1はじめに
Xiao Diaosi:Yu兄弟、最近少しとんでもないことです。
Xiaoyu:え??どういう意味ですか
〜Xiao Diaosi:1週間経ちましたが、私はほとんど知識を共有していません。
Xiaoyu:これだけの理由で??
Xiao Diaosi:つまり、私は学ぶことが大好きです。
Xiaoyu:あなたが解決できないことがあるのではないかと思います。私のことを考えますか?
Xiao Diaosi:ああ〜冗談〜私は...何...何...ものを...
Xiaoyu:さあ、
Xiaodiaosi:あなたは私にこれを言うように頼んだ、私は尋ねる主導権を握らなかった!
Xiaoyu:さあ、なぜまだおしゃべりしているのですか?
Xiaodiaosi:あるサイトからダウンロードしたpfdファイルに透かしが入っていますが、どうすれば削除できますか?
Xiaoyu:PPTがまだ終わっていないことを突然思い出しました。
Xiao Diaosi:階下にバーベキューレストランをオープンしたばかりです。悪くないと言われています!
Xiaoyu:PPTを書き終えることができません。夜に書くことができます。他の人を助けることで、私は幸せになります。

2.コード戦闘
前回のブログ投稿では、PDFドキュメントに透かしを追加する方法を知ってい
ました。この記事では、PDFから透かしを削除します。
透かしを追加する方法がわからない場合は、次のように読んでください。「Python3、2つのコード、pdfファイルに透かしを追加すると、元の透かしもこのように再生できます。》
Xiao Diaosi:透かしを追加してから削除しましたが、何をしていますか??
Xiaoyu:私はそれが好きです、私はまれです、私はしたいです!!
2.1除去の原則
除去方法:
- 1. PyMuPDFでPDFファイルを開き、PDFの各ページを画像のピックスマップに変換します。
- 2. pixmapには独自のRGBがあり、PDF透かしのRGBを(255、255、255)に変更して、画像を保存するだけです。
- 3.生成された画像をPDFドキュメントに挿入します
pfdドキュメントは透かしを直接削除できないため、最初にpfdドキュメントを画像に変換し、画像に対して透かし削除操作を1つずつ実行し、最後に画像をpdfドキュメントに挿入する必要があります。
2.2コード分析
1.最初にPDFドキュメントの透かしのrgb値を確認します。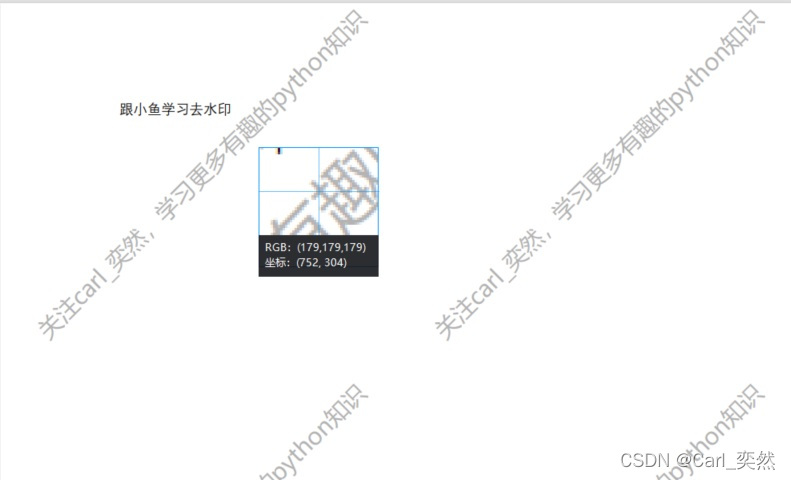
ここではRGBカラー値の合計が必要であるため、RGB(179,179,179)であることがわかります。したがって、510を超える場合は考慮されると考えられます。透かしになります。
黒板をノックする
- 光学原色の3色は赤、緑、青(RGB)で、分解できない基本色の3色です。他のすべての色は、これらの3色を混合することで形成できます。3色を等比率で混合して形成します。白で、光は黒ではありません。
- コンピューターでは、3バイトを使用してRGBカラーを表すことができ、1バイトが表すことができる最大値は255です。したがって、(255、0、0)は赤を表し、(0、255、0)は緑を表し、( 0)、0、255)は青を表します。したがって、(255、255、255)は白を表し、(0、0、0)は黒を表します。(0、0、0)〜(255、255、255)の任意の組み合わせは、異なる色を表すことができます。
- 画像の各位置の色は4倍で表され、最初の3つはRGBで、4つ目はアルファチャネルです。
2. PDFを画像に変換し、透かしの
コード例を削除します。
# -*- coding:utf-8 -*-
# @Time : 2022-02-23
# @Author : carl_DJ
from PIL import Image
from itertools import product
import fitz
# 去除pdf的水印
def remove_pdfwatermark():
#打开源pfd文件
pdf_file = fitz.open("跟小鱼学习去水印.pdf")
#page_no 设置为0
page_no = 0
#page在pdf文件中遍历
for page in pdf_file:
#获取每一页对应的图片pix (pix对象类似于我们上面看到的img对象,可以读取、修改它的 RGB)
#page.get_pixmap() 这个操作是不可逆的,即能够实现从 PDF 到图片的转换,但修改图片 RGB 后无法应用到 PDF 上,只能输出为图片
pix = page.get_pixmap()
#遍历图片中的宽和高,如果像素的rgb值总和大于510,就认为是水印,转换成255,255,255-->即白色
for pos in product(range(pix.width), range(pix.height)):
if sum(pix.pixel(pos[0], pos[1])) >= 510:
pix.set_pixel(pos[0], pos[1], (255, 255, 255))
#保存去掉水印的截图
pix.pil_save(f"./{
page_no}.png", dpi=(30000, 30000))
#打印结果
print(f'第 {
page_no} 页去除完成')
page_no += 1
if __name__ == '__main__':
remove_pdfwatermark()
実行が完了したら、
生成されたイメージを表示します。
画像の内容を表示し

ます。3。画像をPDFに変換します
コード例:
# -*- coding:utf-8 -*-
# @Time : 2022-02-23
# @Author : carl_DJ
from PIL import Image
from itertools import product
import fitz
''' 图片转为pdf'''
#图片所在的文件夹
pic_dir = 'D:\Project\watemark'
pdf = fitz.open()
#图片数字文件先转换成int类型进行排序
img_files = sorted(os.listdir(pic_dir), key=lambda x: int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
#将打开后的图片转成单页pdf
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
#将单页pdf插入到新的pdf文档中
pdf.insertPDF(imgpdf)
pdf.save("跟小鱼学习去水印_完成.pdf")
pdf.close()
コードを実行して
、生成されたpdfドキュメントを表示します
2.3コード統合
上記の内容を理解した後、コードを統合して直接実行できます。
# -*- coding:utf-8 -*-
# @Time : 2022-02-23
# @Author : carl_DJ
from PIL import Image
from itertools import product
import fitz
# 去除pdf的水印
def remove_pdfwatermark():
#打开源pfd文件
pdf_file = fitz.open("跟小鱼学习去水印.pdf")
#page_no 设置为0
page_no = 0
#page在pdf文件中遍历
for page in pdf_file:
#获取每一页对应的图片pix (pix对象类似于我们上面看到的img对象,可以读取、修改它的 RGB)
#page.get_pixmap() 这个操作是不可逆的,即能够实现从 PDF 到图片的转换,但修改图片 RGB 后无法应用到 PDF 上,只能输出为图片
pix = page.get_pixmap()
#遍历图片中的宽和高,如果像素的rgb值总和大于510,就认为是水印,转换成255,255,255-->即白色
for pos in product(range(pix.width), range(pix.height)):
if sum(pix.pixel(pos[0], pos[1])) >= 510:
pix.set_pixel(pos[0], pos[1], (255, 255, 255))
#保存去掉水印的截图
pix.pil_save(f"./{
page_no}.png", dpi=(30000, 30000))
#打印结果
print(f'第 {
page_no} 页去除完成')
page_no += 1
#去除的pdf水印添加到pdf文件中
def pictopdf():
#水印截图所在的文件夹
# pic_dir = input("请输入图片文件夹路径:")
pic_dir = 'D:\Project\watemark'
pdf = fitz.open()
#图片数字文件先转换成int类型进行排序
img_files = sorted(os.listdir(pic_dir), key=lambda x: int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
#将打开后的图片转成单页pdf
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
#将单页pdf插入到新的pdf文档中
pdf.insertPDF(imgpdf)
pdf.save("跟小鱼学习去水印_完成.pdf")
pdf.close()
if __name__ == '__main__':
remove_pdfwatermark()
pictopdf()
3.まとめ
ここに書いて、今日の共有はもうすぐ終わります。
理解するプロセスは、
- 最初にPDFドキュメントを画像に変換する必要があり、透かしが削除されます。
- PDFに変換
- 最後に、新しいpdfドキュメントに挿入します。
写真やPDFに透かしを追加する方法については、Xiaoyuによる次の2つのブログ投稿を参照してください。