[データ サイエンス プロジェクト 1]: 最初のデータ サイエンス プロジェクトを構築する

前書き
「データサイエンス」というバズワードを誰もが聞いたことがあるでしょう。私たちのほとんどは、「それは何ですか? データ アナリストまたはデータ サイエンティストになることができますか? どのようなスキルが必要ですか?」についてあまり知りません。たとえば、データ サイエンス プロジェクトを開始したいのですが、わかりません。私たちのほとんどは
、いくつかのオンライン コースを通じてこの分野について学びました. コースで与えられた課題やプロジェクトに満足しています. しかし、まったく新しいデータセットや未知のデータセットの分析を開始すると、道に迷います.あらゆるデータセットや問題に遭遇したら, 絶え間なく練習する必要があります. 最良の方法の1つはプロジェクトで学ぶことだと思います. だから誰もが最初のプロジェクトを始める必要があります. だから私はコラムを書くつもりです.誰もがデータ サイエンス プロジェクトを完了することができます. 興味のある友人がコミュニケーションを取り、一緒に完了することができます. 50 以上の記事があると予想されます. このコラムは実用的なコラムです.
では、データ サイエンス プロジェクトを構築するにはどうすればよいでしょうか。
データ サイエンス プロジェクトで成功するには、そのプロセスを理解し、最適化して、結果が信頼できるものであり、必要に応じてプロジェクトの追跡、保守、および変更が容易になるようにする必要があります。したがって、最善かつ最速の方法は、正規のテンプレートを使用してプロジェクトをビルドすることです。ここでは、以下に示すように、比較的標準化されたプロセスを要約します。
- ステップ 1: データを収集する
- ステップ 2: 適切な IDE を選択する
- ステップ 3: データセットで実行するアクティビティを一覧表示する
- ステップ 4: プロジェクトの概要
- ステップ 5: オープンソース プラットフォームでプロジェクトを共有する
1. データ取得
機械学習アルゴリズムをトレーニングするプロセスは、幼い子供たちに最初にオブジェクトの名前を教え、次にそれを見たときにそれを個別に識別させることに少し似ています. 人間が新しいオブジェクトを認識するために必要なのは、いくつかの例だけです。しかし、オブジェクトに慣れるために数百または数千の同様の例が必要なマシンの場合はそうではありません。これらの例は、私たちが必要とするデータセットです。
機械学習アルゴリズムをトレーニングするには、十分なデータを取得する必要があります。さて、問題は、取り組みたいプロジェクトのデータをどこで収集するかということです。
公式ソースから既存のデータセットを収集したり、データベースからデータをインポートしたり、Web ページから直接データをスクレイピングしたり、ソーシャル メディア チャネルを通じてデータを収集したり、データ収集にオンライン フォームを利用したりできます。他にも多くのソースがあり、データ収集の方法はデータ サイエンス プロジェクトによって異なります。初めてデータ サイエンス プロジェクトに取り組む場合は、関心のあるデータセットを選択してください。スポーツ、映画、音楽など、興味のあるものなら何でも構いません。ここでは、私が通常データを取得するいくつかの Web サイトをお勧めします。
- Kaggle データセット
- UCI データセット
- 世界データ
- 政府のウェブサイト
- 自分でデータをスクレイピングする
ここでは、予測分析を実践するためのデータセットを選択しました。Kaggle の Web サイトからデータセットを取得しました
このプロジェクトのデータセットも私の github にアップロードされています: データセット
# 首先安装kaggle
! pip install -q kaggle
# 将kaggle的json文件导入
!mkdir -p ~/.kaggle
!cp /content/kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle config set -n path -v /content
# 下载数据集并解压。
! kaggle datasets download -d mirichoi0218/insurance
! unzip insurance.zip -d health-insurance
2. IDE を選択する
労働者が良い仕事をしたいのなら、まず道具を研がなければならない
データを取得したら、次に、データの処理とモデル化に使用するツールを検討します。最も使い慣れた IDE を選択してください。Python 言語を使用している場合は、いくつかの一般的な IDE を次に示します。
-
Pycharm - Python コードを書くために設計された IDE です. スマート コード補完、エラー チェック、コード修正など、さまざまなプロダクション機能を提供します。プロジェクトのメンテナンスを容易にするバージョン管理機能との統合により、Web 開発とデータ サイエンスをサポートします。
-
Jupyter Notebook -ライブ コード、ビジュアライゼーションを含むドキュメントを作成および共有できるオープン ソースの Web アプリケーションです。作業を簡素化し、コラボレーションを容易にするのに役立ちます
-
Google Colab - ユーザーが Python コードを記述して実行できるようにします。コンピューティング リソースを無料で提供するため、機械学習やデータ サイエンス プロジェクトに最適です。ここでは、インフラストラクチャやコストを気にすることなく、負荷の高い機械学習アルゴリズムを簡単に実行できます。
-
拡張子が .py の単純なテキスト ファイル。上記のオプションはすぐに利用できて使いやすいですが、メモ帳でコーディングする場合は、メモ帳を使用してファイルに .py 拡張子を付けて保存できます。その後、コマンド ラインで構文「python .py」を使用して同じコマンドを実行できます。これによりプログラムが実行されますが、データ サイエンスの作業では、コードを表示したり、その場で出力を視覚化したりすることができないため、これは最良の選択ではない可能性があります。
ここでは、作業環境として Google Colab を選択しました。
使用するデータを取得したら、次のステップは、データの品質を調べて、データの第一印象を取得することです。このフェーズの主な目的は、データのサニティ チェックを実行することです。これを行う最善の方法は、不可能または非常にありそうもないことを探すことです。外れ値と欠損値をチェックし、正しいデータ型をチェックし、最も極端なケースをチェックします。彼らは理にかなっていますか?データに対していくつかの簡単な統計テストを実行し、それらを視覚化して、データの統計的特性をすばやく理解し、可能な外れ値を検出することをお勧めします。
3. データセットで実行するアクティビティを一覧表示する
データセットに対して実行する操作をリストして、開始する前にパスを明確にします。データ サイエンス プロジェクトで実行する一般的なアクションは次のとおりです。
データの読み取り、データのクリーニング、データの変換、探索的データ分析、モデルの構築、モデルの評価、およびモデルの展開。これらの手順を以下で簡単に説明します。
データ読み取りは、パンダを使用してデータをデータフレーム構造に読み取ります
# 导入基本库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.cbook import boxplot_stats
import statsmodels.api as sm
from sklearn.model_selection import train_test_split,GridSearchCV, cross_val_score, cross_val_predict
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.tree import DecisionTreeRegressor
from sklearn import ensemble
import numpy as np
import pickle
# 读取数据,并总览一下数据情况。
health_ins_df = pd.read_csv("health-insurance/insurance.csv")
health_ins_df.head()
| 索引 | 年 | セックス | BMI | 子供 | 喫煙者 | 領域 | 料金 |
|---|---|---|---|---|---|---|---|
| 0 | 19 | 女性 | 27.9 | 0 | はい | 南西 | 16884.924 |
| 1 | 18 | 男 | 33.77 | 1 | 番号 | 南東 | 1725.5523 |
| 2 | 28 | 男 | 33.0 | 3 | 番号 | 南東 | 4449.462 |
| 3 | 33 | 男 | 22.705 | 0 | 番号 | 北西 | 21984.47061 |
| 4 | 32 | 男 | 28.88 | 0 | 番号 | 北西 | 3866.8552 |
データクリーニング: データセットの欠落および異常値の特定と排除
# 查看缺失值
health_ins_df.isnull().sum()
# 可以看出数据集中没有缺失值
age 0
sex 0
bmi 0
children 0
smoker 0
region 0
charges 0
dtype: int64
データ変換 - 列のデータ型の変更、派生列の作成、データの重複排除などが含まれます。
探索的データ分析– データセットに対して単変量および多変量分析を実行して、データセット内に隠されている関係の一部を明らかにします
数値変数とカテゴリ変数でデータのクリーニングと探索的データ分析を実行しましょう。
探索的データ分析
数値変数の分析
#数值型变量的可视化
# 直方图绘制
fig,axes = plt.subplots(1,2,figsize=(12,6))
plt.style.use('ggplot')#使用ggplot主题,R语言的一个绘图包
sns.histplot( health_ins_df['age'] , color="skyblue",ax=axes[0])
sns.histplot( health_ins_df['bmi'] , color="olive",ax=axes[1])
plt.show()
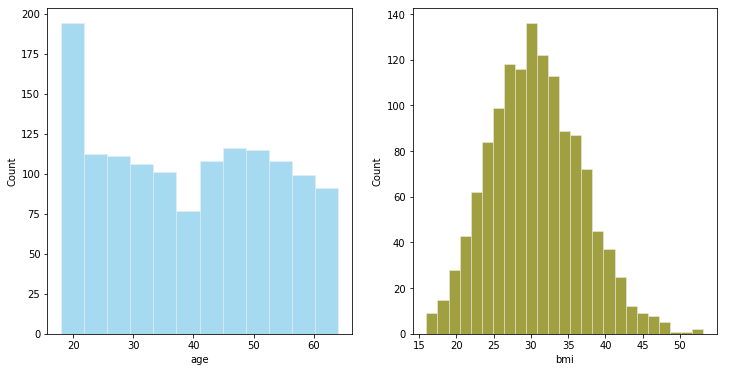
-
年齢を年齢グループにグループ化できます
-
正規分布に近いBMI
# 箱线图
fig,axes=plt.subplots(1,2,figsize=(10,5))
sns.boxplot(x = 'age', data = health_ins_df, ax=axes[0])
sns.boxplot(x = 'bmi', data = health_ins_df, ax=axes[1])
plt.show()

BMIにはいくつかの外れ値 があることがわかります。これらのポイントを見てみましょう。
outlier_list = boxplot_stats(health_ins_df.bmi).pop(0)['fliers'].tolist()
print(outlier_list)
#查找包含异常值的行数
outlier_bmi_rows = health_ins_df[health_ins_df.bmi.isin(outlier_list)].shape[0]
print("bmi 中包含异常值的行数:", outlier_bmi_rows)
#离群值占比
#Percentage of rows which are outliers
percent_bmi_outlier = (outlier_bmi_rows/health_ins_df.shape[0])*100
print("bmi离群值异常值的百分比 : ", percent_bmi_outlier)
[49.06, 48.07, 47.52, 47.41, 50.38, 47.6, 52.58, 47.74, 53.13]
bmi 中包含异常值的行数: 9
bmi离群值异常值的百分比 : 0.672645739910314
数値変数のデータ変換
# 将年龄转换为分桶的
print("Minimum value for age : ", health_ins_df['age'].min(),"\nMaximum value for age : ", health_ins_df['age'].max())
'''
18至40岁的年龄将属于青年
41至58岁的年龄将低于中年
58岁以上将落入老年
'''
health_ins_df.loc[(health_ins_df['age'] >=18) & (health_ins_df['age'] <= 40), 'age_group'] = '青年'
health_ins_df.loc[(health_ins_df['age'] >= 41) & (health_ins_df['age'] <= 58), 'age_group'] = '中年'
health_ins_df.loc[health_ins_df['age'] > 58, 'age_group'] = '老年'
Minimum value for age : 18
Maximum value for age : 64
# 去除BMI中的异常值
health_ins_df_clean = health_ins_df[~health_ins_df.bmi.isin(outlier_list)]
sns.boxplot(x = 'bmi', data = health_ins_df_clean)

カテゴリ変数の分析
fig,axes=plt.subplots(1,5,figsize=(20,8))
sns.countplot(x = 'sex', data = health_ins_df_clean, palette = 'magma',ax=axes[0])
sns.countplot(x = 'children', data = health_ins_df_clean, palette = 'magma',ax=axes[1])
sns.countplot(x = 'smoker', data = health_ins_df_clean, palette = 'magma',ax=axes[2])
sns.countplot(x = 'region', data = health_ins_df_clean, palette = 'magma',ax=axes[3])
sns.countplot(x = 'age_group', data = health_ins_df_clean, palette = 'magma',ax=axes[4])

データの準備が完了したら、次の段階はモデリングです。適切なアルゴリズムの選択は、データのタイプによって異なります。たとえば、データが連続的である場合は回帰モデリングを適用し、データがカテゴリカルである場合は分類アルゴリズム モデリングを適用します。データ サイエンティストは、多くのモデルを試して最適なモデルを見つけます。
モデル構築
ビジネス/技術的な制約に基づいて適切なモデルを選択する前に、データセットで考えられるすべてのモデルを試してテストしてください。この段階で、バギングやブースティングのテクニックを試すこともできます。ここでは、線形回帰モデル、決定木回帰、および勾配ブースティング回帰を構築しました。
単純な線形回帰モデル
ここでは、最初に線形回帰モデルをベースライン モデルとして使用します。
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
X = health_ins_df_processed.loc[:, health_ins_df_processed.columns != 'charges']#自闭哪里
y = health_ins_df_processed['charges']#因变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)#划分训练集和测试集
lm.fit(X_train,y_train)
print("R-Squared on train dataset={}".format(lm.score(X_train,y_train)))#训练集R2
lm.fit(X_test,y_test)
print("R-Squaredon test dataset={}".format(lm.score(X_test,y_test)))#测试集R2
R-Squared on train dataset=0.7494776882061486
R-Squaredon test dataset=0.7372938495110573
結果から、単純な線形回帰R 2 R^2を使用R2は 0.74 で、モデルがデータ内の情報の 74% を説明していることを示しています. 以下のいくつかのより複雑なモデルを見てみましょう.
決定木回帰
X = health_ins_df_processed.loc[:, health_ins_df_processed.columns != 'charges']
y = health_ins_df_processed['charges']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
dtr = DecisionTreeRegressor(max_depth=4,min_samples_split=5,max_leaf_nodes=10)#初始化参数
dtr.fit(X_train,y_train)
print("R-Squared on train dataset={}".format(dtr.score(X_train,y_train)))#训练集R2
dtr.fit(X_test,y_test)
print("R-Squaredon test dataset={}".format(dtr.score(X_test,y_test)))#测试集R2
R-Squared on train dataset=0.8594291626976573
R-Squaredon test dataset=0.8571718114547656
上記のパラメータは私がランダムに設定したものです.パラメータを調整して効果を改善することもできます.パラメータ調整コードをgithubにアップロードしましたhttps://github.com/JoJoYao996/data-science-projects
勾配ブースティング回帰
勾配ブースティング回帰モデルの主な調整パラメーター
- learning_rate : 学習率、デフォルトは 0.1
- n_estimators : デフォルトは 100 です
- max_depth : 単一回帰推定量の最大深度。最大の深さは、ツリー内のノードの数を制限します。最適なパフォーマンスを得るには、このパラメーターを調整します。最適な値は、入力変数の相互作用によって異なります。値は [1, inf) の範囲内である必要があります。
- min_samples_split : 内部ノードを分割するために必要なサンプルの最小数:
- min_samples_leaf : リーフ ノードのサンプルの最小数。このパラメーターは、特に回帰において、モデルの平滑化効果に影響します。
gridsearchを使用してこれらのパラメーターを個別に調整しました。以下は、パラメーターを調整した後の結果です。
#最终的模型
f_model = ensemble.GradientBoostingRegressor(learning_rate=0.015,n_estimators=250,max_depth=2,min_samples_leaf=5,
min_samples_split=2,subsample=1,loss = 'squared_error')
f_model.fit(X_train, y_train)
print("Accuracy score (training): {0:.3f}".format(f_model.score(X_train, y_train)))
f_model.fit(X_test, y_test)
print("Accuracy score (test): {0:.3f}".format(f_model.score(X_test, y_test)))
Accuracy score (training): 0.866
Accuracy score (test): 0.818
機能の重要性を表示する
#查看变量的重要性
feature_importance = f_model.feature_importances_
sorted_idx = np.argsort(feature_importance)#得到重要性的排序索引
fig = plt.figure(figsize=(12, 6))
pos = np.arange(sorted_idx.shape[0]) + .5
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(health_ins_df_processed.columns)[sorted_idx])
plt.show()

最も重要な 3 つの特徴は次のとおりです。smoker_no、children_5、bmi
モデルを保存
# 保存模型
filename = 'health_insurance_data_model.sav'
pickle.dump(f_model, open(filename, 'wb'))
# 加载模型
filename = 'health_insurance_data_model.sav'
loaded_model = pickle.load(open(filename, 'rb'))
result = loaded_model.score(X_test, y_test)
print(result) #测试集精度
0.8180114370687565
4. 要約を準備する
プロジェクトとそれを完了するために実行した手順を簡単に説明するドキュメントを要約します。設計したビジネス上の問題の記述とデータ サイエンス ソリューションを要約してみてください。また、将来の参考のために、プロジェクトに関する鮮明な詳細についても言及してください。
簡単なワード文書またはパワーポイントのプレゼンテーションを使用して要約を準備できます。5つのパーツを持つことができます。第一部では、背景と問題点を簡単に説明します。2 番目の部分では、予測分析に使用しているデータセットとそのデータのソースについて説明します。パート 3 で述べたように、どのようなデータ クリーニング、データ変換、および探索的データ分析を実行しましたか? 次に、試してテストしたさまざまな予測モデルの概念実証について簡単に述べます。最後に、ビジネス上の問題の最終結果と解決策について言及できます。
このプロジェクトが完了したら、短い要約を作成します
5. オープンソース プラットフォームで共有する
github、gitee など、プロジェクトの要約またはコードを公開するオープン ソース プラットフォームを選択して、より多くのデータ サイエンティストとのコミュニケーションを促進し、プロジェクトを継続的に改善します。
スペースが限られています. 完全なコードは私の github で見ることができます. スターとフォークへようこそ.
github アドレス:完全なコード
github にアクセスできない場合は、非公開でメッセージを送ってソース コードを入手してください。