目次
1: はじめに
正規表現 (Regular Expression) は、通常の文字 (a と z の間の文字など) と特殊文字 (「メタ文字」と呼ばれる) を含むテキスト パターンです。
正規表現は、単一の文字列を使用して、特定の構文規則に一致する一連の文字列を記述および照合します。
正規表現は面倒ですが、強力で、学習後の応用は作業の効率化だけでなく、達成感をもたらします。
正規表現の英語は正規表現であるため、通常、これら 2 つの単語の最初の数文字を一緒に使用して、正規表現に関連する変数名を regexp (単数形) または regexps (複数形) として定義します。
Java の String クラスには、正規表現をサポートする関連する置換メソッドがいくつかあり、そのパラメーター名も正規表現です。
2: 構造構成
(1) 構成
通常、正規表現は通常の文字とメタ文字で構成されます。
通常の文字: 文字自体の場合、通常使用する大文字と小文字の文字や数字のように、それ以外の意味はありません。
メタ文字: 文字そのものであることに加えて、他の意味を表現することもできます (次の表はすべてメタ文字です)。
| キャラクター | 説明 |
|---|---|
| \ | 次の文字を特殊文字、リテラル文字、後方参照、または 8 進エスケープとしてマークします。たとえば、「n」は文字「n」と一致します。'\n' は改行文字に一致します。シーケンス「\\」は「\」と一致し、「\(」は「(」と一致します。 |
| ^ | 入力文字列の先頭に一致します。RegExp オブジェクトの Multiline プロパティが設定されている場合、^ は '\n' または '\r' の後の位置にも一致します。 |
| $ | 入力文字列の末尾に一致します。RegExp オブジェクトの Multiline プロパティが設定されている場合、$ は '\n' または '\r' の前の位置にも一致します。 |
| * | 直前の部分式に 0 回以上一致します。たとえば、zo* は「z」だけでなく「zoo」にも一致します。* {0,} に相当します。 |
| + | 直前の部分式に 1 回以上一致します。たとえば、「zo+」は「zo」と「zoo」には一致しますが、「z」には一致しません。+ は {1,} と同等です。 |
| ? | 直前の部分式と 0 回または 1 回一致します。たとえば、「do(es)?」は「do」または「does」のいずれかに一致します。? は {0,1} と同等です。 |
| {n} | n は負でない整数です。正確に n 回一致します。たとえば、「o{2}」は「Bob」の「o」には一致しませんが、「food」の両方の o には一致します。 |
| {n,} | n は負でない整数です。少なくとも n 回一致します。たとえば、「o{2,}」は「Bob」の「o」には一致しませんが、「fooooood」のすべての o に一致します。「o{1,}」は「o+」と同等です。「o{0,}」は「o*」と同等です。 |
| {n,m} | m と n はどちらも非負の整数で、n <= m です。少なくとも n 回、最大で m 回一致します。たとえば、「o{1,3}」は「fooooood」の最初の 3 つの o に一致します。「o{0,1}」は「o?」と同等です。コンマと 2 つの数字の間にスペースを入れないでください。 |
| ? | この文字が他の修飾子 (*、+、?、{n}、{n,}、{n,m}) のいずれかの直後にある場合、マッチング パターンは貪欲ではありません。非貪欲モードは検索文字列に可能な限り一致しませんが、デフォルトの貪欲モードは検索文字列に可能な限り一致します。たとえば、文字列「oooo」の場合、「o+?」は単一の「o」に一致し、「o+」はすべての「o」に一致します。 |
| . | 改行 (\n、\r) を除く任意の 1 文字に一致します。「\n」を含む任意の文字に一致させるには、 「 (.|\n) 」のようなパターンを使用します。 |
| (パターン) | パターンに一致し、この一致を取得します。VBScript では SubMatches コレクションを使用し、JScript では $0…$9 プロパティを使用して、生成された Matches コレクションから取得された一致を取得できます。括弧文字を一致させるには、'\(' または '\)' を使用します。 |
| (?:パターン) | パターンに一致しますが、一致する結果を取得しません。つまり、取得しない一致であり、後で使用するために保存されません。これは、「または」文字 (|) を使用してパターンの一部を結合する場合に便利です。たとえば、'industr(?:y|ies)' は 'industry|industries' よりも短い表現です。 |
| (?=パターン) | パターンに一致する任意の文字列の先頭にあるルックアップ文字列に一致する肯定的なアサートを先読みします。これは非取得一致です。つまり、後で使用するために一致を取得する必要はありません。たとえば、「Windows(?=95|98|NT|2000)」は「Windows2000」の「Windows」に一致しますが、「Windows3.1」の「Windows」には一致しません。先読みは文字を消費しません。つまり、一致が発生した後、次の一致の検索は、先読みを含む文字の後ではなく、最後の一致の直後に開始されます。 |
| (?!パターン) | 正負のアサートは、パターンに一致しない文字列の先頭にある検索文字列に一致します。これは非取得一致です。つまり、後で使用するために一致を取得する必要はありません。たとえば、「Windows(?!95|98|NT|2000)」は「Windows3.1」の「Windows」と一致しますが、「Windows2000」の「Windows」とは一致しません。先読みは文字を消費しません。つまり、一致が発生した後、次の一致の検索は、先読みを含む文字の後ではなく、最後の一致の直後に開始されます。 |
| (?<=パターン) | リバース (後ろを向く) ポジティブ プリチェックは、フォワード ポジティブ プリチェックと似ていますが、方向が逆です。たとえば、" (?<=95|98|NT|2000)Windows" は " "2000Windowsの " Windows" に一致しますが、" "3.1Windowsの " Windows" には一致しません。 |
| (?<!パターン) | 逆ネガティブ ルックアップは、前方ネガティブ ルックアップに似ていますが、方向が逆です。たとえば、" " は " "の " "(?<!95|98|NT|2000)Windowsと一致しますが、" "の " " とは一致しません。3.1WindowsWindows2000WindowsWindows |
| x|y | x または y に一致します。たとえば、「z|food」は「z」または「food」と一致します。「(z|f)ood」は、「zood」または「food」に一致します。 |
| [xyz] | キャラ集合。含まれる文字のいずれかに一致します。たとえば、「[abc]」は「plain」の「a」に一致します。 |
| [^xyz] | 負の文字セット。含まれていない任意の文字に一致します。たとえば、'[^abc]' は、"plain" の 'p'、'l'、'i'、'n' に一致します。 |
| [az] | 文字の範囲。指定された範囲内の任意の文字に一致します。たとえば、'[az]' は、'a' から 'z' までの範囲の小文字の英字に一致します。 |
| [^az] | 負の文字範囲。指定された範囲外の任意の文字に一致します。たとえば、'[^az]' は、'a' から 'z' までの範囲にない任意の文字に一致します。 |
| \b | 単語境界、つまり単語とスペースの間の位置に一致します。たとえば、「er\b」は「never」の「er」には一致しますが、「動詞」の「er」には一致しません。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
(二)优先级
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,"或"操作 字符具有高于替换运算符的优先级,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。 |
三:表达式
(一)普通字符
当我们的正则表达式为一串普通字符(不包含元字符)时,校验字符串只有和正则一致时,才会校验通过。
举例:
import java.util.regex.Pattern;
public class Main {
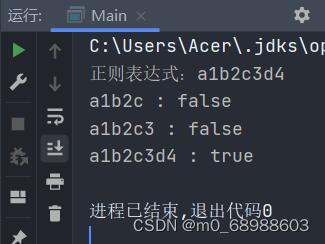
public static final String regex = "a1b2c3d4";
public static void main(String[] args) {
System.out.println("正则表达式:" + regex);
check("a1b2c");
check("a1b2c3");
check("a1b2c3d4");
}
static void check(String str) {
boolean result = Pattern.matches(regex, str);
System.out.println(str + " : " + result);
}
}结果:
(二)元字符
注:选择常用的一些举例,举例就不带代码了 ,原理跟普通字符几乎差不多。
注意:在Java定义的正则里,由于一个\表示的是字符串转义,因此在Java定义带有\的元字符时,还需要多写一个\,即\\

1. \d
\d表示一个数字
例1:aaa\d:表示验证的字符串后面必须以 aaa 开头,且以一个数字结尾。
例2:aaa\d\d:aaa后面跟2个数字。
例3:aaa\dbbb:aaa和bbb中间有一个数字。
2. \D
\D 表示一个非数字,它和上面 \d 的意思恰好相反。
例1:\D\D\D:则表示一个长度为3,不包含数字的字符串。
例2:111\D222:则表示111和222中间,必须包含一个非数字。
3. \w
\w 表示一个字母(大小写均可)、数字,或下划线。
例1:12\w45:则表示12和45中间必须是一个字母,数字,或下划线。如:12a45、12345、12_45
4. \W
\W 与 \w 相反,表示这个位置的字符既不是字母、数字,也不是下划线。
也就是:特殊符号(除下划线)、空格等满足。
例1:12\w45:则表示12和45中间是一个非字母,非数字,或非下划线。
5. \s
\s 表示匹配一个看不见的符号,即空格或制表符(Tab键)
例1:88\s99:则表示88和99中间必须是一个空格或制表符。
6. \S
\S 与 \s 相反,表示一个可以看得见的符号。
例1:88\S99:则表示88和99中间必须有一个看得见的符号,而不能是空格或制表符。
7. .
. (小数点) 则表示“\n”和"\r"之外的任何单个字符。
例1:.... :则表示任意四个字符 。
8. |
| (竖线) 则表示或的关系,表示检测的字符串须满足其中一个时,才符合条件。
例1:aa|bb|cc:则表示输入的字符串须是aa,或bb,或cc其中的一个。
例2:xx(aa|bb|cc)yy:则表示输入的字符串须是xx开头,yy结尾,且中间是aa,或bb,或cc其中的一个。(注意,如果我们的 "|" 的前后还有其它字符时,需要用()将他们包裹起来。)
9. [abc]
[ ] 表示匹配其中任意一个字符。
例1:a[bcd]e:则表示a和e的中间必须是b,或c,或d其中的一个。(注意:用 | 表示其中之一,它可以是字符,也可以是字符串。而只用中括号时,则只表示其中一个字符。)
10. [^abc]
[^ ] 表示不与中括号里的任意字符匹配。
例1:a[^bcd]e:则表示a和e的中间除b,c,d这三个字符外,其他的字符都满足。
11. [a-z]
[值1-值2] 则表示值1到值2中间的所有字符都满足(包括值1和值2)。常用该正则来表示大小写字母范围、数字范围。
例1:a[b-d]e:等同于 a[bcd]e,因为 b-d 其实就是b,c,d三个数。
例2:a[0-9]e:则表示a和e中间是一个数字,等同于 a\de(前面说过\d表示一个数字)。
12. [^a-z]
[^值1-值2] 则表示除值1和值2之外的所有字符,都可以满足。
例1:a[^1-3]e:则表示a和e中间的字符,只要不是1,2,3,则都满足。
13. \num
这里的num指number,也就是数字,当 \ 后面跟数字,表示匹配第几个括号中的结果。
例1:现在有 abcd 字符串,当我们用小括号把 c 包裹起来后,然后在字符串后面写上 \1,即 ab(c)d\1,则这里的 \1 就指 c,因为 \1 表示第1个小括号中的结果。
ab(c)d\1:等同于 abcdc 。
例2:如果我们继续把 ab(c)d\1 中的 d 包括起来,并在后面写上 \2,即 ab(c)(d)\1\2, 那么这里的 \2 就表示 d 这个字符,因为第2个小括号的结果是 d,所以整个表达式就等同于 abcdcd 。
ab(c)(d)\1\2:等同于 abcdcd,也等同于 ab(cd)\1 。
14. ?
? 表示匹配前面的子表达式零次或一次。
例1:abc?de: 表示可匹配的字符串为 abde (匹配0次c) 或 abcde (匹配1次c)。
15. +
匹配前面的子表达式一次或多次 (次数 >= 1,即至少1次)
例1:abc+de:ab 和 de 之前至少有一个 c 。
16. {n}
这里的 n 是一个非负整数。匹配确定的前面的子表达式 n 次。
例1: abc{3}de:表示 ab 和 de 之间有3个c。
例2:ab(xx|yy){3}de:表示 ab 和 de 之间有 xx 或 yy 的个数, 一起共计为3个。结果为abxxxxxxde、abyyyyyyde、abxxyyxxde、abyyxxyyde...
17. {n, m}
m和n均为非负整数,其中 n<=m。最少匹配 n 次且最多匹配 m 次。
例1:abc{2,3}de:表示 ab 和 de 之间有 2 到 3 个 c。 结果为abccde、abcccde
18. *
表示匹配前面的子表达式任意次。
例1:abc*de:表示 ab 和 de 之间有任意个数(包括0)的c 。
四:常用的正则表达式
(一)校验数字的表达式
- 数字:^[0-9]*$
- n位的数字:^\d{n}$
- 至少n位的数字:^\d{n,}$
- m-n位的数字:^\d{m,n}$
- 零和非零开头的数字:^(0|[1-9][0-9]*)$
- 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
- 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
- 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
- 有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
- 有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
- 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
- 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
- 非负整数:^\d+$ 或 ^[1-9]\d*|0$
- 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
- 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
- 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
- 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
- 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
- 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
(二)校验字符的表达式
- 汉字:^[\u4e00-\u9fa5]{0,}$
- 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
- 长度为3-20的所有字符:^.{3,20}$
- 由26个英文字母组成的字符串:^[A-Za-z]+$
- 由26个大写英文字母组成的字符串:^[A-Z]+$
- 由26个小写英文字母组成的字符串:^[a-z]+$
- 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
- 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
- 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
- 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
- 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
- 禁止输入含有~的字符:[^~]+
(三)特殊需求表达式
- Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
- 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
- InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
- 手机号码:^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$
- 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
- 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
- 电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
- 身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
- 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
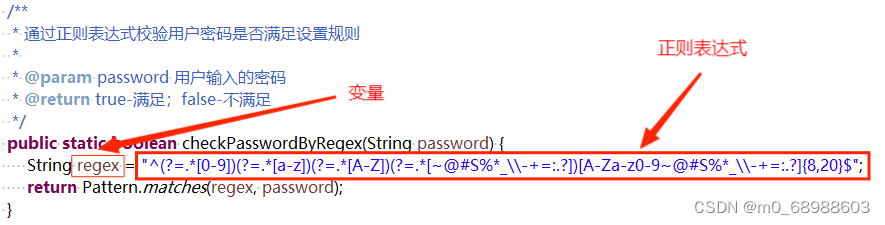
- 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
- 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
- 强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
- 日期格式:^\d{4}-\d{1,2}-\d{1,2}
- 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
- 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
- 钱的输入格式:
- 有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
- 这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
- 一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
- 这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
- 必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
- 这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
- 这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
- 1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
- 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
- xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
- 中文字符的正则表达式:[\u4e00-\u9fa5]
- 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
- 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
- HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
- 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
- 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
- IPv4地址:((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}