフォルトで同期的でバッファリングされていないため、チャネルの/送受信相手の準備が整うまでブロックされます。
1 同じチャネルの場合、(コルーチンまたは関数内の) 送信操作は、受信側の準備が整うまでブロックされます。ch
のデータが受信されない場合、他のデータをチャネルに渡すことはできません。
2 同じチャネルの場合、(コルーチンまたは関数で) 送信者が利用可能になるまで、受信操作はブロックされます
次の例のコルーチンは、無限ループでチャネルにデータを送信し続けますが、受信側がないため、数値 0 のみが出力されます。
package main
import "fmt"
func main() {
ch1 := make(chan int)
go pump(ch1) // pump hangs
fmt.Println(<-ch1) // prints only 0
}
func pump(ch chan int) {
for i := 0; ; i++ {
ch <- i
}
}
//Output:0
連続して出力できるチャネル値を受け取る新しいコルーチンを定義します。
package main
import "fmt"
func main() {
ch1 := make(chan int)
go pump(ch1)
go suck(ch1)
time.Sleep(1e9)
}
func pump(ch chan int) {
for i := 0; ; i++ {
ch <- i
}
}
func suck(ch chan int) {
for {
fmt.Println(<-ch)
}
}
4 セマフォ (Semaphore)
Go 言語では、通常、セマフォ (Semaphore) を使用して同時アクセス リソースの数を制限します。
セマフォは、共有リソースに同時にアクセスするスレッドの数を制御するために使用できるカウンター オブジェクトです。
一般に、セマフォには次の 2 つの基本操作があります。
- Acquire 操作はライセンス (またはシグナル) の取得を試み、現在利用可能なライセンスの数が 0 の場合、ライセンスが利用可能になるまでブロックして待機します。
- Release 操作は、他のブロックされたスレッドが許可を取得できるように、許可を解放します。
Go 言語では、sync.Mutex と sync.Cond を使用してセマフォを実装できます。
Go 言語では、sync.Cond は複数のゴルーチン間の通信に使用される条件変数オブジェクトです。
多くの場合、スレッド間同期を実現するためにミューテックス (sync.Mutex) と共に使用されます。
ゴルーチンが別のゴルーチンの特定の条件が満たされるのを待ちたい場合、Wait() メソッドを呼び出して自身をブロックし、条件変数の通知を待つことができます。
条件が満たされると、Signal() または Broadcast() メソッドを介して通知を送信し、待機中のゴルーチンを起動できます。
sync.Mutex と sync.Cond を使用してセマフォを実装するサンプル コードを次に示します。
package main
import (
"fmt"
"sync"
)
type Semaphore struct {
// 当前可用的许可数量
count int
// 条件变量对象,用于等待和唤醒 goroutine
cond *sync.Cond
}
// 创建许可数量
func NewSemaphore(count int) *Semaphore {
return &Semaphore{
count: count,
cond: sync.NewCond(&sync.Mutex{
}),
}
}
// 操作许可
func (s *Semaphore) Acquire() {
// 获取条件变量对应的锁
s.cond.L.Lock()
defer s.cond.L.Unlock()
// 如果当前没有可用的许可,就等待条件变量
for s.count <= 0 {
// 释放锁并等待条件变量满足
s.cond.Wait()
}
s.count-- // 获取许可,许可数量减一
}
// 释放许可
func (s *Semaphore) Release() {
s.cond.L.Lock()
defer s.cond.L.Unlock()
// 释放许可,许可数量加一
s.count++
// 唤醒等待条件变量的 goroutine 中的一个
s.cond.Signal()
}
func main() {
sem := NewSemaphore(3)
// 协调多个 goroutine 的执行
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1) // 增加计数器的值
go func(id int) {
sem.Acquire()
defer sem.Release()
fmt.Printf("Goroutine %d acquired 获取许可 semaphore\n", id)
// do some work
fmt.Printf("Goroutine %d released 释放许可 semaphore\n", id)
wg.Done() //减少计数器的值
}(i)
}
wg.Wait() //等待计数器归零
fmt.Println("All goroutines have finished")
}
root@debiancc:~/www/test# go run test.go
Goroutine 4 acquired 获取许可 semaphore
Goroutine 4 released 释放许可 semaphore
Goroutine 2 acquired 获取许可 semaphore
Goroutine 2 released 释放许可 semaphore
Goroutine 3 acquired 获取许可 semaphore
Goroutine 3 released 释放许可 semaphore
Goroutine 0 acquired 获取许可 semaphore
Goroutine 0 released 释放许可 semaphore
Goroutine 1 acquired 获取许可 semaphore
Goroutine 1 released 释放许可 semaphore
All goroutines have finished
root@debiancc:~/www/test#
5チャンネルファクトリー
チャネル ファクトリ モードはプログラミングでよく使用されます。つまり、チャネルはパラメータとしてコルーチンに渡されませんが、関数を使用してチャネルを生成し、それを返します。
package main
import (
"fmt"
"time"
)
func main() {
stream := pump()
go suck(stream)
time.Sleep(1e9)
}
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
for {
fmt.Println(<-ch)
}
}
実行の流入と流出を 1 秒以内に連続して実行します。
6 チャネルに for ループを使用する
for ループの range ステートメントはチャネル ch で使用でき、値は次のようにチャネルから取得できます。
for v := range ch {
fmt.Printf("The value is %v\n", v)
}
このような使用は、チャネルの作成および閉鎖と調整する必要があり、単独では存在できません。
package main
import (
"fmt"
"time"
)
func main() {
suck(pump())
time.Sleep(1e9)
}
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
go func() {
for v := range ch {
fmt.Println(v)
}
}()
}
7 チャンネルを閉じる
チャネルは明示的に閉じることができますが、送信者のみがチャネルを閉じる必要があり、受信者は閉じる必要はありません。
ch := make(chan float64)
defer close(ch)
チャネルが閉じているかどうかをテストするには、ok 演算子を使用します。
v, ok := <-ch // ok is true if v received value
完全な例
package main
import "fmt"
func main() {
ch := make(chan string)
go sendData(ch)
getData(ch)
}
func sendData(ch chan string) {
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokio"
close(ch)
}
func getData(ch chan string) {
for {
input, open := <-ch
if !open {
break
}
fmt.Printf("%s ", input)
}
}
root@debiancc:~/www/test# go run test.go
Washington Tripoli London Beijing Tokio
root@debiancc:~/www/test#
ただし、チャネルが閉じているかどうかを自動的に検出するため、for-range を使用してチャネルを読み取る方が優れています。
for input := range ch {
process(input)
}
選択する
同時に実行されるさまざまなコルーチンから値を取得するには、select キーワードを使用します。これは、switch 制御ステートメントに非常に似ています。その動作は、「準備はできていますか」というポーリング メカニズムのようなものです。
select は、チャネルに入るデータをリッスンするか、チャネルを使用して値が送信されたときにリッスンします。
select {
case u:= <- ch1:
...
case v:= <- ch2:
...
...
default: // no value ready to be received
...
}
select が行うことは: リストされた多くの通信状況の 1 つを処理することを選択します。
- 両方がブロックされている場合は、どちらかが処理できるようになるまで待機します。
- 複数扱える場合はランダムに1つ選ぶ。
- 処理するチャネル操作がなく、default ステートメントが書き込まれている場合は、それが実行されます。default は常に実行可能です (実行準備完了)。
デフォルトを使用すると、送信がブロックされないことを確認できますが、デフォルトのないリスニング モードも使用でき、break ステートメントを介してループを終了します。
完全な例:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go pump1(ch1)
go pump2(ch2)
go suck(ch1, ch2)
time.Sleep(1e9)
}
func pump1(ch chan int) {
for i := 0; ; i++ {
ch <- i * 2
}
}
func pump2(ch chan int) {
for i := 0; ; i++ {
ch <- i + 5
}
}
func suck(ch1, ch2 chan int) {
for {
select {
case v := <-ch1:
fmt.Printf("Received on channel 1: %d\n", v)
case v := <-ch2:
fmt.Printf("Received on channel 2: %d\n", v)
}
}
}
ch1 と ch2 の 2 つのチャネルと、pump1()、pump2()、suck() の 3 つのコルーチンがあります。
無限ループでは、ch1 と ch2 は pump1() と pump2() を介して整数で埋められます。
suck() はまた、無限ループで入力をポーリングします。
select文でch1とch2の整数を取得して出力します。
どのケースが選択されるかは、メッセージを受信したチャネルによって異なります。
プログラムは main の実行から 1 秒後に終了します。
例
1つのレイジージェネレーター
ジェネレーターは、呼び出されたときにシーケンス内の次の値を返す関数です。
例えば:
generateInteger() => 0
generateInteger() => 1
generateInteger() => 2
....
ジェネレーターは、毎回シーケンス全体ではなく、シーケンス内の次の値を返します。
この機能は遅延評価とも呼ばれます。
必要なときにのみ評価し、関連する変数リソース (メモリと CPU) を保持します。
これは、必要に応じて式を評価するための手法です。
たとえば、偶数の数列を無限に生成するとします。
このような数列を生成して 1 つずつ使用するのは困難であり、メモリがオーバーフローする可能性があります。ただし、チャネルと go コルーチンを使用する関数は、この要件を簡単に達成できます。
次の例では、int 型のチャネルを使用して実装されたジェネレーターを実装しています。
チャネルは、yield と resume という名前で、コルーチン コードでよく使用される言葉です。
package main
import (
"fmt"
)
var resume chan int
func integers() chan int {
yield := make(chan int)
count := 0
go func() {
for {
yield <- count
count++
}
}()
return yield
}
func generateInteger() int {
return <-resume
}
func main() {
resume = integers()
fmt.Println(generateInteger()) //=> 0
fmt.Println(generateInteger()) //=> 1
fmt.Println(generateInteger()) //=> 2
}
メーカーと新品の違い
Go 言語では、make と new の両方を使用してメモリを割り当てることができますが、それらの使用シナリオと動作は異なります。
1 make は、スライス、マップ、パイプなどの参照型 (スライス、マップ、およびチャネル) を作成するために使用され、初期化された参照型 (スライス、マップ、またはチャネル) の値を返します。これらの型は、基礎となるデータ構造への参照であり、使用する前に初期化する必要があります。
例:
// 创建一个长度为 5,容量为 10 的整型切片
slice := make([]int, 5, 10)
// 创建一个字符串类型的管道
channel := make(chan string)
2 new は、値型 (struct、int、float64 など) のメモリ空間を割り当て、この型へのポインターを返すために使用されます。
割り当てられたメモリは、型の既定値であるゼロに設定されます。
例:
var ptr *int
// 分配一个整型的内存空间,并将 ptr 指向该空间
ptr = new(int)
一般に、make と new の主な違いは次のとおりです:
make は参照型を初期化し、初期化された値を返すためにのみ使用できます
が、new は値型のメモリ空間を割り当て、この型へのポインターを返すために使用されます。
slice := new([]int, 5, 10)これでいいですか?
できません。
Go 言語では、新しい関数を使用して値型 (struct、int、float64 など) のメモリ空間を割り当て、その型へのポインターを返します。
スライス (slice) は参照型であるため、new を使用してスライスを作成することはできません。
値型と参照型の違いは何ですか?
値型 (Value Type) と参照型 (Reference Type) は、2 つの異なるデータ型です。
主な違いは次のとおりです。
- 値型の変数は、データの値を直接格納します。
- 参照型の変数には、データ ストレージの場所への参照が格納されます。
より具体的には、値型の変数は、データへの参照ではなく、データ自体を格納します。
これは、値型の変数が別の変数に割り当てられると、新しいコピーが作成され、2 つの変数が互いに影響を与えないことを意味します。値型データには、整数、浮動小数点数、ブール値、文字などが含まれます。
参照型の変数には、データ ストレージの場所への参照が格納されます。
参照型の変数が別の変数に割り当てられると、それらはすべて同じデータ ストレージの場所を指し、それらのいずれかを変更すると他の変数に影響します。参照型データには、スライス、マップ、パイプ、インターフェイス、関数などが含まれます。