まず、エスケープ文字
あなたは、バックスラッシュ\エスケープ文字と文字、pythonで特殊文字を使用する必要がある場合に正規表現は、文字列に基づいています。
次の表には:
转义字符 描述
\(在行尾时) 续行符
\\ 反斜杠符号
\' 单引号
\" 双引号
\a 响铃
\b 退格(Backspace)
\e 转义
\000 空
\n 换行
\v 纵向制表符
\t 横向制表符
\r 回车
\f 换页
\oyy 八进制数yy代表的字符,例如:\o12代表换行
\xyy 十进制数yy代表的字符,例如:\x0a代表换行
\other 其它的字符以普通格式输出,例如:\w就是\w,\.就是\.
元の文字列
時々、私たちが有効に文字をエスケープしたくない、我々は、使用RおよびRは、元の文字列を定義し、元の文字列の意味を示したいと思います。以下のような:
print(r'\t\r')
实际输出为“\t\r”。
第二に、正規表現を理解します
正規表現は、文字を表現するために使用され、この「ルール列」、文字列操作の論理式であり、特定の事前定義された文字の組み合わせ、及びこれらの特定の文字を使用し、「文字列ルール」を形成することです文字列フィルタ・ロジックのため。
正規表現は、文字列の非常に強力なツール、他のプログラミング言語で正規表現の同じ概念を一致させるために使用されている、Pythonは例外、正規表現を使用し、我々は復帰したいというページコンテンツから抽出したいんコンテンツに簡単にできるように。
正規表現は大体マッチング処理されています。
式とテキスト文字比較を消す1.、
2.各文字を一致させることができるならば、マッチは成功し、一致しない場合、一致の文字が失敗します。
3.表現数量詞や境界がある場合は、このプロセスは、いくつかは少し異なるがあります。
一致する正規表現を使用して次の図に示すプロセス:
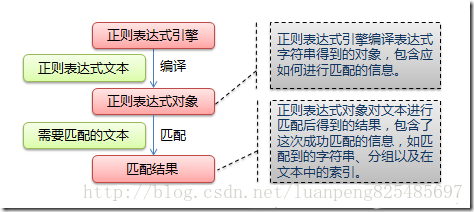
第三に、正規表現の構文規則
次の図に示すPythonの正規表現の構文とメタ文字をサポートしています。
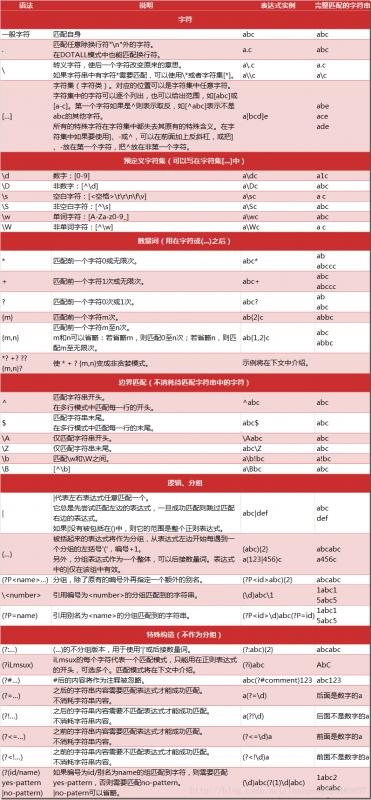
正規表現のコメントに関連する第四に、
1、数量詞と非貪欲貪欲
正規表現は、通常のテキスト文字列に一致するものを見つけるために使用されています。デフォルトの数量詞でPythonは(少数民族の言語でもデフォルトで非欲張りかもしれない)、常に多くの文字と一致させようと貪欲であり、非貪欲、対照的に、常に数文字と一致してみてください。たとえば、次の正規表現「AB 」「ABBBC」を見つけるために使用される場合、「ABBB」でしょう。非貪欲数量詞「ABを使用した場合は?」、あなたは「」でしょう。
注:私たちは、一般的に抽出物に非貪欲モードを使用します。
2、スラッシュ問題
問題は、バックスラッシュ引き起こす可能性がエスケープ文字として「\」を使用して、ほとんどのプログラミング言語、正規表現と同じ。最初の2つと最後の2つはに脱出するために使用されるプログラミング言語である:あなたがテキストの文字を「\」と一致する必要がある場合は、4つのバックスラッシュを「\」が必要となる正規表現のプログラミング言語表現を使いますバックスラッシュ、バックスラッシュ、その後、正規表現でバックスラッシュのようにエスケープ2に変換します。
Pythonは元の文字列で、この問題に対する良い解決策は、このケースでは、あなたは、正規表現は「\」の表現rを使用することができます。同様に、マッチの数「\ d」は、R「\ D」のように書くことができます。ネイティブの文字列で、ママは、心配はバックスラッシュ、書かれた表現でより直感的なルを逃していませんしません。
ここでは、文字列の正規エスケープエスケープとの違いに注意しなければなりません。正規表現が文字列であるため、彼は、システムによって認識された文字列に第1のフォーマットで書かれた(エスケープ文字列で)コードであり、システムは使用して(通常のオブジェクトにシステム識別文字列を識別する)定期的に逃れます。
エスケープ文字列は、正則化を識別することができ、かつ、通常のエスケープ文字列では、必ずしも特定されていません。
例えば:. \ N
文字列のみで識別さ\ nは、識別することはできません。
どちらも、正規中で識別することができ、そして\ n個を認識することができます
サンプルコード
import re
text = '.525heart.com\n' #在系统中表示为 .525heart.com换行
patternstr = '\.525heart.com\n'
# 代码里的书写为 \.525heart.com\n
# 系统识别为 \.525heart.com换行 字符串转义能识别\n,但是无法识别\.就原样保存
# 正则识别为 .525heart任意字符com换行 正则转义能识别\.和.
patternstr = r'\.525heart.com\n'
# 代码里的书写为 \.525heart.com\n
# 系统识别的字符串为 \.525heart.com\n 原样保存
# 正则识别为 .525heart任意字符com换行 正则转义能识别\.和.和\n
print(patternstr)
pattern = re.compile(patternstr)
result = re.search(pattern,text)
print(result.group())
出力は、
\.525heart.com\n
.525heart.com
五、Pythonの再モジュール
Pythonは、正規表現のサポートを提供reモジュールが付属しています。
使用される主な方法は以下のとおりであります
#返回pattern对象
re.compile(string[,flag])
#以下为匹配所用函数
re.match(pattern, string[, flags])
re.search(pattern, string[, flags])
re.split(pattern, string[, maxsplit])
re.findall(pattern, string[, flags])
re.finditer(pattern, string[, flags])
re.sub(pattern, repl, string[, count])
re.subn(pattern, repl, string[, count])
これらのメソッドを導入する前に、我々は最初のパターンの概念を導入し、パターンマッチングは、パターンとして理解することができ、その後、どのように我々は、一致するパターンを得るのですか?簡単に言えば、我々は使用することができre.compileメソッドを使用する必要があります。
例えば
pattern = re.compile(r'hello')
私たちは、コンパイラはコンパイル方法でパターンオブジェクトを生成して、我々はさらに試合にこのオブジェクトを使用するパラメータの文字列ネイティブオブジェクトを渡します。
また、あなたはパラメータの意味を説明するために、ここで、別のパラメータフラグを気づいているかもしれません。
パラメータフラグパターンマッチング
「|」を有効にするために同じ時間を表し、そのようre.Iなど| re.M.値が使用ビット単位のOR演算子をすることができ
可能な値は以下のとおりです。
- re.I(綴り:IGNORECASE):(括弧内に、以下同じフル言葉遣いである)場合を無視
- re.M(スペル:MULTILINE):マルチラインモード、「^」と「$」動作を変更する(上記参照)
- re.S(綴り:DOTALL):「」を含む\ Nを含むすべての文字にマッチする任意の点のパターンマッチング
- re.L(綴り:LOCALE):所定の文字クラス\ W \ W \ B \ B \ S \ S領域の設定は電流に依存すること
- re.U(綴り:UNICODE):その所定の文字クラス\ W \ W \ B \ B \ S \ S \ D \ Dは、文字に依存する定義された属性のUnicode
- re.X(スペル:VERBOSE):詳細モード。このモードでは、正規表現は、複数行になる文字やコメントを追加できる空白を無視することができます。
flagsパラメータは、コンパイルに正規表現文字列をコンパイルするために使用することができます。以下のような:
pattern = re.compile('.*525heart.*',re.S)マッチクエリ機能上に配置することができ、正規表現文字列をコンパイルするために使用され、例えば:
result = re.search('.*525heart.*',text,re.S)しかし、彼は唯一の定期的なターゲットを生成するために正規表現文字列コンパイルするために使用することができますが、通常のオブジェクトを処理することはできません。以下は間違っているような。
pattern = re.compile('.*525heart.*')
result = re.search(pattern,text,re.S)第六に、通常の方法
ちょうど私たちはこのパターンを使用する必要があるなどre.matchなど、いくつかの他の方法を言及し、ここで私たちは一つ一つを紹介しています。
注:生成されたパターンは、次に、以下の方法が、この値を渡す必要がないフラグを、指摘している場合にフラグの以下の7つの方法は、また、パターンマッチングの意味を表します。
1、re.match(パターン、文字列[、フラグ])
この方法は、(私たちは、文字列にマッチしたい)は、文字列の先頭から開始し、パターンに一致するようにしようと、一致が文字列の末尾が最後に到達しているされていない場合、彼らは文字にマッチすることができない場合は、すぐにNoneを返し、一致したバックあったが、またしていますそれはNoneを返します。2つの結果がマッチが失敗、または終了をマッチングしながら、パターンマッチングの成功、もはや文字列のバック一致しないことが示されています。
理解するための例で見てみましょう
# 导入re模块
import re
# 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串”
pattern = re.compile(r'hello')
# 使用re.match匹配文本,获得匹配结果,无法匹配时将返回None
result1 = re.match(pattern, 'hello')
result2 = re.match(pattern, 'helloo world!')
result3 = re.match(pattern, 'helo world!')
result4 = re.match(pattern, 'hello world!')
# 如果1匹配成功
if result1:
# 使用Match获得分组信息
print(result1.group())
else:
print('1匹配失败!')
# 如果2匹配成功
if result2:
# 使用Match获得分组信息
print(result2.group())
else:
print('2匹配失败!')
# 如果3匹配成功
if result3:
# 使用Match获得分组信息
print(result3.group())
else:
print('3匹配失败!')
# 如果4匹配成功
if result4:
# 使用Match获得分组信息
print(result4.group())
else:
print('4匹配失败!')
業績
hello
hello
3匹配失败!
helloマッチング分析:
- 最初の試合は、パターンの正規表現は、「こんにちは」、我々はまた、対象の文字列の文字列に一致する最初から最後までこんにちは、完全一致、マッチング成功です。
- 末端二一致する文字列がhelloo世界で、パターンマッチングが正確な文字列の先頭と一致し始め、エンドパターンも一致し、世界O後者もはや一致は、成功メッセージを戻します。
- 第三マッチング、文字列は、文字列のパターンマッチングからやり直す、HELO世界で、一致が完了していない発見された「O」、整合終端、リターンなし
- でもスペースの顔に二一致の原則第4試合は、影響を受けません。
我々はまた、これはそれがどういう意味で、)(result.groupから最後の印刷を参照してください?
Matchオブジェクトのプロパティとメソッドについてましょう話。
re.match機能はMatchオブジェクトを返します。Matchオブジェクト試合の結果であり、このマッチングに関する情報の多くは、この情報を取得するために読み込み可能なマッチのプロパティやメソッドを提供するために使用することができます含まれています。
属性:
- 文字列:試合で使用されるテキスト。
- 再:オブジェクトのパターンマッチングの使用。
- POS:検索のテキスト、正規表現ベースのインデックス。同じ名前と同じパラメータ値Pattern.match()とPattern.seach()メソッド。
- もしendpos:テキストインデックスは、正規表現検索を終了します。同じ名前と同じパラメータ値Pattern.match()とPattern.seach()メソッド。
- lastIndexの:最後のパケットのインデックスは、テキストでキャプチャされます。何のパケットがキャプチャされていない場合はNoneになります。
- lastgroup:エイリアスが捕獲される最後のパケット。パケットが別名でない場合、またはパケットがキャッチされていない場合は、Noneになります。
方法:
- グループ([GROUP1、...]):
1つ以上のパケットを得ることは、文字列を傍受し、タプルは、指定された複数のパラメータの形で返されます。番号0が一致するサブストリングを表す;パラメータが満たされていない、グループリターン(0); GROUP1は、エイリアスIDを使用してもよい使用できる文字列インターセプトなしグループを返さない、いくつかのグループが最後のサブ戻りインターセプトインターセプト文字列。
- グループ([デフォルト]):
戻り値は、すべてのインターセプトされたパケットは、タプルの文字列を形成します。グループ(1,2、...最後に)呼び出すのと同じ。デフォルトでは、デフォルトはNoneです、この値を交換するには、noインターセプト文字列セットを示していません。
- groupdict([デフォルト]):
戻るエイリアスエイリアスグループは、グループへの結合が、値の辞書をサブストリング傍受している、何の別名グループが含まれていないされていません。上記のように意味デフォルト。
- 開始([グループ])。
戻り値は、指定されたサブセットは、文字列内の文字列(文字インデックスの最初の部分文字列)のインデックスを開始傍受しました。デフォルト値は0グループです。
- 末端([グループ])。
リターンのサブグループは、(インデックス+1最後の文字をサブストリング)文字列内の指定された終了インデックスの文字列を傍受しました。デフォルト値は0グループです。
- スパン([グループ])。
リターン(スタート(グループ)、終了(グループ))。
- (テンプレート)を展開します。
マッチングパケットは、テンプレートに代入してから戻ります。テンプレートは、\ IDまたは\ G、\ G基準パケットではなく、番号0に使用することができます。\イドと\ gは同等である。しかし、\ 10は\だけG0を使用し、あなたは\ 1を表現したい場合は、文字「0」が続いている、最初の10個のパケットとみなされます。
のは、このことを理解するために例を使用してみましょう:
#一个简单的match实例
import re
# 匹配如下内容:单词+空格+单词+任意字符
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')
print("m.string:", m.string)
print("m.re:", m.re)
print("m.pos:", m.pos)
print("m.endpos:", m.endpos)
print("m.lastindex:", m.lastindex)
print("m.lastgroup:", m.lastgroup)
print("m.group():", m.group())
print("m.group(1,2):", m.group(1, 2))
print("m.groups():", m.groups())
print("m.groupdict():", m.groupdict())
print("m.start(2):", m.start(2))
print("m.end(2):", m.end(2))
print("m.span(2):", m.span(2))
print(r"m.expand(r'\g \g\g'):", m.expand(r'\2 \1\3'))
出力は、
m.string: hello world!
m.re: re.compile('(\\w+) (\\w+)(?P<sign>.*)')
m.pos: 0
m.endpos: 12
m.lastindex: 3
m.lastgroup: sign
m.group(): hello world!
m.group(1,2): ('hello', 'world')
m.groups(): ('hello', 'world', '!')
m.groupdict(): {'sign': '!'}
m.start(2): 6
m.end(2): 11
m.span(2): (6, 11)
m.expand(r'\g \g\g'): world hello!2、re.search(パターン、文字列[、フラグ])
のみ、返却する必要があり、その後、0の位置に成功と一致する)だけで検索、再は、文字列の先頭にマッチしていない検出に一致()関数を除き、法と一致する方法は非常に似て検索()試合、試合を(見つけるために、文字列全体をスキャンします開始位置が成功一致しない場合は、(一致)Noneを返します。
同様に、同一の戻りオブジェクトの一致()は、オブジェクトのメソッドと、検索方法のプロパティを返します。
私たちは感じることの例を使用します
# 导入re模块
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'world')
# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match = re.search(pattern, 'hello world!')
if match:
# 使用Match获得分组信息
print(match.group())
出力は、
world
3、re.split(パターン、文字列[、maxsplit個])
応じて一致させることができるサブ文字列は、文字列分割のリストを返します。maxsplit個は全体の部門を指定しないでください、部門の最大数を指定します。
私たちは、次の例を感じます。
import re
pattern = re.compile(r'\d+')
print(re.split(pattern, 'one1two2three3four4'))
出力は、
['one', 'two', 'three', 'four', '']4、re.findall(パターン、文字列[、フラグ])
リスト形式で返しますすべての一致をサブストリング、文字列を検索します。
私たちは、この例のように感じます
import re
pattern = re.compile(r'\d+')
print(re.findall(pattern, 'one1two2three3four4'))出力
['1', '2', '3', '4']5、re.finditer(パターン、文字列[、フラグ])
検索文字列は、各照合結果(一致オブジェクト)イテレータのシーケンシャルアクセスを返します。
私たちは、次の例を感じます
import re
pattern = re.compile(r'\d+')
for m in re.finditer(pattern, 'one1two2three3four4'):
print(m.group(),end=' ')出力は、
1 2 3 4 6、re.sub(パターン、REPL、文字列[カウント])
代替的に置換文字列の後に返される各サブ文字列と一致する文字列を使用して、REPL。
場合REPLは\ IDまたは\ G、\ G基準パケットではなく、番号0を使用することができる文字列です。
REPLがメソッドである場合は、この方法は、唯一のパラメータ(Matchオブジェクト)を受け入れなければならない、と(もはや参照された文字列は、パケットを返される)の交換のための文字列を返します。
カウントが指定されていないすべての時間を交換、交換の最大数を指定するために使用されます。
import re
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print(re.sub(pattern, r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(re.sub(pattern, func, s))出力は、
say i, world hello!
I Say, Hello World!7、re.subn(パターン、REPL、文字列[カウント])
リターン(サブ(REPL、文字列[カウント])、置換の数)。
import re
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print(re.subn(pattern, r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(re.subn(pattern, func, s))
出力は、
('say i, world hello!', 2)
('I Say, Hello World!', 2)
別の用途8.Python reモジュール
上記では、我々はそのような試合、検索など7つのユーティリティメソッドを導入し、そうではなく、呼び出しがre.match、re.search方法です方法は、実際には、呼び出しに別の方法があり、あなたは、pattern.searchをpattern.matchすることができます呼び出し、その最初の引数としてのパターン、それを呼び出すことはありません、私がすることができるかを呼び出すしたいと思います。
API機能一覧
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit])
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags])
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count])
オリジナルリンク:https://blog.csdn.net/luanpeng825485697/article/details/78386400
本研究の目的のために温家宝ソースネットワーク、侵害の接触は削除した場合。
