ステートメント
一部のメタ文字はどの文字とも一致しませんが、単に成功または失敗を示すため、これらの文字はゼロ幅アサーションとも呼ばれます。例えば、\bそれが表す現在位置がワード境界であるが、\bと位置を変更しません。したがって、現在の位置を変更しないため、ゼロ幅アサーションを再利用しないでください。現在も違いはありません。\b\b\b\b
説明:
多くの人は「位置の変更」と「ゼロ幅アサーション」の意味を理解していないかもしれませんか?たとえば、abcaの一致が終了した後、bの一致を継続するために現在の位置を移動するなど、説明しようとしています...しかし\babc、は、単語(最初の文字)の境界の現在の位置を\b表します。単語または最後の文字の)、この時点では、現在の位置は変更されず、現在の位置の文字と一致します。
|
OR演算子は、2つの正規表現に対してOR演算を実行します。AとBが正規表現の場合A | B、AまたはBのすべての文字が一致します。より合理的に働くことができるようにするために|、優先順位は非常に低くなっています。たとえば、Fish|C一致するか魚CでFisある'h'必要があり'C'ますが、一致しない場合は、または。
同様に、を使用\|し'|'て文字自体を照合します。または、このように文字クラスに含まれ[|]ます。
^
一致した文字列の開始位置。MULTILINEフラグを設定すると、各行の一致開始位置になります。ではMULTILINE真ん中、それは改行に遭遇した時はいつでもすぐにマッチします。
たとえば、文字列の先頭にある単語のみを照合するFrom場合、正規表現は次のように記述できます^From。
>>> print(re.search('^From', 'From Here to'))
<_sre.SRE_Match object; span=(0, 4), match='From'>
>>> print(re.search('^From', 'Reciting From Memory'))
None
結果を達成する:
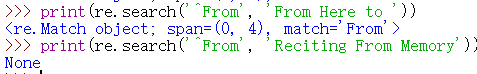
$
一致する文字列の終了位置。改行文字が検出されるたびに、一致するために残されます。
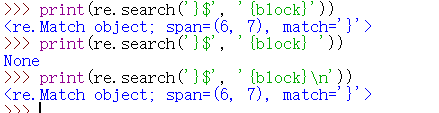
>>> print(re.search('}$', '{block}'))
<_sre.SRE_Match object; span=(6, 7), match='}'>
>>> print(re.search('}$', '{block} '))
None
>>> print(re.search('}$', '{block}\n'))
<_sre.SRE_Match object; span=(6, 7), match='}'>
結果を達成する:
同様に、我々は、使用\$一致する'$'文字自体を、または文字クラスに含まれている、のような[$]。
print(re.search('}[$]', '{block}$'))
print(re.search('}\$', '{block}$'))
結果を達成する:
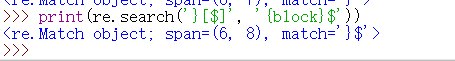
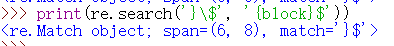
\ A
文字列の先頭のみに一致します。と関数が同じときに MULTILINEフラグを設定しない場合、ただしフラグを設定すると、何かが異なります。文字列の先頭と一致しますが、各行の文字列は一致します。\A^MULTILINE\A^
\ WITH
文字列の終了位置のみに一致します。
\ b
単語の境界。これは、単語の最初と最後にのみ一致する幅ゼロのアサーションです。「単語」は英数字シーケンスとして定義されているため、単語の終わりはスペースまたは英数字以外の文字を指します。
次の例でclassは、完全な単語classが一致する場合にのみ一致します。他の単語に存在する場合のみ、一致しません。
>>> p = re.compile(r'\bclass\b')
>>> print(p.search('no class at all'))
<_sre.SRE_Match object; span=(3, 8), match='class'>
>>> print(p.search('the declassified algorithm'))
None
>>> print(p.search('one subclass is'))
None
結果を達成する:

これらの特別なシーケンスを使用する場合、注意すべき2つのポイントがあります。最初に注意すべき点はPython、文字列と正規表現の一部の文字で競合があることです(前の円記号の例を思い出してください)。たとえば、Pythonでは\b、バックスペース文字を表します(ASCIIコード値は8です)。したがって、元の文字列を使用しない場合、Pythonは\ bをバックスペース文字に変換します。これは、予想とは明らかに異なります。
次の例では、我々は意図的に書いていない元の文字列を、'r'そしてその結果は確かに非常に異なっています:
>>> p = re.compile('\bclass\b')
>>> print(p.search('no class at all'))
None
>>> print(p.search('\b' + 'class' + '\b'))
<_sre.SRE_Match object; span=(0, 7), match='\x08class\x08'>
結果を達成する:


注意すべき2番目のポイントは、このアサーションは文字クラスでは使用できないということです。Pythonと同様に、文字クラスで\bは、バックスペース文字を表すためにのみ使用されます。
\ B
ゼロ幅アサーションと、\b反対の意味は、\Bを表し、非ワード境界の位置を。
グループ化
通常、実際の申請プロセスでは、正規表現が一致するかどうかを知ることに加えて、より多くの情報も必要です。より複雑なコンテンツの場合、正規表現は通常、グループ化を使用して異なるコンテンツを個別に照合します。
以下の例は、我々はなりますRFC-822頭“:”の数に名前と値をそれぞれ一致します:
From: author@example.com
User-Agent: Thunderbird 1.5.0.9 (X11/20061227)
MIME-Version: 1.0
To: editor@example.com
このように、最初のRFC-822頭全体に一致する正規表現を記述してから、グループ関数を使用し、グループを使用して頭の名前に一致させ、他のグループを対応する値の名前に一致させることができます。
RFC-822これはメールの標準形式です。もちろん、ここに表示されているときにグループを分割する方法はわかりません。心配しないでください。以下をお読みください...
正規表現で、グループ( )を分割するためのメタ文字の使用。( )メタ文字は、数式の括弧と同じ意味です。メタ文字は、内部に含まれる式を組み合わせているため、*、+、?、{m,n}。など、グループのコンテンツに対して操作を繰り返すメタ文字を使用できます。
たとえば、(ab)*0個以上に一致しますab。
>>> p = re.compile('(ab)*')
>>> print(p.match('ababababab').span())
(0, 10)


使用( ):我々はレイヤインデックスを実行することができ、それによって表されるサブグループは、インデックス値は、これらのメソッドにパラメータとして渡すことができgroup()、start()、end()とspan()。シリアル番号0は最初のグループを表します(これはデフォルトのグループであり、常に存在するため、パラメーターを渡さないことはデフォルト値の0と同等です)。
>>> p = re.compile('(a)b')
>>> m = p.match('ab')
>>> m.group()
'ab'
>>> m.group(0)
'ab'

ある括弧のいくつかの対が複数のサブグループに分割され、例えば、(a)(b)そして(a(b))その2つのサブグループで構成されています。
サブグループのインデックス値には左から右に番号が付けられ、サブグループをネストすることもできるため、左括弧を数えることができます(左から右にサブグループの数を決定します)。
>>> p = re.compile('(a(b)c)d')
>>> m = p.match('abcd')
>>> m.group(0)
'abcd'
>>> m.group(1)
'abc'
>>> m.group(2)
'b'

group()メソッドは、複数のサブグループのシリアル番号を一度に渡すことができます。
>>> m.group(2,1,2)
('b', 'abc', 'b')
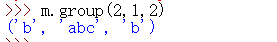
start()パラメータサブグループの開始位置end()を取得することspan()です。対応するサブグループの終了位置を取得することです。対応するサブグループの範囲を取得することです。
groups()一致するすべての文字列サブセットの使い捨てメソッドを返すことができます。
>>> m.groups()
('abc', 'b')
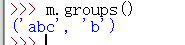
後方参照
導入する必要のある後方参照の概念もあります。後方参照とは、以前に一致したコンテンツを後方の位置で使用できることを意味します。使用法は円記号と数字です。たとえば、サブグループの一致が成功する前の参照番号を\1表します。
>>> p = re.compile(r'(\b\w+)\s+\1')
>>> p.search('Paris in the the spring').group()
'the the'
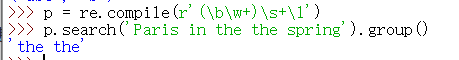
文字列のみを検索する場合、この方法で文字を繰り返すテキスト形式はほとんどないため、後方参照は使用されません。ただし、文字列を置き換えるときに後方参照が非常に役立つことがすぐにわかります。
注意
Pythonの言葉では、文字列はバックスラッシュと値に対応するASCII文字番号を表す方法の数を使用するため、正規表現の転置インデックスを使用しますが、元の文字列を使用する必要があることを強調しました。