データセット: 1960 年から 2020 年までの世界の国の国内総生産
データ形式:CSV
データソース:世界銀行
実験環境:Jupyter Notebook
ネットワーク ディスク リンク: Baidu ネットワーク ディスク - GDP データ セット
記事ディレクトリ
1.1 依存関係の準備
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
最初に関連する依存関係、データ処理用の pandas/numpy、データ視覚化用の matplotlib.pyplot をインポートします。
1.2 データの準備
データの読み取り このコード行は、CSV ファイルと ipynb ファイルを同じディレクトリに配置する必要があります。
df = pd.read_csv('GDP.csv',encoding = 'utf-8')
データの読み取りが完了すると、データは DataFrame 型として環境に格納されます
1.3 データ観測
(1) データの形状を観察する
df.shape
(266, 65)
(2) データの最初の 5 行を観察します。
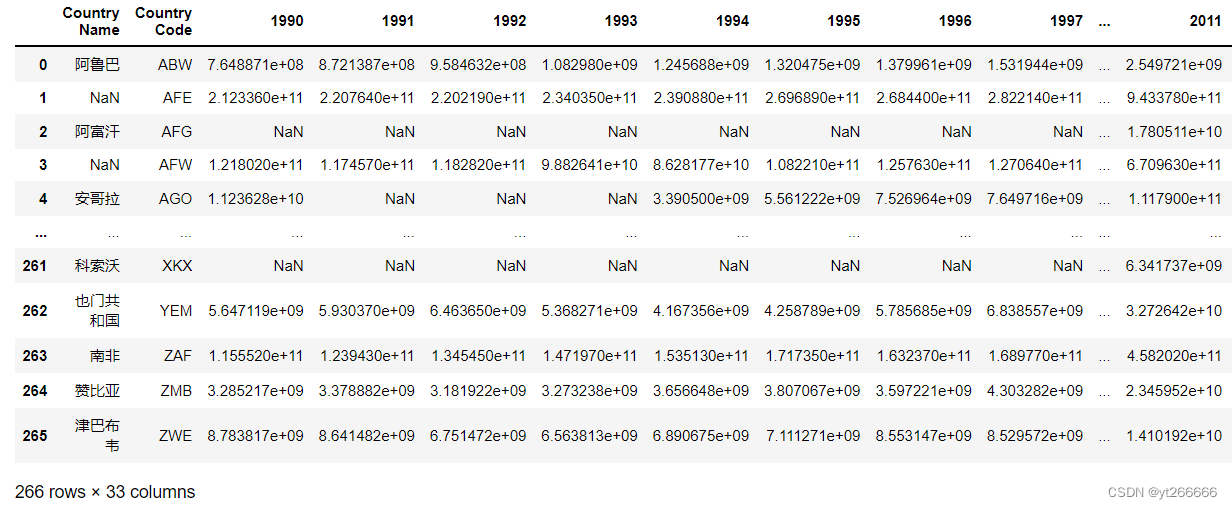
df.head()
| 国の名前 | 国コード | 指標名 | 指標コード | 1960年 | 1961年 | 1962年 | 1963年 |
|---|---|---|---|---|---|---|---|
| アルバ | ABW | GDP (現在の米ドル) | NY.GDP.MKTP.CD | それか | それか | それか | それか |
| それか | AFE | GDP (現在の米ドル) | NY.GDP.MKTP.CD | 1.93E+10 | 1.97E+10 | 2.15E+10 | 2.57E+10 |
| アフガニスタン | AFG | GDP (現在の米ドル) | NY.GDP.MKTP.CD | 5.38E+08 | 5.49E+08 | 5.47E+08 | 7.51E+08 |
| それか | AFW | GDP (現在の米ドル) | NY.GDP.MKTP.CD | 1.04E+10 | 1.11E+10 | 1.19E+10 | 1.27E+10 |
| アンゴラ | 前 | GDP (現在の米ドル) | NY.GDP.MKTP.CD | それか | それか | それか | それか |
(3)観測データ列名一覧
df.columns
Index(['Country Name', 'Country Code', 'Indicator Name', 'Indicator Code',
'1960', '1961', '1962', '1963', '1964', '1965', '1966', '1967', '1968',
'1969', '1970', '1971', '1972', '1973', '1974', '1975', '1976', '1977',
'1978', '1979', '1980', '1981', '1982', '1983', '1984', '1985', '1986',
'1987', '1988', '1989', '1990', '1991', '1992', '1993', '1994', '1995',
'1996', '1997', '1998', '1999', '2000', '2001', '2002', '2003', '2004',
'2005', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013',
'2014', '2015', '2016', '2017', '2018', '2019', '2020'],
dtype='object')
(4) 各列のデータ型を観察する
df.dtypes
Country Name object
Country Code object
Indicator Name object
Indicator Code object
1960 float64
...
2016 float64
2017 float64
2018 float64
2019 float64
2020 float64
(5) 観測結果
上記のコードと実行結果を組み合わせると、
- 2 次元データの合計は 266 行 65 列です。
- データの最初の 4 列は、国と指標を説明しています
- 後続の列はすべて年データ型で、浮動小数点数 (float64) です。
- 各行は国のエンティティです
1.4 データクリーニング
データの観察が完了したら、データ セットの全体的な印象を把握してから、データのクリーニングを実行します。
(1) 無駄なフィールドを削除する
loc 関数を使用して別々にスライスし、データセットから 2 列のデータを抽出します
useless_column = df.loc[:,['Indicator Name','Indicator Code']]
その前後の3行に注目
| 索引 | 指標名 | 指標コード |
|---|---|---|
| 0 | GDP (現在の米ドル) | NY.GDP.MKTP.CD |
| 1 | GDP (現在の米ドル) | NY.GDP.MKTP.CD |
| 2 | GDP (現在の米ドル) | NY.GDP.MKTP.CD |
| 263 | GDP (現在の米ドル) | NY.GDP.MKTP.CD |
| 264 | GDP (現在の米ドル) | NY.GDP.MKTP.CD |
| 265 | GDP (現在の米ドル) | NY.GDP.MKTP.CD |
エンティティごとに同じ値が繰り返され、データ マイニングのための差別化された/貴重な情報を提供できないため、列全体を直接削除します。
print("进行删除前数据集的列数为:"+str(df.shape[1]))
df.drop(labels = 'Indicator Name',axis = 1,inplace = True)
df.drop(labels = 'Indicator Code',axis = 1,inplace = True)
print("完成删除后数据集的列数为:"+str(df.shape[1]))
(2) 欠損値の特定
関数 isnull を使用して、テーブル内の null 値の数を決定します
df.isnull().sum()
Country Name 2
Country Code 0
Indicator Name 0
Indicator Code 0
1960 138
...
2016 10
2017 10
2018 10
2019 13
2020 24
欠損値の数をより直感的に観察するために画像を描画します
x = np.arange(0, df.shape[1])## 生成x轴数据
y = list(df.isnull().sum())## 生成y轴数据
plt.figure(figsize=(16,7))## 设置画布
plt.subplot(1, 2, 1)
## 原图
plt.plot(x,y)## 绘制sin曲线图
plt.title('列缺失值数目')
# plt.savefig('gen_pics/缺失值曲线.png')
plt.xlabel('列索引')## 添加横轴标签
plt.subplot(1, 2, 2)
x = np.arange(0, df.shape[1])## 生成x轴数据
y = list(i/df.shape[0] for i in df.isnull().sum())## 生成y轴数据
## 绘制散点1
plt.bar(x,y)
plt.xlabel('列索引')## 添加横轴标签
plt.title('列缺失值占比')
plt.show()
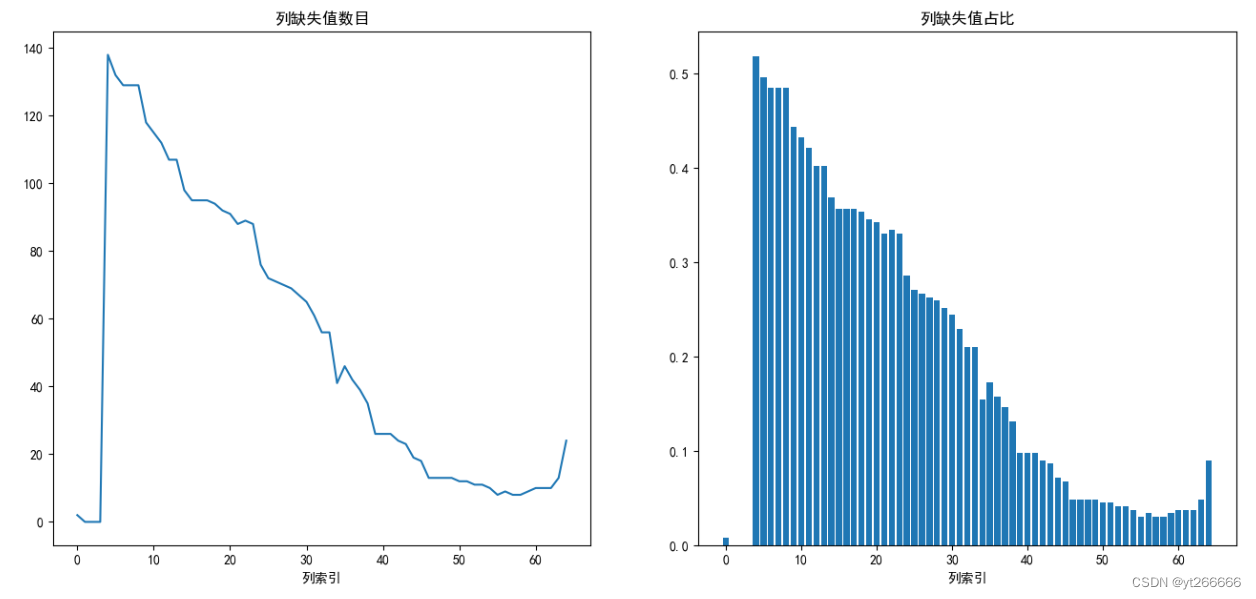
ほぼすべての列に欠損値があることが判明し、1960年から1970年の間でもGDPデータの欠損値の割合は40%を超えていました
(3) 欠落している行と列を削除しすぎる
欠損値が 20% を超える列を直接削除するように設定します
ここでの削除の数は、主に方法を示すには多すぎる可能性があります。
for name in df.columns:
if (df[name].isnull().sum()/df.shape[0])>0.2:
df.drop(labels = name,axis = 1,inplace = True)
現在のデータセットは、1990 年から 2020 年までの各国の GDP データの欠損値の割合を保持しており、いずれも 20% 未満です。
列の欠損値をもう一度観察します
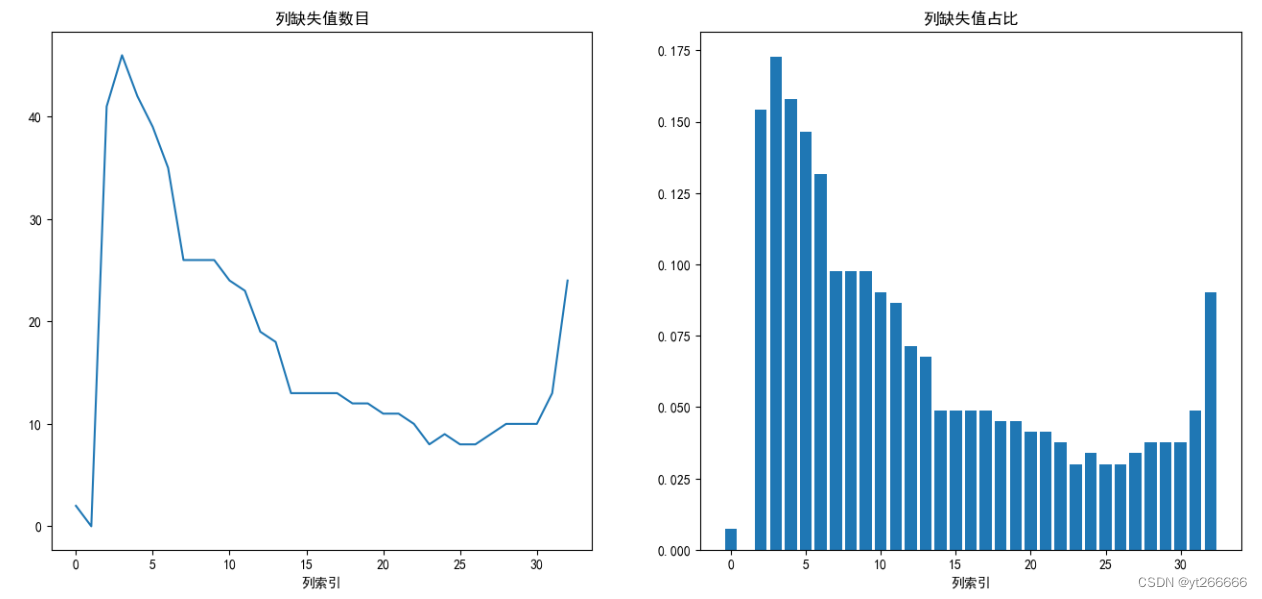
欠損値の状況が以前よりもはるかに良くなっていることが感じられます。
行に対して上記と同じことを行い、欠損値が多すぎる国を削除します。
(4) 欠損値を埋める
線形補間のキーコードは次のとおりです。
# 对列进行前向线性插值
df = df.interpolate(method='linear', axis=0,inplace=False,limit_direction='forward')
# 对列进行后向线性插值
df = df.interpolate(method='linear', axis=0,inplace=False,limit_direction='backward')
データ型の変換は、数値型でのみ補間できることに注意してください。
(5)外れ値の確認
データの数値分布は、ほぼ全て区間(μ-3σ、μ+3σ)に集中しており、3σを超える部分は異常データと考えられます。
for name in df.columns:
min_GDP = df[0] < (df[0].mean() - 3*df[0].std())
max_GDP = df[0] > (df[0].mean() + 3*df[0].std())
GDP_fit = min_GDP | max_GDP
print(df.loc[GDP_fit,0])
箱ひげ図を使用して外れ値をより直感的に観察することもできます
label= ['南非','阿根廷','津巴布韦']## 定义标签
gdp = (list(b[263]),list(b[9]),list(b[265]))
plt.figure(figsize=(6,4))
plt.boxplot(gdp,labels = label)
plt.title('国民生产总值箱线图')
plt.show()
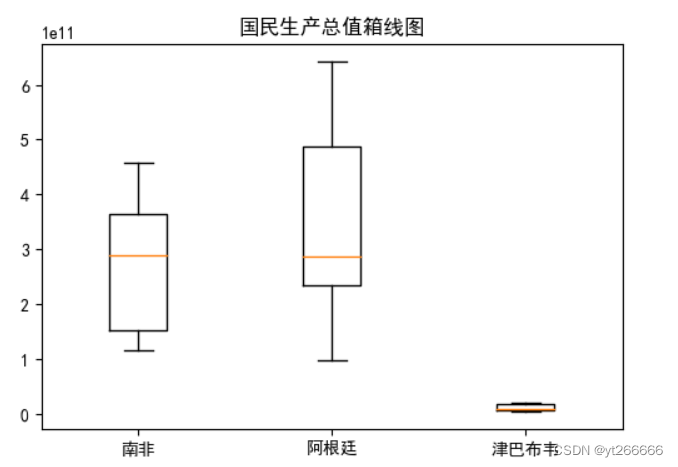
外れ値が見つかった場合、それらは削除または平滑化されます。
(6) 残りのステップ
このデータ セットは高品質です。完全なデータ クリーニングには、残りの手順も含める必要があります。
- 世界の合計を超える国の GDP 値など、不合理な値を削除する
- GDP フィールドに入力されたテキストなどのシンボル エラーを削除します。
- 繰り返される行と列を削除します。たとえば、1 年の GDP は 2 回カウントされます
- 相関検定、各フィールド間の相関を計算します。
- 等