1. ニューラル ネットワーク モデル
ニューラルネットワーク(Neural Networks)は、人間の脳の神経系を微細構造と機能の観点からシミュレートして確立された数学的モデルであり、人間の脳の思考をシミュレートする能力を持っています.セックスなどをシミュレートする重要な方法です.人間の知性。ニューラル ネットワークは、情報を受け取って処理できるニューロンの相互接続によって形成されます。この情報処理は、主にニューロン間の相互作用、つまりニューロン間の結合重みによって処理および実現されます。ニューラル ネットワークは、人工知能、自動制御、コンピューター サイエンス、情報処理、パターン認識などの分野で非常にうまく使用されています。
生物学的ニューロンの構造と基本機能によると、次の図の形に簡略化でき、ニューラル ネットワーク モデルの基礎 - 人工ニューロン数学モデル:
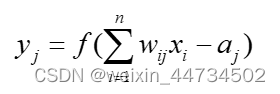
このうち、 はニューロン j の出力を表し、 は
ニューロン i の入力を表し、
はニューロン間の結合重みを表し、
はニューロンの閾値を表し、
は入力から出力への伝達関数 (活性化関数とも呼ばれます) を表します。
Sigmod は、次の例でよく使用される一般的なアクティベーション関数です。
2. ニューラル ネットワーク モデル BP アルゴリズム
2.1 ネットワーク構造と動作モード
ユニットの特性に加えて、ネットワークのトポロジーも NN の重要な特性です。接続方法に関して、NN には主に 2 つのタイプがあります。
(i) フィードフォワード ネットワーク
各ニューロンは前の層から入力を受け取り、フィードバックなしで次の層に出力します。ノードは、入力ユニットと計算ユニットの 2 つのカテゴリに分けられます。各計算ユニットは、任意の数の入力を持つことができますが、出力は 1 つだけです (入力として任意の数の他のノードに結合できます)。通常、フィードフォワード ネットワークはさまざまな層に分割できます. i 番目の層の入力は i-1 番目の層の出力にのみ接続され、入力ノードと出力ノードは外部の世界に接続されますが、他の中間層は隠れ層と呼ばれます。
(ii) フィードバックネットワーク
すべてのノードは、外界への入出力も受け入れることができるコンピューティング ユニットです。NN の作業プロセスは主に 2 つの段階に分けられます: 第 1 段階は学習期間で、この時点で各計算ユニットの状態は変更されず、各接続の重みは学習によって変更できます。第 2 段階は作業です。期間、この時点で、各接続の重みは固定され、計算ユニットの状態は変化して特定の安定状態を達成します。
効果の観点から、フィードフォワード ネットワークは主に関数マッピングであり、パターン認識と関数近似に使用できます。エネルギー関数の極小点の利用に応じて、フィードバック ネットワークには 2 つのタイプがあります: 1 つ目は、エネルギー関数のすべての極小点が機能するタイプで、このタイプは主にさまざまな連想メモリとして使用されます。グローバル 最低限、主に最適化問題を解決するために使用されます。
(iii) バックプロパゲーション アルゴリズム (Back-Propagation)
フィードバック ネットワークで言及されている各リンクの重みの変更には、バック プロパゲーション アルゴリズム (Back-Propagation) が主に使用されます。これは、3層 BP ニューラル ネットワーク モデルのコア部分でもあります。
学習サンプルに対応する出力が非常に正確であることを願っていますが、実際には不可能であり、実際の出力が理想的な出力にできるだけ近いことを願うしかありません。明確にするために、サンプル s に対応する理想的な出力を として示し、次に
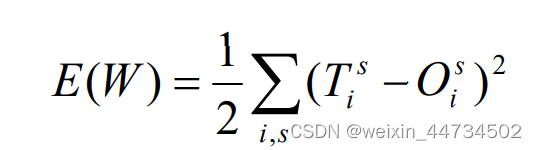
これは、与えられた一連の重みの下で実際の出力と理想的な出力との差を測定します. したがって、適切な一連の重みを見つける問題は、当然、E(W ) を最小化できるように適切な W の値を見つけることになります. .
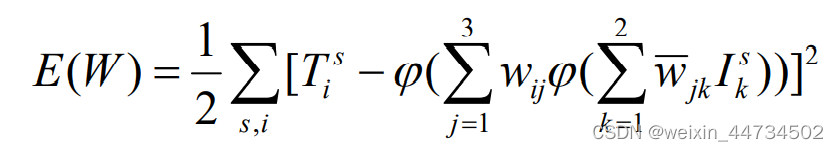
各変数または について、これは連続微分可能な非線形関数であることは簡単にわかります。その最小点と最小値を取得するには、最も便利な方法は最急降下法を使用することです。最急降下法は反復アルゴリズムです. E(W ) の (局所的な) 最小値を見つけるために, 任意の初期点から開始し,その点における負の勾配方向 -∇E ( )を計算します. これは関数です. in この時点で最も速く下降する方向; ∇E( ) ≠ 0 である限り、この方向に沿って少し移動して新しい点に到達できます W1 = W0 −η∇E ( ), η はパラメーターです。 η が十分に小さい限り、E( W1) < E ( ) を保証できなければなりません。このプロセスを絶えず繰り返すと、E の (ローカル) 最小点に到達する必要があります。本質的に、これが BP アルゴリズムのすべてです。
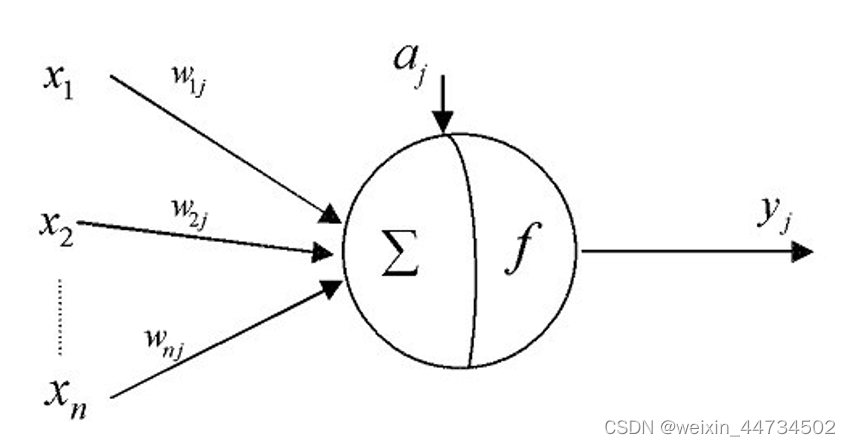
2.2 BP ニューラルネットワークのトポロジーを図に示します。
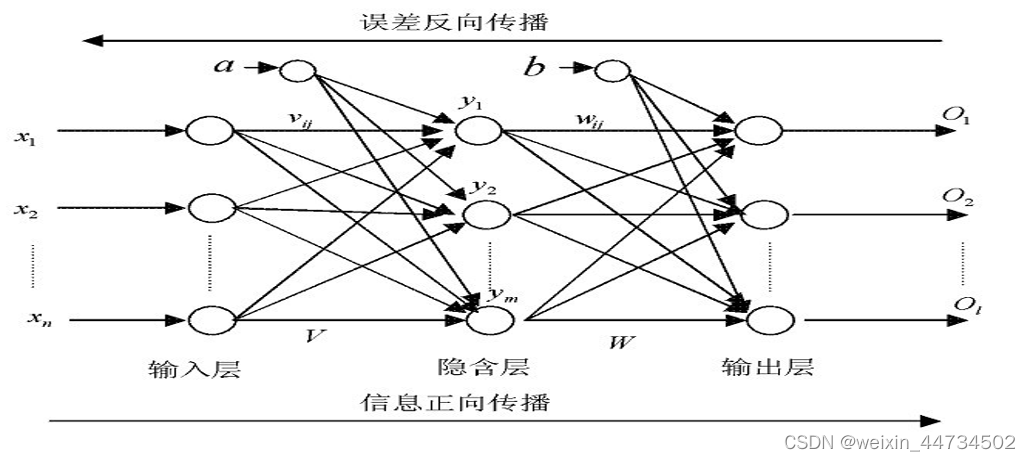
その中で、はニューラル ネットワークの (実際の) 入力、
は隠れ層の出力、つまり出力層の入力、
ネットワークの (実際の) 出力、a、b は隠れ層のしきい値です。層と出力層のニューロン (ノード) はそれぞれ、
入力層から隠れ層への重み、および隠れ層から出力層への重みです。つまり、図に示した BP ニューラル ネットワークでは、入力層のニューロン (ノード) の数は n、中間層のニューロン (ノード) の数は m、ニューロン (ノード) の数は) は出力層の l であり、この構造はnml構造の 3 層 BP ニューラル ネットワークと呼ばれます。
2.3 BP ニューラル ネットワークの学習アルゴリズムとプロセス (3 層の BP ニューラル ネットワークを例にとると)


3. BP ニューラル ネットワーク アルゴリズムの一般的なツールボックス機能
3.1 newff——BPニューラルネットワークパラメータ設定機能
関数関数: BP ニューラル ネットワークを構築します。
関数形式: net=newff(PR,[S1,S2,…,SN],{TF1,TF2,…,TFN},BTF,BLF,PF)
このうち、PR:サンプルデータからなる行列、最大値と最小値からなるR×2次元の行列。
Si: i層のノード数、合計 N 層。
TFi:線形伝達関数purelin、タンジェント S 型伝達関数 tansig、対数 S 型伝達関数 logsig を含むi層ノードの伝達関数。デフォルトは「tansig」です。
BTF: ネットワークの重みとしきい値を調整するために使用されるトレーニング関数。デフォルトは、Levenberg_Marquardt 共役勾配法のトレーニング関数 trainlm に基づいています。その他のパラメータについては、次の表を参照してください。
BLF: BP学習ルールlearngdを含むネットワークの学習関数; モメンタム項目を持つBP学習ルールlearngdm。デフォルトは「learndm」です。
PF: 平均絶対誤差パフォーマンス分析関数 mae、平均二乗パフォーマンス分析関数 mse を含む、ネットワークのパフォーマンス分析関数。デフォルトは「mse」です。
通常、最初の 4 つのパラメータは使用中に設定され、後の 2 つのパラメータはシステムのデフォルト パラメータを採用します。
例: net=newff([-1,1],[5,1],{'tansig','purelin'});
その中で、[-1,1] は入力ベクトルの最小値と最大値を示し、minmax(p) も使用できます; [5,1] は隠れ層が 5 セクションで、出力層が 1 であることを示します。セクション; tansig、purelin 分布は隠れ層と出力層の伝達関数を示します。
3.2 トレーニング——BP ニューラル ネットワーク トレーニング機能
関数 function: トレーニング関数を使用して BP ニューラル ネットワークをトレーニングします。
関数形式: [net,tr]=train(NET,P,T)
NET: トレーニングされるネットワーク、つまり、newff によって作成された最初のネットワーク。
P: 入力データ行列;
T: 期待される出力データ マトリックス。
net: 訓練されたネットワーク。
tr: 訓練過程記録。
例:

3.3 sim——BPニューラルネットワークの予測・シミュレーション機能
関数関数: トレーニング済みの BP ニューラル ネットワークを使用して、関数の出力を予測/シミュレートします。
関数形式: Y=sim(net,x)
net: 訓練された BP ニューラル ネットワーク。
x: 入力データ。
Y: ネットワーク予測/シミュレーション データ、つまり、ネットワークの実際の出力。
例
net=train(net,P,T); %Network トレーニング関数、net in train は最初に作成されたネットワークです
Y=sim(net,P); %P は入力ベクトル、Y はシミュレーション結果
plot(P,T,'-',P,Y,'o'); %T は元の出力で、元の結果とシミュレーション結果をグラフに描画します。
4. 予測
4.1 分類問題
例 1生物学者は、アンテナと翼の長さのデータに基づいて 2 種類のユスリカ (Af と Apf) を識別しようとします. 9 Af と 6 Apf のデータは次のように測定されました. Af: (1.24,1.27) Apf : (1.14,1.82), (1.18,1.96), (1.20,1.86), (1.26,2.00), (1.28,2.00), (1.30,1.96).
問題は次のとおりです。
(i) 上記の情報に基づいて、2 種類のユスリカを正しく区別する方法を開発する方法。
(ii) 得られた方法を使用して、触角と翼の長さが (1.24、1.80)、(1.28、1.84)、および (1.40、2.04) の 3 つの標本を特定しました。
上記の問題は代表的なものであり、その特徴は、既知の情報(Af の 9 枝のデータと -353-Apf の 6 枝のデータ)に基づいて分類方法を策定する必要があり、カテゴリがすでに与えられていることです(Afまたは Apf )。今後は、9 Af と 6 Apf のデータ セットを学習サンプルとして参照します。
Matlab の実装 (ここでは、各ステップについて詳細なメモを示しています。その他の指示はありません)
clear
p1=[1.24,1.27;1.36,1.74;1.38,1.64;1.38,1.82;1.38,1.90;
1.40,1.70;1.48,1.82;1.54,1.82;1.56,2.08]; %9支Af的触角和翅膀的长度存在p1中
p2=[1.14,1.82;1.18,1.96;1.20,1.86;1.26,2.00
1.28,2.00;1.30,1.96]; %6支APf的触角和翅膀的长度存在p2中
p=[p1;p2]'; %将p1和p2合成一个矩阵并取转置,得到2行15列的矩阵p,第一列表示触角,第二列表示翅膀
pr=minmax(p); %求出P两列的最小值和最大值存在pr中
goal=[ones(1,9),zeros(1,6);zeros(1,9),ones(1,6)]; %写出已经15支的输出矩阵,Af为(1.0),Apf为(0,1)
plot(p1(:,1),p1(:,2),'h',p2(:,1),p2(:,2),'o') %把Af的触角~翅膀,及Apf触角~翅膀散点图画在同一个图中
net=newff(pr,[3,2],{'logsig','logsig'}); %用newff函数创建一个神经网络,隐藏层为3节,输出层为2节,隐藏层和输出层的传递函数均为logsig
net.trainParam.show = 10; %两次显示直接的训练字数(没有时取NAN)
net.trainParam.lr = 0.05; %学习速率为0.05
net.trainParam.goal = 1e-10; %训练目标
net.trainParam.epochs = 50000; %最大训练次数
net = train(net,p,goal); %从输入p到输出goal用已创建的net训练
x=[1.24 1.80;1.28 1.84;1.40 2.04]'; %输入想要预测的三支的触角和翅膀数据
y0=sim(net,p) %已知P的仿真,这里p即作为训练数据又作为仿真数据
y=sim(net,x)%对未知类型的x中三支进行仿真预测アフの触手~羽とアプの触手~羽が同じ図1に描かれているが、
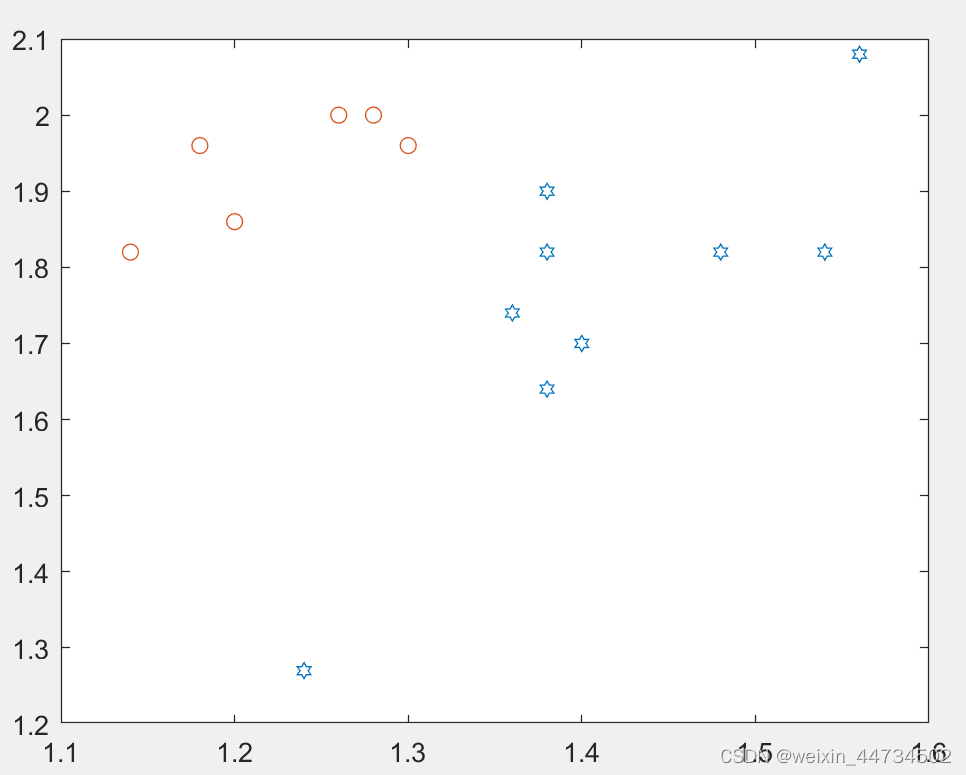
図1
実際、2 種類のダニの触角~翅データが実際に異なる分布をしていることは簡単にわかります. もちろん、これは直感的な判断にすぎません. ここでは、トレーニング済みのネットワークをシミュレーションに使用します. 最高のトレーニング パフォーマンスを達成します (図 2)。
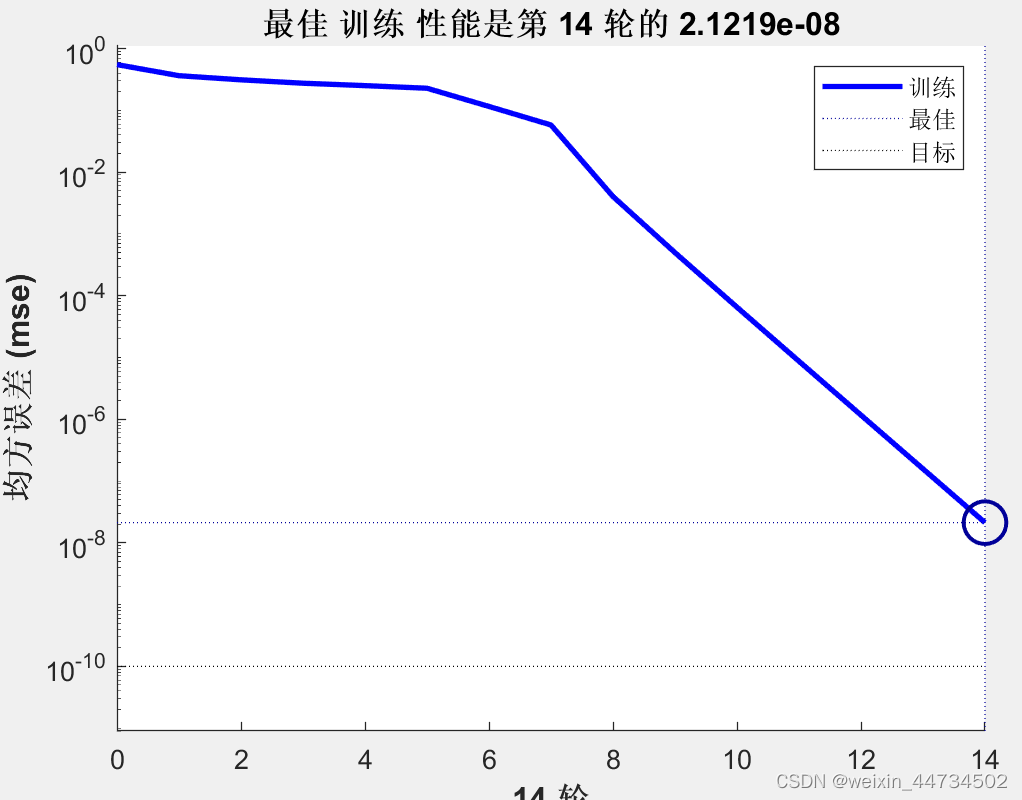
図2
トレーニング済みネットワークを使用して 15 匹のダニの既知のデータをシミュレートした結果を表 1 に示します。
| 1 | 2 | 3 | 5 | 5 | 6 | 7 | 8 | 9 |
| 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9994 | 0.9999 | 1.0000 | 1.0000 | 1.0000 |
| 0.0001 | 0.0001 | 0.0000 | 0.0000 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| 10 | 11 | 12 | 13 | 14 | 15 |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | 0.0005 |
| 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9999 | 0.9994 |
表1
シミュレーション結果は目標結果と 100% 一致するわけではありませんが、分類基準を確実に満たしていることがわかります。
トレーニング済みネットワークを使用して、(1.24, 1.80)、(1.28, 1.84)、および (1.40, 2.04) の 3 つのサンプルを分類します。結果を表 2 に示します。
| 1 | 2 | 3 |
| 0.0001 | 0.0008 | 0.9503 |
| 0.9996 | 0.9974 | 0.0294 |
表 2
したがって、(1.24,1.80)、(1.28,1.84) は Apf に属し、(1.40,2.04) は Af に属します。
4.2 非線形マッピングの問題
BP ニューラル ネットワークの重要な機能は非線形マッピングであり、関数近似などに非常に適しています。簡単に言えば、2 つのデータ セット間の関係を見つけることです。
例 2 入力ベクトル P とターゲット ベクトル T が既知であり、P と T の関係を見つけるために BP ネットワークが確立されます。
T=[-0.96 -0.577 -0.0729 0.377 0.641 0.66 0.461 0.1336 -0.201 -0.434 -0.5 -0.393 -0.1647 0.0988 0.3072 0.396 0.3449 0.1816 -0.0312 -0.2183];1
解決策:入力ベクトル P とターゲット ベクトル T はそれぞれ次のとおりです。
>>P= -1:0.1:1;
>>T=[-0.96 -0.577 -0.0729 0.377 0.641 0.66 0.461 0.1336 -0.201 -0.434 -0.5 -0.393 -0.1647 0.0988 0.3072 0.396 0.3449 0.18106 -0.03212 -0.318];
まず、newff を使用して BP ニューラル ネットワークを作成します。コードは次のとおりです。
>>net=newff([-1,1],[5,1],{'tansig','purelin'});
その中で、[-1,1] は入力ベクトル P の最小値と最大値を表し、minmax(P) に置き換えることができます。[5,1] は、ネットワークの中間層に 5 つのニューロンがあり、出力層に 1 つのニューロンがあることを意味します。つまり、BP ニューラル ネットワークは 1-5-1 構造のニューラル ネットワークです。{'tansig','purelin'} は、ネットワークの隠れ層の伝達関数が tansig であり、出力層の伝達関数が purelin であることを意味します。トレーニング関数は特別に設定されていないため、トレーニング関数はデフォルト値の trainlm を使用します。
次に、トレーニング パラメーターを設定し、ネットワークをトレーニングします。コードは次のとおりです。
>>net.trainParam.epochs=200; % 最大トレーニング時間
>>net.trainParam.goal=0; % トレーニング目標
>>net.trainParam.show=50; %2 つのディスプレイ間のトレーニング回数
>>net=train(net,P,T); %Network トレーニング関数、net in train は最初に作成されたネットワークです
最後に、トレーニングをシミュレートしてネットワーク出力結果 Y を取得し、グラフを描画します。コードは次のとおりです。
>> Y=sim(ネット,P);
Matlan の実装は次のとおりです。
P= -1:0.1:1;
T=[-0.96 -0.577 -0.0729 0.377 0.641 0.66 0.461 0.1336 -0.201 -0.434 -0.5 -0.393 -0.1647 0.0988 0.3072 0.396 0.3449 0.1816 -0.0312 -0.2183 -0.3201];
net=newff([-1,1],[5,1],{'tansig','purelin'});
net.trainParam.epochs=200; %最大训练次数
net.trainParam.goal=0; %训练目标
net.trainParam.show=50; %两次显示之间的训练次数
net=train(net,P,T); %网络训练函数,train中的net为创建的初始网络
Y=sim(net,P)%用训练好的网络对P仿真
plot(P,T,'-',P,Y,'o')%把训练样本和仿真画在一个图中最高のトレーニング パフォーマンスは、図 3 に示すようにエポック 61 での 2.7485e-06 エラー曲線です。ネットワーク出力とターゲット ベクトルの関係をより直感的に理解するには、図 4 を参照してください。
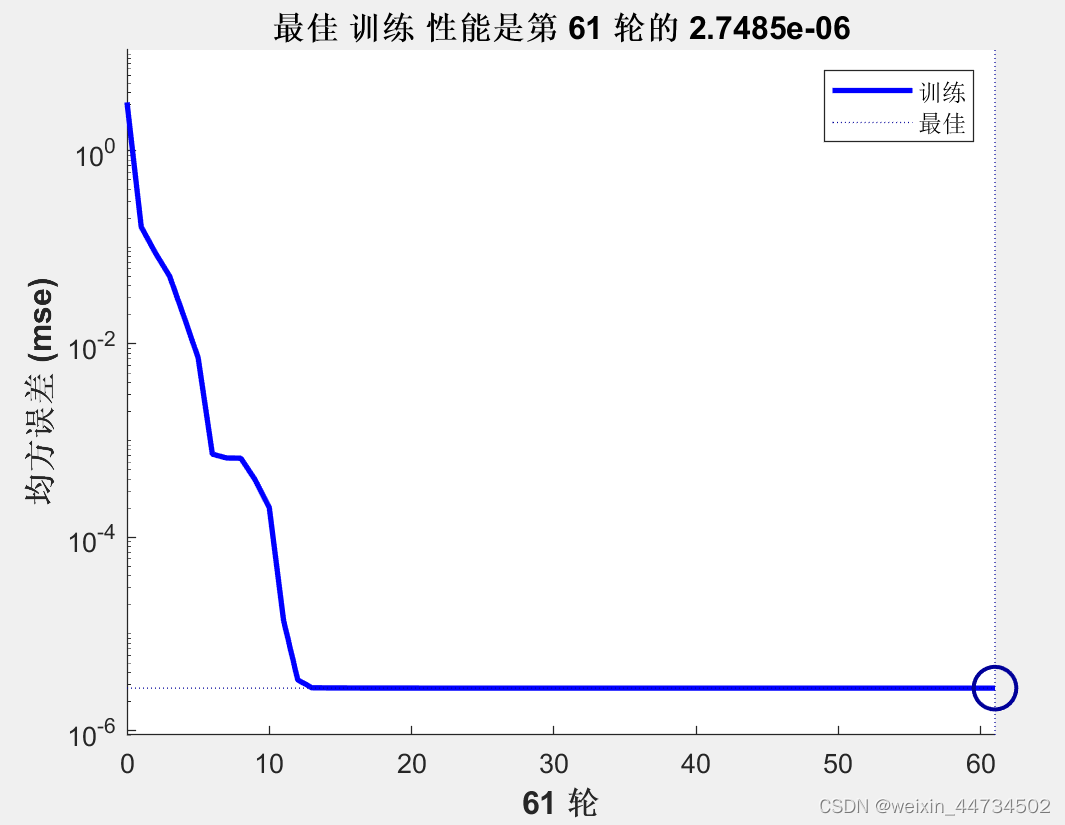
図 3 BP ニューラル ネットワークのトレーニング エラー曲線
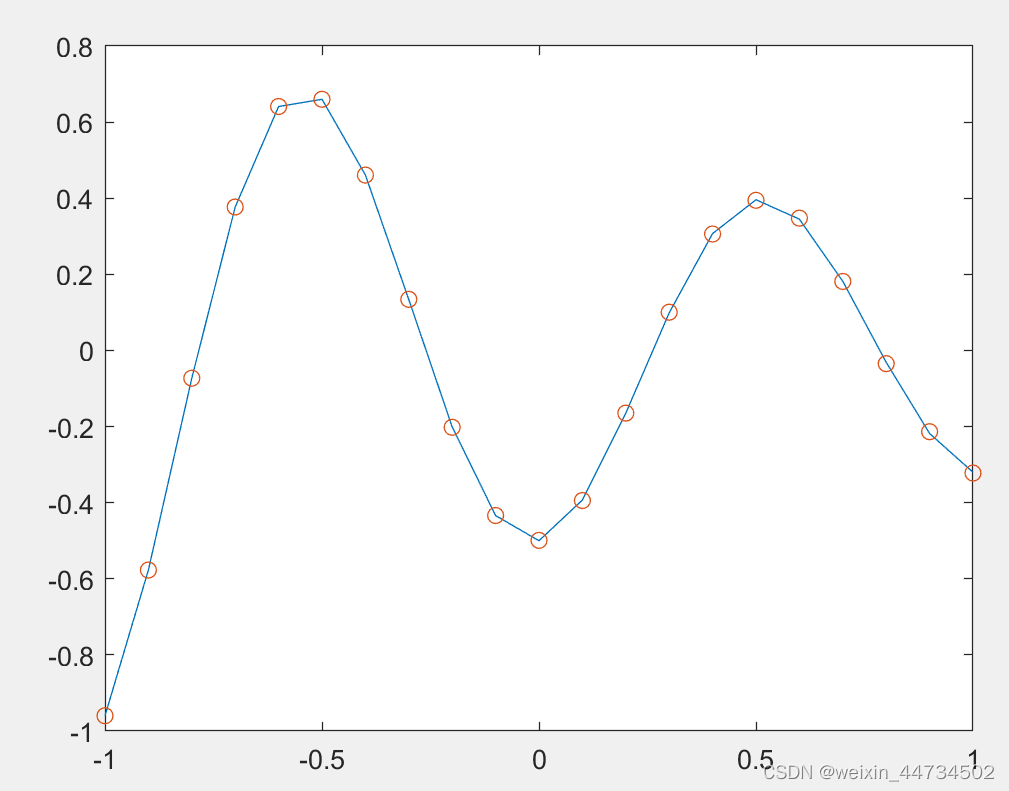
図 4 トレーニング後の BP ニューラル ネットワークのシミュレーション図
ネットワークトレーニング中に、編集者は非常に興味深いことを発見しました.ネットワークの最適なトレーニング回数は毎回異なります.これは、初期化された重みとしきい値がランダムであるため、ニューラルネットワークの結果が毎回異なるためです.結果が毎回異なる場合にのみ, より理想的な結果を見つけることができます. より良い結果を見つけた後, コマンド save filename net を使用します; ネットワークを保存するには, 予測された結果は変わりません.呼び出します。
4.3 予測問題
例 3 貨物量の予測には、1990 年から 2011 年までの中国統計年鑑のデータを使用し、国民総生産、エネルギー総生産、輸出入貿易量、社会消費財の小売総額、投資総額の 5 つの指標を使用してください。固定資産の主な要因であり、BP ニューラル ネットワークを使用して貨物の総量を予測します。
1990年から2011年までの貨物の総量と主な要因の一部のデータ
| 年 |
合計貨物 (万トン) |
国民総生産(億元) |
エネルギー総生産額(万トン) |
輸出入貿易額(億元) |
社会消費財の総小売売上高 |
固定資産への総投資額 |
| 1990年 |
970602 |
18718.3 |
103922 |
5560.1 |
8300.1 |
6955.81 |
| 1991年 |
985793 |
21826.2 |
104844 |
7225.8 |
9415.6 |
9810.4 |
| 1992年 |
1045899 |
26937.3 |
107256 |
9119.6 |
10993.7 |
12443.12 |
| 1993年 |
1115902 |
35260 |
111059 |
11271 |
14270.4 |
14410.22 |
| 1994年 |
1180396 |
48108.5 |
118729 |
20381.9 |
18622.9 |
17042.94 |
| 1995年 |
1234938 |
59810.5 |
129034 |
23499.9 |
23613.8 |
20019.3 |
| 1996年 |
1298421 |
70142.5 |
133032 |
24133.8 |
28360.2 |
22974 |
| 1997年 |
1278218 |
78060.9 |
133460 |
26967.2 |
31252.9 |
24941.1 |
| 1998年 |
1267427 |
83024.3 |
129834 |
26849.7 |
33378.1 |
28406.2 |
| 1999年 |
1293008 |
88479.2 |
131935 |
29896.2 |
35647.9 |
29854.7 |
| 2000年 |
1358682 |
98000.5 |
135048 |
39273.2 |
39105.7 |
32917.7 |
| 2001年 |
1401786 |
108068.2 |
143875 |
42183.6 |
43055.4 |
37213.5 |
| 2002年 |
1483447 |
119095.7 |
150656 |
51378.2 |
48135.9 |
43499.9 |
| 2003年 |
1564492 |
134977 |
171906 |
70483.5 |
52516.3 |
55566.6 |
| 2004年 |
1706412 |
159453.6 |
196648 |
95539.1 |
59501 |
70477.43 |
解決策:モデルの確立: 予測に BP ニューラル ネットワークを使用します。まず、入出力データに基づいてネットワークの構造を決定します。そして、ネットワークが予測能力を持つように、ネットワークをトレーニングするためのトレーニング データを決定します。次に、ネットワークの予測性能をテストするためのテスト データを決定します。最後に、訓練されたネットワークに基づいて総貨物量が予測されます。
この例の入力データは 5 次元で、出力は 1 次元であるため、BP ニューラル ネットワークの構造は 5-9-1 です。つまり、入力層は、国民総生産、総エネルギー生産、輸出入貿易量、社会消費財の小売総額、固定資産への投資総額の 5 つの主要な要素の正規化されたデータであり、産出は貨物の合計金額で、包含層は9ノードあります(状況に応じて調整可能)。そして、隠れ層の伝達関数として tansig を選択し、出力層の伝達関数として線形関数 f(x)=x を選択します。
データは 22 年分あることがわかっており、最初の 20 年分のデータがネットワークを訓練するための訓練データとして使用されます。データ量が少ないため、トレーニング データをテスト データとして使用して、ネットワークの予測パフォーマンスを判断し、最終的に 2010 年と 2011 年の総貨物量を予測します。
モデル ソリューション: BP ニューラル ネットワークの原理に従って、Matlab でプログラムされています。
(1) データ処理: テーブル データは e4_3.xls に格納されます。上記のデータの割り当てと同じ方法でデータを呼び出し、データを正規化します。データの正規化プロセスは、すべてのデータを [0,1] の間の数値に変換します. 目的は、データ間の大きさの違いをなくし、入力データと出力データの大きさの大きな違いによる大きなネットワーク予測エラーを回避することです. 正規化の方法はたくさんあります. この例では, 最大および最小の正規化方法が使用されています. 正規化関数はMatlabに付属の関数 mapminmax を使用しています. この関数には多くの形式があり、一般的に使用されるメソッドは次のとおりです。
[x1,ps] = mapminmax(x)
ここで、x は正規化されるデータ、x1 は正規化されたデータ、ps は正規化された構造体であり、データ x の最大値、最小値、平均値などの情報が含まれています。正規化されたデータ x1 を非正規化する方法は次のとおりです。
x = mapminmax('reverse',x1,ps)
ニューラル ネットワークのテスト データや予測データなど、データ x の正規化された構造 ps を使用して新しいデータ y を正規化する必要がある場合、次のような方法があります。
y1 = mapminmax('適用',y,ps)
このうち、y1 はデータ y の正規化データであり、y1 の非正規化処理方法は上記と同じです。
(2) BP ニューラル ネットワークの初期化: BP ニューラル ネットワークの 5-9-1 構造に従って、BP ニューラル ネットワークの重みとしきい値がランダムに初期化されます。
(3) BP ニューラル ネットワークのトレーニング: トレーニング データを使用して BP ニューラル ネットワークをトレーニングし、ネットワークの予測誤差に応じてネットワークの重みとしきい値を調整します。
(4) BP ニューラル ネットワーク テスト: テスト データを使用して BP ニューラル ネットワークの予測性能をテストします。
(5) BP ニューラル ネットワーク予測: 2010 年と 2011 年の主な要因を入力し、トレーニングされたネットワークを使用して、この 2 年間の貨物の総量を予測します。
(6) 予測結果: テスト データの結果から、BP ニューラル ネットワーク テストの最大エラー率は約 4% です. テスト結果は図 12-23 に示されています.予測能力。2010 年と 2011 年の貨物量の予測結果は、それぞれ 31,331,470,000 トンと 3,370,948 トンであり、誤差率は 3.35% と 8.82% であり、比較的実績に近い。
Matlabの実装は次のとおりです
clc;clear all %情况变量环境
[xdata,textdata]=xlsread('e4_3.xls'); %读取货运量数据
[n,m]=size(xdata);
Train_Num=20; %输入样本数量为20
Test_Num=Train_Num; %测试样本数量也是20
Sim_Num=2; %预测样本数量为6
%提取输入Input和输出Output数据
Input=[xdata(1:Train_Num,3) xdata(1:Train_Num,4) xdata(1:Train_Num,5) xdata(1:Train_Num,6) xdata(1:Train_Num,7)]';
Output=xdata(1:Train_Num,2)';
%%%数据归一化处理
[Inputn,In_ps]=mapminmax(Input,0,1); %输入数据归一化
[Outputn,Out_ps]=mapminmax(Output,0,1); %输出数据归一化
Train_Input=Inputn(:,1:Train_Num); %训练数据输入
Test_Input=Train_Input; %测试数据输入
Train_Output=Outputn(:,1:Train_Num); %训练数据输出
Test_Output=Train_Output; %测试数据输出
Input_Num=5; %输入节点个数
Hidd_Num=9; %中间层隐节点数量取9
Out_Num=1; %网络输出维度为1
MaxEpochs=50000; %最多训练次数为50000
lr=0.01; %学习速率为0.01
E0=0.45*10^(-2); %目标误差为0.45*10^(-2)
W1=0.5*rand(Hidd_Num,Input_Num)-0.1; %初始化输入层与隐含层之间的权值
B1=0.5*rand(Hidd_Num,1)-0.1; %初始化输入层与隐含层之间的阈值
W2=0.5*rand(Out_Num,Hidd_Num)-0.1; %初始化输出层与隐含层之间的权值
B2=0.5*rand(Out_Num,1)-0.1; %初始化输出层与隐含层之间的阈值
ErrHistory=[]; %给中间变量预先占据内存
for i=1:MaxEpochs
HiddenOut=logsig(W1*Train_Input+repmat(B1,1,Train_Num)); % 隐含层网络输出 9x5x5x20+9x20=9x20
NetworkOut=W2*HiddenOut+repmat(B2,1,Train_Num); % 输出层网络输出
Error=Train_Output-NetworkOut; % 实际输出与网络输出之差
SSE=sumsqr(Error) %能量函数(误差平方和)
ErrHistory=[ErrHistory SSE];
if SSE<E0,break, end %如果达到误差要求则跳出学习循环
% 以下是BP网络最核心的程序
% 它们是权值(阈值)依据能量函数负梯度下降原理所作的每一步动态调整量
Delta2=Error;
Delta1=W2'*Delta2.*HiddenOut.*(1-HiddenOut);
dW2=Delta2*HiddenOut';
dB2=Delta2*ones(Train_Num,1);
dW1=Delta1*Train_Input';
dB1=Delta1*ones(Train_Num,1);
%对输出层与隐含层之间的权值和阈值进行修正
W2=W2+lr*dW2;
B2=B2+lr*dB2;
%对输入层与隐含层之间的权值和阈值进行修正
W1=W1+lr*dW1;
B1=B1+lr*dB1;
end
HiddenOut=logsig(W1*Test_Input+repmat(B1,1,Test_Num)); % 隐含层输出最终结果
NetworkOut=W2*HiddenOut+repmat(B2,1,Test_Num); % 输出层输出最终结果
Test_Out=mapminmax('reverse',NetworkOut',Out_ps); % 还原网络输出层的结果,得到测试数据网络实际输出
Error=Test_Out-Output'; % 网络实际输出Test_Out与期望输出Output之间的误差
Error_bi=Error./Output'; % 网络实际输出与期望输出之间的误差比
%%%BP神经网络预测 输入为2010年和2011年主要因素
Sim_Input=[xdata(Train_Num+1:end,3) xdata(Train_Num+1:end,4) xdata(Train_Num+1:end,5) xdata(Train_Num+1:end,6) xdata(Train_Num+1:end,7)]';
Sim_Output=xdata(Train_Num+1:end,2)';
Sim_Input=mapminmax('apply',Sim_Input,In_ps);
HiddenOut=logsig(W1*Sim_Input+repmat(B1,1,Sim_Num)); % 隐含层输出最终结果
NetworkOut=W2*HiddenOut+repmat(B2,1,Sim_Num); % 输出层输出最终结果
Sim_Out=mapminmax('reverse',NetworkOut',Out_ps); % 还原网络输出层的结果
Error=Sim_Out-Sim_Output'; % 网络预测输出Sim_Out与期望输出Sim_Output之间的误差
baifenbi=Error./Sim_Output'; % 网络预测输出与期望输出之间的误差比
figure(1)
time1=1:Train_Num;
plot(time1+1989,Test_Out,'r-o',time1+1989,Output(1:Train_Num),'b--+')
legend('网络测试输出货运量','实际货运总量');
xlabel('年份');ylabel('货运总量/万吨');
% figure(2)
% time2=Train_Num+1:22;
% plot(time2+1989,Sim_Out,'r-o',time2+1989,Sim_Output,'b--+')
図 5 に示すように、最高のトレーニング パフォーマンスは 775 ラウンドの 0.00099919 です。
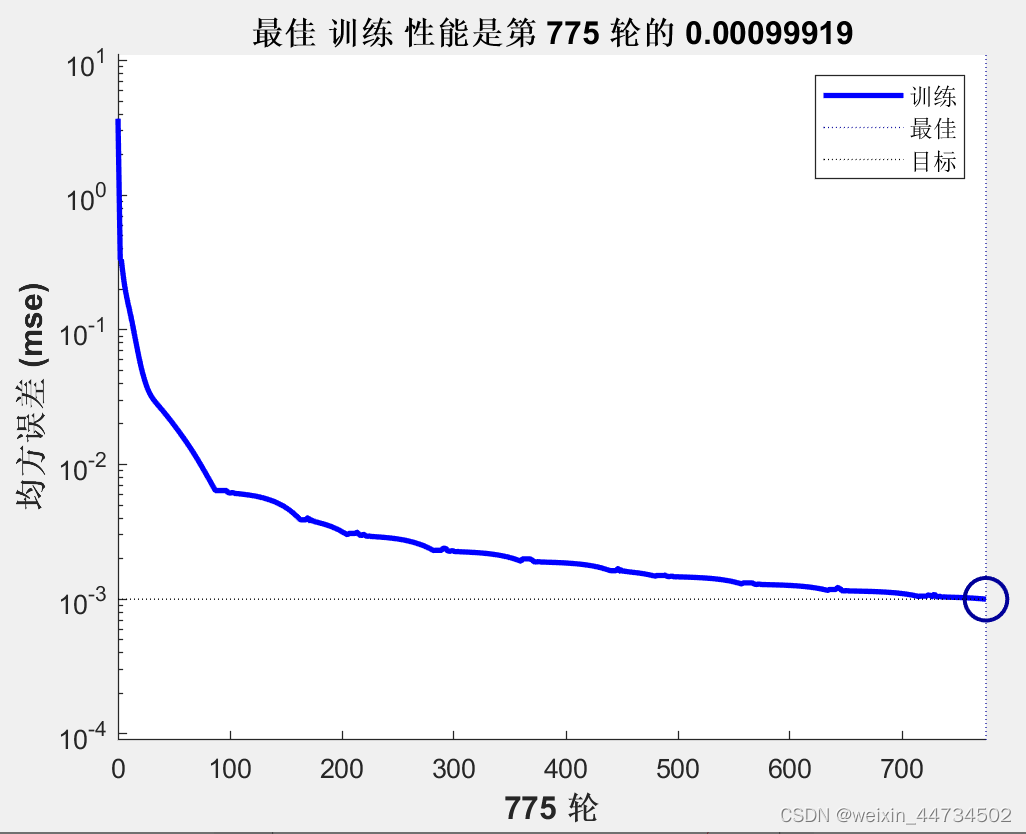
図 5
BP ニューラル ネットワークのテスト結果を図 6 に示します。
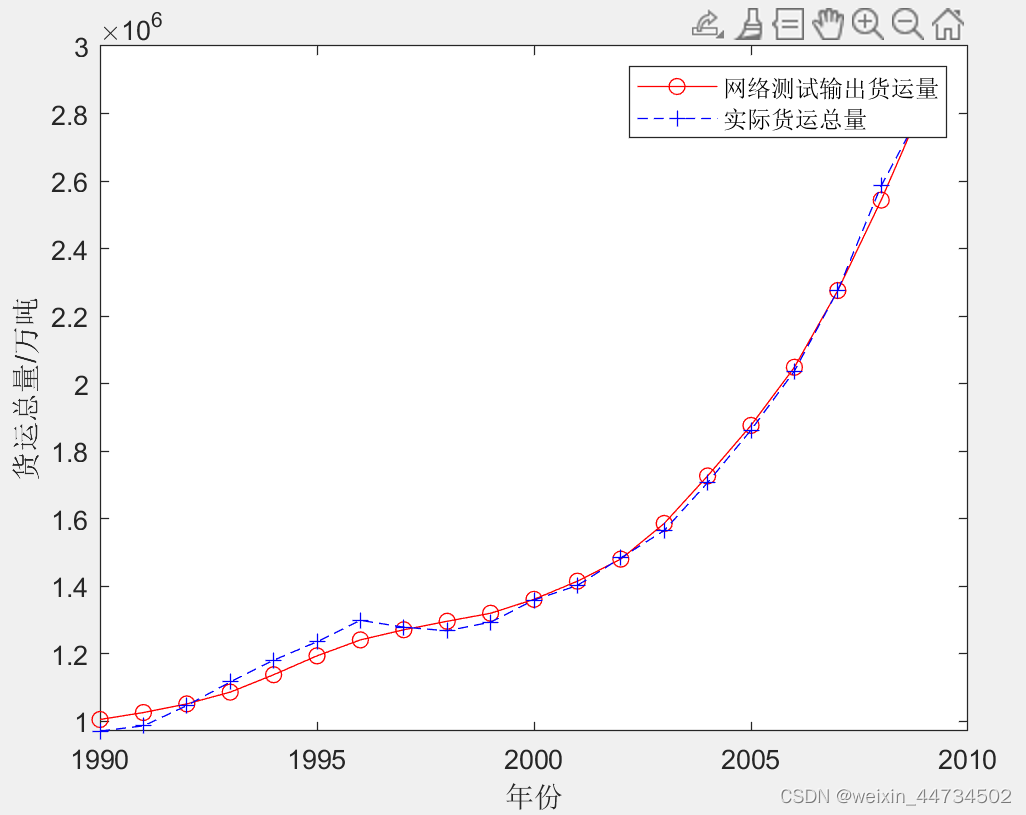
図 6
2010 年と 2011 年の貨物量の予測データを図 7 に示します。赤い線は予測値を表します。
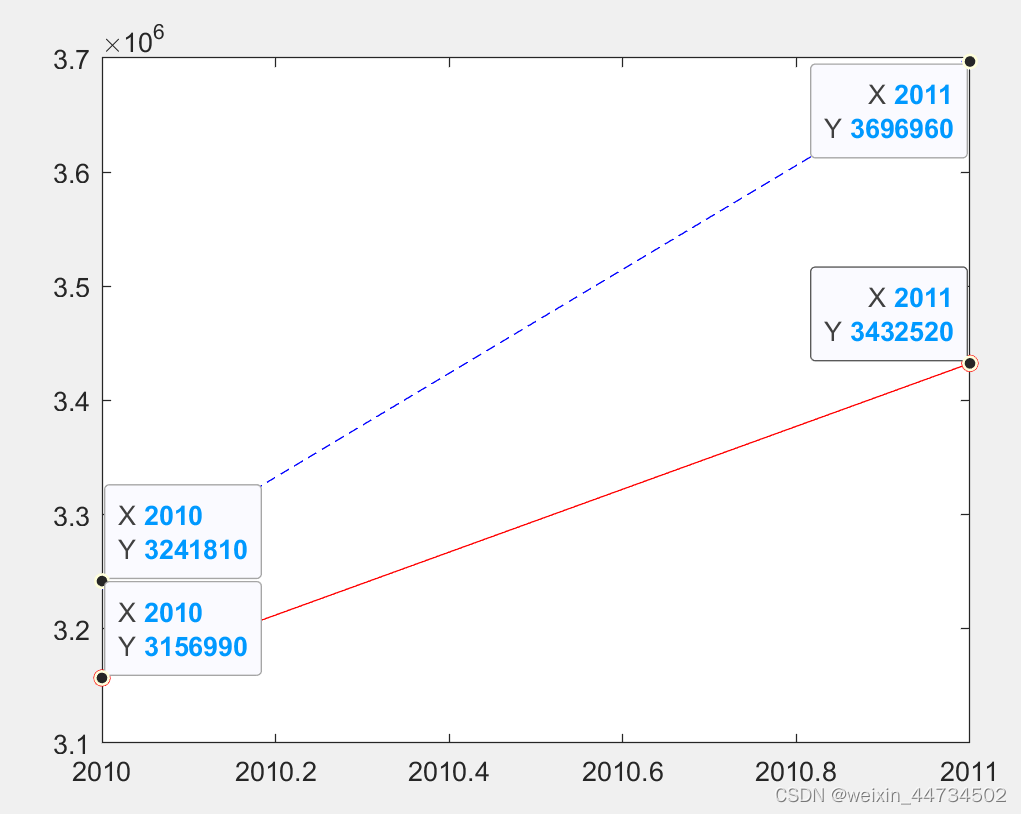
図 7
例 4ある貯水池の既存の流出データと、それに対応する 4 つの以前の予測変数の測定データを下の表に示します.4 つの予測変数は、前年の 11 月と 12 月の貯水池の総雨量 x1 と、今年の 2 月と 3 月の降水量 x2、x3、x4。この例では、これらの 4 つの予測子を入力として使用し、年間流出量を出力として使用して、4 つの入力と 1 つの出力を持つネットワークを形成します.最初の 19 の測定データはトレーニング サンプル セットとして使用され、後者の測定データは予測試験サンプルとして使用されます。
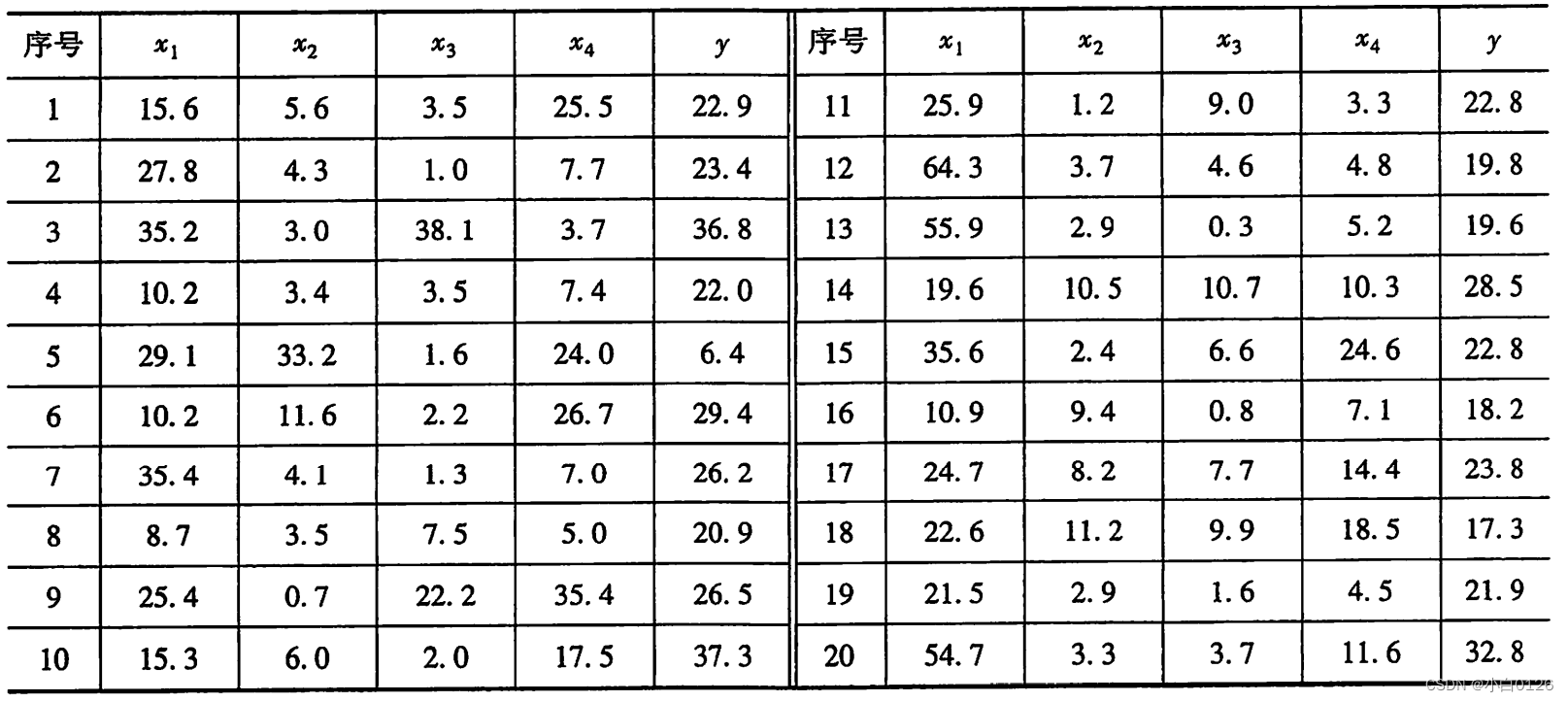
ネットワークトレーニング
人工ニューラル ネットワークの機能を実現するには、Matlab が提供するニューラル ネットワーク ツールボックスを使用すると非常に便利です。毎年の流出予測には独立変数が 4 つ、従属変数が 1 つあるため、入力ニューロンの数を 4、出力ニューロンの数を 1、中間の隠れ層ニューロンの数を BP ニューラル ネットワークが必要とします。経験に基づいて決定されます。RBF ニューラル ネットワークは、トレーニング プロセス中に適応的に決定されます。
BP ニューラル ネットワークには、収束が遅い、ネットワークが局所的最小値に陥りやすい、学習プロセスが頻繁に振動するなど、いくつかの欠点があります。この場合の予測では、BP ニューラル ネットワークの隠れ層の数を 4 に設定すると計算結果が比較的安定し、隠れ層の数をそれ以外の値に設定すると実行結果が特に不安定になり、各実行の結果は大きく異なります。
Matlab ツールボックスを使用して 20 番目のサンプル ポイントを取得すると、RBF ニューラル ネットワークの予測値は 26.7693 であり、相対誤差は 18.39% であり、RBF ニューラル ネットワーク モデルの予測結果は BP ニューラル ネットワーク モデルよりも優れています。
Matlabコードは次のとおりです
clc, clear
a=load('l_4.txt'); %把表中的数据保存到文本文件l_4.txt
a=a'; %注意神经网络的数据格式,不要将转置关系搞错
P=a([1:4],[1:end-1]); [PN,PS1]=mapminmax(P); %自变量数据规格化到[-1,1]
T=a(5,[1:end-1]); [TN,PS2]=mapminmax(T); %因变量数据规格化到[-1,1]
net1=newrb(PN,TN) %训练RBF网络
x=a([1:4],end); xn=mapminmax('apply',x,PS1); %预测样本点自变量规格化
yn1=sim(net1,xn); y1=mapminmax('reverse',yn1,PS2) %求预测值,并把数据还原
delta1=abs(a(5,20)-y1)/a(5,20) %计算RBF网络预测的相对误差
net2=feedforwardnet(4); %初始化BP网络,隐含层的神经元取为4个(多次试验)
net2 = train(net2,PN,TN); %训练BP网络
yn2= net2(xn); y2=mapminmax('reverse',yn2,PS2) %求预测值,并把数据还原
l_4.txt
15.6 5.6 3.5 25.5 22.9
27.8 4.3 1.0 7.7 23.4
35.2 3.0 38.1 3.7 36.8
10.2 3.4 3.5 7.4 22.0
29.1 33.2 1.6 24.0 6.4
10.2 11.6 2.2 26.7 29.4
35.4 4.1 1.3 7.0 26.2
8.7 3.5 7.5 5.0 20.9
25.4 0.7 22.2 35.4 26.5
15.3 6.0 2.0 17.5 37.3
25.9 1.2 9.0 3.3 22.8
64.3 3.7 4.6 4.8 19.8
55.9 2.9 0.3 5.2 19.6
19.6 10.5 10.7 10.3 28.5
35.6 2.4 6.6 24.6 22.8
10.9 9.4 0.8 7.1 18.2
24.7 8.2 7.7 14.4 23.8
22.6 11.2 9.9 18.5 17.3
21.5 2.9 1.6 4.5 21.9
54.7 3.3 3.7 11.6 32.8
5. ニューラル ネットワーク モデルの長所と短所
BP ニューラル ネットワークは、ネットワーク理論とパフォーマンスの両方において比較的成熟しています。その優れた利点は、強力な非線形マッピング機能と柔軟なネットワーク構造です。ネットワークの中間層の数と各層のニューロンの数は、特定の状況に応じて任意に設定でき、構造の違いによってパフォーマンスも異なります。ただし、BP ニューラル ネットワークには次のような大きな欠点もあります。
① 学習速度が遅い 単純な問題でも収束するまでに数百回、数千回の学習が必要です。
②極小値に陥りやすい。
③ネットワーク層の数とニューロンの数を選択するための対応する理論的ガイダンスはありません。
④ネットワーク推進力には限界があります。