
共有ゲスト:
Fu Qingwu - OPPO データ アーキテクチャ グループのビッグ データ アーキテクト
OPPO の実際のアプリケーションでは、自社開発した Shuttle と Alluxio を完璧に組み合わせることで、Shuttle サービス全体のパフォーマンスが大幅に向上し、基本的にパフォーマンスが 2 倍になりました。この最適化により、システム圧力を約半分に低減し、スループットを直接2倍にすることに成功しました。この組み合わせは、パフォーマンスの問題を解決するだけでなく、OPPO のサービス システムに新たな活力を注入します。
全文版共有内容↓
共有トピック:「Data&AI Lake とウェアハウス統合における Alluxio の実践」
データと AI を統合したデータレイク ウェアハウス アーキテクチャ
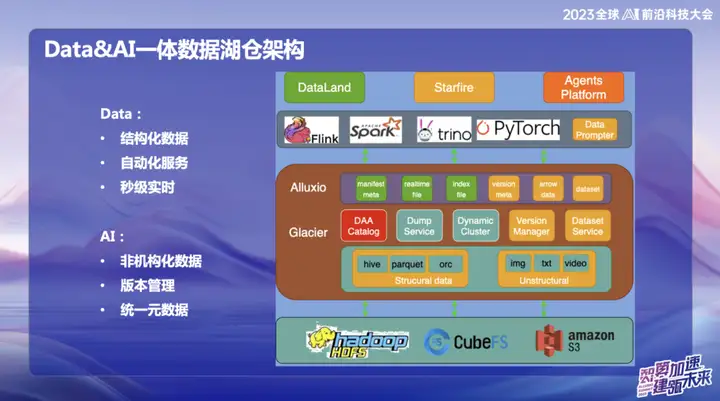
上の図は OPPO の現在の全体的なアーキテクチャを示しており、主に 2 つの部分に分かれています。
1、データ
2、AI
データ分野では、OPPO は構造化データ、つまり通常 SQL を使用して処理されるデータに主に焦点を当てています。 AIの分野では、主に非構造化データに焦点が当てられています。 OPPOでは、構造化データと非構造化データの一元管理を実現するために、カタログメタデータの形で管理するData and Catalogというシステムを構築しています。同時に、これはデータ レイク サービスでもあり、上位データ アクセス層は Alluxio 分散キャッシュを使用します。
Alluxio を使用することを選択した理由は何ですか?
OPPO の国内コンピュータ室は大規模であるため、コンピューティング ノード上のアイドル メモリの量はかなりのものになります。毎日平均して約 1PB のメモリがアイドル状態であると推定されており、この分散メモリ管理システムを通じてそれを最大限に活用したいと考えています。オレンジ色の部分は非構造化データの管理を表しています。私たちの目標は、データ レイク サービスを使用して非構造化データを構造化データと同じくらい簡単に管理し、AI トレーニングを高速化することです。
DAAカタログ
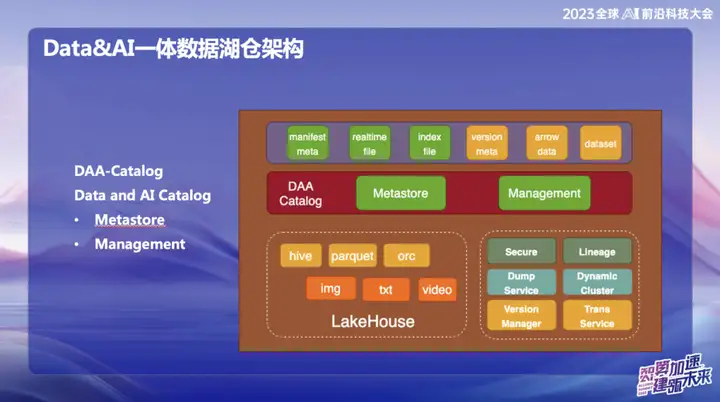
DAA-Catalog (データおよび AI カタログ) は、データ アーキテクチャの最下位で当社のチームが追求する目標です。OPPO が業界最高の企業との競争に全力を尽くしているため、この名前を選択しました。現在、Databricks はデータと AI の分野で最も優れた企業の 1 つであると考えています。テクノロジー、先進的なコンセプト、ビジネス モデルのいずれにおいても、Databricks は好成績を収めています。
Databricks の Unicatalog からインスピレーションを得た、Databricks のサービス データと AI トレーニング プロセスは主に Unity Catalog を中心に展開していることがわかります。したがって、データ レイク ウェアハウジング分野で業界最高の企業と競争するという目標を追求するために、DAA-Catalog を構築することにしました。
具体的には、この機能は 2 つの主要モジュールに分かれています。
-メタストア (メタデータ ストレージ) : この部分はメタデータの管理を担当し、基礎となる層は Iceberg メタデータ管理に基づいています。同時コミットとライフサイクル管理が含まれます。同時に、データはまず Alluxio の巨大なメモリ キャッシュ プールに入力され、各レコードのリアルタイムの挿入とクエリが実現されるため、管理には Down Service を使用します。
-管理: この部分は DOM サービスです。なぜ Down Service を選択するのですか?データは入力後初めて Alluxio のメモリに保存されるため、第 2 レベルのリアルタイム パフォーマンスが実現されます。プロセス全体を通じて、データは受信後に Catalog を通じて自動的に Iceberg に送信され、メタデータは基本的に Alluxio にあります。
なぜこのような第 2 レベルのリアルタイム関数を実装する必要があるのでしょうか?
その主な理由は、以前に Iceberg を使用したときに重大な問題が見つかったためです。基本的に 5 分ごとにコミットが必要となり、Flink コンピューティング システムと HDFS のメタデータに多大な負荷がかかります。同時に、これらのファイルも手動でクリーンアップしてマージする必要があります。 Alluxio サービスを通じて、データをメモリに直接入力でき、Down Service もカタログを通じて管理されます。プロセス全体を通じて、データは入力後に自動的に Iceberg に保存され、メタデータは基本的にすべて Alluxio にあります。
OPPO は Alluxio との連携が盛んなので、バージョン 2.9 をベースにいくつかの調整を加え、パフォーマンスが大幅に向上しました。ストリーミング ファイルの読み取りと書き込みはデータ レイク上で実装され、ファイル全体をコミットする必要がなく、各データをコミットのように扱うことができます。
構造化データの高速化
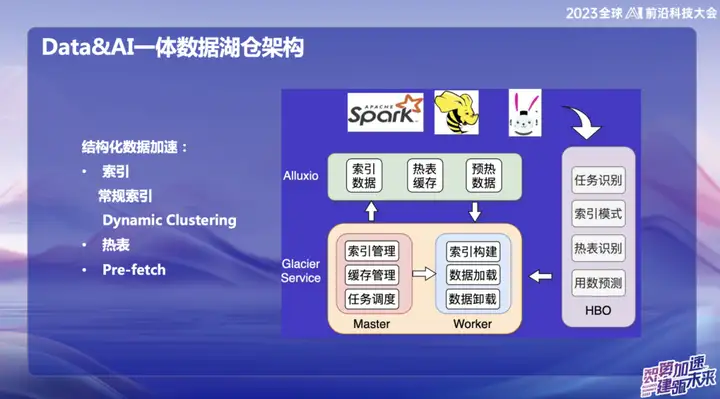
ビッグデータの発展により、多くのインフラストラクチャが完全になり、さまざまなシナリオの問題を解決できるようになりました。ただし、私たちが焦点を当てているのは、アイドル状態のリソースとメモリをより効率的に利用する方法です。したがって、私たちは 2 つの側面から始めることに注力しています。1 つはキャッシュの高速化、もう 1 つはホット テーブルとインデックスの最適化です。
Databricksの技術をヒントに、動的にデータを集約する機能「Dynamic Cluster」という概念を提案しました。 Hallway カーブも内部的に使用されていますが、その上に「the order」および「incremental the order」ソート アルゴリズムを実装し、それらを融合して動的クラスターを形成しました。このイノベーションにより、データ入力後にデータを動的に集約し、クエリ効率を向上させることができます。ホールウェイ カーブと比較すると、「順序」アルゴリズムの方が効率的ですが、リアルタイムの変化ではホールウェイ カーブの方が優れています。この統合により、データのクエリと集計を行うためのより柔軟かつ効率的な方法が提供されます。
非構造化データの管理
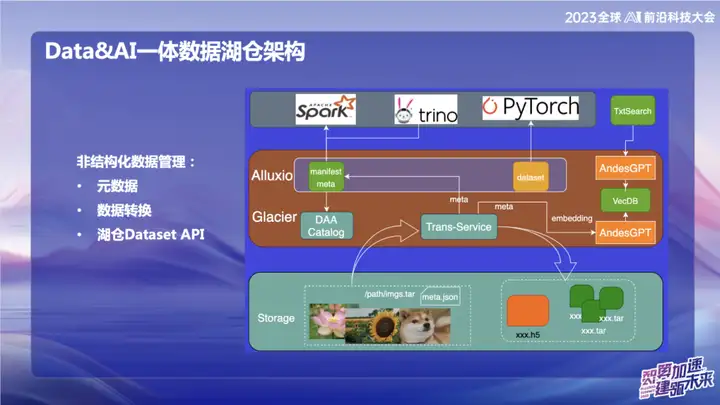
上の図は、主に AI 分野に関連する、非構造化データの分野における当社の取り組みの一部を示しています。 OPPO 内では、最初に AI トレーニングに使用されるツールは比較的古いもので、データは通常、スクリプトを通じて直接読み取られるか、または裸の txt ファイルまたは裸の画像ファイルの形式でオブジェクト ストレージに保存されます。 Transfer サービスを使用すると、データをデータ レイクに自動的にインポートし、パッケージ化されたイメージ データを更新セット形式に切り取ることができます。 AI の分野、特に画像処理の分野では、アップデート セットは Web データ セット インターフェイスと互換性があるだけでなく、H5 形式に変換することもできる効率的なデータ セット インターフェイスです。
私たちの目標は、メタデータを処理することで、非構造化データの管理を構造化データと同じくらい便利にすることです。データ変換プロセス中に、非構造化データのメタデータがカタログに書き込まれます。同時に、大規模モデルと組み合わせて、メタデータの一部の情報をベクトル データベースに書き込み、大規模モデルまたは自然言語を使用して湖の倉庫内のデータを簡単にクエリできるようにしました。この統合作業の目的は、非構造化データの管理効率を向上させ、構造化データの管理との一貫性を高めることです。
非構造化データ - メタデータ管理の例
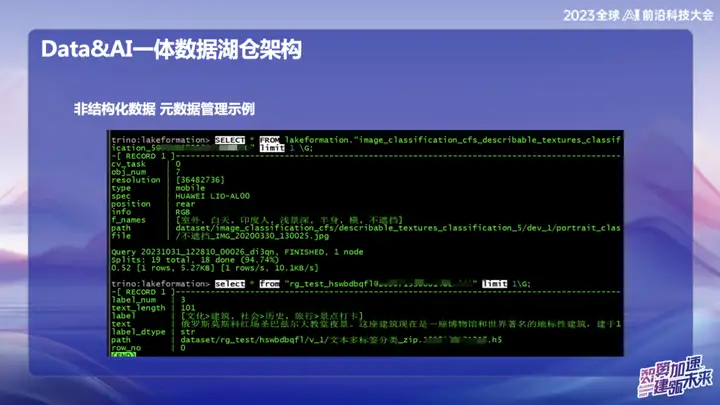
上の写真はOPPOの非構造化データ管理の一例で、SQLのようにテキストや画像の位置を検索することができます。
データプロンプター
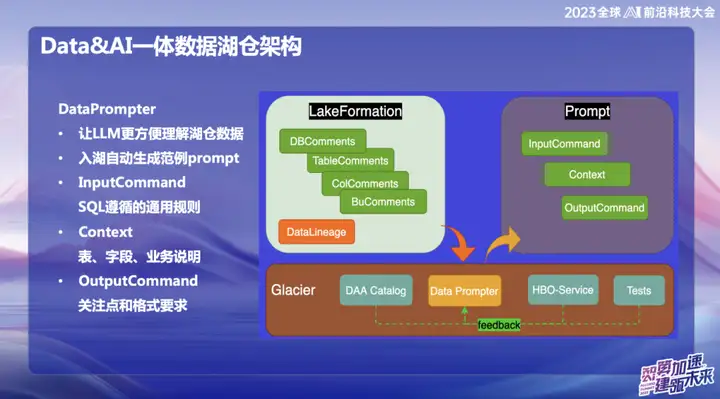
DataPrompter の構築を選択した本来の目的は、大規模モデルをより効果的に利用することの追求から生じています。 OPPO は、データと大規模モデルを組み合わせる分野に注力しており、ユーザーは社内チャット ソフトウェアを通じてすべてのデータを簡単にクエリできる、Data Chart と呼ばれる製品を発売しました。たとえば、ユーザーは昨日の携帯電話の販売台数を簡単に確認したり、Xiaomi 携帯電話の販売台数との販売差を比較したり、自然言語を介してデータ分析を行うことができます。
製品構築プロセス中、各フィールドのデータ テーブルには専門のビジネス担当者がプロンプターを入力する必要があります。各テーブルのプロンプターに時間がかかるため、データ レイク ウェアハウスまたは製品全体のプロモーションに課題が生じます。たとえば、財務テーブルのデータを入力する場合、テーブルのフィールド、ビジネス ドメインの意味、展開されたディメンション テーブルなどの専門的および技術的な情報を詳細に入力する必要があります。
私たちの最終的な目標は、データがレイク ウェアハウスに入った後、大規模モデルが上位レベルのデータを簡単に理解できるようにすることです。データがレイクに入力されるプロセス中に、企業は、データ プロンプターで蓄積された経験と組み合わせて、いくつかの所定の情報を表示し、HBO サービスが提供するいくつかの一般的なクエリを使用して、最終的に大規模なモデルを理解しやすくするプロンプター テンプレートを生成する必要があります。 。この組み合わせは、モデルがビジネス データをよりよく理解し、Hucang モデルと大規模モデルの統合をよりスムーズにできるようにすることを目的としています。
Alluxio は数秒でリアルタイムに湖に入るのに役立ちます
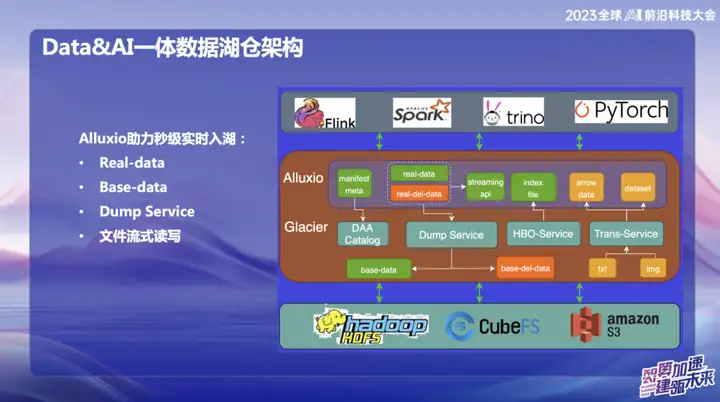
Alluxio は、数秒でリアルタイムに湖に入るのに役立ちます。主に次のように分けられます。
1、実データ
2、基礎データ
3、ダンプサービス
4. ファイルストリーミングの読み書き
Alluxio の湖倉建築における実践
Alluxio と Spark RSS の組み合わせ
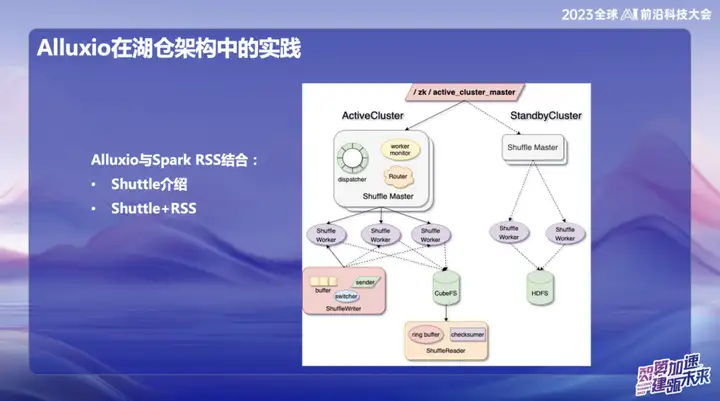
私たちは当初、自社開発の Spark Shuttle サービスを通じて Alluxio を Spark RSS サービスと組み合わせ、それを Shuttle の名前でオープンソースにすることを選択しました。当初、私たちの基礎となるベースは分散ファイル システムに基づいていましたが、その後パフォーマンスの問題が発生したため、Alluxio を見つけました。
Shuttle と Alluxio の完璧な組み合わせにより、Shuttle サービス全体のパフォーマンスが大幅に向上し、基本的にパフォーマンスが 2 倍になりました。この最適化により、システム圧力を約半分に低減し、スループットを直接2倍にすることに成功しました。この組み合わせは、パフォーマンスの問題を解決するだけでなく、当社のサービス システムに新たな活力を注入します。
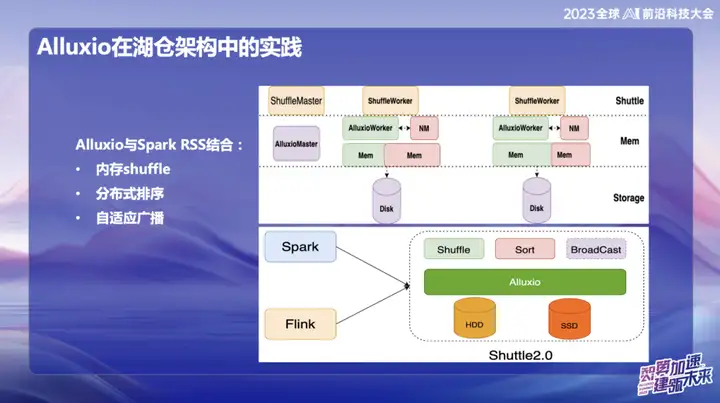
OPPO のその後の研究開発では、Alluxio+Shuttle をベースとしたフレームワークがさらなる革新を実現しました。 Shuttle オペレーターとブロードキャスト オペレーターの両方をメモリ データ レベルに最適化することで、特にシングルポイント リデュースを処理する際にデータが歪んでいる場合に、効率的なメモリ データ インタラクションを通じて、当初は最大 50 分かかっていた並べ替え操作を移行できます。新しいソリューションの採用後、処理時間を 10 分未満に短縮することに成功しました。この最適化により、処理効率が大幅に向上するだけでなく、システム パフォーマンスに対するデータ スキューの影響も効果的に軽減されます。
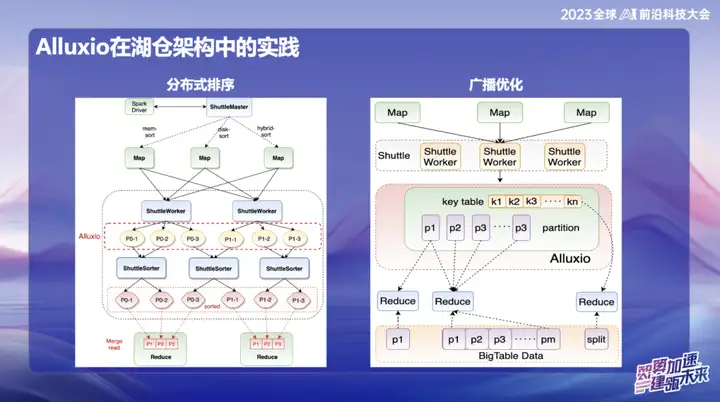
ブロードキャストの結果は、特に Spark では非常に重要です。デフォルトのブロードキャスト サイズは 10M であるため、すべてのブロードキャスト データは Java 側に保存される必要があり、Java のシリアル化後に拡張する傾向があり、OOM (メモリ不足) の問題が発生します。 . これはオンライン環境でよく起こります。
この問題を解決するために、現在は放送データを Alluxio に保存しています。これにより、最大 10 ギガバイトまでのほぼすべてのサイズのデータをブロードキャストできます。このイノベーションは、OPPO のオンラインでの複数のケースで成功裏に導入され、効率の向上に大きな影響を与えています。
パブリッククラウド/ハイブリッドクラウド上での Alluxio アプリケーションの実践
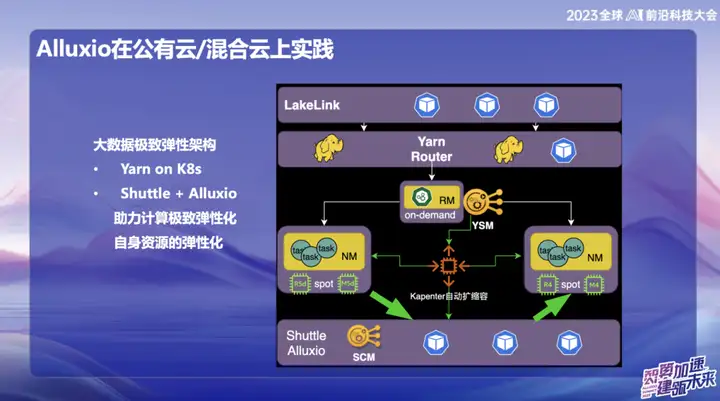
OPPOのパブリッククラウドビッグデータシステムでは、特にシンガポールにおいてインフラとしてAWSを主に利用しています。初期段階では、AWS が提供するエラスティック コンピューティング サービス (EMR) を使用しました。しかし、近年、業界全体の経済情勢は楽観的なものではなく、多くの企業がコスト削減と効率化を追求しています。このような流れに対し、当社は海外のパブリッククラウド分野において、クラウド上の柔軟なリソースを活用して新たなアーキテクチャを構築する自社開発ソリューションを提案してきました。この革新的なソリューションの中核は、ビッグ データ システムに重要なサポートを提供する Alluxio+Shuttle の組み合わせに依存しています。

Alluxio+Shuttle ソリューションの大きな利点は、Alluxio クラスターが Shuttle 専用ではなく、データ キャッシュやメタデータ キャッシュなどの他のサービスのサポートを提供できることです。パブリック クラウドでは、S3 でのリスト操作は送信時に非常に時間がかかることがわかっています。Alluxio とオープンソースの Magic commit および Shuttle ソリューションを組み合わせることで、コンピューティング コストを約 80% 削減するという大幅なコスト削減効果を達成しました。 。
ハイブリッド クラウド環境で、AI チームにサービスを提供します。データレイクの底にはオブジェクトストレージがあるため、トレーニングプロセス中に Alibaba Cloud 上の GPU カードを使用し、またそれを自社構築の GPU リソースと組み合わせました。帯域幅が限られており、専用線はコストが高いため、データのコピーには効果的なキャッシュ層が必要です。当初、ストレージ チームが提供したソリューションを採用しましたが、その拡張性とパフォーマンスは理想的ではありませんでした。 Alluxio の導入後、複数のシナリオで数倍の IO 高速化を達成し、データ処理のより効率的なサポートを提供しました。
展望

OPPOのクラスター規模は中国では数万台に達しており、かなり大きな規模を形成している。将来的にはメモリ リソースをさらに深く掘り下げて、内部ストレージ スペースをより最大限に活用する予定です。チームには、リアルタイム コンピューティング フレームワーク Flink とオフライン処理フレームワーク Spark の両方があり、この 2 つは、Alluxio のアプリケーション エクスペリエンスから相互に学習して、Alluxio とデータ レイクの詳細な統合開発を実現できます。
ビッグデータと機械学習を組み合わせる波の中で、私たちは業界のトレンドを常に追い続けています。データ アーキテクチャと人工知能 (AI) を根底から深く統合し、AI 向けの高品質なサービスを最優先で提供します。この統合は技術の進歩だけでなく、将来の開発のための戦略計画でもあります。
最後に、パブリック クラウド環境のコスト削減に役立つ Alluxio の利点をさらに検討します。これには技術的な最適化だけでなく、クラウド コンピューティング リソースのより効果的な管理も含まれており、企業の持続可能な発展を確実にサポートします。
「Qing Yu Nian 2」の海賊版リソースが npm にアップロードされたため、npmmirror は unpkg サービスを停止せざるを 得なくなりました。 周宏儀: すべての製品をオープンソースにすることを提案します 。ここで time.sleep(6) はどのような役割を果たしますか? ライナスは「ドッグフードを食べる」ことに最も積極的! 新しい iPad Pro は 12GB のメモリ チップを使用していますが、8GB のメモリを搭載していると主張しています。People 's Daily Online は、オフィス ソフトウェアのマトリョーシカ スタイルの充電についてレビューしています。「セット」を積極的に解決することによってのみ、 Flutter 3.22 と Dart 3.4 のリリース が可能になります。 Vue3 の新しい開発パラダイム、「ref/reactive」、「ref.value」不要 MySQL 8.4 LTS 中国語マニュアルリリース: データベース管理の新しい領域の習得に役立ちます Tongyi Qianwen GPT-4 レベルのメイン モデルの価格が値下げされました97%、1元と200万トークン