
作者 | 夢のように浮かぶ石
ガイド
リアルタイム コンピューティング テクノロジーがビッグ データに広く適用されることで、データの適時性が大幅に向上しましたが、実際のアプリケーション シナリオでは、適時性に加えて、より高い技術的要件にも直面しています。
この論文は、水位技術の概念と関連する理論的実践、特に実際の水位の特性、境界定義、および適用に焦点を当てて、フローバッチ統合データウェアハウスにおけるリアルタイムコンピューティング水位技術の調査と実践を組み合わせたものです。 -time コンピューティング システム、そして最後に説明に焦点を当てます。正確な水位の改善された設計と実装が提示されます。技術アーキテクチャは現在、Baidu の実際のビジネス シナリオで成熟しており、安定しています。皆様の参考になることを願って、共有したいと思います。
全文は 7118 ワードで、予想読了時間は 18 分です。
01 事業背景
製品開発、戦略の反復、データ分析、および運用上の意思決定の効率を向上させるために、企業はデータの適時性に対する要件をますます高くしています。
リアルタイム コンピューティングに基づくリアルタイム データ ウェアハウスの構築は非常に早い時期に実現しましたが、それでもオフライン データ ウェアハウスに取って代わるものではありません. リアルタイムおよびオフライン データ ウェアハウスのセットの開発と保守のコストは高く、最も重要なことは、ビジネスの能力は 100% ではないということです。したがって、ストリーム バッチ統合データ ウェアハウスの構築に取り組んできました。これは、全体的なデータ処理効率を高速化するだけでなく、データがオフライン データと同じくらい信頼性が高く、100% ビジネス シナリオをサポートできることを保証します。全体のコスト削減と効率化を実現します。
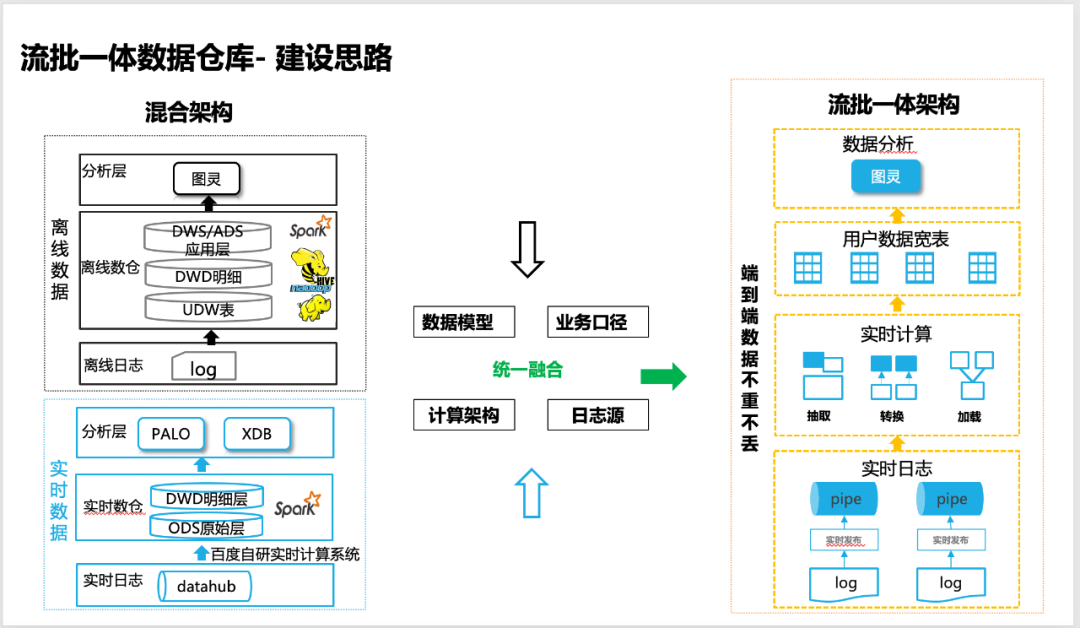
△ストリームバッチ統合データウェアハウス構築の考え方
02 Stream-Batch統合データウェアハウスの技術的難点
エンドツーエンドの統合されたストリーミングおよびバッチ データ ウェアハウスを、基礎となる技術アーキテクチャのリアルタイム コンピューティング システムとして実現するために、多くの技術的な困難と課題に直面しています。
1. データの整合性を確保するために、エンドツーエンドのデータは厳密に繰り返されたり失われたりしません。
2.リアルタイム データ ウィンドウとオフライン データ ウィンドウは、データを含めて調整されます (99.9% ~ 99.99%)。
3.リアルタイム計算は、リアルタイムのアンチチート戦略の正確な効果を確保するために、正確なウィンドウ計算をサポートする必要があります。
4.リアルタイムコンピューティングシステムはBaiduの内部ビッグデータエコロジーと統合されており、大規模なオンライン安定運用の実際の実践があります。
上記の 2 と 3 のすべての点で、進行状況の認識とリアルタイム データの正確なセグメンテーションを確実にするために、信頼性の高い水位メカニズムが必要です。
したがって、この記事では、ストリーム バッチ統合データ ウェアハウスでの正確な水位の調査と実際の経験を共有します。
03 水位概念の現状と一般的な実施
3.1 水位の必要性
透かしの概念を導入する前に、2 つの概念を挿入する必要があります。
-
イベント時間、イベントが発生した時間。通常、これはユーザーの実際の行動が発生した時間として理解されており、具体的にはログでユーザーの行動が発生したときのタイムスタンプに対応しています。
-
処理時間、データ処理時間。通常、システムがデータを処理する時間と理解しています。
透かしの具体的な用途は何ですか?
実際のリアルタイム データ処理プロセスでは、データは無制限 (Unbounded) であるため、Window に基づくウィンドウ コンピューティングまたは他の同様のシナリオは実際的な問題に直面します。
特定のウィンドウ内のデータが完全であることをどのように確認しますか? ウィンドウcompute()はいつトリガーできますか?
ほとんどの場合、Event Time を使用してウィンドウ計算 (またはデータ パーティション分割とオフライン アライメント) をトリガーします。ただし、実際の状況では、リアルタイム ログには常に異なる程度の遅延 (ログ収集、ログ送信、およびログ処理の段階) があります。つまり、下の図に示すように、ウォーターマークのスキューは実際には発生します (つまり、データが順不同で表示されます)。この場合、データの整合性を確保するために透かしメカニズムが必要です。
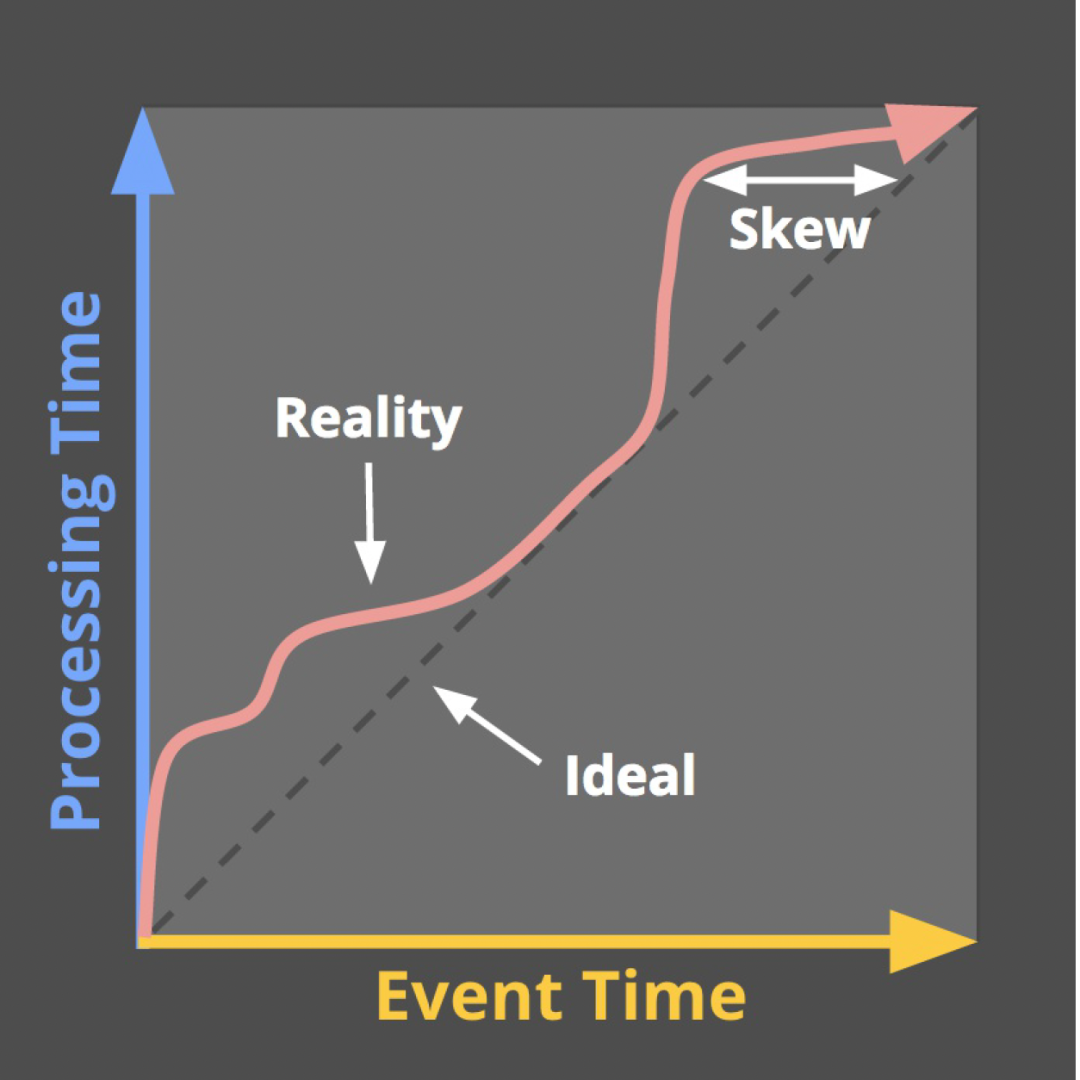 △水位傾斜現象
△水位傾斜現象
3.2 水位の定義と特徴
透かし(透かし)の定義は現在、業界で統一されていませんが、本** Streaming Systems ** (著者は Google Dataflow R&D チーム) の定義と組み合わせると、個人的にはより正確だと思います。
透かしは、まだ完了していない最も古い作業の単調に増加するタイムスタンプです。
この定義から、水位の 2 つの基本的な特徴を要約できます。
-
水位が上昇し続ける(返却不可)
-
水位はタイムスタンプです
しかし、実際の生産システムでは、水位をどのように計算し、実際の効果は何ですか?業界のさまざまなリアルタイム コンピューティング システムと組み合わせても、水位のサポートは依然として異なります。
3.3 水位の現状と課題
Apache Flink (Google Dataflow のオープン ソース実装) や Apache Spark (Structured Streaming フレームワークのみに限定) など、業界の現在のリアルタイム コンピューティング システムでは、すべて水位をサポートしています。コミュニティの Apache Flink. 水位の実装メカニズムを一覧表示します。

ただし、上記の水位の実装メカニズムと効果により、ログ送信元で大きな領域のログ送信の遅延が発生した場合でも、水位は更新されます (新旧のデータが順不同で送信されます)。これにより、対応するウィンドウのデータが不完全になり、ウィンドウの計算が不正確になります。そのため、Baidu 内では、ログ収集および送信システムとリアルタイム コンピューティング システムに基づいて、改善された比較的正確な水位メカニズムを調査し、ウィンドウとデータ ランディング (シンクから AFS) でリアルタイム データが確実に計算されるようにしました。 /Hive) とその他のアプリケーション シナリオ 次に、ウィンドウ データの整合性の問題は、ストリーム バッチ統合データ ウェアハウスを実現するための要件を満たすことです。
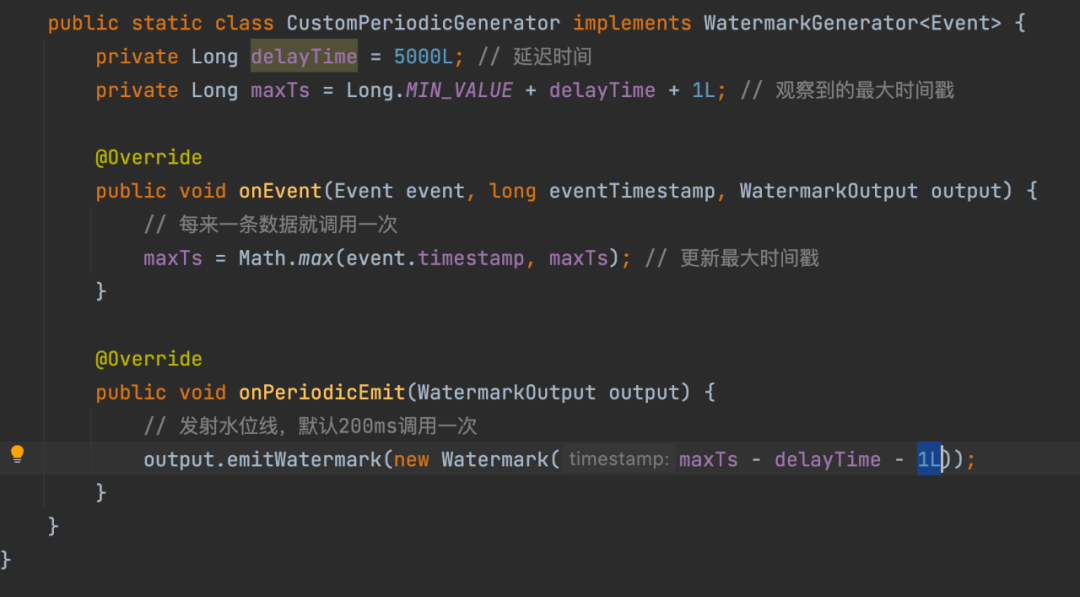
△フリンク水位生成作戦
オタクトーク
04 全球水位の設計と応用
4.1 集中水位管理の設計
リアルタイム計算で水位をより正確にするために、集中型水位管理のアイデアを設計しました。つまり、ソース、オペレーター、シンカーなどを含むリアルタイム計算の各ノードが水位を報告します。独自に計算した情報をグローバルな透かしサーバーに送信し、水位情報の一元管理を透かしサーバーで行います。
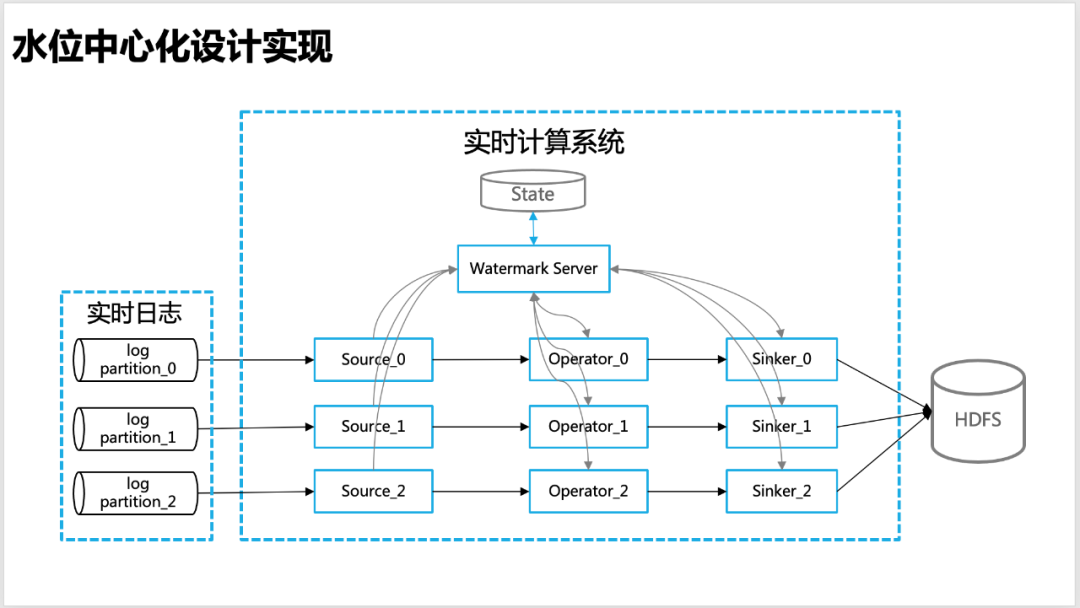
△集中水位設計
Watermark Server : リアルタイム計算プログラム (APP) の全体的なトポロジー情報 (Source、Operator、Sinker など) の各レベルに対応する水位情報を含む水位情報テーブル (hash_table) を維持するため、グローバルな水位 (低水位標など) の計算を容易にするために、Watermark Server は定期的に状態と対話して、水位情報が失われないようにします。
ウォーターマーク クライアント: ソース、ワーカー、シンカーなどのリアルタイム オペレーターの水位更新クライアントは、水位情報 (上流またはグローバル水位など) をウォーターマーク サーバーに報告および要求し、baidu-rpc を介してコールバックを要求します。サービス。
ロー ウォーターマーク (ロー ウォーター レベル) : ロー ウォーターマークは、リアルタイム データ処理プロセスで最も古い (最も古い) 未処理のデータの時間をマークするために使用されるタイムスタンプです (ロー ウォーターマーク。最も古い未処理のイベント時間を悲観的に捉えようとします)。システムが認識していることを記録します。 ) そのタイムスタンプより前に将来のデータが到着しないことを約束します。ここでの時間の計算は、通常、イベント時間、つまり、ログ内のユーザーの行動が発生した時間などのイベントが発生した時間と、データ処理時間 (処理時間、一部のシナリオで使用することもできます) に基づいています。ウォーターマークの計算式は次のとおりです (Google MillWheel Thesisから):
A の Low Watermark = min(A の最も古い作業、C の Low Watermark : C が A に出力)
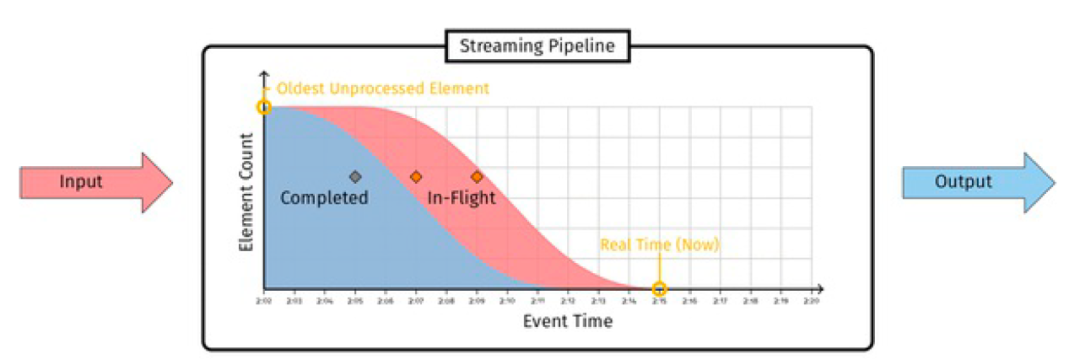
ただし、実際のシステム設計では、以下のようにオペレータ処理の境界に従ってロー ウォーターマークを区別できます。
-
Input Low Watermark : このストリーミング ステージにまだ送信されていない最も古い作品。
InputLowWatermark(ステージ) = min { OutputLowWatermark(ステージ') | Stage' は Stage} の上流です}
現在のオペレーターに入力されるウォーターマーク、つまり上流のオペレーターによって処理されたデータとして理解できる最低水位を入力します。
-
Output Low Watermark : このストリーミング ステージでまだ完了していない最も古い作業。
OutputLowWatermark(Stage) = min { InputLowWatermark(Stage), OldestWork(Stage) }
現在のオペレータが未処理データの最も古い(最も古い)水位と理解できる最低水位、つまり処理済みデータの水位を出力します。
下図のように、理解がより鮮明になります。
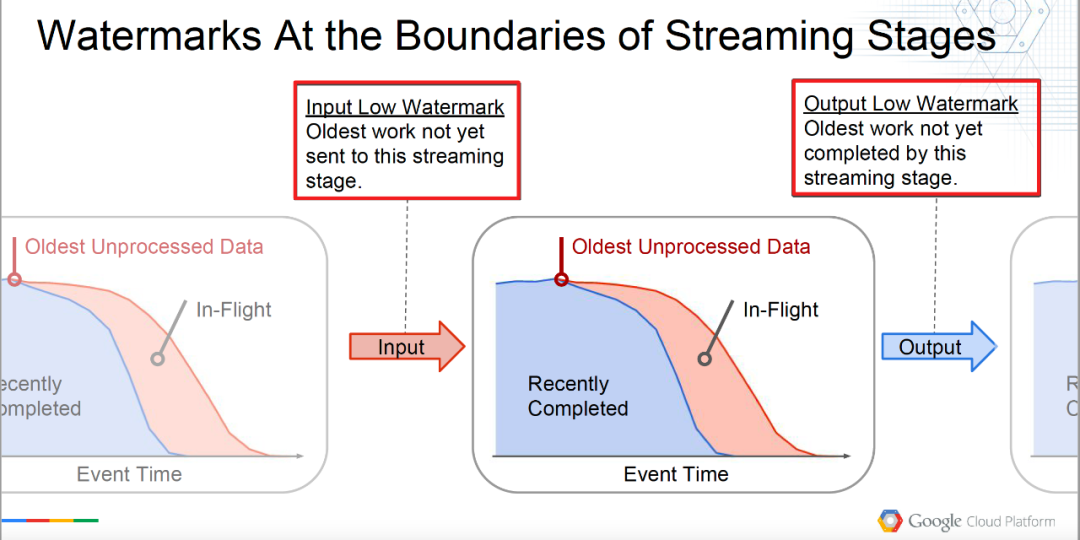 △ローウォーターマークの境界定義
△ローウォーターマークの境界定義
4.2 正確な水位を達成する方法
4.2.1 正確な水位の前提条件
現在、リアルタイム データ ウェアハウスでのリアルタイム コンピューティング システムのアプリケーション シナリオでは、ウィンドウ計算をトリガーするために低ウォーターマークを使用しています (信頼性が高いため)。3.1 の低ウォーターマークの定義から、 : 低水位標は階層的な反復によって計算され、水位が正確であるかどうかは、最上流 (つまりソース) の水位の精度に依存します。したがって、源水位計算の精度を向上させるためには、次の前提条件が必要です。
-
サーバー側の単一サーバーで時間 (event_time) に従ってログが順次生成されます。
-
ログが収集されると、次の図に示すように、実際のユーザーの動作ログに加えて、サーバー タグ (ホスト名) やログ時間 (msg_time) などの他の情報も含まれている必要があります。

△ ログのパッケージ情報
-
ログは、メッセージ キューの 1 つのパーティション内で、1 つのサーバーのログが厳密に順序付けられるように、リアルタイムのポイント ツー ポイントでメッセージ キューに発行されます。
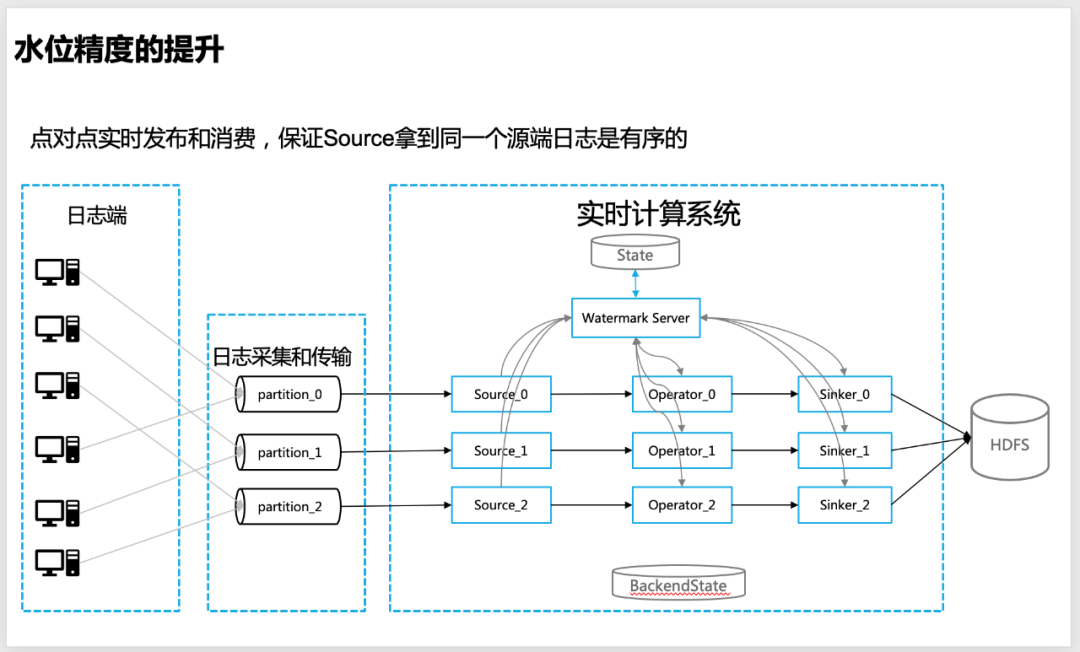
△ソース ログはメッセージ キューにポイント ツー ポイントで発行され、単一パーティション ログが整然としていることを確認します
4.2.2. 水位の計算方法
1、透かしサーバー
初期化:
最初は別のスレッド(スレッド)として開始されました。構成されたログ送信タスクの BNS (Baidu Naming Service、サービス名からサーバーの実行中のすべてのインスタンスへのマッピングを提供する Baidu ネーム サービス) に従って、ログ ソースのサーバー リスト (ホスト名リスト) が解析されます。構成された APP トポロジ関係に従って、透かしは初期化された情報テーブルであり、永続的な書き込みテーブル (Baidu 分散 kv ストレージ エンジン) です。
通常の水位情報更新: クライアントから水位情報を受け取り、対応する粒度 (プロセッサ粒度またはキーグループ粒度) の水位を更新し、ローカル水位を更新します。
正確な水位計算:
実際には、ソースのログが 100% 正確に到着する必要がある場合、頻繁に遅延が発生したり、遅延が長すぎたりします (配布にグローバルな低ウォーターマーク ロジックが使用されている場合)。その理由は、ログ側のサーバー インスタンスが多すぎる場合 (たとえば、実際には 6000 ~ 10000 のログ インスタンスがある場合)、有線オンライン サービスのインスタンスでのログのリアルタイム アップロードで常に遅延が発生するためです。 、したがって、これは、データの整合性と適時性との間で妥協することで行う必要があります。たとえば、パーセンテージの形式で遅延を許可するインスタンスの数を正確に制御するなどです (たとえば、99.9% または 99.99% を構成して、ソースを許可する比率を設定します) 。ログが遅れる)、正確に 水位の精度を正確に制御します。
正確な水位には、特別な構成が必要です. ソースの出力の最低水準点は、サーバーと、ソースによってリアルタイムで報告されるログの進行状況との間のマッピング関係、および許容される遅延インスタンスの構成された比率に従って計算されます.
グローバルな最低水位標を計算します: グローバルな最低水位が計算され、クライアントの要求に返されます
状態の持続性: 状態の回復を容易にするために、グローバルな水位情報の持続性を外部ストレージに定期的に書き込みます
2、透かしクライアント
ソースエンド: ログ パッケージを解析し、ログ パッケージ内のマシン名や元のログなどの情報を取得します。元のログが ETL によって処理され、元のログに従って最新のタイム スタンプ (event_timestamps) が取得された後、Source は、ホスト名に解決されたマッピング関係テーブルと最新のタイム スタンプ (event_timestamps) を、Watermark クライアント API (現在、 1000 ミリ秒を設定) を透かしサーバーに送信します。
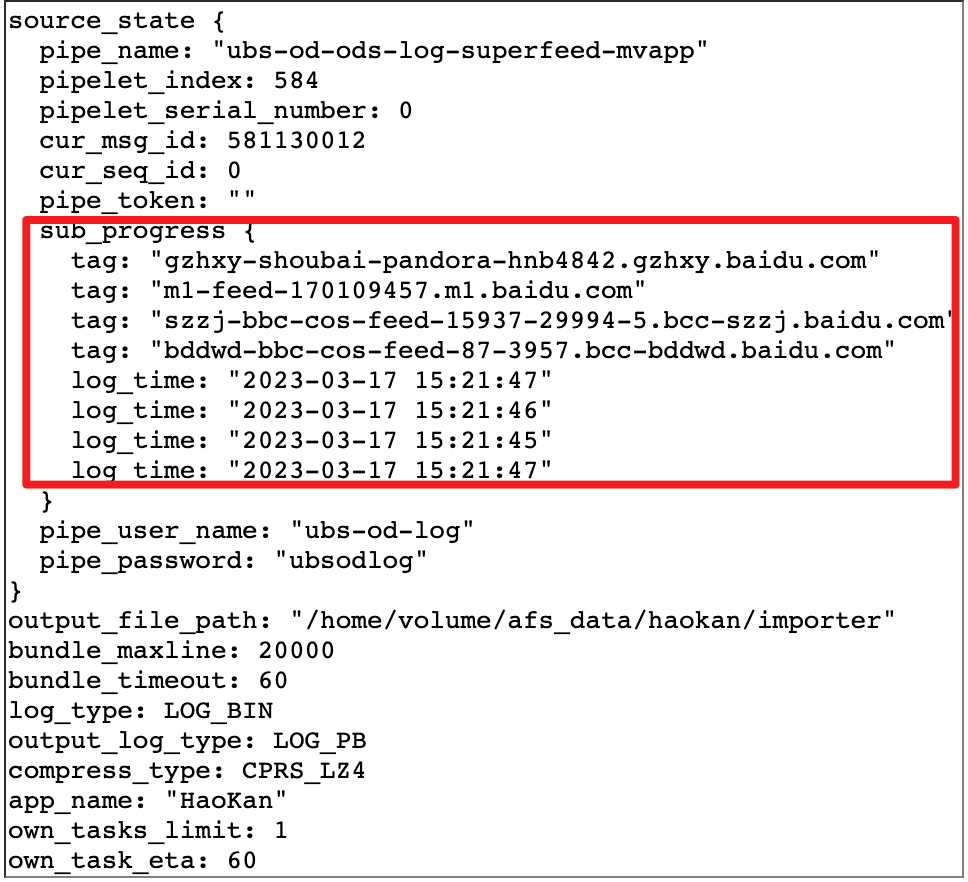
△Source ログを解析して得られたサーバーとログの進行状況のマッピング関係
オペレーター側:
入力ロー ウォーターマーク計算: アップストリーム (アップストリーム) の出力ロー ウォーターマークを入力ロー ウォーターマークとして取得し、ウィンドウ計算およびその他の操作をトリガーするかどうかを決定します。
出力のロー ウォーターマークの計算: ログ、ステータス (状態)、およびその他の処理の進行状況 (最も古い作業) に基づいて独自の出力のロー ウォーターマークを計算し、それをダウンストリーム オペレーター (ダウンロード プロセッサ) が使用するためにウォーターマーク サーバーに報告します。
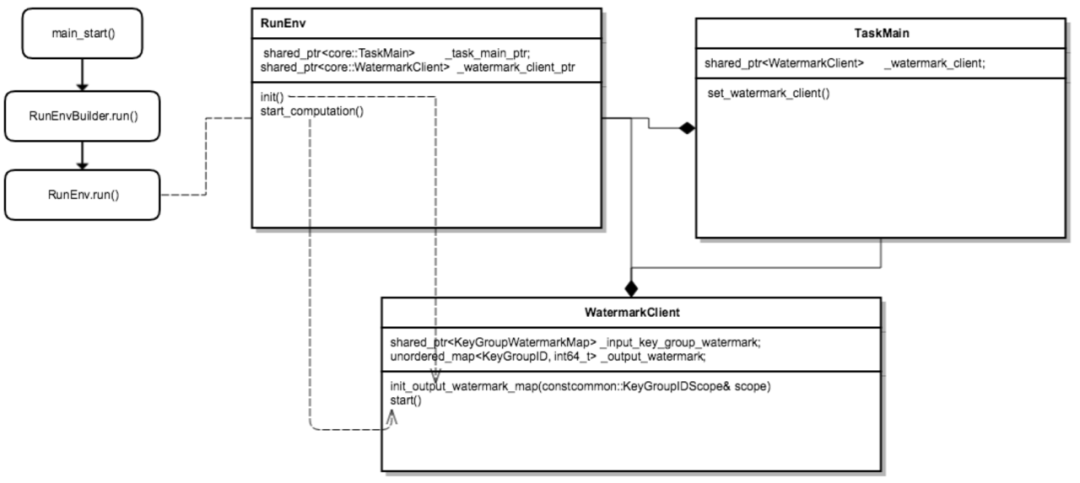
△透かしクライアントのワークフロー
シンカー側:
シンカー側は上記の通常のリアルタイムオペレーター(Operator)と同じで、Input Low WatermarkとOutput Low Watermarkを計算して自身の水位を更新し、
さらに、データ出力ウィンドウが閉じているかどうかを判断するために、グローバルな Low Watermark を要求する必要があります。
4.3 システム間の正確な水位の伝達
水位移動の必要性
多くの場合、リアルタイム システムは分離されておらず、複数のリアルタイム コンピューティング システム間でデータのやり取りが行われています。最も一般的な方法は、2 つのリアルタイム データ処理システムが上流と下流にあることです。
具体的なパフォーマンスは次のとおりです。2 つのリアルタイム データ処理システムがメッセージ キュー (コミュニティの Apache Kafka など) を介してデータ転送を実装しているため、この場合、正確な水位転送を実現するにはどうすればよいでしょうか?
具体的な実装手順は次のとおりです。
1.上流のリアルタイムコンピューティングシステムのログソースは、ログがポイントツーポイントでリリースされることを保証します。これにより、グローバルな水位の精度が保証されます(特定の比率は調整可能です)。
2. 上流のリアルタイム コンピューティング システムの出力側 (メッセージ キュー側へのシンカー/エクスポーター) で、グローバルな低水位標が発行されていることを確認する必要があります.現在、出力されるグローバルな水位情報を使用しています各ログで配信を実現します。
3. 下流のリアルタイム データ計算システムのソース側では、(上流のリアルタイム計算システムからの) ログによって運ばれる水位情報フィールドを分析し、それを入力として使用する必要があります。水位 (入力低水位標) を入力し、レイヤーごとの水位の反復計算とグローバル水位計算を開始します。
4. 下流のリアルタイム データ コンピューティング システムのオペレーター/シンカー側では、ログのイベント時間を使用して、ウィンドウ計算の入力として特定のデータ セグメンテーションを実現できますが、ウィンドウ計算をトリガーするメカニズムは依然としてベースになっています。ウォーターマーク サーバーによって返されたグローバル データでは、データの整合性を確保するために低ウォーターマークが優先されます。
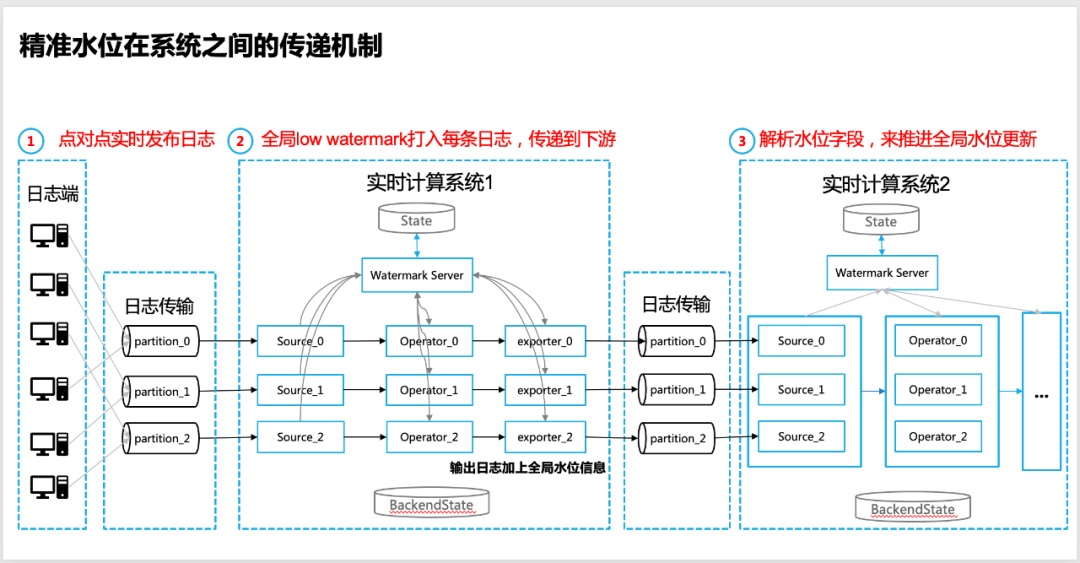
△リアルタイムコンピューティングシステム間の正確な水位の転送メカニズム
05 実際の効果とその後の見通し
5.1 実際のオンライン効果
5.1.1 測定された着陸データの効果 (完全性)
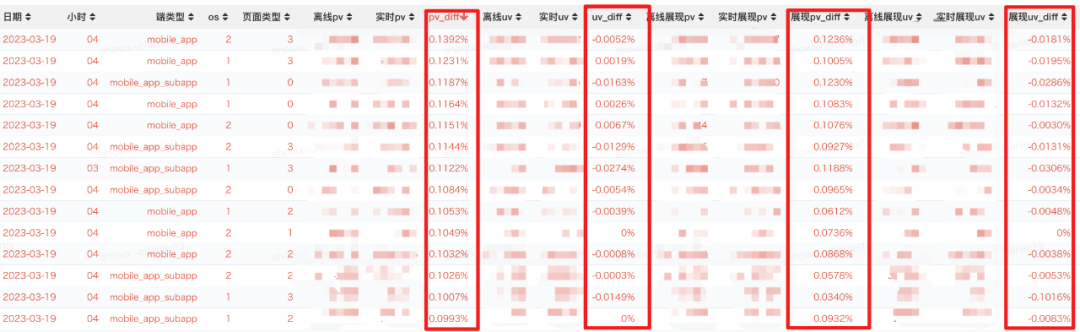
実際のオンライン テストでは正確な水位が採用され (設定された水位の精度は 99.9%、つまり、ソース インスタンスの遅延の 1000 分の 1 のみが許容されます)、ログに遅延がない場合、リアルタイムの着陸データとオフライン データは同じ時間枠 (イベント時間) にあります。効果の比較は次のとおりです (基本的にすべて 100,000 ポイント未満)。

△ソースログが遅延していない場合のデータ整合性の影響
ソース ログが遅延した場合 (ソース ログ インスタンスの <=0.1% が遅延した場合、水位は更新され続けます)、全体のデータ差分効果は基本的に約 1/1,000 です (ログ ソース ポイントの可能性に依存します)。 -to-point ログ自体 データの不均一性の影響):

ソース ログに大きな遅延領域がある場合 (ソース ログ インスタンスの遅延の >0.1%)、正確な水位メカニズム (水位精度 99.9%) の使用により、グローバルな水位は更新されず、リアルタイム データが AFS に書き込まれます。ウィンドウは閉じられません。ウィンドウは、遅延データの到着とグローバルな水位の更新を待ってから閉じられ、データの完全性が保証されます。データ. 実際のテスト結果は次のとおりです (ログ ソースに応じて、1000 あたり 1.1 ~ 1.2 の範囲で、インスタンス自体にばらつきの影響があります)。
5.2 まとめとプレゼンテーション
実際の正確な水位と実際のオンラインアプリケーションに関する研究の後、正確な水位に基づくリアルタイムデータウェアハウスは、適時性を向上させるだけでなく、より高度で柔軟なデータ精度メカニズムを備えており、安定性を最適化した後、実際には以前のオフラインおよびリアルタイムのデータ ウェアハウス システムの代わりに、真のストリーム バッチ統合データ ウェアハウスが実現されます。
同時に、集中化された水位メカニズムに基づいて、パフォーマンスの最適化、高可用性 (障害回復メカニズムの改善)、およびより細かい粒度と正確な水位 (ウィンドウ計算トリガー メカニズムの下) の課題にも直面します。
- 終わり -
参照:
[1] T. Akidau、A. Balikov、K. Bekiroğlu、S. Chernyak、J. Haberman、R. Lax、S. McVeety、D. Mills、P. Nordstrom、および S. Whittle。Millwheel: インターネット規模でのフォールト トレラントなストリーム処理。議事録 VLDB 基金、6(11):1033–1044、2013 年 8 月。
[2] T. Akidau、R. Bradshaw、C. Chambers、S. Chernyak、RJ Fernández-Moctezuma、R. Lax、S. McVeety、D. Mills、F. Perry、E. Schmidt、他。データフロー モデル: 大規模で制限のない順不同のデータ処理において、正確性、レイテンシ、およびコストのバランスを取るための実用的なアプローチ。VLDB 基金の議事録、8(12):1792–1803、2015 年。
[3] T. Akidau、S. Chernyak、R. Lax。ストリーミング システム。O'Reilly Media, Inc.、第 1 版、2018 年。
[4] 「透かし - ストリーミング パイプラインの時間と進行状況の測定」、Slava Chernyak、Google Inc
[5] P. Carbone、A. Katsifodimos、S. Ewen、V. Markl、S. Haridi、および K. Tzoumas。Apache flink: 単一のエンジンでのストリーム処理とバッチ処理。IEEE Computer Society Technical Committee on Data Engineering の会報、36(4)、2015 年。
推奨読書:
ビデオ編集シナリオにおけるテキスト テンプレートの技術的ソリューション
アンチチートの活動シーンにおけるグラフアルゴリズムの応用について語る
サーバーレス: パーソナライズされたサービス ポートレートに基づく柔軟なスケーリングの実践
パフォーマンス プラットフォーム データ アクセラレーション ロード