JVMの概要
JVMは、Java仮想マシンの略語であり、Java仮想マシンを意味します。
仮想マシンとは、ソフトウェアによってシミュレートされ、完全に分離された環境で実行される完全なハードウェア機能を備えた完全なコンピューターシステムを指します。
一般的な仮想マシン:JVM、VMwave、VirtualBox。
JVMと他の2つの仮想マシンの違い:
- VMwaveとVirtualBoxは、ソフトウェアを介して物理CPUをシミュレートする命令セットであり、物理システムには多くのレジスタがあります。
- JVMは、ソフトウェアを介してJavaバイトコードの命令セットをシミュレートします。JVMでは、PCレジスタのみが主に予約され、他のレジスタは
トリミングされます。
JVMは、実際には存在しないカスタマイズされたコンピューターです。
日常の開発では、Javaプログラマーは一般的にJVM内のものを使用しません。より深く理解したい場合は、この本を読むことができます。乾物がたくさんあります。

1.JVMメモリ領域の分割
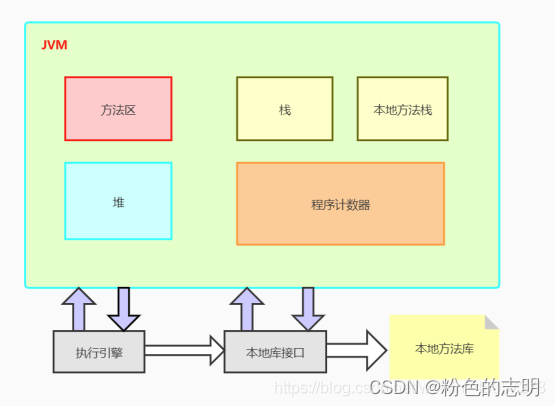
JVMメモリはオペレーティングシステムから適用され、さまざまな領域に分割され、さまざまな領域がさまざまな機能を完了します
什么是线程私有?
JVMのマルチスレッド化は、スレッドを順番に切り替えてプロセッサの実行時間を割り当てることで実現されるため、任意の時点で、プロセッサ(マルチコアプロセッサはコアを指します)は1つのスレッドのみを実行します。したがって、スレッドを切り替えた後に正しい実行位置を復元するには、各スレッドに独立したプログラムカウンターが必要であり、各スレッド間のカウンターは相互に影響を与えず、独立して格納されます。このタイプの領域を「スレッドプライベート」メモリと呼びます
1.1プログラムカウンター(スレッドプライベート)
プログラムカウンターの役割:現在のスレッドによって実行された行番号を記録するために使用されます。
これはメモリ内に最小的区域あり、次に実行されるアイテムのアドレスはどこにあります指令か...
指令これはバイトコードです。プログラムを実行する場合、JVMはバイトコードをロードして、現在実行中のメモリに配置する必要があります
。CPUは同時実行プロセスであり、1つのプロセスにサービスを提供するだけではありません。 、オペレーティングシステムがスレッド単位でスケジュールおよび実行されるため、すべてのプロセスにサービスを提供する必要があります。各スレッドは、スレッドごとに1つずつ、独自の実行場所、つまりプログラムカウンターを記録する必要があります。
1.2 Java仮想マシンスタック(スレッドプライベート)
ローカル変数とメソッド呼び出し情報について説明します。メソッドが呼び出されると、新しいメソッドが呼び出されるたびに「プッシュ」操作が実行され、メソッドが実行されるたびに「ポップ」操作が実行されます。
スタックスペースは比較的小さく、スタックスペースのサイズはJVMで構成できますが、通常は数Mまたは数十Mであるため、スタックがいっぱいになる可能性が非常に高くなります(通常、コードを記述する場合は通常問題ありません。ただし、再帰が発生する可能性があります。設定すると、スタックオーバーフローが発生します:StackOverflowException)
Java仮想マシンスタックの役割:Java仮想マシンスタックのライフサイクルはスレッドのライフサイクルと同じです。Java仮想マシンスタックは
内存模型:、Javaメソッドによって実行される各メソッドがスタックフレーム(スタックフレーム)を作成することを記述しています。局部变量表、操作数栈、动态链接、方法出口実行と同時に保存するためのその他の情報。私たちがよく話すヒープメモリとスタックメモリでは、スタックメモリは仮想マシンスタックを指します。
Java仮想マシンスタックには、次の4つの部分が含まれます
。1。ローカル変数テーブル:さまざまな基本データ型(8つの基本データ型)と、コンパイラーが認識しているオブジェクト参照を格納します。ローカル変数テーブルに必要なメモリスペースはコンパイル時に割り当てられます。メソッドを入力するときに、メソッドがフレームに割り当てる必要のあるローカル変数スペースの量が完全に決定され、ローカル変数テーブルのサイズは実行中に変更されません。簡単に言えば、メソッドパラメータとローカル変数を格納します。
2.操作スタック:各メソッドは、ファーストイン、ラストアウトの操作スタックを生成します。
3.ダイナミックリンク:ランタイム定数プールへのメソッド参照。
4.メソッドの差出人住所:PCレジスタのアドレス
1.3ネイティブメソッドスタック(スレッドプライベート)
ネイティブメソッドスタックは仮想マシンスタックに似ていますが、Java仮想マシンスタックがJVMによって使用され、ネイティブメソッドスタックがネイティブメソッドによって使用される点が異なります。
1.4ヒープ(スレッド共有)
ヒープの役割:プログラムで作成されたすべてのオブジェクトはヒープに格納されます
プロセスにはコピーが1つだけあり、複数のスレッドがヒープを共有します。ヒープは、メモリ内で最大のスペースを持つ領域でもあります。作成する新しいオブジェクトはヒープ内にあり、オブジェクトのメンバー変数も当然ヒープ内にあります。
注:
内置类型的变量在栈上,引用类型的变量在堆上、このステートメントは間違っています。ローカル変数がスタックにあり、メンバー変数と新しいオブジェクトがヒープにある
はずです。

1.5メソッド領域(スレッド共有)
メソッド領域の役割:クラス情報、定数、静的変数、仮想マシンによってロードされたリアルタイムコンパイラによってコンパイルされたコードなどのデータを格納するために使用されます。
メソッド領域には、「クラスオブジェクト」、いわゆる「クラスオブジェクト」が配置されます。.java作成したコードは.class(バイナリバイトコード)になり.class、メモリ、つまりJVMオブジェクトによって構築されたクラスにロードされます。 (ロードプロセスは「クラスロード」と呼ばれます)、「クラスオブジェクト」は、クラスがどのように見えるか、クラスの名前、クラスに含まれるメンバー、そこにあるメソッド、および各メンバーの名前を記述します。 ?タイプ(public / private ...)、各メソッドの名前、タイプ(public / private ...)、メソッドに含まれる命令...
「クラス」にはもう1つの非常に重要なことがあります。オブジェクト」、静态成员(静的)
staticによって変更されたメンバーは「クラス属性」になり、通常のメンバーは「インスタンス属性」と呼ばれます
2.JVMクラスのロードメカニズム
クラスの読み込みは、実際にはランタイム環境を設計する上で重要なコア機能です。クラスの読み込みは何をしますか?.classファイル、クラスオブジェクトに組み込みます。
2.1クラスの読み込みプロセス
クラスローディングのライフサイクル:
最初の5つのステップは決まった順序であり、クラスローディングのプロセスでもあります。真ん中の3つのステップはすべて接続されているため、クラスローディングの場合は3つのステップに分けられます
Loading,Linking,Initialization。英語を使用)
2.1.1ロード
「ロード」ステージは、「クラスロード」プロセス全体のステージです。クラスロードとは異なります。1つはロードで、もう1つはクラスロードなので、2つを一緒にしないでください。混乱します。
在加载 Loading 阶段,Java虚拟机需要完成以下三件事情:
1)このクラスを完全修飾名で定義するバイナリバイトストリームを取得します。
2)このバイトストリームで表される静的ストレージ構造をメソッド領域のランタイムデータ構造に変換します。
3)メソッド領域のこのクラスのさまざまなデータへのアクセスエントリとして、メモリ内のこのクラスを表すjava.lang.Classオブジェクトを生成します。
要約すると、最初に対応するファイルを見つけ、次にファイル(バイトストリーム)
.classを開いて読み取り、最初にクラスオブジェクトを生成します。.class
Loadingのキーリンクで
.class、ファイルには正確に何が含まれていますか?詳細について
は、公式ドキュメントを参照してください:https ://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html
上の図の形式によれば、読み取られて解析された情報は、最初にクラスオブジェクトに入力されます。
2.1.2リンク
接続は通常、複数のエンティティ間の接続の確立です
一: 验证(Verification)
主なことは、読み取ったコンテンツが仕様で指定された形式と完全に一致するかどうかを確認することです。ここで読み取ったデータ形式が仕様に準拠していないことが判明した場合、クラスの読み込みは失敗し、例外がスローされます。
二: 准备(Preparation)
準備段階では、クラスで定義された変数(つまり、静的変数、静的変数によって変更された変数)にメモリを正式に割り当て、クラス変数の初期値を設定し
比如:
ます
三: 解析(Resolution)
解析フェーズは、Java仮想マシンが定数プール内のシンボリック参照を直接参照に置き換えるプロセス、つまり定数を初期化するプロセスです。
これは、.classファイル内で定数が中央に配置され、各定数に番号が付いていることを意味します。.classファイル構造の初期状態では番号のみが記録されるため、番号に応じて対応するコンテンツを見つけて入力する必要があります。クラスオブジェクト。
2.1.3初期化
初期化フェーズでは、Java仮想マシンは実際にクラスで記述されたJavaプログラムコードの実行を開始し、支配権をアプリケーションに転送します。初期化フェーズは、クラスコンストラクターメソッドを実行するプロセスです。これは、特に静的メンバーの場合、クラスオブジェクトを実際に初期化するためのものです。
典型的なインタビューの質問:特定のクラスのロードはいつトリガーされますか(コード例)?
その印刷順序は何ですか?
結果:
クラスが使用されている限り、クラスを最初にロードする必要があります(インスタンス化、メソッドの呼び出し、静的な呼び出しなど)メソッド、継承...すべて使用済みとしてカウントされます)
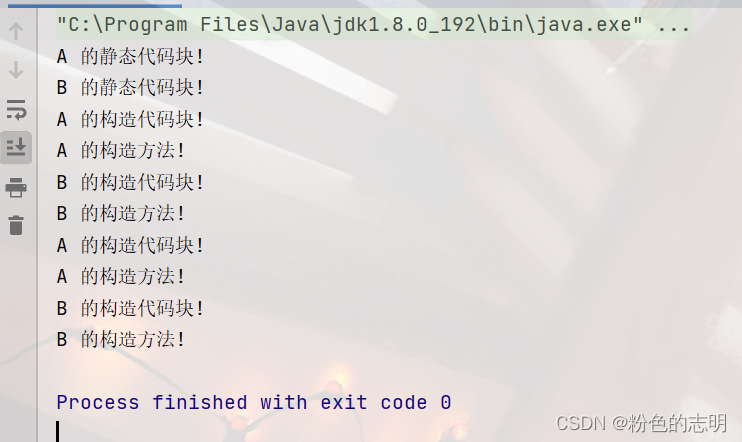
大的原则:
1:静的コードブロックはクラスロードフェーズで実行されます。インスタンスを作成するには、最初にクラスロードを実行する必要があります
。2:静的コードブロックはクラスロードフェーズで1回だけ実行され
ます。実行、構築コードブロックは構築メソッドの前にあります
4:親クラスが最初に実行され、サブクラスが後ろに実行されます
5:プログラムはメインから実行されます。メインはテストのメソッドです。メインを実行するには、最初にTestDemoをロードする必要があります
プログラムはmainメソッドから実行されます。ここでmainはTestDemoクラスのメソッドです。したがって、mainを最初に実行するには、最初にTestDemoをロードする必要があり、TestDemoはBを継承します。TestDemoをロードするには、最初にBをロードし、Bをロードする必要があります。 Aを継承し、最初にAをロードします
2.2親委任モデル
これは私たちの仕事ではあまり役に立ちませんが、インタビュー中によく聞かれます...
これはクラスの読み込みのリンクです。このリンクは読み込み段階(前部)にあり、実際には親の委任モデルです。 JVM类加载器で、完全修飾名(java.lang.String)に従って.classファイル
类加载器:JVMは、クラスローダーと呼ばれる特別なオブジェクトを提供します。これはクラスのロードを担当します。もちろん、ファイルを検索するプロセスもクラスローダーの責任です...
.classファイルは多くの場所に配置される場合があります。 JDKディレクトリ、および一部はプロジェクトディレクトリに配置され、一部は他の特定の場所に配置されます。したがって、JVMには複数のクラスローダーが提供され、各クラスローダーがスライスを担当します。
主に3つのデフォルトのクラスローダーがあります。現在のプロジェクトディレクトリのクラスのロードを担当するJDK拡張クラス(現在はほとんど使用されていません)のロードを担当
1: BootstrapClassLoader
する標準ライブラリ(String、ArrayList、Random、Scanner ...)のクラスのロードを担当します。
2: ExtensionClassLoader
3: ApplicationClassLoader
さらに、プログラマーはクラスローダーをカスタマイズして他のディレクトリのクラスをロードすることもできます。たとえば、Tomcatはクラスローダーをカスタマイズして
.class...を具体的にロードします。
親委任モデルは、ディレクトリを見つけるこのプロセス、つまり、上記のクラスローダーがどのように連携するかを説明しています...
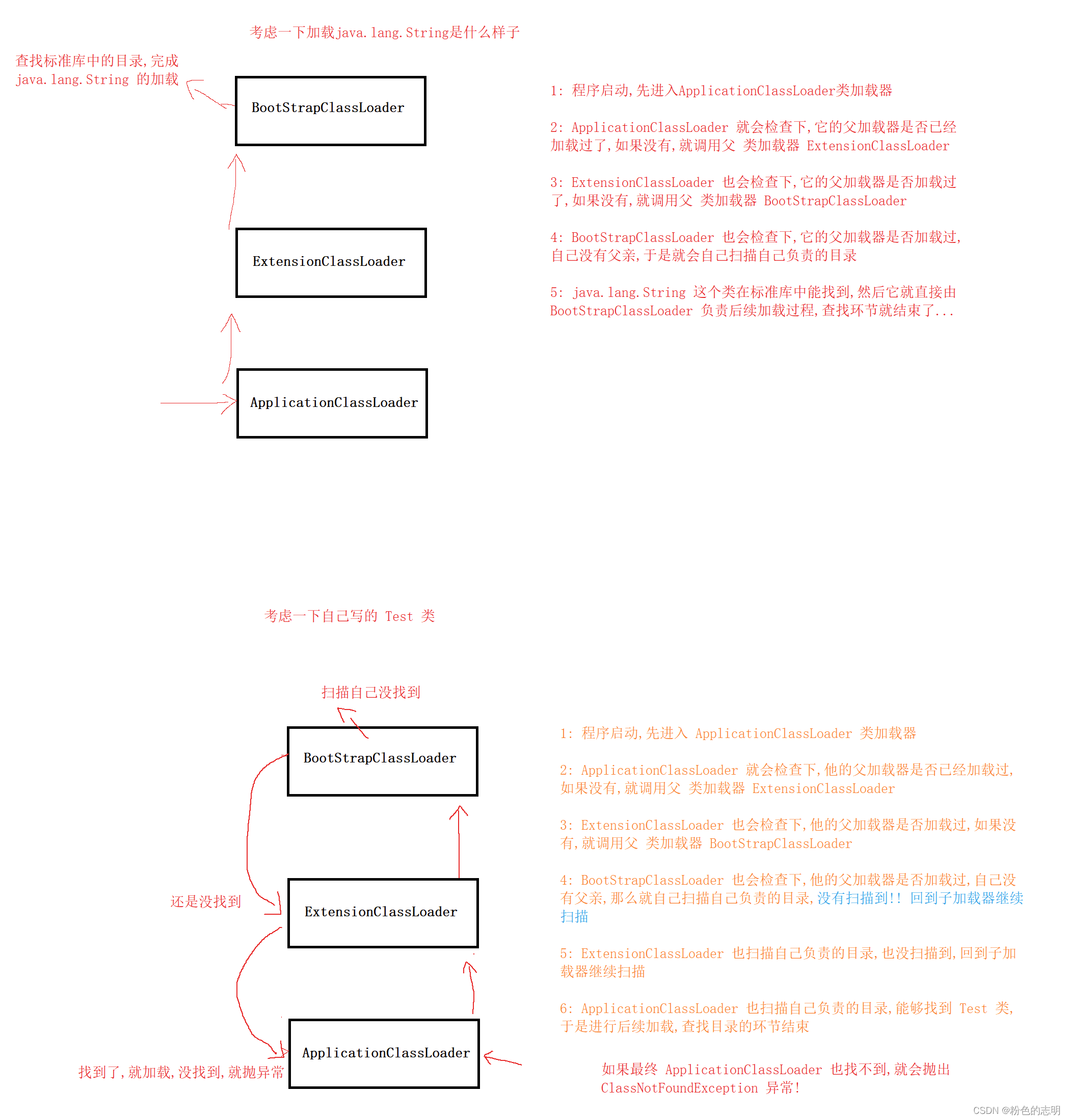
この一連の検索ルールは「親委任モデル」と呼ばれます(これは音訳され、親は父親または母親のいずれかになります。ルールによれば、彼を「ひとり親委任モデル」と呼ぶことは不可能ではありません。もちろん、名前を決めるのは私たち次第ではありません)
JVMがこのように設計されているのはなぜですか?
その理由は、プログラマーによって記述されたクラスの完全修飾クラス名と標準ライブラリのクラスが繰り返されると、標準ライブラリのクラスもスムーズにロードできるためです
!! java.lang .Stringなどのクラスは自分で定義します。プログラムがロードされても、それは標準ライブラリのクラスであるため、競合は発生せず、セキュリティが保証されます。
カスタムクラスローダーが親委任モデル
にも準拠している場合、要件に応じて準拠するかどうかを指定できます
。TomcatがWebアプリケーションでクラスをロードするのと同様に、準拠しません(準拠は無意味であるため)。
3. JVMガベージコレクションメカニズム(GC)
3.1ガベージコレクションとは
ガベージコレクション(GarbageCollection、GC)、コードを書くとき、私たちはしばしばメモリを適用し、変数、新しいオブジェクトを作成し、クラスをロードします...これらはすべてオペレーティングシステムからメモリを適用します。不用的时候間違いなくメモリも返します。
一般的に、メモリを申請するタイミングは明確ですが(データを保存する必要がある場合は、メモリを申請する必要があります)、メモリを解放する期間はそれほど明確ではありません。このメモリがまだ必要かどうかはわかりません。 。
例:午後に家に帰ったら、服を捨てて気にしないとしましょう。母親が見つけたら、服を整理してクローゼットに入れます。翌日、着てはいけない、大丈夫ですが、外出するにはこのドレスを着なければなりません。元の場所に行って見つけますね。なくなった、恥ずかしくないですか...
(这就是内存释放早了)
後でリリースしても大丈夫ですか?あなたは図書館の席を占有している、あなたは早朝に席を占有している、そしてあなたは一日中行かない、それは恥ずかしいことではない、あなたは席を占有する必要はない、そして誰もいない、のようにあまり良くない他の人はそれを使う(这就是内存释放迟了)
ことができます、そして私たちが望んでいるのは遅かれ早かれできないことです
3.2ガベージコレクションメカニズムが表示されるのはなぜですか?
C言語のように:「私はメモリ解放を気にしません、あなたのプログラマーはあなた自身でそれをすることができます、とにかく、あなたは私のお金を差し引くことはありません...」したがって、C言語では、あなたは一般的な頭痛に遭遇します=> "内存泄露"(申请之后,忘了释放)=>使用可能なメモリはますます少なくなり、最終的にはメモリが使用できなくなります!!したがって、「メモリリーク」は、C / C ++プログラマーにとって頭痛の種であり、リークが速く、リークが遅く、露出のタイミングが不確実です。 C ++は後に智能指针(大概就只是简单依赖了一下 C++ 中的 RAII机制,其实一点也不智能..)このようなメカニズムを提案し、それによって「メモリリーク」のリスクをある程度減らすことができます...しかし、それはjavaの多くのメカニズムの前にいる弟です(面白い) )。
したがって、Java、GO、PHPなど...市場に出回っている主流のプログラミング言語のほとんどは、ガベージコレクションメカニズムであるソリューションを採用しています!!
おそらくランタイム環境(JVM、Pythonインタープリター、Goなど)がありますランタイム...)より複雑な戦略でメモリを再利用できるかどうかを判断し、再生アクションを実行するには...ガベージコレクションは、本質的にランタイム環境に依存し、操作を完了するために多くの追加作業を行います自動的にメモリを解放するため、プログラマーの心に大きな負担がかかります。
ただし、ガベージコレクションには欠点もあります
。1:追加のオーバーヘッドを消費します(より多くのリソースが消費されます)
2:プログラムのスムーズな実行に影響を与える可能性があります(ガベージコレクションはSTW(Stop The World、まだ時間のように)の問題を引き起こすことがよくあります)
ガベージコレクションはとても香りがよいのに、なぜC ++はGCを導入しないのですか?
実際、一部のボスはこの計画を提案しましたが、C ++言語には2つの高電圧ラインがあり、それがコア原則であるため、実装されていません。
1:互換性があります。 C言語を使用し、さまざまなハードウェアオペレーティングシステムと互換性があります。あらゆる種類のハードウェアオペレーティングシステムが最大化され、人工知能、ゲームエンジン、高性能サーバー、オペレーティングシステムカーネルなど
2:の最も極端なパフォーマンスと互換性があります。
互換性/パフォーマンス要件が非常に高いシナリオでも、C /C++が必要です。
3.3ガベージコレクションで何をリサイクルするか
再利用されるのはメモリですが、メモリには次のものが含まれます:プログラムカウンター、スタック、ヒープ、およびメソッド。一部は再利用され、一部は再利用されません。
程序计数器:固定サイズ、リリースは含まれないため、GC
栈:関数を実行する必要はなく、対応するスタックフレームが自動的にリリースされるため、GCがGC
堆:を必要とする必要はありません。コード内の大量のメモリがクラスによってロードされるヒープ
方法区:クラスオブジェクト。「クラスアンロード」を実行するには、メモリを解放する必要があり、アンロード操作は実際には非常に低頻度の操作です(ガベージコレクションが含まれることはめったにありません)。
ここでは、ヒープでのガベージコレクションについて説明します。
最初にこの画像を見てください。
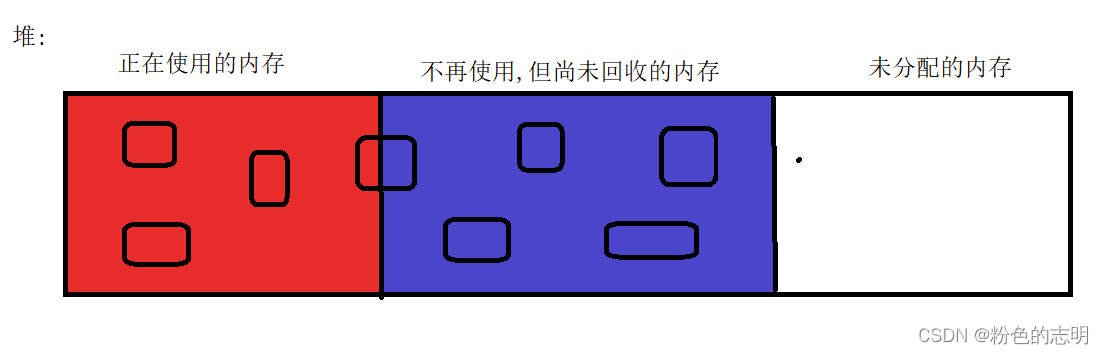
上の写真は3つの派閥として理解することができます:积极派,消极派,中间摇摆派、
积极派:使用中のメモリは解放されません
消极派:。使用されなくなったメモリは解放する必要があります
中间摇摆派:。赤と青の間の部分は、使用中のメモリと使用されていないメモリを表します。この場合是不释放的、解放されません。それが使い果たされるまで。
GCには、主にガベージコレクションをより便利で簡単にするための「ハーフオブジェクト」はありません。次の点に注意してください。垃圾回收的基本单位是"对象",而不是字节
3.4ガベージコレクションの実装方法
2つの主要な段階に分かれています。第一阶段: 找垃圾/判定垃圾.., 第二阶段: 释放垃圾..
部屋を掃除するのと同じように、最初にすべてのゴミをゴミ箱に入れてから、部屋から捨てます...
3.4.1ごみ/判断ごみの見つけ方
私たちの現在の主流の考え方には2つの解決策があり
1: 基于引用计数(不是Java中采取的方案,这是别的语言,像Python采取的方案)
2:基于可达性分析(这个是Java采取的方案)
ます:他の人があなたに尋ねるときに注意を払う:
1:
ガベージコレクションメカニズムでガベージかどうかを判断する方法について話す2:Javaのガベージコレクションメカニズムでガベージかどうかを判断する方法について話す
これらの2つの問題は、到達可能性分析に基づいていますが、参照カウントに基づいています。
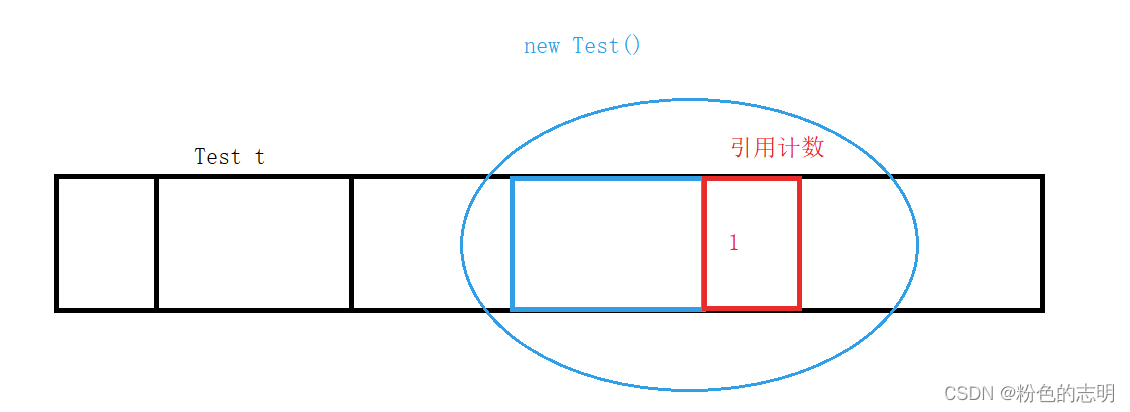
①参照カウントに基づく
オブジェクトごとに、このオブジェクトへの参照がオブジェクトを指す数を節約するために、追加の小さなメモリが導入されます
次に例を示します。Testt=new Test(); tはこのオブジェクトへの参照であるため、Testオブジェクトには参照があり、参照カウントは1です。
もう一度書くと:Test t2 = t、つまり両方のt t2はこのオブジェクトを指し、その時点で参照カウントは2になります
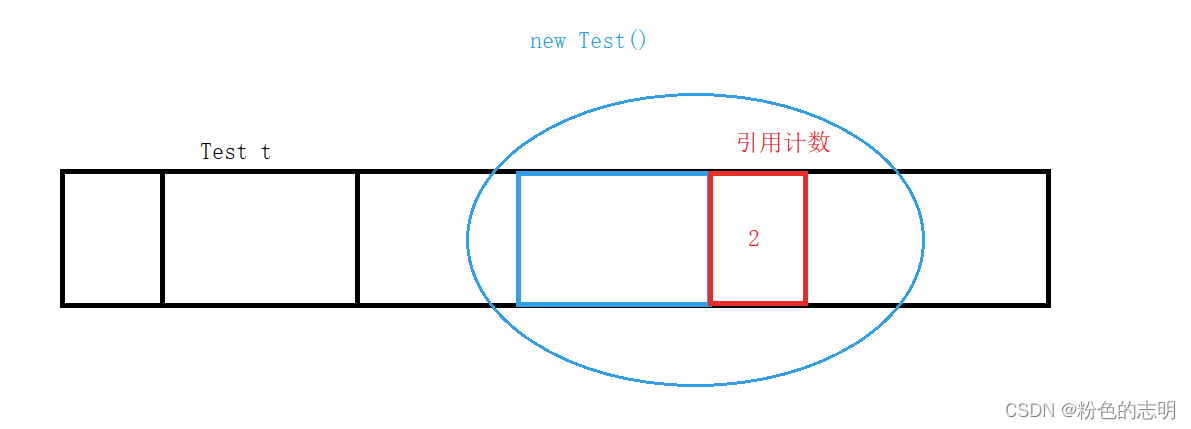
参照カウントが0の場合、使用されておらず、ガベージと見なされ、メモリが解放されます。

参照カウントのデメリット:
1:スペース使用率は比較的低いです!!新しいオブジェクトはそれぞれカウンターと一致する必要があります(カウンターは4バイトを想定しています)。オブジェクト自体が非常に大きい場合(数百バイト)、4バイト多い場合は何もありませんが、オブジェクト自体が小さい場合(4バイトしかない)バイト)、4バイト以上、これは無駄になっているスペースの半分に相当します。
2:循環参照の問題が発生します。
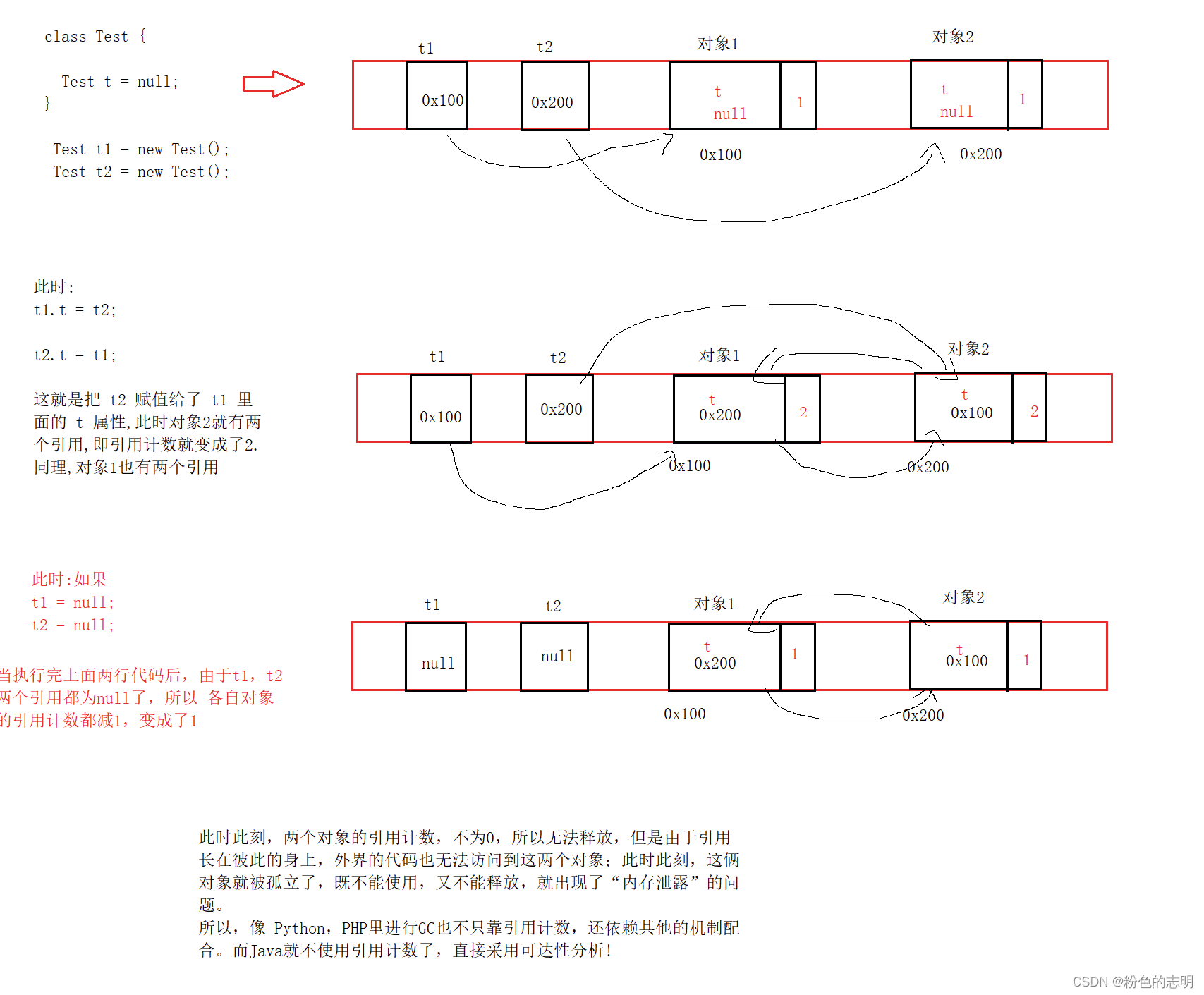
②アクセシビリティ分析に基づく
これは、追加のスレッドを介してメモリ空間全体のオブジェクトを定期的にスキャンすることです。深さ優先探索に似た開始位置(GCRootsと呼ばれる)がいくつかあり、アクセス可能なすべてのオブジェクトにマークを付けます(マークアップを使用してオブジェクトは到達可能)、マークされていないオブジェクトは到達不能、つまりガベージ...
GCRoots:スタック上のローカル変数、定数プール内の参照によってポイントされるオブジェクト、メソッド領域内の静的メンバーによってポイントされるオブジェクトを参照します。
例えば:
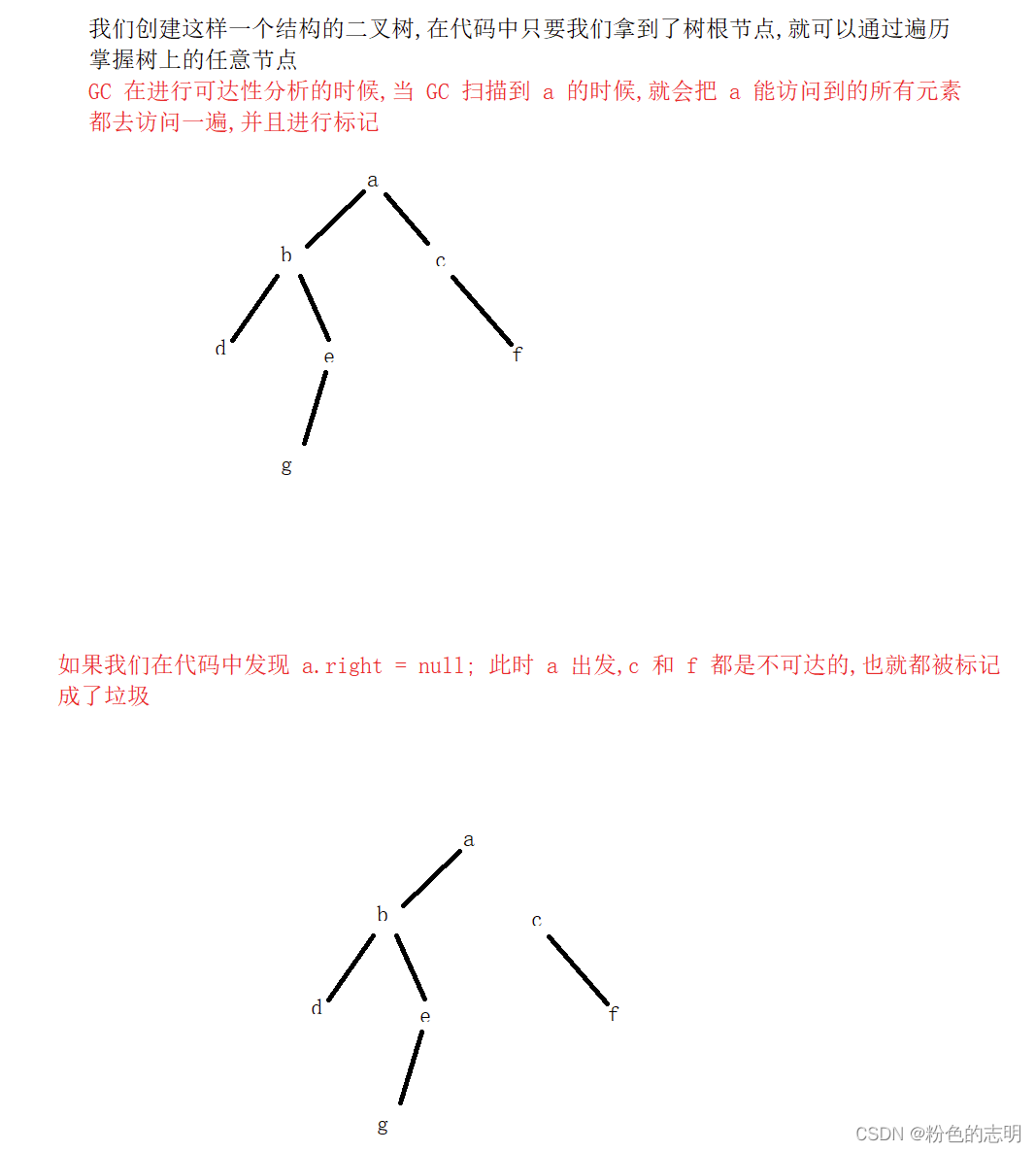
优点:参照カウントの2つの欠点、スペース使用率の低さ、循環参照の問題
缺点:、システムオーバーヘッドの高さを克服します。メモリ内のオブジェクトが多すぎると、1回のトラバースが遅くなり、時間とシステムリソースが消費される可能性があります。
つまり、ガベージを見つけることの核心は、オブジェクトが将来使用されるかどうかを確認することです。つまり、何が使用されないのでしょうか。つまり、参照ポイントがない場合は使用されません。
3.4.2ガベージコレクションアルゴリズム
①マークスイープアルゴリズム
マーキングは到達可能性分析のプロセスであり、クリアはメモリを直接解放すること
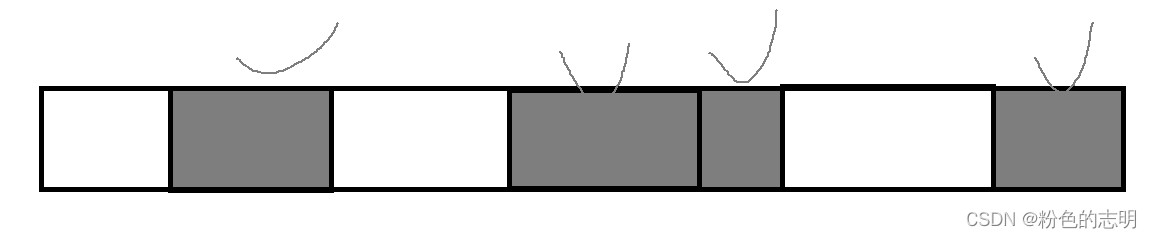
です。この時点でメモリが直接解放されると、メモリはシステムに戻されますが、解放されたメモリは離散的で連続的ではなく、それがもたらす問題は「メモリの断片化」です
空きメモリがたくさんあります。合計メモリを1Gとすると、500Mのメモリを適用すると、アプリケーションが失敗する可能性もあります(適用された500Mは連続メモリであるため)。各アプリケーションは、メモリは連続したスペースである必要があり、ここでの1Gの空きメモリは単に「メモリの断片化」であり、合計で1Gになる可能性があります。
②コピーアルゴリズム
「メモリの断片化の問題」を解決するために、コピーアルゴリズムが導入されました。一般的には、「半分を使用し、半分を失う」です。
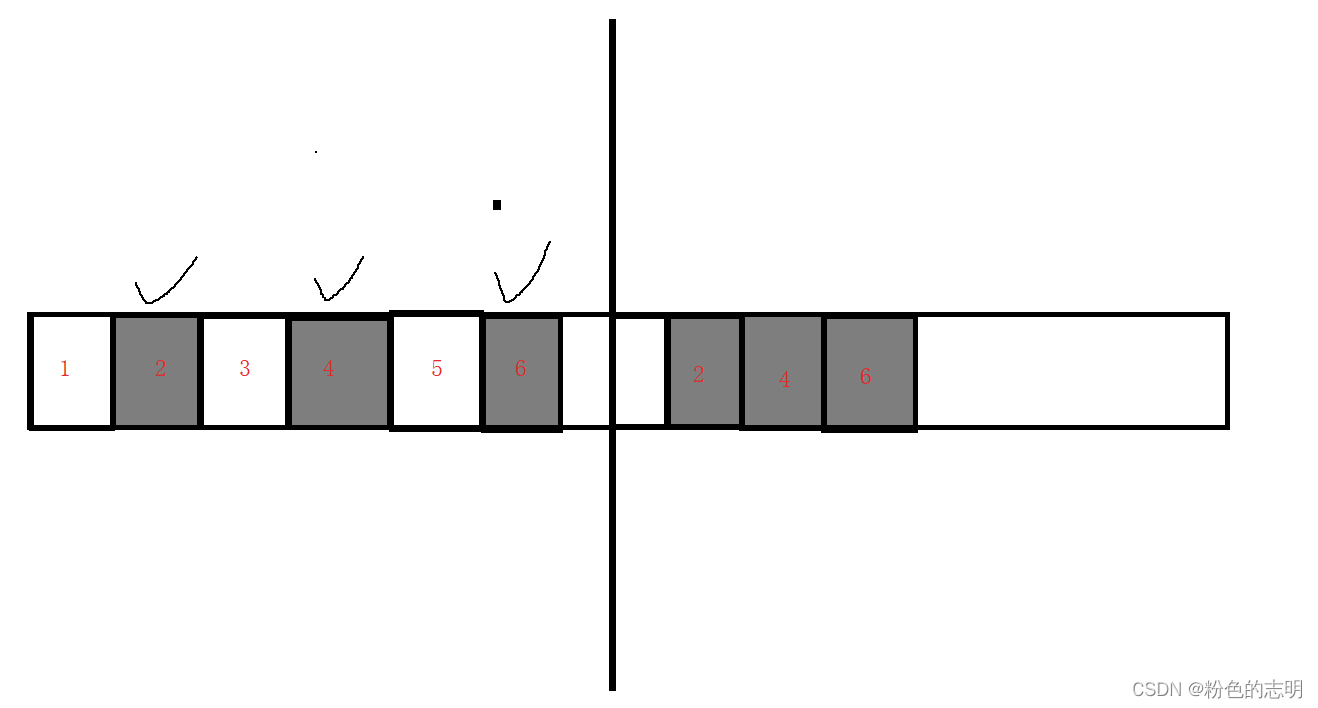
ゴミ以外の部分を直接コピーして、元のスペース全体を解放!
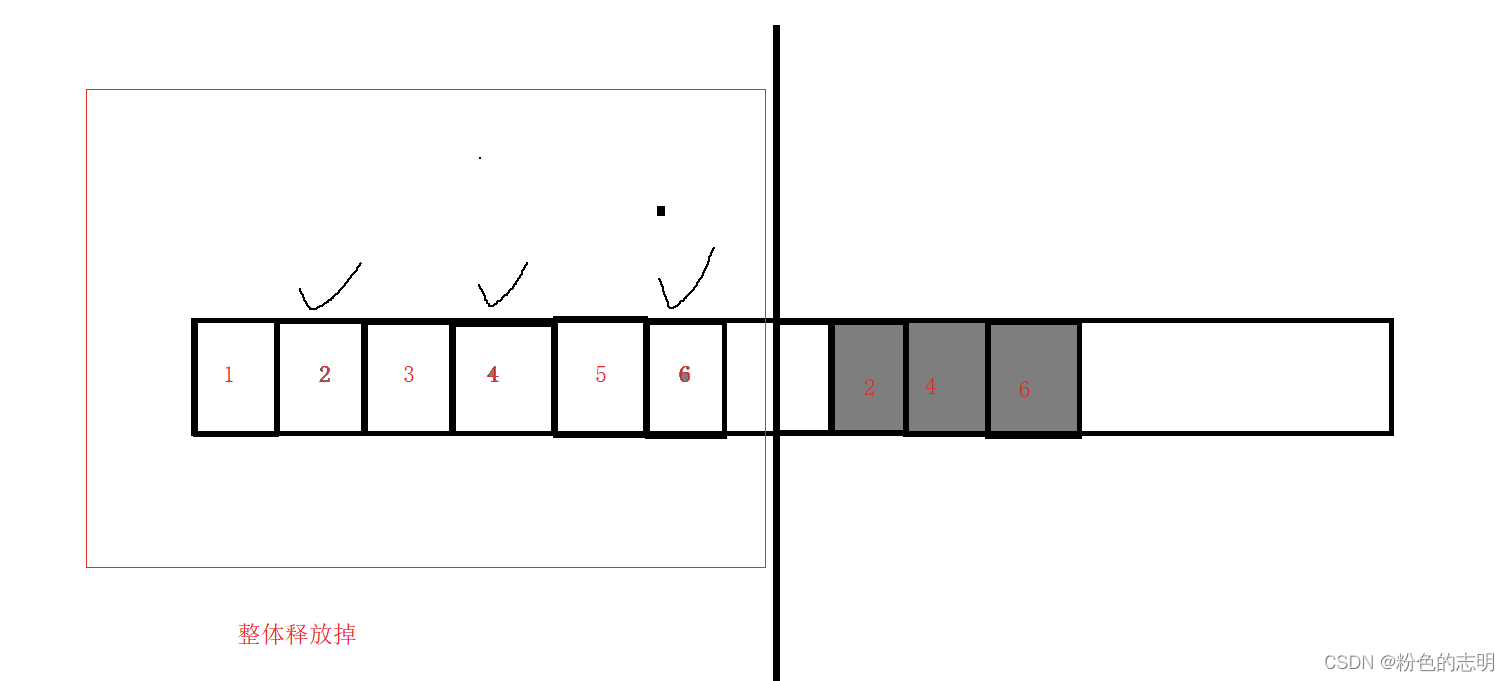
优点:「メモリの断片化」の問題を解決しました
缺点:1.メモリスペースの使用率が低い2.保持するオブジェクトが多く、解放するオブジェクトが少ない場合、レプリケーションのオーバーヘッドは非常に大きくなります。
③マーキング照合アルゴリズム
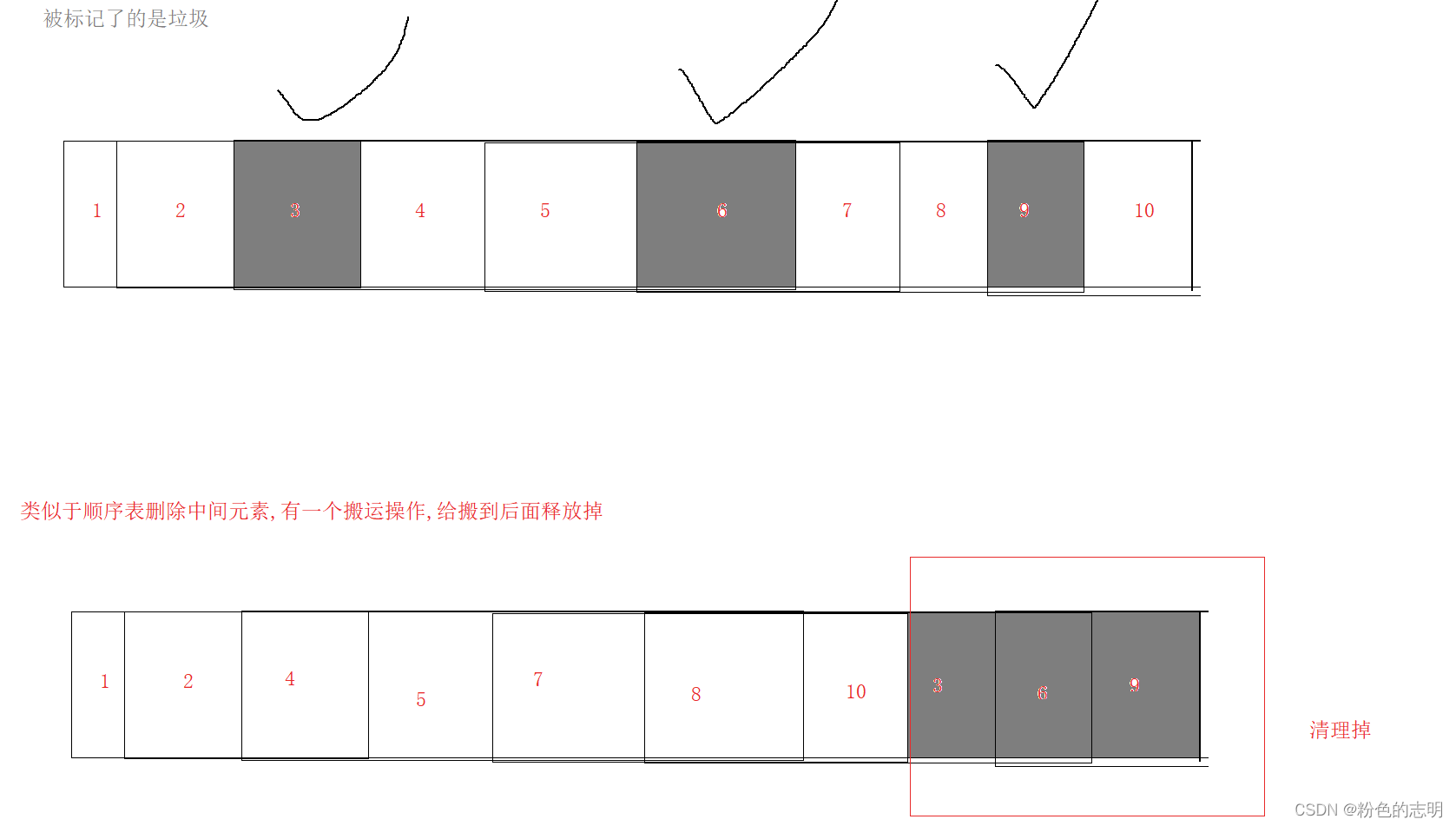
优点:スペース使用率は高いですが、
缺点:要素のコピー/移動のコストが高いという問題はまだ解決されていません
上記のすべてに欠陥がありますが、JVMでの実装はさまざまなスキームの組み合わせを使用します。
④世代別リサイクルアルゴリズム
オブジェクトを分類するために(オブジェクトの「年齢」に従って分類)、オブジェクトは「1年前」と呼ばれるGCスキャンのラウンドを生き延び、さまざまな年齢のオブジェクトに対してさまざまな計画が採用されます。
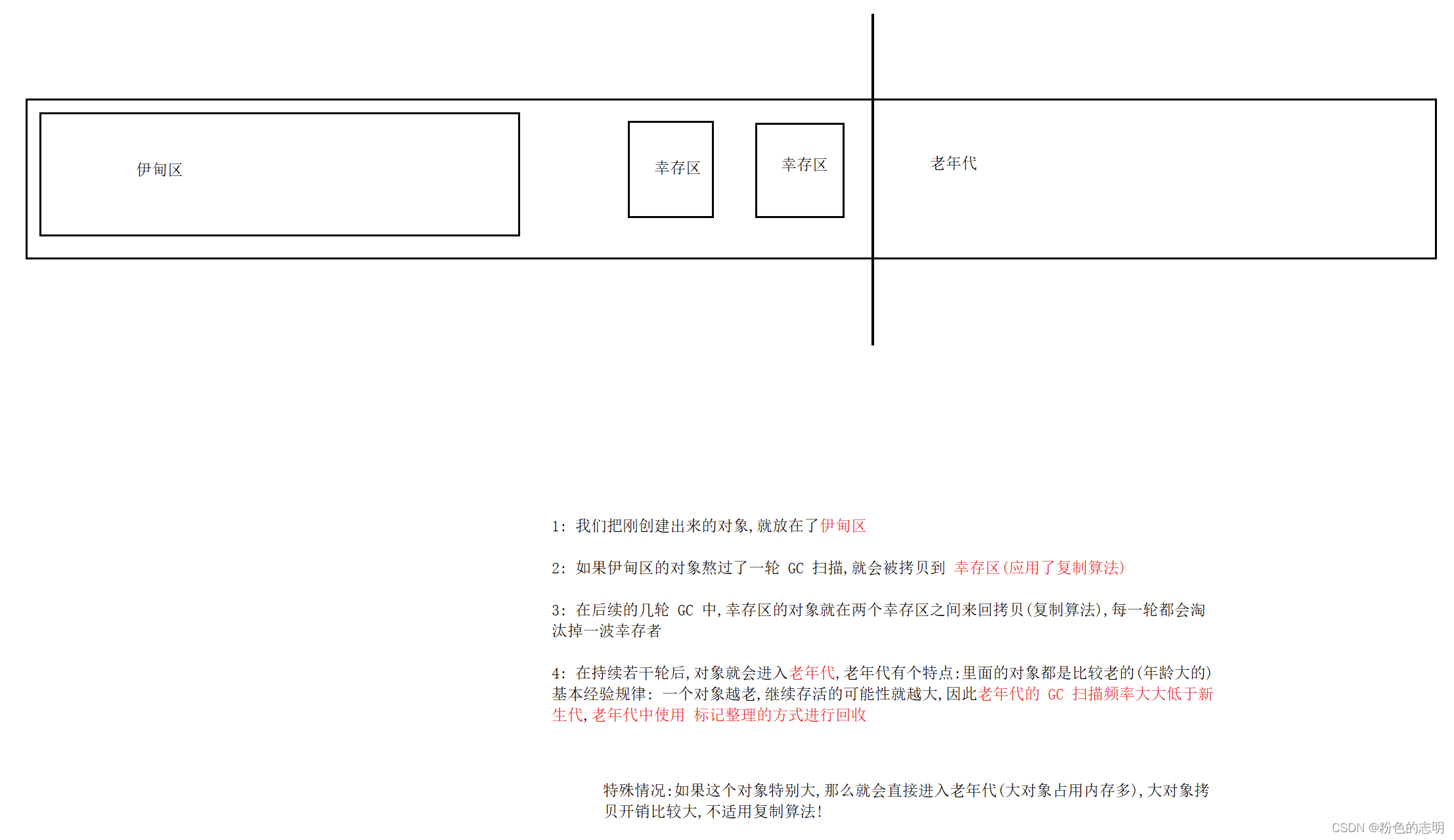
注意:インターネット上で、98%の新しいオブジェクトがGCのラウンドを生き残ることができず、2%の新しいオブジェクトがサバイバルエリアに入るということわざがあるかもしれません。この数は実際には信頼できません。誰かが尋ねた場合、それを言わないのが最善です。 、ほとんどのオブジェクトは1回のGCラウンドで生き残ることができないと言ってください。