映画のデータに基づいて、pyecharts を使用して視覚的な分析を行います。
データ紹介
import pandas as pd
data=pd.read_csv('./电影.csv')
data.head()
データの最初の 5 行は次のとおりです。

インストールする必要がある python ライブラリ
pip install pandas
pip install pyecharts
データクリーニング
欠損値を表示する
data.isnull().sum()
一部の映画は脚本家や主演がいないため、クロールされませんでしたが、データの分析や可視化には影響しません。

前回のデータ紹介からわかるように、現在のところ、取得したデータの各フィールドをクリーンアップする必要はありません。この部分はスキップしてください。(絵文字を追加したいのですが、追加する場所が見つかりません。)
データの視覚化
公開年と作品数
Year=data['上映年份'].value_counts().reset_index()
Year.rename(columns={
"index":"上映年份","上映年份":"电影数量"},inplace=True)
Year.head()
Jupyter Notebook で実行しています. 他のエディタで実行してコードbar.render_notebook()の最後の行をbar.render("xxx.html"), 操作が成功するとファイルが生成されますxxx.html. 開くとビジュアルチャートが表示されるはずです. 以降のコードは同じです。
パイチャートのインポート
from pyecharts.charts import Bar,Pie,Line
import pyecharts.options as opts
bar = (
Bar(init_opts=opts.InitOpts(height='700px', theme='light'))
.add_xaxis(
Year['上映年份'].tolist()[::-1])
.add_yaxis(
"电影数量",
Year['电影数量'].tolist()[::-1],
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts(itemstyle_opts=opts.ItemStyleOpts(
border_color='#5C3719', ))
.set_global_opts(
title_opts=opts.TitleOpts(
title='上映年份及电影数量',
subtitle='截止2023年3月',
title_textstyle_opts=opts.TextStyleOpts(
font_family='Microsoft YaHei',
font_weight='bold',
font_size=22,
),
pos_top='1%'),
legend_opts=opts.LegendOpts(is_show=True),
xaxis_opts=opts.AxisOpts(
# name='电影数量',
is_show=True,
max_=int(Year['电影数量'].max()),
axislabel_opts=opts.LabelOpts(
font_family='Microsoft YaHei',
font_weight='bold',
font_size='14' #标签文本大小
)),
yaxis_opts=opts.AxisOpts(
# name='上映年份',
is_show=True,
axislabel_opts=opts.LabelOpts(
#interval=0,#强制显示所有y轴标签,需要可以加上
font_family='Microsoft YaHei',
font_weight='bold',
font_size='14' #标签文本大小
)),
tooltip_opts=opts.TooltipOpts(
is_show=True,
trigger='axis',
trigger_on='mousemove|clike',
axis_pointer_type='shadow',
),
toolbox_opts=opts.ToolboxOpts(is_show=True,
pos_left="right",
pos_top="center",
feature={
"saveAsImage":{
}}
)
).reversal_axis())
bar.render_notebook()
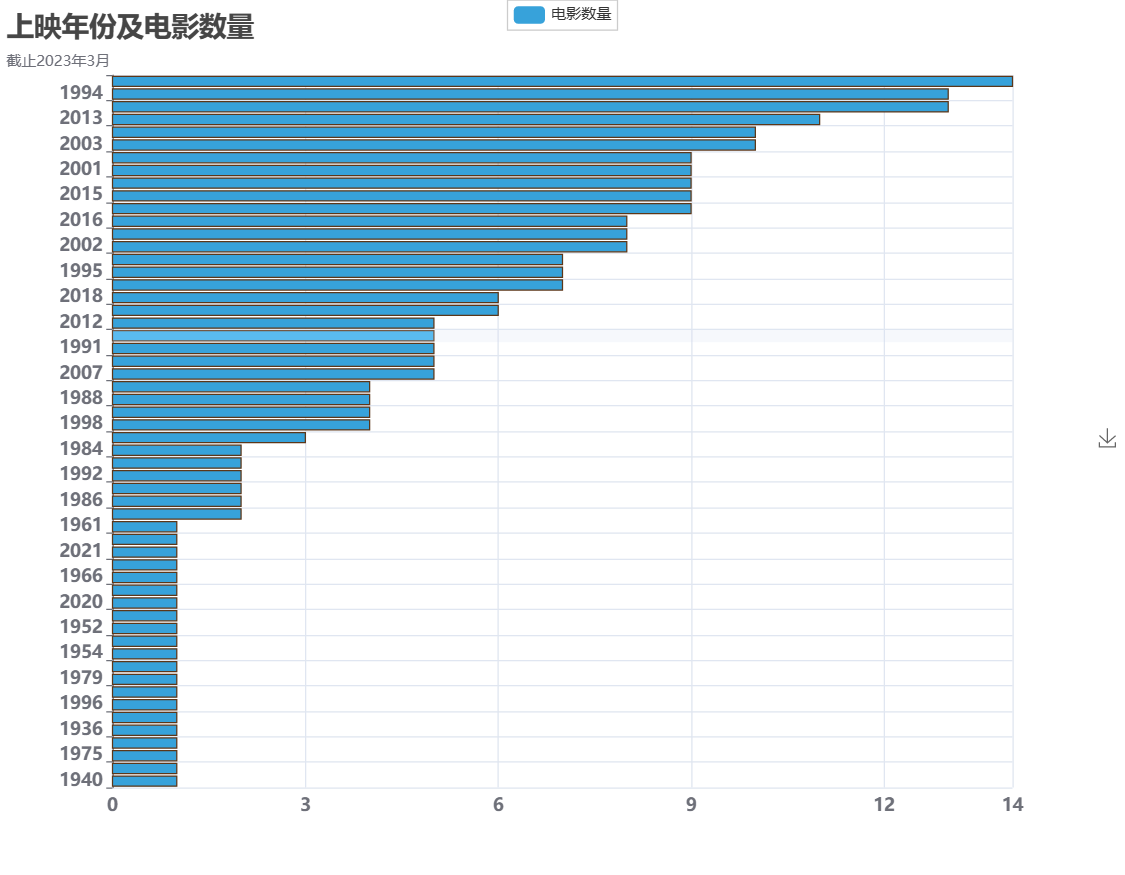
ここでは、すべての Y 軸ラベルを表示するように設定していません。コードは、すべての Y 軸ラベルを強制的に表示するようにコメントを付けています。チャートによると、2010 年に公開された映画の最大数は 14 本でした。
トップ10の監督と映画の数
Director=data['导演'].value_counts()[0:11].reset_index()
Director.rename(columns={
"index":"导演","导演":"电影数量"},inplace=True)
Director.head()
pie = (
Pie(init_opts=opts.InitOpts(theme='light'))
.add(
series_name='电影类型',
data_pair=[list(z) for z in zip(Director['导演'].to_list(), Director['电影数量'].to_list())],
radius=["40%", "75%"],
)
# .set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(
title_opts=opts.TitleOpts(
title="导演及电影数量",
subtitle='TOP10',
title_textstyle_opts=opts.TextStyleOpts(
font_family='Microsoft YaHei',
font_weight='bold',
font_size=22,
),
),
legend_opts=opts.LegendOpts(
pos_left="left",
pos_top="center",
orient='vertical',
is_show=True
),
toolbox_opts=opts.ToolboxOpts(
is_show=True,
pos_left="right",
pos_top="center",
feature={
"saveAsImage":{
}}
)
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render_notebook()
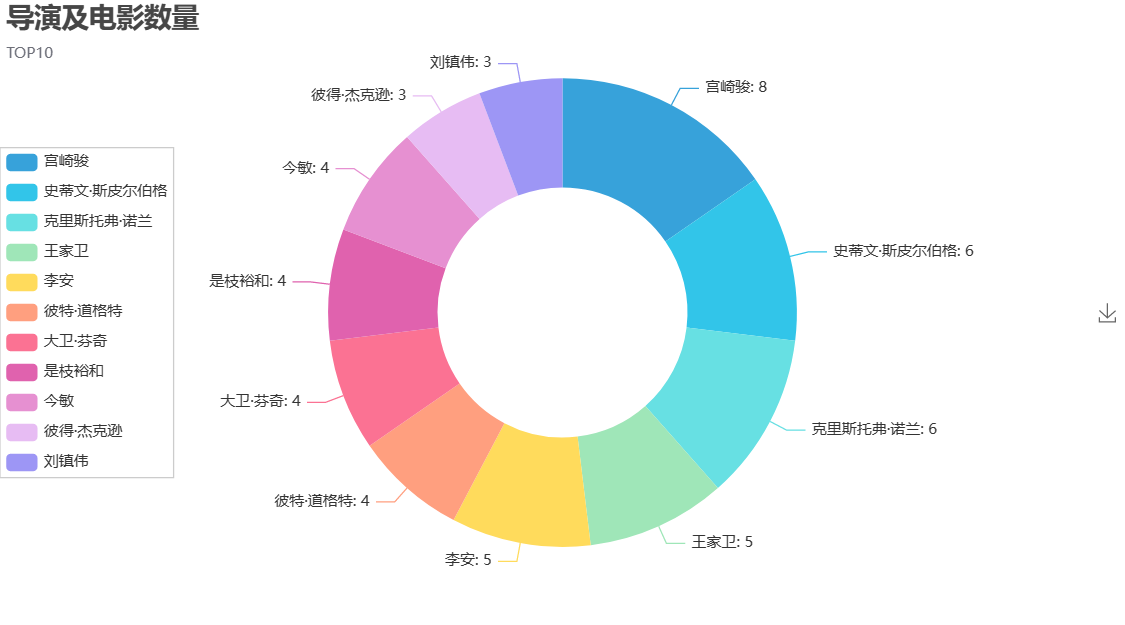
これは TOP10 データのみを取得します。さらにデータを取得する場合は、変更します
Director=data['导演'].value_counts()[0:11].reset_index()
[0:10] はインデックス 0 からインデックス 9 までフェッチすることを意味し、自分で変更できます。
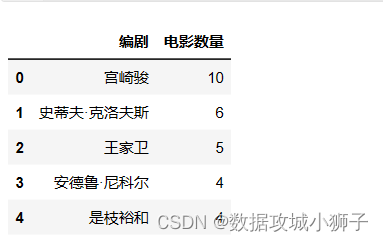
トップ10の脚本家と映画の数
Screenwriter=data['编剧'].value_counts()[0:11].reset_index()
Screenwriter.rename(columns={
"index":"编剧","编剧":"电影数量"},inplace=True)
Screenwriter.head()
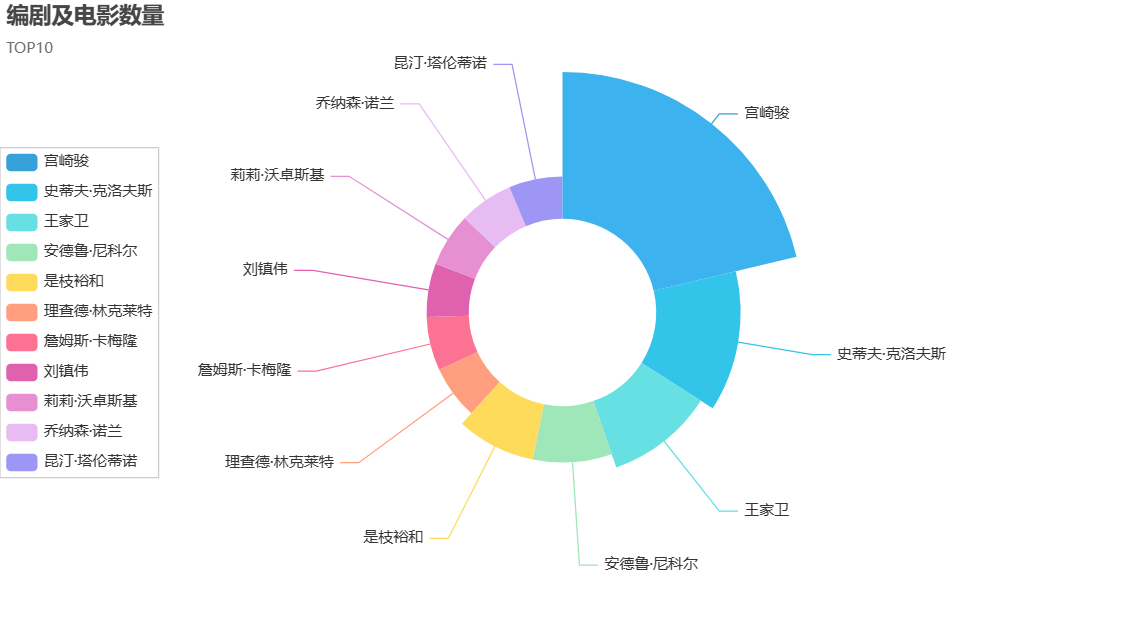
c = (
Pie(init_opts=opts.InitOpts(theme='light'))
.add(
"",
[list(z) for z in zip(Screenwriter['编剧'].to_list(), Screenwriter['电影数量'].to_list())],
radius=["30%", "75%"],
rosetype="radius",
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="编剧及电影数量",
subtitle='TOP10',
),
legend_opts=opts.LegendOpts(
pos_left="left",
pos_top="center",
orient='vertical',
is_show=True,
)
)
)
c.render_notebook()
映画の長さと数
Film_length=data['片长'].value_counts().sort_index().reset_index()
Film_length.rename(columns={
"index":"片长","片长":"电影数量"},inplace=True)
Film_length
c = (
Bar()
.add_xaxis(Film_length['片长'].to_list())
.add_yaxis(
"电影数量", Film_length['电影数量'].to_list(),
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(title_opts=opts.TitleOpts(title="电影片长及数量"))
)
c.render_notebook()
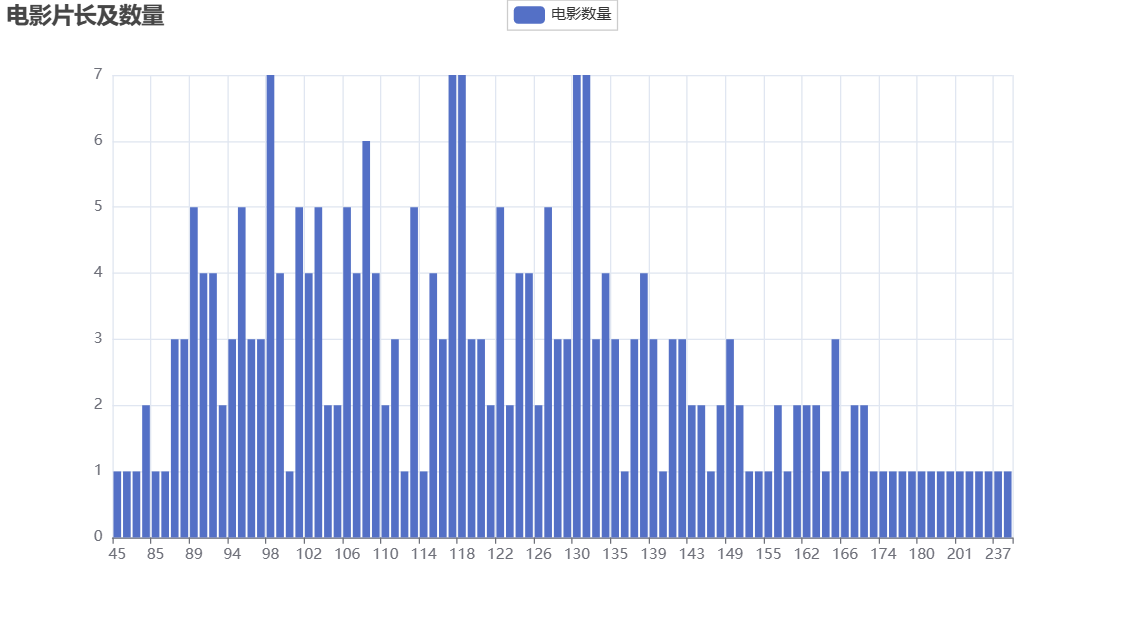
映画の長さは、最短が45分、最長が238分で、主に98~132分あたりに集中しています。映画の質は長さとは関係なく、主なものは内容だと思います。
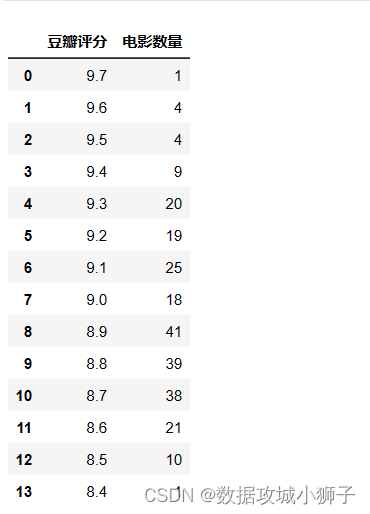
映画の評価と数量
Douban_score=data['豆瓣评分'].value_counts().sort_index(ascending=False).reset_index()
Douban_score.rename(columns={
"index":"豆瓣评分","豆瓣评分":"电影数量"},inplace=True)
Douban_score
Line()
.set_global_opts(
title_opts=opts.TitleOpts(title="电影豆瓣评分及数量"),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.add_xaxis(xaxis_data=Douban_score['豆瓣评分'])
.add_yaxis(
series_name="电影数量",
y_axis=Douban_score['电影数量'],
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=opts.ItemStyleOpts(
color="red"),
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(type_="max",name="最大值")]
)
)
)
c.render_notebook()
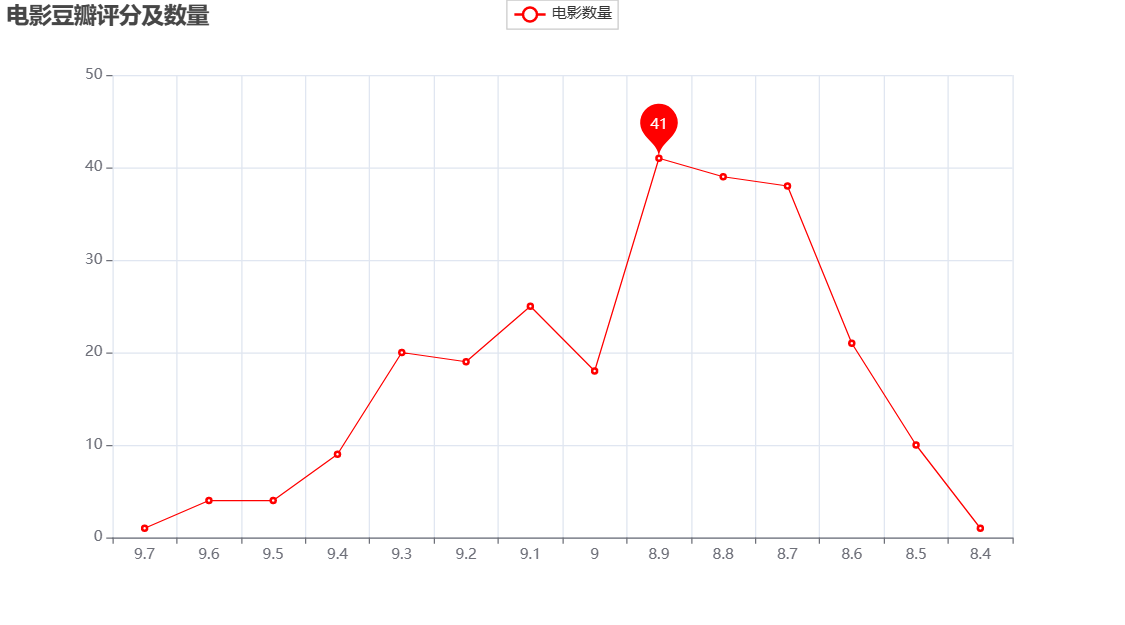
Douban が 8.9 点で最もスコアが高く、合計 41 本の映画がこのスコアを獲得したことがわかります。好みは人それぞれで、自分が良いと思った映画でも、他の人にとってはそうでもないかもしれません。これは、高評価の映画を維持することの価値も反映しています。
この記事は最初にここに書いて、後で更新します. pyecharts には多くの構成があります. 具体的には、公式 Web サイトのドキュメントに従って、必要なスタイルにチャートを変更できます.