1 分でエッセンスの概要を簡単に説明
何万ものサーバーの使用率が低い場合、それは莫大な無駄を意味します.適切な容量管理は、「土壇場での」一時的な緊急ブラインドまたは過剰購入を排除するのに役立ちます. 合理的なコスト管理に加えて、キャパシティ管理では、顧客に影響を与える可能性のあるビジネスの発展とリスクの変化を見積もる必要もあります。
B局では、コスト削減と効率化を背景に、全体のキャパシティをビジネスの視点から見える化して管理しており、そのキャパシティ管理の背景、考え方、成果について詳しく解説しています。
著者 紹介Zhang He、Bilibili シニア SRE エキスパート
紹介Zhang He、Bilibili シニア SRE エキスパート
TakinTalksコミュニティの専門家グループのメンバーで、2020年にB局に入社し、本局/生放送/OGV/プロモーション検索関連のSRE業務を担当。マルチアクティブ、アクティビティ保証、カオス エンジニアリング、容量管理関連の構築に深く関与し、容量管理プラットフォームとカオス プラットフォームのアーキテクチャ設計と実装を主導しました。以前はビリビリSコンペのインフラ保証業務、年越しパーティー、年賀状等を担当し、現在は主に検索事業の安定構築とPaaSガバナンスの推進を担当。
注意事項: この記事は約 4,500 語で、読むのに 9 分かかると予想されます。
バックグラウンドで「通信」と応答してリーダー交換グループに入り、「2252」と応答してコースウェア情報を取得します。
バックグラウンド
B駅の三大活動は、S大会、新年のご挨拶、B駅での年越しパーティーです。ユーザーの増加の背後で、SRE チームは、マルチアクティブ、カオス エンジニアリングなど、ビジネスの継続性を確保するために多くのことを行ってきました。
今日は別の角度から「キャパシティ管理」についてお話しましょう.ステーション B には、なぜキャパシティ管理プラットフォームが必要なのですか? 当社の容量管理システムはどのように設計されていますか? プラットフォーム側とビジネス側でどのように運用し、作品を「ビジュアル」にするか。また、S12 コンペティションでのキャパシティ管理プラットフォームの実際の適用に基づいて、「ビジネスに力を与える」という経験を共有します。
1. ステーション B にキャパシティ管理が必要なのはなぜですか?
キャパシティ管理を行う前、ステーション B は、下の図に示すように、いくつかの明らかな問題点に直面していました。
 未知のキャパシティ リスクを解決するだけでなく、「コスト削減と効率化」を提唱する背景の下で、リソースの使用率を改善し、合理的かつデータに基づいた予算決定を策定することも非常に重要です。
未知のキャパシティ リスクを解決するだけでなく、「コスト削減と効率化」を提唱する背景の下で、リソースの使用率を改善し、合理的かつデータに基づいた予算決定を策定することも非常に重要です。
以前は、S9、S10 などの大規模なアクティビティでステーション B によって行われた容量決定は、システム自体の容量が十分かどうか、必要かどうかなど、S12 が参照する関連データを蓄積していませんでした。拡張する必要があるか、どの程度拡張する必要があるかなど、容量データのサポートはほとんどありません。さらに、年間予算の策定には、参照容量データも緊急に必要です。
2. ステーション B のキャパシティ システムはどのように設計されていますか?
2.1 さまざまな役割の要求
上記の問題点に基づいて、さまざまな役割がさまざまなトラフィック インジケーターに注意を払うように、キャパシティ システム全体を設計する予定です。例えば:
R&D 部門: 拡張およびリリースするのに十分なリソースがあるかどうかに焦点を当てます。比較的高いレベルの R&D リーダーは、部門全体のリソース使用率や部門のコストが妥当かどうかなどに注意を払うことがあります。
プラットフォーム: プラットフォームの販売率、リソース バッファー、リソース使用率、およびその他の作業に注意を払い、コストを削減して効率を高めます。
SRE: 主な焦点は安定性であり、コストの削減と効率の向上という大きな目標を達成するには、全体的なリソースの使用率を向上させることも必要です。
コスト部門: 請求書、コスト、予算、リソースの使用状況などにもっと注意を払います。つまり、全体的なコストを節約します。
2.2 キャパシティシステムの全体設計
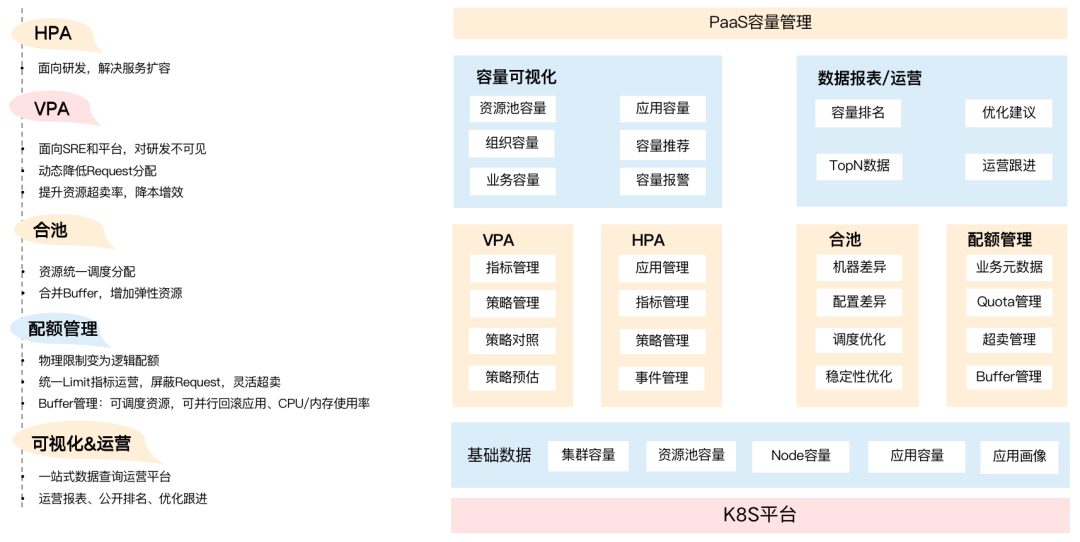 下から順に、最下層は主にマシン、リソース プールなどの基本データ (基本容量) であり、クラウドの最下層に偏っています。SRE とプラットフォームは、クラスタのキャパシティとリソース プールのキャパシティをより認識する必要があります.リソース プールがどのように過剰に売られたり規制されたりしても、基盤となるリソースの全体的な使用量が安全なレベルでなければならないという前提があります.
下から順に、最下層は主にマシン、リソース プールなどの基本データ (基本容量) であり、クラウドの最下層に偏っています。SRE とプラットフォームは、クラスタのキャパシティとリソース プールのキャパシティをより認識する必要があります.リソース プールがどのように過剰に売られたり規制されたりしても、基盤となるリソースの全体的な使用量が安全なレベルでなければならないという前提があります.
基本容量に基づいて、一連の VPA ベースのスケーリング戦略と HPA ベースのインスタンスのエラスティック スケーリングを構築しました。ビジネスのリソースプールも統合しました.プールが統合された後、大きなプールで各ビジネスパーティーが使用するリソースをどのように制御するかという問題に直面する可能性があります. このとき、業務に基づいたクォータ管理、つまり、業務ごとに使用できるリソースの量を制御する必要があります。
より高いレベルでは、キャパシティの視覚化と運用データのセットを提供して、ビジネスをサポートし、ビジネスチームの効率を向上させます。これには、キャパシティオペレーションの週次レポートなど、ビジネス部門に基づく組織のキャパシティとキャパシティイベントが含まれます。部門の利用率を公開ランキング化し、そのデータをもとに最適化提案を行っているのですが、この部分は後ほど詳しく紹介します。
3. キャパシティの運用と可視化は、企業の問題解決にどのように役立ちますか?
3.1 基本容量
基本容量は、容量システム全体の基礎です. 前述のように、以下の図に示すように、クラスター、リソース プール、ノード、および一部のアプリケーション ディメンションの容量レポートに注意を払います。
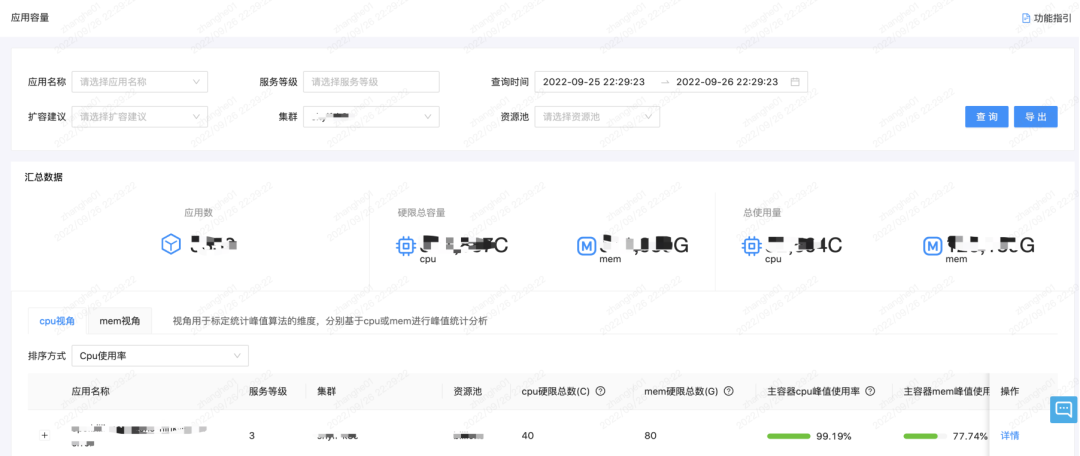
クラスター: クラスター容量の水位と売られ過ぎ率に注意してください。
リソース プール: リソース プールの容量の水位、過剰販売率、およびリソースの冗長性に注意してください。リソースの使用状況は、時間内にマシンを購入する必要があるかどうかを決定し、それらがより多くのビジネスを実行できるかどうかを判断します。
ノード: ノード リソースの水位とノードの売られ過ぎ率に注意してください。売られ過ぎはホットスポットから圧力を受けるため、ノードの使用状況に関するレポートが作成されます。
アプリケーション: 使用状況、使用率、インスタンス数、単一インスタンス コンテナーの数などに注目します。ビジネスは、アプリケーション レベルでデータにもっと注意を払います. たとえば、サービスがシングル ポイントであるかどうか. シングル ポイントとは、物理マシンがハングアップし、サービスがたまたまこの物理マシン上にある場合に、サービスが停止することを意味するためです。現時点では一時的に利用できません.コアビジネスについては、それは受け入れられないと述べました.
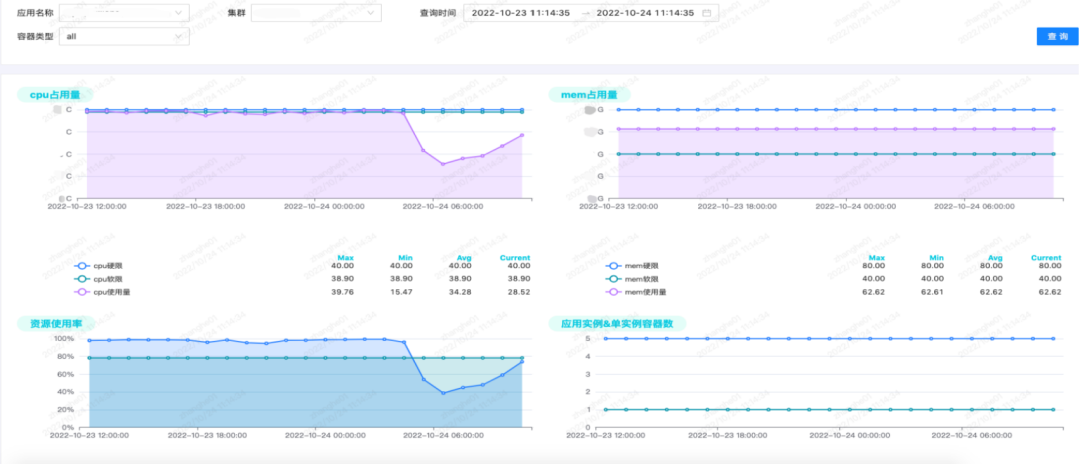
これらの指標に基づいて、いくつかの視覚的なインターフェイスを作成しました.デフォルトで2週間データを保存する外部監視システムGrafanaとは異なり、容量プラットフォーム全体のデータは永続的に保存されます.現在、ほぼ2年間データを保存しています.
3.2 事業組織能力
コストを削減し、効率を高めるという文脈で、企業が問題を解決するのをどのように支援しますか? 一般に、ビジネス側は、どのサービスがより多くの容量を占有しているか、リソースの使用率が比較的低く、縮小できるビジネスはどれか、どのビジネスがコストまたは使用量の急激な増加を引き起こしたか、およびビジネス ガバナンスまたはアーキテクチャの後で、どのように見つけるかにより注意を払います。統合 ガバナンスがどれほど効果的かなど、全体的な状況を理解するのに役立つ、より直感的なインターフェースが必要です。
以上の点を踏まえ、下図のように事業組織別のキャパシティレポートを作成しました。
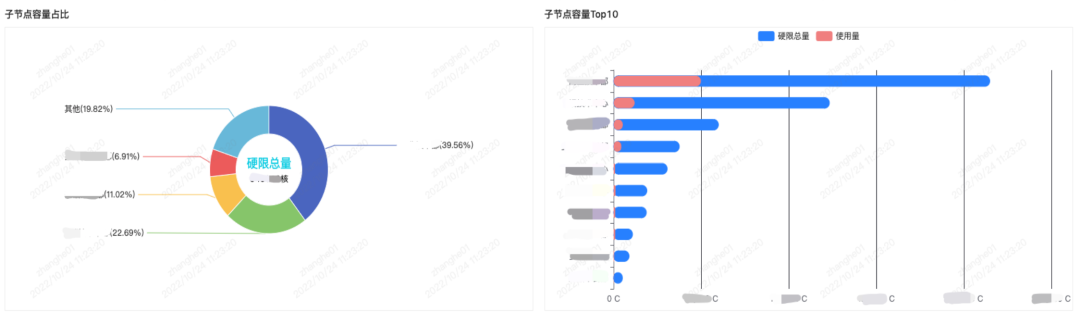
B局の生放送事業を例にとると、大規模な部門として、生放送は全体の稼働率を40%と想定しており、プレゼントや抽選などのサービスはリソースが多く、利用率が低いと判断された場合、ビジネス チームは、ビジュアル レポートの情報に基づいてそれらを事前に管理し、より多くのメリットを得ることができます。
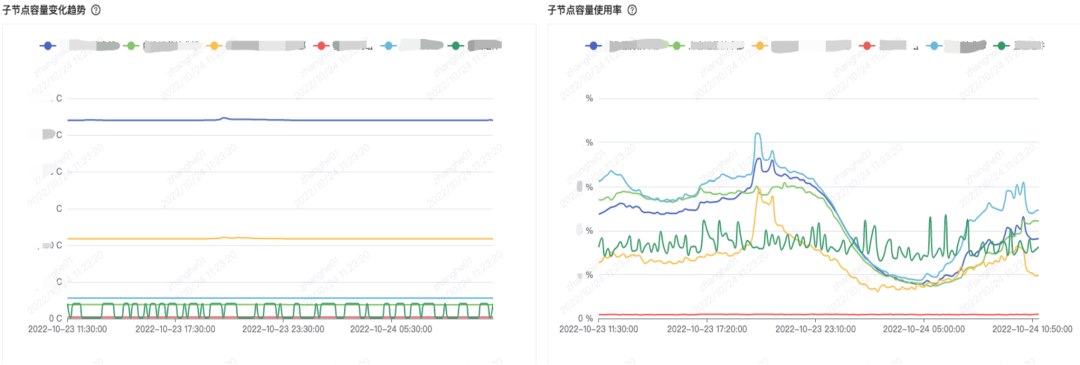
同時に、トレンドグラフをもとに、新規事業シナリオや研究開発、急な事業拡大など、生放送事業のどの事業が急に大きなキャパシティを占めているかを把握し、データのドリルダウンを支援します。収益事業にドリルダウンして、懸賞なのか、贈答事業による変化なのかを調べることができます。
3.3 容量イベント
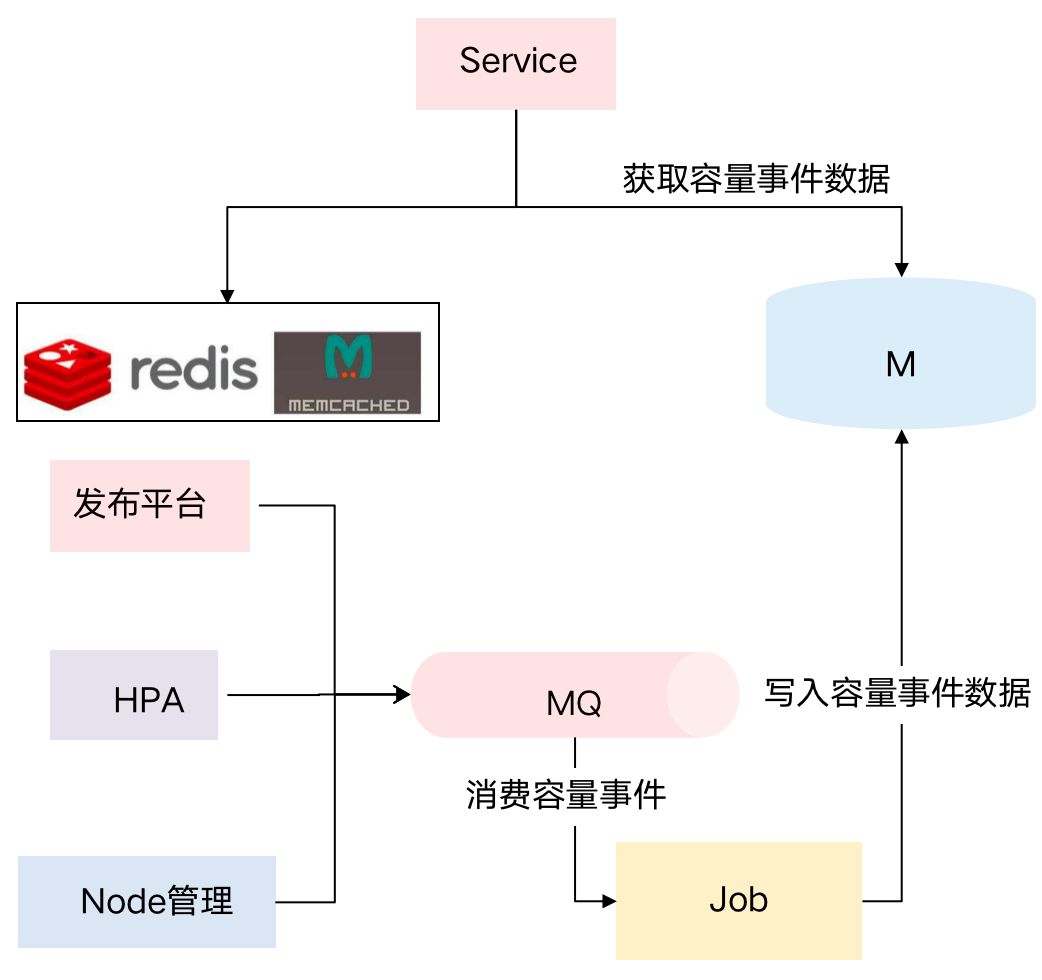
イベント ソースの観点からは、リリース プラットフォーム/HPA 変更プラットフォーム/ノード管理など、容量変更を引き起こす可能性のある多くのイベントがあります.リリース プラットフォームでは、R&D は容量を拡張したり、新しいサービスを追加したり、容量構成を変更したりできます.容量の変更。また、HPAの拡張・縮小、Node物理マシンの追加・削除なども容量の変化につながります。
そのため、さまざまなキャパシティ変更プラットフォームを内部で接続し、キャパシティ イベント関連の機能を構築しました.企業が全体的なリソース使用量が大幅に変化したことに気付いた場合、キャパシティ イベントを通じてイベントの原因を迅速に特定し、キャパシティ リスクをタイムリーに認識できます。方法、およびトレース容量の変更根本原因。
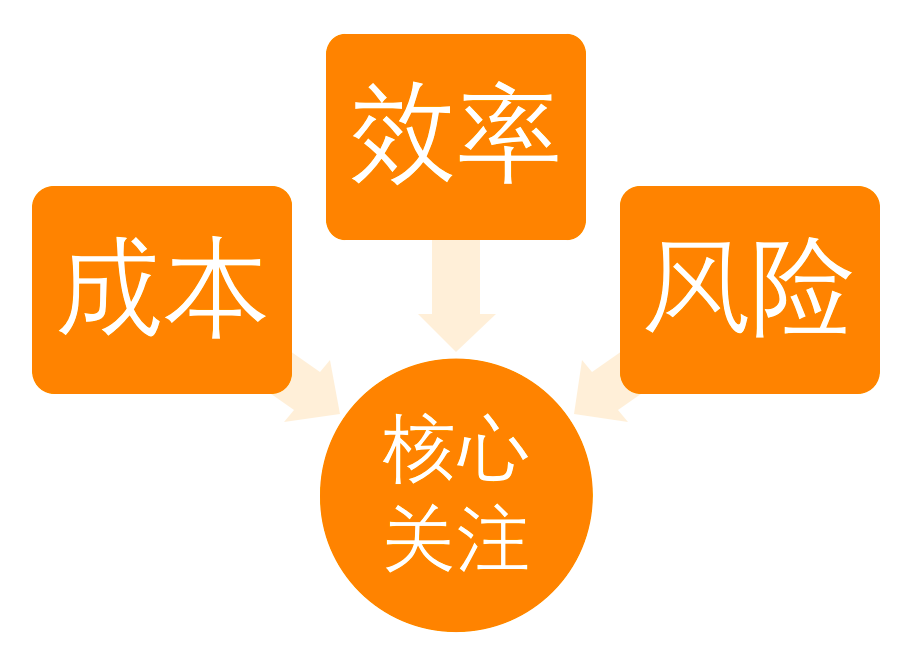
3.4 キャパシティ週間レポート
キャパシティは毎週変動するため、当社のプラットフォームは週報を分析しますコスト、効率、リスクの3つのコアから始めて、事業部門とプラットフォーム側の週報の焦点はかなり異なります。
3.4.1 部門のキャパシティ週間レポート (ビジネス側)
事業サイドの週報は、以下の4点に着目しております——
**全体のリソース容量とリソース使用率は先週から変更されました。**つまり、先週と比較して、リソースの使用量がどれだけ増加または減少したか。
アプリケーション容量トップ。つまり、どのアプリケーションがより多くのリソースを占有するかを把握することで、企業は大量のリソースを迅速に認識し、コスト削減と最適化の効率を向上させることができます。
**リスクの高いアプリケーション (L0/L1 アプリケーションが最初に表示されます)。**この部門にリスクの高いアプリケーションがある場合でも、使用率の高いコア サービスがある場合は、事前に容量を拡張できます。
**一週間ボリューム変更申請トップ。**つまり、どのサービスが追加されたのか、どのサービスが拡張・縮小されたのか、どのサービスがオフラインになったのかなど、一目でわかるようになっています。
 (社外週報表示 -- 部門メインの全体資源稼働率)
(社外週報表示 -- 部門メインの全体資源稼働率)
3.4.2 内部週報(プラットフォーム側)
プラットフォーム側の週報は、以下の2点に着目しております——
部門リソースの使用率とランキング、部門のキャパシティ トップ; 部門リソースの空き率トップ (5000 以上のコア部門)。
公開ランキングを通じて、キャパシティ ガバナンスが弱いビジネスを把握し、ガバナンスを優先します。同時に、リソースの使用量が多いため、ガバナンスで優先する必要があり、プラットフォームもより大きなガバナンスの利点を得ることができます。 (内部週報表示 -- 全体的なリソース使用率)
(内部週報表示 -- 全体的なリソース使用率)
3.5 容量検査
活動を推進する上でも、日々の事業の安定を保証する上でも、全体のキャパシティが危うい状態に陥っていないか、細心の注意を払う必要があるため、キャパシティ検査制度を設けています。
3.5.1 業務検査
業務側が注目する2つの側面である「申請容量検査」と「割当検査」について、ビジュアル表示を行いました。
ピーク使用率が高いアプリケーションは安定性にリスクがあり、緊急の拡張を検討する必要がありますが、使用率が低いアプリケーションは、リソースを節約するためにスケールダウンできるかどうかを検討する必要があります。
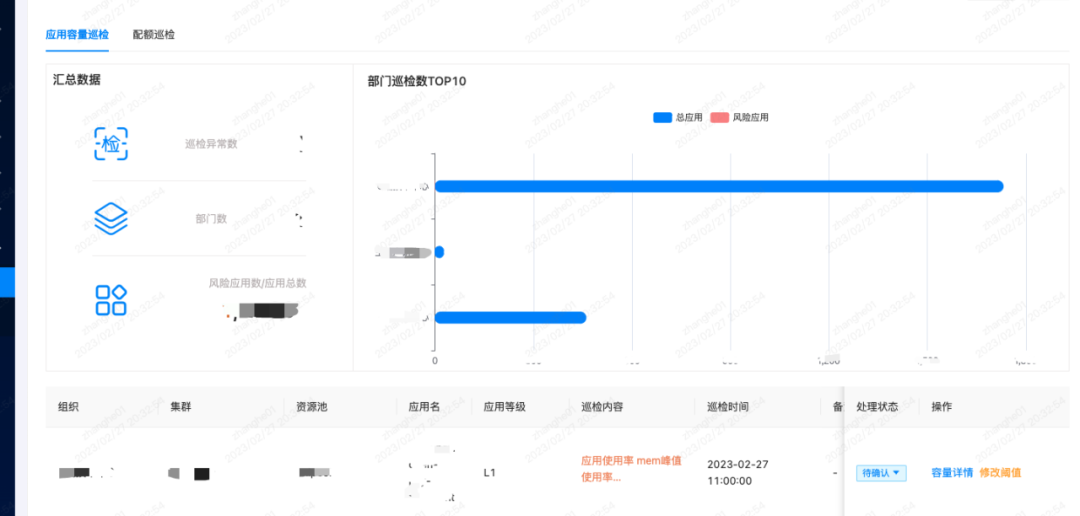
先述のとおり、プールを統合しておりますので、プール統合後のクォータ使用率が高すぎる状況には注意を払い、その後の拡大や期待外れの新規事業を回避し、リスクを事前に発見し、それらを管理します。
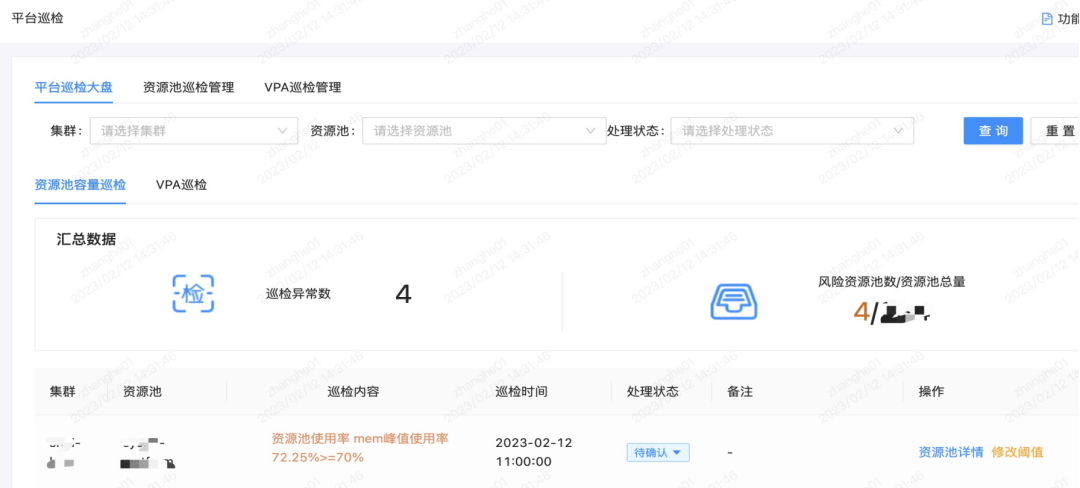
3.5.2 プラットフォーム検査
プラットフォームは、基本的な使用率、スケジュール可能なインスタンスの数がその後のビジネス ニーズを満たしているかどうか、リソース プールが単一ノードであるかどうかなどに、より注意を払います。同時に、プラットフォームが VPA をカバーしているため、VPA 調整後の故障率もプラットフォームに依存します。
これに基づき、プラットフォームの検査、リソースプールの検査管理、VPAの検査管理などを行ってきました。検査パネルには、上位リスクのリソース プール/アイドル状態のリソース プール、上位リスクのアプリケーション、および上位リスクのクォータが適宜表示されます。
3.6 キャパシティ管理のビジネス価値

キャパシティ管理の実装後、全体的な作業がビジネスにもたらす助けを直感的に見ることができます.たとえば、キャパシティリソースに起因するリリースの問題は80%削減され、キャパシティの問題に起因するオンライン障害は90%削減されます. %。この観点から、ビジネス部門はキャパシティ管理においてプラットフォームと協力していませんが、キャパシティ管理が実装された後、ビジネスの要求に迅速かつ安定的に対応できることを保証できる最終的なビジネス目標のために全員が協力しています。より大きな改善を達成できます。
4. 容量管理は S12 イベントをどのようにサポートしますか?
先ほど、プラットフォーム側の機能とビジネス側のニーズについて説明しました.次に、B 駅で過去に開催された大規模なイベント S12 を例として、特定のビジネス シナリオにおける容量管理プラットフォームの適用について詳しく説明します。 .
4.1 S12 活動リズム
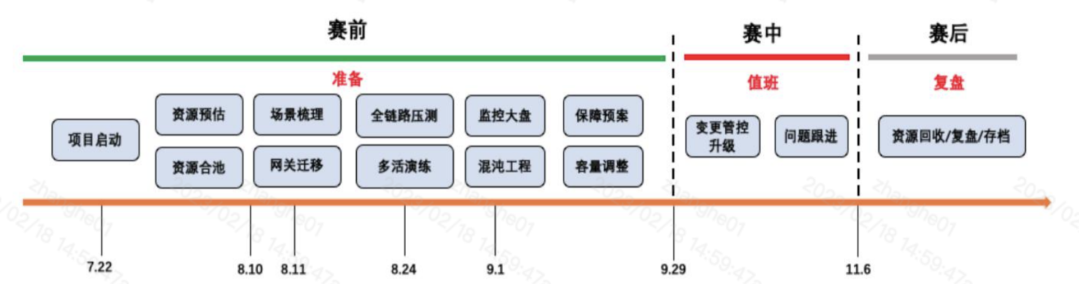
4.2 S12の試合前のキャパシティ推定
S12戦前の能力予想は大きく分けて3段階。
最初のステップは、過去の基本キャパシティ データを参照して、キャパシティ デルタを計算することです。
S イベントや大晦日のパーティーに関係なく、B 局の長年にわたる大規模な活動は、参照用の履歴データを蓄積しており、増分は履歴データに基づいて計算できます。
例えば、S11は11月に総括戦を行い、8月に活動保証を開始した場合、8月の使用量aとS11のピーク時の使用量bを比較し、デルタ=1+(ba)/aからS11を算出する1.3、1.5 など。
2 番目のステップ、S12 新しいシーン、推定増分
S12 には元のベースに基づくいくつかの新しいシナリオがあることを考慮すると、現時点では、ビジネス目標が明確化された後、それらを技術目標に変換する必要があります。次に、技術目標を容量要件に変換して、推定増分 d を取得します。 .
3 番目のステップは、S12 の容量を見積もり、リソース ギャップを取得することです。
リソースの準備では、余分なバッファーは通常 10% から 20% です。推定総容量は、現在の使用量 e と 8 月の S12 のバッファーに基づいて計算できます。式は次のとおりです。
容量の見積もり = (e * デルタ + d) * (1 + バッファー)
推定キャパシティのこの部分から、現在の総リソース ストックを差し引いて、全体的なリソース ギャップを取得し、これに基づいてキャパシティを調整できます。
4.3 S12 の PaaS プール
4.3.1 プール前後の比較
プールする前は、各物理リソースプールは比較的独立しています. 下の図に示すように、コミックビジネスの全体的なリソース使用率は最も低く、生放送は飽和に近づいている可能性があります.完全に独立した物理リソース プール、コミック、e コマース ビジネスのアイドル状態のリソースを活用できません。S11 期間などの前の年には、アクティビティ全体をサポートするために、クラウドからリソースを購入するか、一時的にリソースを追加する必要がありました。
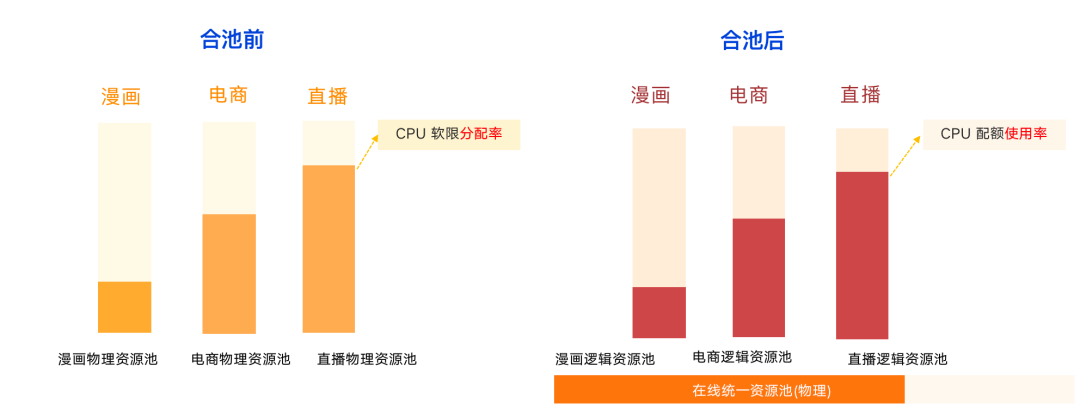
S12 コンテストの前に、コミック、e コマース、ライブ放送などのオンライン マイクロサービスをプールした後、ビジネスは物理リソース プール全体を気にする必要がなくなりました。基になる割り当てや使用率ではなく、独自のビジネス ロジック クォータ。物理レベルでは、オンラインの統合された物理リソース プールがあり、基盤となる割り当て率と使用率は SRE とプラットフォームによって完全に保証されます。
4.3.2 プールプーリングの潜在的なリスク
プール後、リソースプールが異なれば、カーネルのバージョンが異なるなどの不安定要因が発生する可能性があるため、物理層全体を標準化し、カーネルを統合し、CPUSET を削除しました. 基盤となる VPA ポリシーを動的に介して全体的なリソース使用量を調整します。
4.4 S12のクォータ管理
プール後の各業務はリソースプールを共有するため、各業務のリソースクォータを細分化して管理し、リソースを無制限に使用しないようにする必要があります。ここではキャパシティ管理プラットフォームを介して管理し、キャパシティ クォータを発行するロジックを次の図に示します。
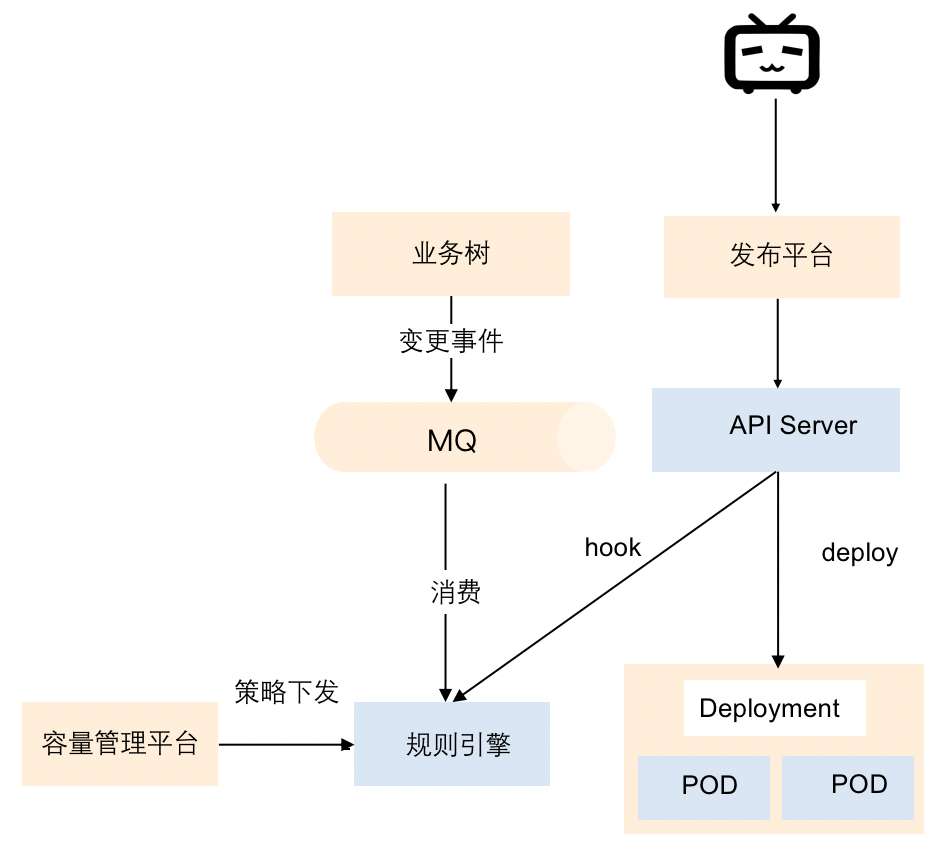
クォータは、組織の数に基づいて発行されます.たとえば、組織が使用できるクォータの数.ポリシーが発行された後、ルールエンジンに適用されます.公開前など、業務が変化した場合、対応するビジネスはルールプラットフォームで学習されます クォータがリリースに十分かどうかを確認します.リソースが十分でない場合, クォータが不足していることを通知します.この場合, SREに連絡してクォータを調整するか, クォータを実行する必要があります.管理。このようにして、クォータ制御を実現し、リソース プール全体が無差別に使用されないようにすることができます。
4.5 S12 の容量サポート
S12 イベント全体で、キャパシティ サポートは、下図に示すように、HPA、VPA、エラスティック クラウド移行、およびキャパシティ インスペクションの 4 つの側面に大まかに分けることができます。
4.6 S12容量監視パネル
S12 イベントの保証については、全体的な懸念事項のコア インジケーターには、ビジネス インジケーター、SLO、およびリソースの飽和が含まれます. キャパシティ モニタリング パネルは、潜在的なリスク ポイントをより迅速に特定し、コア インジケーターに基づいて迅速に意思決定を行うのに役立ちます.
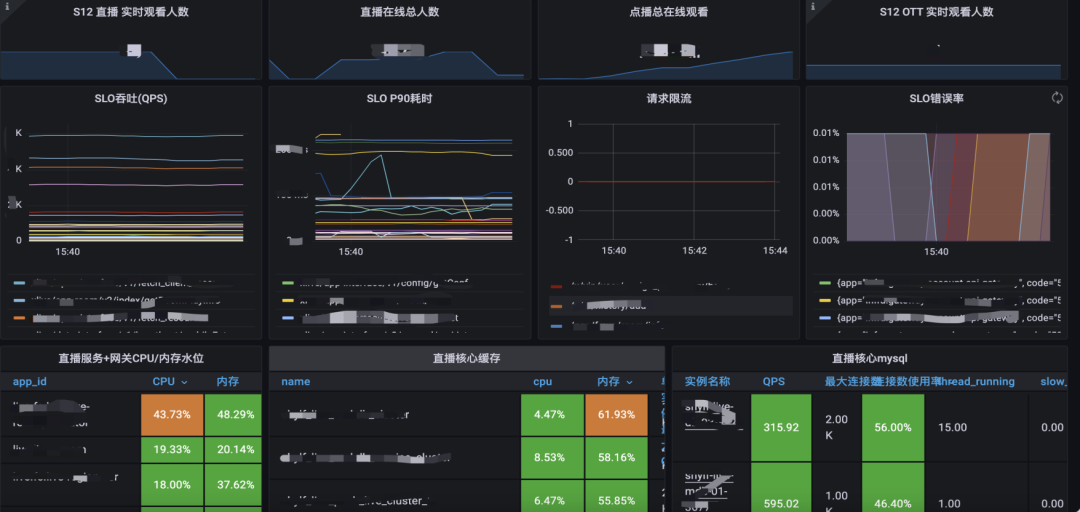
1 つ目はビジネス指標で、S12 では、1000 万人以上、2000 万人以上など、生放送室でオンラインになっている人の数にもっと注意を払います。イベント期間中の全体的なトラフィックが増加すると、オンデマンド ビジネスにも影響が及ぶため、オンライン オンデマンドの数も注目するビジネス指標の 1 つです。
SLO に続いて、SRE チームはコア インターフェースの QPS、スループット、遅延、エラー率などにさらに注意を払うようになります。
最後は、コア サービスの飽和、コア ミドルウェアの飽和などを含むリソースの飽和です。
5. 今後の計画
5.1 容量リスク管理
一部のサービスの容量変更操作には根拠がないことがわかりました。たとえば、当然のことと考えられている容量の縮小など、プロンプトまたは検証する指標がなければ、サービスの障害につながる可能性があります。そのため、キャパシティ ポートレートとアプリケーション グループ パッケージに基づいて、キャパシティ リスク コントロールに関連するインターセプト戦略を実行し、キャパシティ変更リスク コントロールを実現します。
5.2 エラスティックスケーリング
最初のブロックは時分割スケジューリングです。ステーション B には、コミック ビジネスなどの小規模なアクティビティがいくつかあります。これは、基本的に夜間に約 1 時間のピーク トラフィックがあり、その他の時点では通常のトラフィックです。夜の0時から1時までの活動など、時分割のスケジューリングを加えた上で、23時までに事前に定員を拡大し、イベント終了後に定員の縮小を完了することができます。2 番目のブロックは、弾力的な予測です。定常流圧を事前に予測して容量を拡張することができる一方で、監視システムがダウンした場合には、弾力的な予測データを監視データのボトムラインとして使用することもできます。
5.3 ホットスポットの分割
ソフト リミットに基づいてスケジューリングを行っており、ソフト リミットも VPA に基づいて調整されますが、それでも一部のサービスでは物理マシンにホット スポットが発生することは避けられないため、物理マシンに基づいて 2 次スケジューリングを行います。(全文)


アシスタントの女性 (shulie888) を追加し、スクリーンショットで上記のすべての情報を無料で入手してください
「TakinTalks Readers Exchange Group」に無料で参加できます
免責事項: この記事は、もともと公開アカウント「TakinTalks Stability Community」とコミュニティの専門家によって書かれました. 転載する必要がある場合は、許可を得るためにバックグラウンドで「転載」と返信してください.
この記事は、ブログのマルチポスト プラットフォームであるOpenWriteによって公開されています。