目次
1. 二分探索木 (BST)
1. 二分探索木とは
バイナリ サーチ ツリー(略してBST ) は、次のプロパティを満たす一般的なバイナリ ツリー データ構造です。
- どの nodeについても、左側のサブツリー内のすべてのノードはその値よりも小さく、右側のサブツリー内のすべてのノードはその値よりも大きくなります。
- どのノードでも、その左部分木と右部分木は二分探索木です。
二分探索木は上記の性質を持っているため、検索、挿入、削除などの操作を素早く行うことができます。二分探索木では、要素を見つけるための時間計算量は O(log n) です。ここで、n は木内のノードの数です。同時に、二分探索木では、ツリー内のすべてのノードを特定の順序で出力できるため(インオーダー トラバーサルなど)、データを並べ替える方法としても使用できます。
2. 二分探索木の判定
二分探索木かどうかの判断方法現在のノードが左の子ノードより大きく、右の子ノードより小さいというだけでは二分探索木と判断できないので、二分探索木と判断しない人もいます。 「二分探索木の概念を明確に知らない人々の誤解. 本当の定義は、現在のノードがその左側の部分木のどのノードよりも大きく、右側の部分木のどのノードよりも小さいということです. 実際、使用するという考えは非再帰は、判断するために順序トラバーサルを使用することです。なぜなら、フォーク探索ツリーの順序トラバーサルは in order でなければならないので、コードを書くことができるからです
//二叉搜索树的中序遍历为有序序列
public boolean isValidBST(TreeNode root) {
travel(root);
for (int i = 0; i < list.size() - 1; ++i) {
if (list.get(i) >= list.get(i + 1))
return false;
}
return true;
}
ArrayList<Integer> list = new ArrayList<>();
public void travel(TreeNode root) {
if (root == null)
return;
travel(root.left);
list.add(root.val);
travel(root.right);
}再帰の考え方も判断しやすい. 左のサブツリーに入ると前のルートノードの値が最大値. 右のサブツリーに入ると前のルートノードの値が最小値.左側のみが必要です。サブツリーの値は前のルート ノードの値よりも小さく、右側のサブツリーの値はルート ノードの値よりも大きいと判断できます。
public boolean isValidBST(TreeNode root) {
return isValidBST(root, Long.MIN_VALUE, Long.MAX_VALUE);
}
public boolean isValidBST(TreeNode node, long lower, long upper) {
if (node == null) {
return true;
}
if (node.val <= lower || node.val >= upper) {
return false;
}
return isValidBST(node.left, lower, node.val) && isValidBST(node.right, node.val, upper);
}
2.二分探索木CRUD操作
1. 二分探索木のデータ構造
まず、通常のバイナリ ツリーと同じデータ構造を持ち、プライベートな内部クラス TreeNode が必要です (内部クラスがわからない場合は、この記事を読むことができます: https://blog.csdn.net /qq_64580912/article/details/129310721 ) 、バイナリ ツリー ノードとして、ノードの値と左右の子ノードのポインティングを保存し、ルート ノード属性も BST クラス内で使用して、この二分探索木 のルートノード、次に二分探索木のノード数を表すsize属性
public class BST {
private class TreeNode {
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val = val;
}
@Override
public String toString() {
return "TreeNode{" +
"val=" + val +
'}';
}
}
private TreeNode root;
private int size;
}
2.操作を追加する
バイナリ サーチ ツリーの性質のため: 現在のノードの値は、左側のサブツリーのどのノードよりも大きく、右側のサブツリーのどのノードよりも小さい. 追加するとき、バイナリ サーチ ツリーを破棄することはできません。挿入すると、常に新しく追加されたノードがリーフ ノードになるため、追加されたノードの値が現在のルート ノードよりも小さい場合は、追加されたノードの値が現在のルート ノードよりも大きい場合に、左のサブツリーに再帰的に挿入します。現在のルート ノード, 右のサブツリーに再帰的に挿入. ルート ノードが空の場合は、ノードを追加し、追加されたノードを返し、再帰的にノードを接続するために戻ります.
public void add(int val) {
this.root = add(root, val);
}
//插入的结点都是和根结点进行比较,如果大于根结点,右子树的插入,如果小于根结点就是左子树的插入
public TreeNode add(TreeNode root, int val) {
//寻找到了插入的位置
if (root == null) {
TreeNode node = new TreeNode(val);
size++;
return node;
} else if (root.val > val) {//此时左子树插入
root.left = add(root.left, val);
return root;
}
//此时左子树插入
root.right = add(root.right, val);
return root;
}
3. 検索操作
1. 最大値を見つける
反復実装
バイナリ ツリーの性質により、最大値を見つけるための反復は簡単です。現在のノードの値は、左側のサブツリーのどのノードよりも大きく、右側のサブツリーのどのノードよりも小さいため、最大値を簡単に知ることができます。 node Point はツリーの右端のノードです。
//查找最大值 ---迭代实现
public int findMax() {
if (root == null) {
throw new NoSuchElementException("root is null");
}
TreeNode temp = root;
while (temp.right != null) {
temp = temp.right;
}
return temp.val;
}再帰的な実装
再帰は実際には比較的簡単に実装できます. 現在のルート ノードの右の子ノードが空になったときに、継続的に右のサブツリーに再帰し、現在のルート ノードに戻るだけで済みます.
//查找最大值 ---递归实现
public TreeNode findMax2() {
if (root == null) {
throw new NoSuchElementException("root is null");
}
return findMax2(root);
}
public TreeNode findMax2(TreeNode root) {
if (root.right == null) {
return root;
}
return findMax2(root.right);
}2.最小値を見つける
反復実装
バイナリ ツリーの性質により、最小値を見つけるための反復は簡単です。現在のノードの値は、左側のサブツリーのどのノードよりも大きく、右側のサブツリーのどのノードよりも小さいため、最小値を簡単に知ることができます。 node Point はツリーの一番左のノードです。
//查找最小值 ---迭代实现
public int findMin() {
if (root == null) {
throw new NoSuchElementException("root is null");
}
TreeNode temp = root;
while (temp.left != null) {
temp = temp.left;
}
return temp.val;
}再帰的な実装
再帰の実装は実際には比較的簡単で、現在のルート ノードの左の子ノードが空になったときに、左のサブツリーに継続的に再帰し、現在のルート ノードに戻るだけで済みます。
//查找最小值 ---迭代实现
public TreeNode findMin2() {
if (root == null) {
throw new NoSuchElementException("root is null");
}
return findMin2(root);
}
public TreeNode findMin2(TreeNode root) {
if (root.left == null) {
return root;
}
return findMin2(root.left);
}3. 任意の値を見つける
通常の二分木が任意の値を検索する場合、その値が存在するかどうかを確認するために二分木全体を走査する必要がありますが、二分木は依然として二分木の性質であるため、ノードの半分を走査するだけで済みます。現在のノードの値が左のサブツリーのどの値よりも大きい. ノードはすべて右のサブツリーのどのノードよりも大きくて小さい. 値のノードが現在のルート ノードより小さい場合, 再帰的にトラバースする.求める値のノードが現在のルートノードよりも小さい場合 現在のルートノードが大きい場合、右の部分木を再帰的にトラバースし、求める値のノードと等しい場合は直接 true を返しますルート ノードが null の場合は false を直接返します。
//是否包含值为val的结点
public boolean contains(int val) {
return contains(root, val);
}
private boolean contains(TreeNode root, int val) {
if (root == null) {
return false;
}
if (root.val == val) {
return true;
} else if (root.val > val) {
return contains(root.left, val);
}
return contains(root.right, val);
}
4.削除操作
1.最大値を取り除く
下図のような二分探索木で、最大値(つまり7ノード)を削除したい場合、最初に最大ノードの位置を求める必要がありますが、これは最大ノードの位置を求める方法と同じです。最大値、最大値の位置に直接再帰します。この時点で、最大値の左側のサブツリーにはまだノードがある可能性があります。必要なことは、最大値ノードの左側のノード (つまり、現在のノード) を返すことです。ルートノード)、そして前のルートで再帰的に戻る ノードの右側のサブツリーが接続されます。
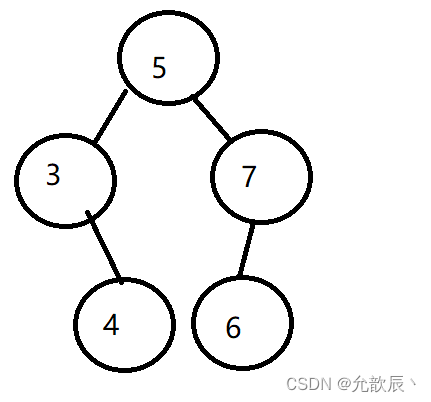
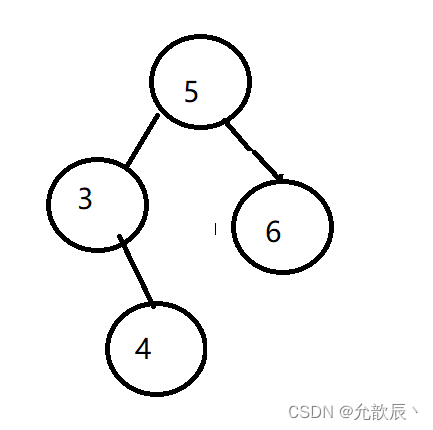
public int removeMax() {
int max = findMax();
root = removeMax(root);
size--;
return max;
}
//删除为root的结点
private TreeNode removeMax(TreeNode root) {
if (root.right == null) {
//当前结点为最大值结点
TreeNode left = root.left;
root.left = root = null;
size--;
return left;
}
root.right = removeMax(root.right);
return root;
}2. 最小値を削除します
最大値を削除する方法と同様に、左の部分木にたどり、最小のノードまでたどり、最小のノードの右の部分木を返し、一度に接続するだけです。
public int removeMin() {
int min = findMin();
root = removeMin(root);
size--;
return min;
}
//删除为root的结点
private TreeNode removeMin(TreeNode root) {
if (root.left == null) {
//当前结点为最大值结点
TreeNode right = root.right;
root.right = root = null;
size--;
return right;
}
root.left = removeMin(root.left);
return root;
}3. 任意の値を削除
任意の値を削除する操作は非常に複雑です. もちろん、以前の任意の値の検索と同じ場所、つまり、削除された値が現在のルート ノードより小さい場合は、左のサブツリーをたどり、削除された値が現在のルート ノードより大きい場合 このとき、右のサブツリーにトラバースしますが、もちろんノードが空である場合もあります (このとき、値が削除されたノードは二分探索木に存在しません)。 、nullを返すだけです。これは、操作を実行しないことと同じです)。
次に検討する必要があるのは、削除するノードを見つけるときの操作で、主に次の状況に分けられます。
- ケース 1: 現在のノード (つまり、削除するノード) の左右のサブツリーが空である
- ケース 2: 現在のノードの左側のサブツリーが空で、右側のサブツリーが空でない場合
- ケース 3: 現在のノードの右側のサブツリーが空で、左側のサブツリーが空でない場合
- 状況 4: 現在のノードの左側のサブツリーも右側のサブツリーも空ではない
ケース 1 の場合は非常にうまく解決できます. null を直接返すだけです. ケース 2 の場合, 左のサブツリーは空です. 右のサブツリーを返すだけでよく, 最小のノードを削除します. ケース 3 の場合, 右のサブツリーは空です. , 左のサブツリーを返すだけでよい. これは最大のノードを削除するのと同じ考え方です. 実際, ケース 1 をケース 2 またはケース 3 に帰属させることができます. なぜなら, ケース 2 とケース 3 は右のサブツリーを返すからです.左のサブツリーは、ケース 1 に対して null を直接返します。これは、ケース 2 またはケース 3 のタイプです。
ケース 4 の場合はもっと複雑です. 実際には、このノードを削除せずに、削除するノード (後続ノード) の位置を置き換えるノードを見つけて、そのノードを返すだけでよいという考え方を変更できます。置換ノード (successor) つまり、削除するノードを置換するためにどのノードを見つける必要があり、二分探索木の構造を破壊してはなりません. このノードは、左部分木の任意の値より大きく、より小さい必要があります右の部分木の任意の値 , 実際には, 置換する左の部分木の最大値または右の部分木の最小値を見つけることです. (例として左の部分木の最大値を取ります) 左を見つけることができます作成したメソッドを使用して削除するノードの子ツリーの最大値 (findMax(root)) を作成し、サクセサーの右の子を (ツリー removeMax(root) の最大値を削除するためのツリー removeMax(root) に接続します)左のサブツリー)、および後続ノードの左の子ノードをルート ノードの左のサブツリーにポイントし、
注: この 2 つの手順は元に戻すことができないため、サクセサーの左の子が root.left を指している場合、removeMax(root) を呼び出すと、間違ったノードのデータ接続が削除される可能性があります。
サイズを変更しないでください -- この時点では、removeMax(root) には既に size が含まれているためです --;
//在bst树中删除任意节点
/**
* @param val
* @return 删除成功返回true, 失败返回false
*/
public void remove(int val) {
root = remove(root, val);
}
/**
* 删除当前树中值为val的结点,没有返回null
*
* @param root
* @param val
* @return
*/
private TreeNode remove(TreeNode root, int val) {
//此时可能树中并不存在val=val的结点
if (root == null) {
return null;
}
//在左子树中进行删除
if (root.val > val) {
root.left = remove(root.left, val);
return root;
} else if (root.val < val) {//在右子树中进行删除
root.right = remove(root.right, val);
return root;
} else {//当前结点就是要删除的结点
if (root.left == null) {
size--;
TreeNode right = root.right;
root.right = root = null;
return right;
}
if (root.right == null) {
size--;
TreeNode left = root.left;
root.left = root = null;
return left;
}
/* //此时都不为空
//寻找左子树的最大值或者右子树的最小值(采用这一种)来替代
TreeNode successor = findMin2(root.right);
//这一步的操作为把successor删除,并且将successor.right与root.right相连接,这两步的顺序不能改变
successor.right = removeMin(root.right);
//不需要size--,因为removeMin中已经进行了这个操作
successor.left = root.left;
root.left = root.right = root = null;
return successor;*/
//左子树的最大值替代
TreeNode successor = findMax2(root.left);
successor.right = removeMax(root.left);
successor.left = root.left;
return successor;
}
}5. その他の操作
1. 印刷操作(toStringの実装)
直接印刷し、レイヤーを印刷します。
@Override
//前序toString打印
public String toString() {
StringBuilder sb = new StringBuilder();
gengerateBSTString(root, 0, sb);
return sb.toString();
}
/**
* 在当前以root为结点的树中,将当前结点的层次和值,拼接到sb对象中
*
* @param root
* @param depth
* @param sb
*/
private void gengerateBSTString(TreeNode root, int depth, StringBuilder sb) {
if (root == null) {
sb.append(generateDepthString(depth) + "null\n");
return;
}
sb.append(generateDepthString(depth).append(root.val + "\n"));
gengerateBSTString(root.left, depth + 1, sb);
gengerateBSTString(root.right, depth + 1, sb);
}
private StringBuilder generateDepthString(int depth) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < depth; ++i) {
sb.append("--");
}
return sb;
}6. 全体的なコードの実装
public class BST {
private class TreeNode {
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val = val;
}
@Override
public String toString() {
return "TreeNode{" +
"val=" + val +
'}';
}
}
private TreeNode root;
private int size;
@Override
//前序toString打印
public String toString() {
StringBuilder sb = new StringBuilder();
gengerateBSTString(root, 0, sb);
return sb.toString();
}
/**
* 在当前以root为结点的树中,将当前结点的层次和值,拼接到sb对象中
*
* @param root
* @param depth
* @param sb
*/
private void gengerateBSTString(TreeNode root, int depth, StringBuilder sb) {
if (root == null) {
sb.append(generateDepthString(depth) + "null\n");
return;
}
sb.append(generateDepthString(depth).append(root.val + "\n"));
gengerateBSTString(root.left, depth + 1, sb);
gengerateBSTString(root.right, depth + 1, sb);
}
private StringBuilder generateDepthString(int depth) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < depth; ++i) {
sb.append("--");
}
return sb;
}
public int removeMax() {
int max = findMax();
root = removeMax(root);
size--;
return max;
}
//删除为root的结点
private TreeNode removeMax(TreeNode root) {
if (root.right == null) {
//当前结点为最大值结点
TreeNode left = root.left;
root.left = root = null;
size--;
return left;
}
root.right = removeMax(root.right);
return root;
}
public int removeMin() {
int min = findMin();
root = removeMin(root);
size--;
return min;
}
//删除为root的结点
private TreeNode removeMin(TreeNode root) {
if (root.left == null) {
//当前结点为最大值结点
TreeNode right = root.right;
root.right = root = null;
size--;
return right;
}
root.left = removeMin(root.left);
return root;
}
//在bst树中删除任意节点
/**
* @param val
* @return 删除成功返回true, 失败返回false
*/
public void remove(int val) {
root = remove(root, val);
}
/**
* 删除当前树中值为val的结点,没有返回null
*
* @param root
* @param val
* @return
*/
private TreeNode remove(TreeNode root, int val) {
//此时可能树中并不存在val=val的结点
if (root == null) {
return null;
}
//在左子树中进行删除
if (root.val > val) {
root.left = remove(root.left, val);
return root;
} else if (root.val < val) {//在右子树中进行删除
root.right = remove(root.right, val);
return root;
} else {//当前结点就是要删除的结点
if (root.left == null) {
size--;
TreeNode right = root.right;
root.right = root = null;
return right;
}
if (root.right == null) {
size--;
TreeNode left = root.left;
root.left = root = null;
return left;
}
/* //此时都不为空
//寻找左子树的最大值或者右子树的最小值(采用这一种)来替代
TreeNode successor = findMin2(root.right);
//这一步的操作为把successor删除,并且将successor.right与root.right相连接,这两步的顺序不能改变
successor.right = removeMin(root.right);
//不需要size--,因为removeMin中已经进行了这个操作
successor.left = root.left;
root.left = root.right = root = null;
return successor;*/
//左子树的最大值替代
TreeNode successor = findMax2(root.left);
successor.right = removeMax(root.left);
successor.left = root.left;
return successor;
}
}
public int getSize() {
return size;
}
public void add(int val) {
this.root = add(root, val);
}
//插入的结点都是和根结点进行比较,如果大于根结点,右子树的插入,如果小于根结点就是左子树的插入
public TreeNode add(TreeNode root, int val) {
//寻找到了插入的位置
if (root == null) {
TreeNode node = new TreeNode(val);
size++;
return node;
} else if (root.val > val) {//此时左子树插入
root.left = add(root.left, val);
return root;
}
//此时左子树插入
root.right = add(root.right, val);
return root;
}
//查找最大值 ---迭代实现
public int findMax() {
if (root == null) {
throw new NoSuchElementException("root is null");
}
TreeNode temp = root;
while (temp.right != null) {
temp = temp.right;
}
return temp.val;
}
//查找最大值 ---递归实现
public TreeNode findMax2() {
if (root == null) {
throw new NoSuchElementException("root is null");
}
return findMax2(root);
}
public TreeNode findMax2(TreeNode root) {
if (root.right == null) {
return root;
}
return findMax2(root.right);
}
//查找最小值 ---迭代实现
public int findMin() {
if (root == null) {
throw new NoSuchElementException("root is null");
}
TreeNode temp = root;
while (temp.left != null) {
temp = temp.left;
}
return temp.val;
}
//查找最小值 ---迭代实现
public TreeNode findMin2() {
if (root == null) {
throw new NoSuchElementException("root is null");
}
return findMin2(root);
}
public TreeNode findMin2(TreeNode root) {
if (root.left == null) {
return root;
}
return findMin2(root.left);
}
//是否包含值为val的结点
public boolean contains(int val) {
return contains(root, val);
}
private boolean contains(TreeNode root, int val) {
if (root == null) {
return false;
}
if (root.val == val) {
return true;
} else if (root.val > val) {
return contains(root.left, val);
}
return contains(root.right, val);
}
}
3. 二分探索木の関連
1. 二分探索木と二重連結リスト
1. トピックの説明
説明
二分探索木を入力し、二分探索木をソート済み二重連結リストに変換します。以下に示すように
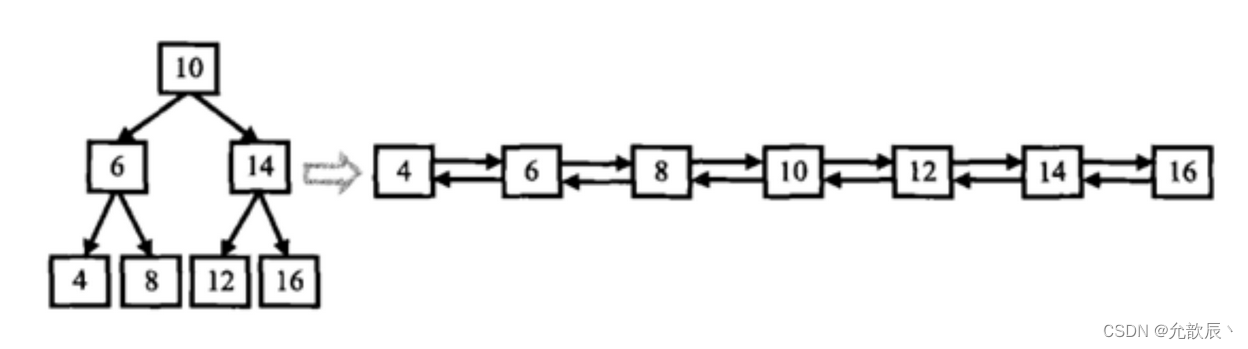
要件: 空間複雑度 O(1) (つまり、元のツリーで操作)、時間複雑度 O(n)
知らせ:
1. 新しいノードを作成できないようにする必要があります。ツリー内のノード ポインタのポイントのみを調整できます。変換が完了した後、ツリー内のノードの左ポインターは先行ノードを指し、ツリー内のノードの右ポインターは後続ノードを指す必要があります 2. リンクされたノードの最初のノードのポインターを返します
。リスト
3. 関数によって返される TreeNode には左右のポインターがあり、実際に見ることができます 双方向リンク リストのデータ構造を形成します 4. 双方向リンク リストを出力する必要はありません。プログラムは自動的に出力しますあなたの戻り値によると
説明を入力してください:
二分木のルートノード
戻り値の説明:
双方向リンク リストのヘッド ノードの 1 つ。
Niuke:二分探索木と二重リンク リスト_Niuke Topic_Niuke.com
2. 問題分析
このタイプの二分木のような問題では、通常、再帰的なアプローチを使用します。
一般的なものから特殊なものまで、このような二分探索木を二重連結リストにするにはどうすればよいでしょうか? このとき、root.left=left, left.right=root, root.right=right, right.left= root ; これは二分探索木に変換できます
実際に、この再帰関数の情報をもう一度分析してみましょう. 戻り値: 返された双方向リンク リストの先頭ノード, パラメータ pRootOfTree は現在のサブツリーのルート ノードです. このとき、接続する必要があるのはルート ノードを左半分の連結リストに接続し、右半分の連結リストに接続すると、この問題は解決できますが、ヌル ポインタの問題に注意する必要があります。左半分の連結リストまたは右半分の連結リストは空で、左半分の連結リストはヘッド ノードを返します。テール ノードを見つけてそれをルート ノードに接続するために、右半分の連結リストはヘッド ノードをルート ノードに直接接続し、最後の戻り値はヘッド ノードを返しますが、ヘッド ノードが空の場合は、現在のルート ノードを返す必要があります (この時点で左半分のリンク リストは null です)。
3. コードの実装
public class Solution {
public TreeNode Convert(TreeNode pRootOfTree) {
if (pRootOfTree == null) {
return null;
}
TreeNode head = Convert(pRootOfTree.left);
TreeNode tail = head;
while (tail != null) {
if (tail.right == null) {
break;
}
tail = tail.right;
}
// 此时tail节点走到了左半链表的尾部
// 2.将左半链表和根节点拼接
if (tail != null) {
// 左子树存在
tail.right = pRootOfTree;
pRootOfTree.left = tail;
}
// 3.转换右子树和根节点拼接
TreeNode right = Convert(pRootOfTree.right);
// 拼接根节点和右半链表
if (right != null) {
right.left = pRootOfTree;
pRootOfTree.right = right;
}
//如果head==null,说明此时左边链表为空,直接返回pRootOfTree
return head == null ? pRootOfTree : head;
}
}2. 昇順配列を平衡二分探索木に変換する
1. トピックの説明
nums要素が昇順整数の配列が与えられた場合、それを高さ調整された二分探索木に変換してください。
高さ平衡二分木は、「各ノードの左右の部分木の高さの差の絶対値が1を超えない」を満たす二分木です。
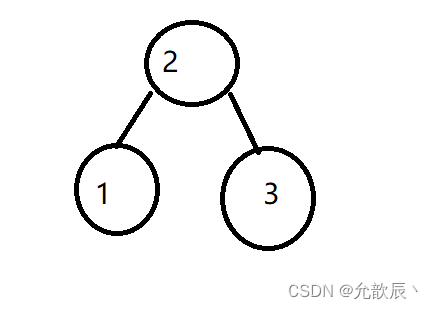
たとえば、入力の昇順配列が [-1,0,1,2] の場合、次の図に示すように、変換された平衡二分探索木 (BST) は {1,0,2,-1} になります。
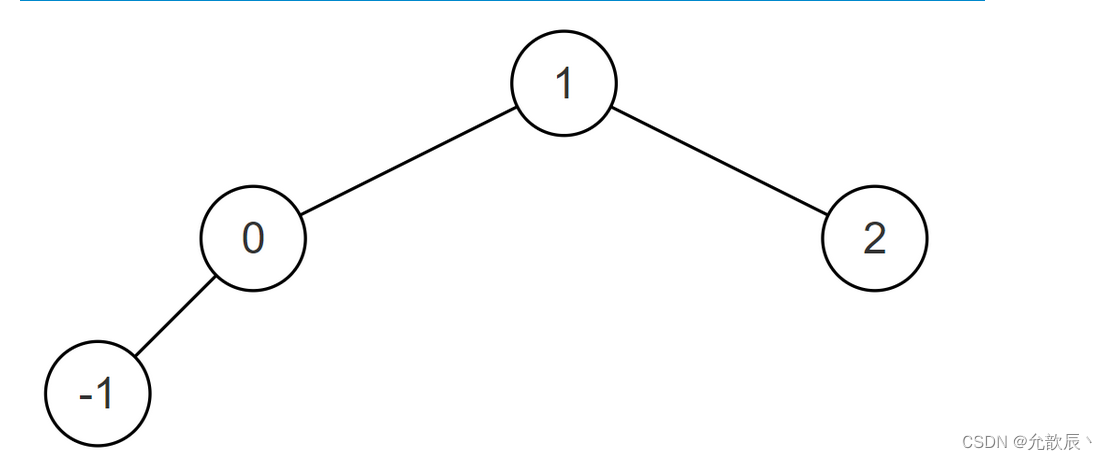
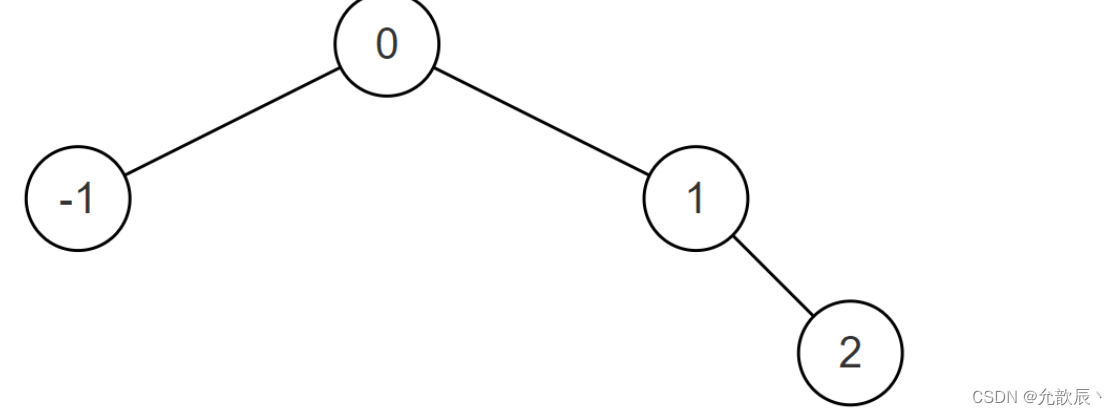
または、以下に示すように {0,-1,1,#,#,#,2}:
2. 問題分析
バランスの取れた二分探索木に変換する必要があります。つまり、左右のサブツリーの高さの差が 1 を超えないようにする必要があります。つまり、配列の中央にある要素をルート ノードとして選択するたびに、 、高さの差が 1 を超えないようにする必要があります。この時点で、新しいメソッドを作成する必要があります。メソッドのパラメーターには配列が含まれている必要があります。左ポインターは左、右ポインターは右で、mid が取得されるたびに、それがルート ノードとして使用されると、左のサブツリーが再帰し、右のサブツリーが左まで再帰します>右が null を返す場合。
3. コードの実装
public class Solution {
/**
*
* @param num int整型一维数组
* @return TreeNode类
*/
public TreeNode sortedArrayToBST (int[] num) {
// write code here
return convert(num, 0, num.length - 1);
}
public TreeNode convert(int[] num, int left, int right) {
if (left > right) {
return null;
}
int mid = left + ((right - left) >> 1);
TreeNode node = new TreeNode(num[mid]);
node.left = convert(num, left, mid - 1);
node.right = convert(num, mid + 1, right);
return node;
}
}