ディープラーニング推奨モデル-DeepCrossing
この記事の参照リンクは個人学習専用です:https://github.com/datawhalechina/team-learning-rs/tree/master/DeepRecommendationModel
関連する学習本の推奨事項:「ディープラーニング推奨システム」Wang Zhe

1.ディープクロッシングの背景
2016年、マイクロソフトは、特徴工学における特徴の組み合わせの問題を解決し、人的資源の特徴の組み合わせの時間コストを削減することを目的としたディープクロッシングモデルを提案しました。特徴の組み合わせを自動的に学習するモデルを通じて、良好な結果を達成することもできます。さまざまな作業に使用でき、安定性に優れています。以前に導入されたFNNおよびPNNとは異なり、ディープクロッシングは明示的なクロス機能を使用しませんが、残りのネットワーク構造を使用して機能間の関係をマイニングします。この記事では、DeepCrossingの原理から実装の詳細までの詳細な分析を行います。
DeepCrossingモデルのアプリケーションシナリオは、Microsoft検索エンジンBingでの検索広告の推奨です。ユーザーが検索用語を入力すると、検索エンジンは関連する結果だけでなく、検索用語に関連する広告も返します。DeepCrossingの最適化の目標は次のとおりです。特定の広告を予測します。ユーザーがクリックするかどうかは、クリックスルー率の予測の問題です。
1.DeepCrossingモデルの構造と原理
エンドツーエンドのトレーニングを完了するには、DeepCrossingモデルで内部ネットワーク構造の次の問題を解決する必要があります。
- 離散特徴は、エンコード後にスパースすぎます。これは、ニューラルネットワークトレーニングへの直接入力を助長しません。スパース特徴ベクトルの高密度化の問題を解決する必要があります。
- 機能の自動クロスコンビネーションの問題を解決する方法
- 出力層の問題によって設定された最適化目標を達成する方法
DeepCrossingは、上記の問題を解決するためにさまざまなニューラルネットワークレイヤーを設定します。

モデル全体には、埋め込み、スタッキング、残余ユニット、スコアリングレイヤーの4つの構造が含まれています。

各層構造の次の分析:
1.埋め込みレイヤー:主に従来の完全に接続されたレイヤー構造に基づいて、疎なカテゴリの特徴を密な埋め込みベクトルに変換します。一般に、埋め込みベクトルの次元は、元のスパース特徴ベクトルよりもはるかに小さい必要があります。ここで、フィーチャ#2世紀は数値フィーチャを表しています。数値フィーチャは埋め込みレイヤーを通過する必要はなく、直接スタッキングレイヤーに入ることがわかります。
2.スタッキングレイヤー:スタッキングレイヤー(スタッキングレイヤー)の機能は比較的単純です。これは、連結レイヤーとも呼ばれる、さまざまな埋め込み機能と数値機能をつなぎ合わせることです。
3.多層残余ユニット層:主な構造は多層パーセプトロンです。ニューラルネットワークの基本単位である標準の多層パーセプトロンと比較して、ディープクロッシングモデルは多層残余ネットワーク(多層残余)を使用します。ネットワーク)MLP実装として。多層残余ネットワークを介して、特徴ベクトルの各次元が完全に相互結合されます。
4.スコアリングレイヤー:スコアリングレイヤーは、最適化ターゲットに適合する出力レイヤーとして使用されます。CTR推定などのバイナリ分類問題の場合、スコアリングレイヤーはロジスティック回帰モデルを使用することがよくあります。画像などの複数分類問題の場合、スコアリングレイヤーはしばしばsoftmax。モデルを使用します。
2.1埋め込みレイヤー
スパースなカテゴリ特徴を密な埋め込みベクトルに変換すると、埋め込みの次元は元のスパース特徴ベクトルよりもはるかに小さくなります。埋め込みはNLPで一般的に使用される手法であり、特徴#1はカテゴリ特徴(ワンホットエンコーディング後のスパース特徴ベクトル)を表し、特徴#2は数値特徴であり、埋め込みなしで直接スタッキングレイヤーに送られます。埋め込みレイヤーの実装に関しては、通常は完全に接続されたレイヤーで十分であり、Tensorflowには直接使用できる適切に実装されたレイヤーがあります。これは、Word2Vec、言語モデルなどのNLPへの埋め込みテクノロジーに似ています。
2.2スタッキングレイヤー
このレイヤーは、さまざまな埋め込み特徴と数値特徴をつなぎ合わせて、すべての特徴を含む新しい特徴ベクトルを形成します。このレイヤーは通常、接続レイヤーと呼ばれます。具体的な実装は次のとおりです。まず、すべての数値特徴が結合され、次に、すべての埋め込みが一緒にスプライスされ、最後に数値機能と埋め込み機能がDNNの入力として一緒にスプライスされます。ここで、TFは連結レイヤーを介してスプライスされます。
#将所有的dense特征拼接到一起
dense_dnn_list = list(dense_input_dict.values())
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list) # B x n (n表示数值特征的数量)
# 因为需要将其与dense特征拼接到一起所以需要Flatten,不进行Flatten的Embedding层输出的维度为:Bx1xdim
sparse_dnn_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list) # B x m*dim (n表示类别特征的数量,dim表示embedding的维度)
# 将dense特征和Sparse特征拼接到一起
dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs]) # B x (n + m*dim)2.3複数の残余ユニットレイヤー
この層の主な構造はMLPですが、DeepCrossingは残りのネットワークの接続を使用します。多層残余ネットワークは、特徴ベクトルのさまざまな次元を完全に相互結合するため、モデルはより多くの非線形特徴と結合された特徴情報をキャプチャし、モデルの表現力を高めることができます。残りのネットワーク構造を次の図に示します。
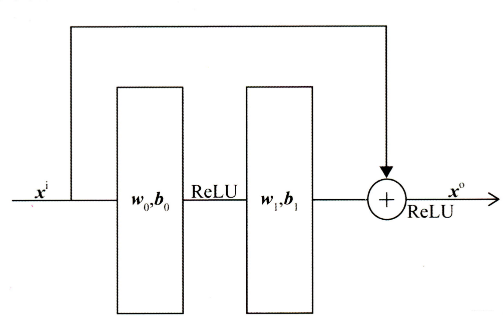
ディープクロッシングモデルは、わずかに変更された残余単位を使用します。畳み込みカーネルを使用せず、代わりに2層ニューラルネットワークを使用します。ReLU変換の2つのレイヤーを介して元の入力特徴を追加することにより、残余単位が実現されていることがわかります。具体的なコードの実装は次のとおりです。
# DNN残差块的定义
class ResidualBlock(Layer):
def __init__(self, units): # units表示的是DNN隐藏层神经元数量
super(ResidualBlock, self).__init__()
self.units = units
def build(self, input_shape):
out_dim = input_shape[-1]
self.dnn1 = Dense(self.units, activation='relu')
self.dnn2 = Dense(out_dim, activation='relu') # 保证输入的维度和输出的维度一致才能进行残差连接
def call(self, inputs):
x = inputs
x = self.dnn1(x)
x = self.dnn2(x)
x = Activation('relu')(x + inputs) # 残差操作
return x2.4スコアリングレイヤー
これは、最適化ターゲットに合わせるための出力レイヤーです。CTR推定の2クラス問題の場合、スコアリングではロジスティック回帰を使用することがよくあります。モデルは、複数の残差ブロックを重ね合わせることでネットワークの深さを深め、最終的に結果を出力の確率値に変換します。
# block_nums表示DNN残差块的数量
def get_dnn_logits(dnn_inputs, block_nums=3):
dnn_out = dnn_inputs
for i in range(block_nums):
dnn_out = ResidualBlock(64)(dnn_out)
# 将dnn的输出转化成logits
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
return dnn_logits总结これはDeepCrossingの構造であり、比較的明確で単純です。特別なモデル構造は導入されていませんが、従来のEmbedding +多層ニューラルネットワークが導入されています。しかし、このネットワークモデルの出現は革命的な重要性を持っています。DeepCrossingモデルには、人工的な特徴エンジニアリングは含まれていません。単純な特徴処理のみが必要です。元の特徴は、埋め込み層を介してニューラルネットワーク層に入力され、自動的に交差して学習されます。FMと比較して、FFMには2次の特徴クロスオーバー機能を備えたモデルしかありません。DeepCrossingはニューラルネットワークの深さを調整することで特徴間の「ディープクロスオーバー」を実行できます。これはディープクロッシングの名前の由来でもあります。。
2、完全なコードの実際の戦闘
import warnings
warnings.filterwarnings("ignore")
import itertools
import pandas as pd
import numpy as np
from tqdm import tqdm
from collections import namedtuple
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
def data_process(data_df, dense_features, sparse_features):
"""
简单处理特征,包括填充缺失值,数值处理,类别编码
param data_df: DataFrame格式的数据
param dense_features: 数值特征名称列表
param sparse_features: 类别特征名称列表
"""
data_df[dense_features] = data_df[dense_features].fillna(0.0)
for f in dense_features:
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
for f in sparse_features:
lbe = LabelEncoder()
data_df[f] = lbe.fit_transform(data_df[f])
return data_df[dense_features + sparse_features]
def build_input_layers(feature_columns):
"""
构建输入层
param feature_columns: 数据集中的所有特征对应的特征标记之
"""
# 构建Input层字典,并以dense和sparse两类字典的形式返回
dense_input_dict, sparse_input_dict = {}, {}
for fc in feature_columns:
if isinstance(fc, SparseFeat):
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
elif isinstance(fc, DenseFeat):
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
return dense_input_dict, sparse_input_dict
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
# 定义一个embedding层对应的字典
embedding_layers_dict = dict()
# 将特征中的sparse特征筛选出来
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
if is_linear:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, 1, name='1d_emb_' + fc.name)
else:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size + 1, fc.embedding_dim, name='kd_emb_' + fc.name)
return embedding_layers_dict
# 将所有的sparse特征embedding拼接
def concat_embedding_list(feature_columns, input_layer_dict, embedding_layer_dict, flatten=False):
# 将sparse特征筛选出来
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns))
embedding_list = []
for fc in sparse_feature_columns:
_input = input_layer_dict[fc.name] # 获取输入层
_embed = embedding_layer_dict[fc.name] # B x 1 x dim 获取对应的embedding层
embed = _embed(_input) # B x dim 将input层输入到embedding层中
# 是否需要flatten, 如果embedding列表最终是直接输入到Dense层中,需要进行Flatten,否则不需要
if flatten:
embed = Flatten()(embed)
embedding_list.append(embed)
return embedding_list
# DNN残差块的定义
class ResidualBlock(Layer):
def __init__(self, units): # units表示的是DNN隐藏层神经元数量
super(ResidualBlock, self).__init__()
self.units = units
def build(self, input_shape):
out_dim = input_shape[-1]
self.dnn1 = Dense(self.units, activation='relu')
self.dnn2 = Dense(out_dim, activation='relu') # 保证输入的维度和输出的维度一致才能进行残差连接
def call(self, inputs):
x = inputs
x = self.dnn1(x)
x = self.dnn2(x)
x = Activation('relu')(x + inputs) # 残差操作
return x
# block_nums表示DNN残差块的数量
def get_dnn_logits(dnn_inputs, block_nums=3):
dnn_out = dnn_inputs
for i in range(block_nums):
dnn_out = ResidualBlock(64)(dnn_out)
# 将dnn的输出转化成logits
dnn_logits = Dense(1, activation='sigmoid')(dnn_out)
return dnn_logits
def DeepCrossing(dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(dnn_feature_columns)
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
embedding_layer_dict = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
#将所有的dense特征拼接到一起
dense_dnn_list = list(dense_input_dict.values())
dense_dnn_inputs = Concatenate(axis=1)(dense_dnn_list) # B x n (n表示数值特征的数量)
# 因为需要将其与dense特征拼接到一起所以需要Flatten,不进行Flatten的Embedding层输出的维度为:Bx1xdim
sparse_dnn_list = concat_embedding_list(dnn_feature_columns, sparse_input_dict, embedding_layer_dict, flatten=True)
sparse_dnn_inputs = Concatenate(axis=1)(sparse_dnn_list) # B x m*dim (n表示类别特征的数量,dim表示embedding的维度)
# 将dense特征和Sparse特征拼接到一起
dnn_inputs = Concatenate(axis=1)([dense_dnn_inputs, sparse_dnn_inputs]) # B x (n + m*dim)
# 输入到dnn中,需要提前定义需要几个残差块
output_layer = get_dnn_logits(dnn_inputs, block_nums=3)
model = Model(input_layers, output_layer)
return model
if __name__ == "__main__":
# 读取数据
data = pd.read_csv('./data/criteo_sample.txt')
# 划分dense和sparse特征
columns = data.columns.values
dense_features = [feat for feat in columns if 'I' in feat]
sparse_features = [feat for feat in columns if 'C' in feat]
# 简单的数据预处理
train_data = data_process(data, dense_features, sparse_features)
train_data['label'] = data['label']
# 将特征做标记
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for feat in sparse_features] + [DenseFeat(feat, 1,)
for feat in dense_features]
# 构建DeepCrossing模型
history = DeepCrossing(dnn_feature_columns)
history.summary()
history.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
# 将输入数据转化成字典的形式输入
train_model_input = {name: data[name] for name in dense_features + sparse_features}
# 模型训练
history.fit(train_model_input, train_data['label'].values,
batch_size=64, epochs=5, validation_split=0.2, )