1. タスク紹介
- CIFAR-10 と CIFAR-100 は、 Alex Krizhevsky、Vinod Nair、および Geoffrey Hinton によって収集された画像分類データセットです。CIFAR-10 データセットには、10 のカテゴリに分割された 60,000 の 32x32 カラー画像が含まれており、それぞれに 50,000 のトレーニング画像と 10,000 のテスト画像があります。下。

- CIFAR-10 は、異なる分類ネットワーク間の比較を容易にするために、ネットワーク パフォーマンスの指標としてよく使用されます。その公式ウェブサイトのダウンロード リンクは次のとおりです。ダウンロード速度が遅くなる可能性があり、科学ツールが必要になる場合があります。
CIFAR-10 公式ウェブサイト
Python バージョンのデータをダウンロードします。

2. データを分析する
-
ダウンロードした CIFAR-10 データは、以下に示すように単一のバッチ ファイルです。
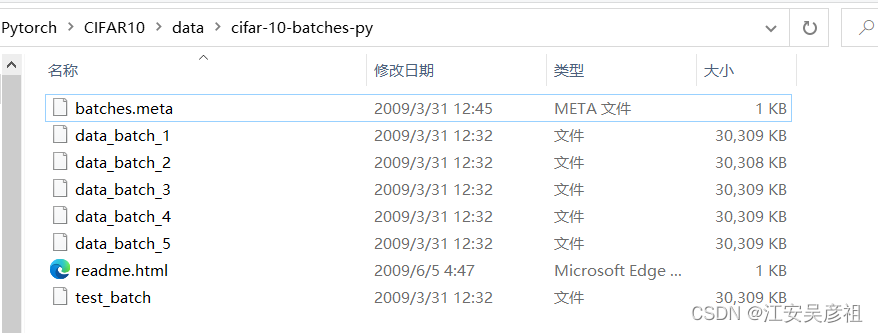
各バッチ ファイルには、10,000 個の画像が含まれています。その中で、data_batch_1 はトレーニング データで、10 クラス、各クラスに 1000 枚の写真が含まれており、test_batch はテスト データで、10 クラス、各クラスに 1000 枚の写真が含まれています。
-
これらの写真は、コンピューターから直接閲覧することはできないため、まず、コンピューターの閲覧に便利な JPG 形式のデータに解析する必要があります。学習済みのネットワークをテストするときは、元の画像を見て理由を調べる必要があるため、直接閲覧できる画像データが存在する必要があります。
-
データを解析するための API は公式 Web サイトで次のように提供されており、解析後に取得される型は python の dict 型です。
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
- フォルダーの下に新しい CIFAR10.py ファイルを作成し、vscode を介してフォルダー全体を開き、ショートカット キーを入力してから、
ctrl + shift + p
次
python:select
のように入力して python インタープリターを選択します。

minicoda の下でインタープリターを選択した後、トーチ ライブラリをインポートできます。次のようにエラーは報告されません:画像データの解析には opencv ライブラリが必要なので、conda を使用して opencv をインストールし、次の図に示すように

コマンドを実行します: 現時点では、実行時にエラーは報告されません。vscode で、opencv が正常にインストールされたことを示します。
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple

import cv2 - 次に、元のファイルの情報を出力する次のコードを記述します。
import torch
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
label_name = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]
import glob
file_list = glob.glob(r"data_batch_*") #获得该目录下与之文件名匹配的文件
for file_i, in file_list,file_list:
print(file_i)
mydict = unpickle(file_i)
print(mydict)
以下の結果が得られます. このとき, CIFAR-10トレーニングファイルのファイル名を取得し, デコード機能によりトレーニングファイルを辞書データにデコードしました. 辞書データを出力することで, それぞれ次の 2 つのコマンド
を追加すると、デコードされた辞書に何が含まれているかを確認できます。
print(mydict.keys())
print(len(mydict))
実行中:

上記の情報から、各バッチ ファイルは画像を辞書として格納し、各辞書のキーと値のキーには、画像のラベル カテゴリ、データ、ファイル名、およびバッチ ラベルを含む 4 つの情報カテゴリが含まれていることがわかります。ディクショナリの値は、画像内の各カテゴリに関する情報を含むリストです。
ディクショナリのラベルに含まれる情報は、次のコマンドで印刷できます。
print(mydict[b'labels'])
print(type(mydict[b'labels']))
print(len(mydict[b'labels']))
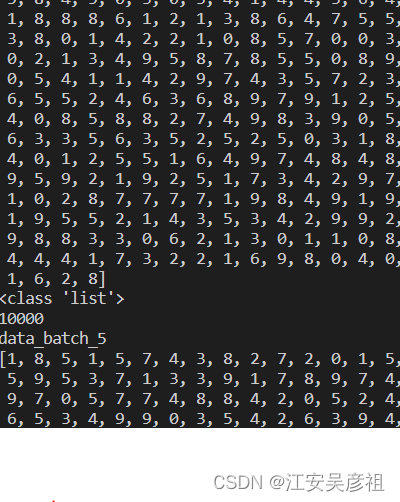
リスト データは labels キー値の下に保存され、リストの長さは 1000 で、リストには画像のカテゴリ番号 0 ~ 9 が含まれ、番号 0 ~ 9 は画像の 10 カテゴリであることがわかります。下図: 各バッチファイルをデコードできるように
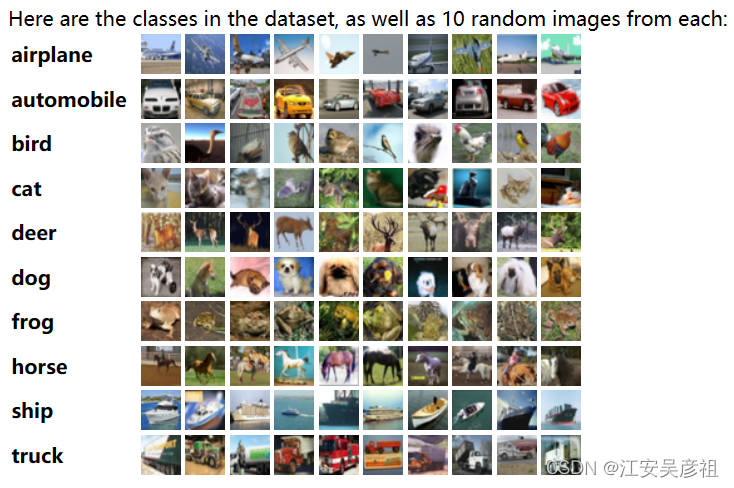
、得られた大量の辞書データを辞書のラベルに従ってフォルダごとに分類し、cv2 の show で画像を表示します. 以下のコードを追加します.
mydict = unpickle(file_i)
for index_i in range(1000):
print(label_name[mydict[b'labels'][index_i]])
print(mydict[b'data'][index_i])
print(mydict[b'filenames'][index_i])
上記のコードは、次のように辞書のリストに対応する画像情報を出力できます.
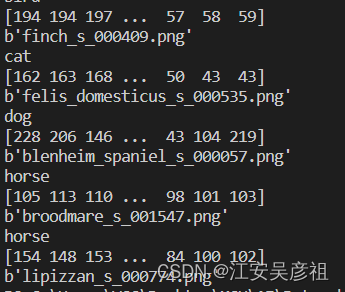
情報から、画像情報が配列として保存されていることがわかります.配列情報を出力します.
print(type(mydict[b'data'][0]))

画像情報が n 次元配列として保存されていることがわかります. numpy を導入し、次のコードで配列情報を観察します:
mydict = unpickle(file_i)
print(mydict[b'data'][0].shape)

配列は3072 1 の配列として保存され、3072 はちょうど 32 32 3 のデータ長であることがわかります。そのうち 32 32 は画像のサイズであり、3 は各ピクセルの RGB 情報の長さです。 numpy reshape データを介して配列を画像に復元できます。
mydict = unpickle(file_i)
img_a = mydict[b'data'][0].reshape(32,32,3)
print(img_a)
得られた:
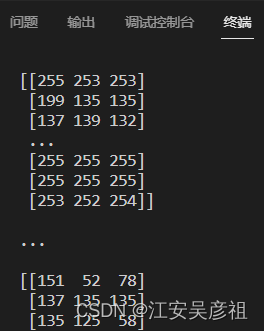
例として画像を取り、画像を表示しましょう:
import torch
import cv2
import numpy as np
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
label_name = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]
import glob
file_list = glob.glob(r"data_batch_*") #获得该目录下与之文件名匹配的文件
for file_i in file_list:
print(file_i)
mydict = unpickle(file_i)
print(mydict[b'data'][0])
img_a = mydict[b'data'][0].reshape(3,32,32) / 255 # CIFAR10数据集在将32*32*3图像拉伸为一维数组时,
# 依次存放1024个R,1024个G,1014个B数据,将其reshape为(3,32,32),则一共有3层,第一层全是R,第二层全是G,第三层全是B
img_a = np.transpose(img_a,(1,2,0)) # 翻转数据,将三层的RGB作为图像的深度
print(img_a)
cv2.imshow("wcc",img_a)
userkey = cv2.waitKey()
上記のコードを実行すると、結果は次のようになります。
ボタンを押して画像を印刷し、画像データを表示します。ここで、単一の画像データの分析が完了しました.次に、コードを変更して、ラベルに従って別のフォルダーに保存するだけで済みます.完全なコードは次のとおりです。
import torch
import cv2
import numpy as np
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
label_name = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]
import glob
import os
file_list = glob.glob(r"data_batch_*") #获得该目录下与之文件名匹配的文件
for file_i in file_list:
print(file_i)
mydict = unpickle(file_i)
for index_i in range(10000):
img_a = mydict[b'data'][index_i].reshape(3,32,32)# CIFAR10数据集在将32*32*3图像拉伸为一维数组时,
# # 依次存放1024个R,1024个G,1014个B数据,将其reshape为(3,32,32),则一共有3层,第一层全是R,第二层全是G,第三层全是B
#由于imwrite时会自动做一次归一化/255,因此这里不除以255进行归一化
img_a = np.transpose(img_a,(1,2,0)) # 翻转数据,将三层的RGB作为图像的深度
label_a = label_name[mydict[b'labels'][index_i]]
a_name = mydict[b'filenames'][index_i]
a_name = a_name.decode("utf8")
# print("IMG_Train/{}/{}".format(label_a,a_name))
if not os.path.exists("IMG_Train/{}".format(label_a)):
os.mkdir("IMG_Train/{}".format(label_a))
cv2.imwrite("IMG_Train/{}/{}".format(label_a,a_name),img_a)
以下の通り:
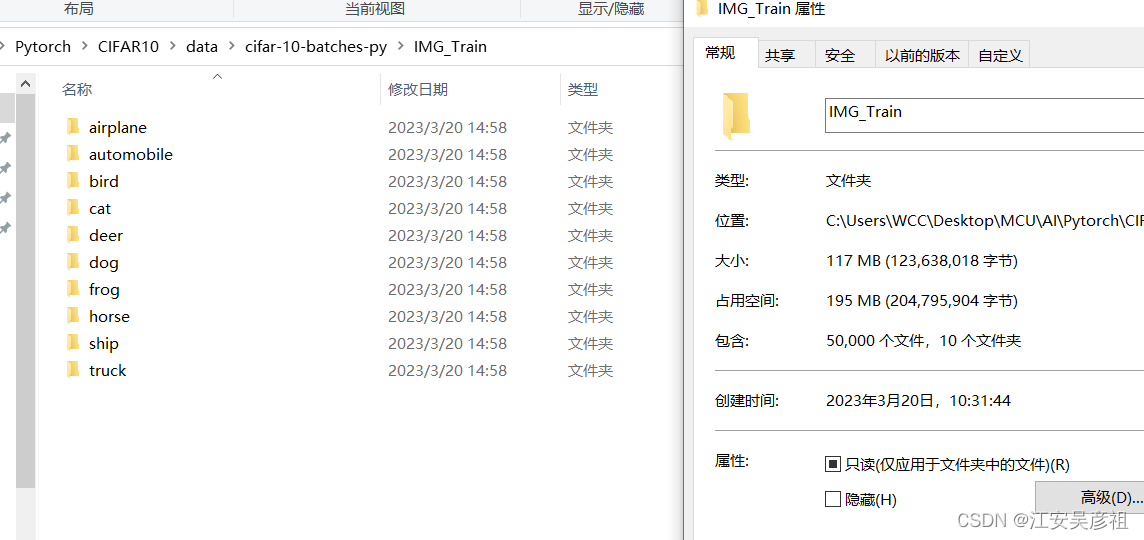
合計 50,000 データが分析されました。
同様に、10,000 個のテスト データを解析できます。