作者简介 毛剑 B站 平台架构师&EP负责人
議題
私は2015年頃にステーションBに参加しました。以前は、ステーションB全体のバックエンドを担当していました。2018年頃、私は建築家に異動してEPチームを監督しました。実は、これまでEPの仕事はしていませんでしたが、チームに異動したとき、実際にこういう練習をしていました。また、迅速に配信する方法、コードの品質を監視する方法、テストする方法などについてもいくつかのアイデアがあります。
私の共有は3つの部分に分けられます。まず、大きな倉庫とは何かです。
これは約1、2年前のことで、誰かがそれを共有していると聞きました。それは、彼らがすべてのコードを倉庫に配置する方法についてでした。後で、いくつかの論文を含むいくつかの記事も見ました。なぜグーグルが倉庫に何十億ものコードを次々と入れているのかという非常に古典的な記事がありました。シリコンバレーで始まったいくつかの外国企業がこれを行っていることを発見しました。実際の戦闘では、いくつかの問題点について考えていたので、この方向に進みました。
2番目の部分は、ツールチェーンにいくつかの構造を実装することです。
3つ目は、大規模な倉庫を組み合わせてCI / CDを実行する方法です。

1. Mono-Repo
最初に背景を紹介します。2015年に参加したとき、私たちはDream Weaving(sound)という会社に基づいていたので、このプロジェクトをより適切に反復するように一部の開発者を誘導するなど、変革を行う必要がありました。当時はステーションBのKFCファミリーでした。バケット、すべてのコードは内部にあります。
その後、マイクロサービスの進化を行ったとき、基本的なライブラリが常に最適化されているか、ビジネスの開発やニーズに重ね合わされていることがわかりました。正直なところ、私たちが基本的なライブラリを構築し始めたとき、または私たちの抽象化があまり合理的でなかったとき、またはそれがいくつかの原則を破ったときなど。実際、基本ライブラリは頻繁に更新されます。
非常に感銘を受けました。以前は、基本ライブラリのすべてのサブリポジトリのコードアドバンスを含め、技術ライブラリをプッシュするために管理に依存していましたが、実際には管理に基づいていました。たとえば、私がグループに所属している場合、すべての基本ライブラリを何月何日にアップグレードする必要があります。この変更は破壊的である可能性があり、ビジネスコードも破壊される可能性があります。これは実際には比較的悪い経験です。 。私を含めて、毎日グループの轟音に頼っているので、これは非常に非効率的です。
当時、私は約50〜60人を担当していましたが、実際には、各同僚のコードに注意を払っていました。スローガンはありますが、プロセスは統一されておらず、基本的には各チームリーダーがチームをリクエストするかどうかに依存しますが、全体が十分に自動化されていません。
3つ目のポイントは、モバイル端末に小さなバグがたくさんあることです。私たちの大量のテスト作業はリリース前に滞っているので、実際には誰もが最初は大きな動きを抑えており、最終リリースがリリースされようとすると、電車に乗る前に誰もがテストを要求します。これもひどい。継続的なものがないため、テスト作業を進めることができず、配信速度が遅くなります。
最後の質問は、バージョン管理が非常に複雑であり、バックエンドが比較的優れていることです。これは、基本ライブラリが比較的統合された後、このバージョンのバージョン番号が1.0であり、他の基本ライブラリのバージョン2.0が非常に複雑であるためです。私がそれを見たとき、巨大な絵、さまざまなバージョン番号、およびコンポーネントは一貫性がなく、非常に混乱していました。

コメントコンポーネントであるステーションBのコメントモジュールがあります。おそらく、プラットフォームがこの要件を実行しているときにそれをそれほど包括的に考慮していなかったためです。ビジネスを使用したときに、機能が完了していないことがわかりました。コードを変更できますか? ?変更、この状況は非常に一般的です。これらのコードはさまざまな倉庫に散在しているため、コードをコピーする場合が多くあります。
そのため、Androidチャンネルに配信する場合、パッケージは1つしかないため、すべてのコードを1つのパッケージにまとめる必要があり、その量は非常に多くなります。これらは私たちが2、3年の間に遭遇した問題です。そこで、後でモノリポジトリを導入しました。このリポジトリでは、単一の製品ウェアハウスに複数の基本的なライブラリやアプリケーションなどが含まれています。プラットフォームと呼ばれるライブラリですべてのコードをホストしており、Kratosという名前を付けています。

2.モノリポジトリツールチェーン
モノリポジトリの利点
なぜ大規模な倉庫に移行するのか、その利点は何ですか?それらについて一つずつ話しましょう。
まず第一に、最初に気分が良くなるのは、一貫したバージョンです。以前は、基本ライブラリが1.0または2.0である可能性があり、非常に煩わしいものでした。別のビジネスがリリースされるたびに、別のバージョン番号に依存する必要があり、これはより面倒です。Okuraを使用した後、最初のエクスペリエンスは一貫性のあるバージョンです。基本ライブラリのアップグレード、バージョンは透過的で表示され、バージョンは一貫性があります。
間接的に、私たちのコードは常に高度なままです。なんでそんなこと言うの?たとえば、私の基本的なライブラリは1.0から2.0まで繰り返されます。悲鳴を上げるために管理手段だけに頼ることができる場合、私の棚パッケージは2.0です、あなたはそれを申請することができます。実際、ビジネス面では、彼にはやる気がありません。一般に、いわゆる変更管理のアイデアがあります。変更はしませんが、互換性を確保する必要があります。
2つ目は、究極のコードの再利用です。コードは何度もコピーされるため、非常に混乱します。ウェアハウスが完成したので、チームが別のチームのコードに依存したい場合、それは実際にはディレクトリ間の依存関係です。特定のjarパッケージをゼロに使用するようなことはありません。これはさらに厄介です。
倉庫がたくさんあると、新参者にとっては大都会のようで、入ってみるとどこにいるのかわからない。
現在、新入生が入社後、倉庫を開く許可があれば、すべてを閲覧することができますが、実はとても簡単です。私たちの同僚の中には、基本的な機能を開発したいときに、大規模な倉庫で既存の機能を探す傾向がある人もいます。
3番目のポイントは単純な依存関係管理ですが、それについてどのように話しますか?システムを構築し、ディレクトリ間でコードを簡単にハングアップできます。依存関係全体は非常に単純です。サードパーティのオープンソースライブラリも参照する可能性があるため、ここでは特別なことがあります。現在、go 1.1などの機能も試しています。現在、バージョン番号を使用してサードパーティのライブラリをダウンロードし、に送信しています。大きな倉庫。
もう1つの利点は、単純な依存関係管理です。以前、モバイルで同僚に会ったことがあります。たとえば、ライブラリAはBとCに依存し、次にBとCはDに依存します。Dに依存するライブラリには2つのバージョンがある可能性があることがわかりました。これらの2つのバージョンは、サーバーを含めて互換性がない可能性があります。たとえば、Kafkaが一度アップグレードされたとき、彼のコードはいくつかの破壊的な変更を加えました。この時点でアップグレードしたい場合、実際には宣伝が難しくなります。これと同様に、古いものを使用する人もいれば、新しいものを使用する人もいます。
もちろん、私たち自身のビルドライブラリにも同じことが言えます。新しいライブラリを使用する人もいれば、古いライブラリを使用する人もいます。サードパーティのライブラリを導入します。実際、コンパイル時に対処する方法はありません。現時点では、いくつかの選択をする必要があります。私たちのモバイル端末は別々の倉庫で開発されており、各ビジネスラインは独自の倉庫で開発されています。最初に使用されたプラットフォームは公に組織されています。1.0の人もいれば1.1の人もいます。このときも簡単です。統合するときに間違いを犯します。
最終的に一般契約に統合されると、ライブラリの変更と再テストも発生しますが、これは利益に値しません。
他の言語では、またはたとえばgoを例として使用すると、静的リンクがより尊重されるのはなぜですか?あなたはバイナリを提供することと同等であるため、実際、このアイデアは大きな倉庫のアイデアと一致していると思います。つまり、私はすべてを自己完結型であり、非常に簡単に提供できます。したがって、彼は単に管理に頼ることができます。


アトミックコードが変更された別のファイルを見てみましょう。開発者は、アトミック操作で、一貫した操作でコードベース内の数百または数千ものファイルに大きな変更を加えることができます。
たとえば、パッケージの名前は特に良くありません。別の倉庫にいて、パッケージ名を変更したい場合は、この変更が行われる理由、影響は何か、誰がそれを破棄するかを変更します。彼を修理する必要がある人は誰でも、私たちはこの種の考え方を使用して、技術部門の反復とアップグレードに協力するようにすべての人を導きます。
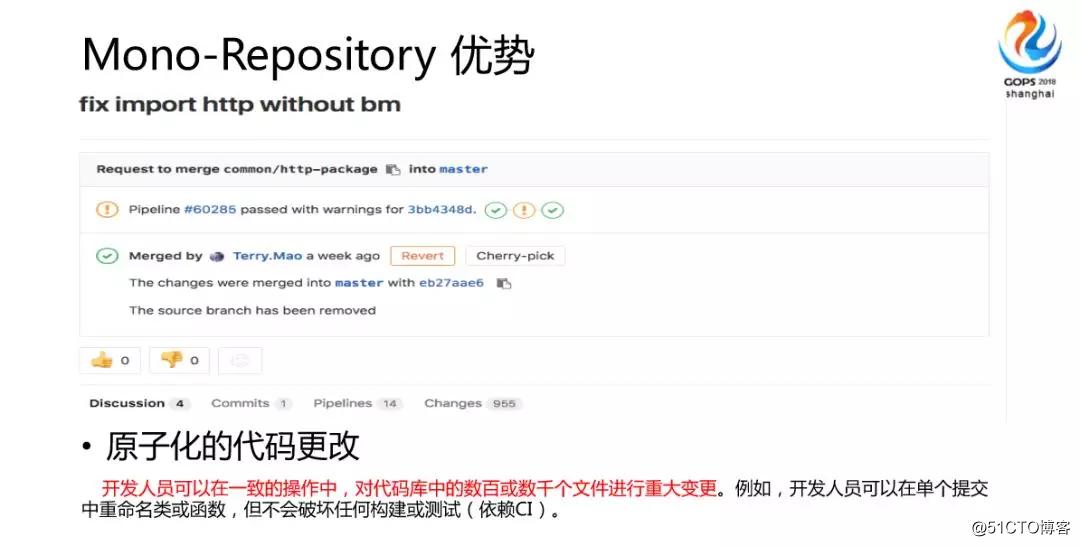
大規模なコードベースのリファクタリングと更新のサポートも改善されています。単一のコードベースですべての依存関係をキャプチャでき、APIを大胆に削除できます。ディレクトリを移行するときに、計画を立てました。
1つは、大きなウェアハウスのワンクリックパッケージを呼び出すことで、パッケージ名のパスが変更され、2つ目は、古いコードを1か月間保持することです。ブランチ開発をしている人もいれば、古いトランクが非常に長い人もいるので、古いトランクを1か月長く保ちます。
1か月後、古いコードに期限切れのマークを付け、期限切れで組み込むことができないことを通知します。このようにして、基本ライブラリの反復と更新を完了することができます。
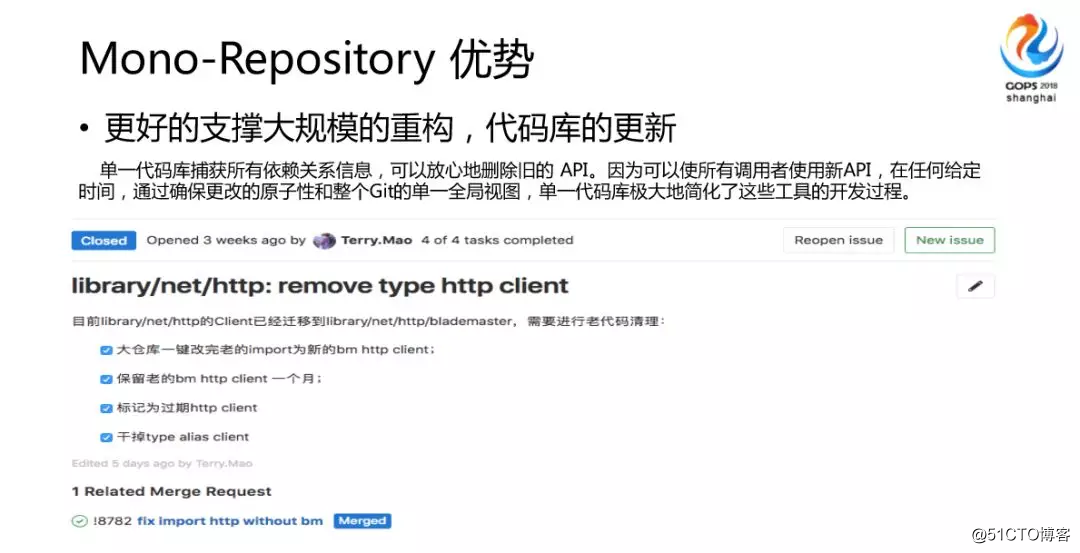
柔軟なチーム境界とコード所有権。まず、コードベースには通常、会社の名前または部門の名前があります。実際、他の人のAPIを使用するのは非常に簡単です。彼のディレクトリを見つければ、次のことができます。彼のすべてのAPIを参照してください。私は彼のAPIを簡単に使用できます。
一部の事業を含め、組織構造が調整されているため、チームは頻繁に変更されます。実際、ディレクトリの操作が行われている限り、ある部門から別の部門に移動できます。
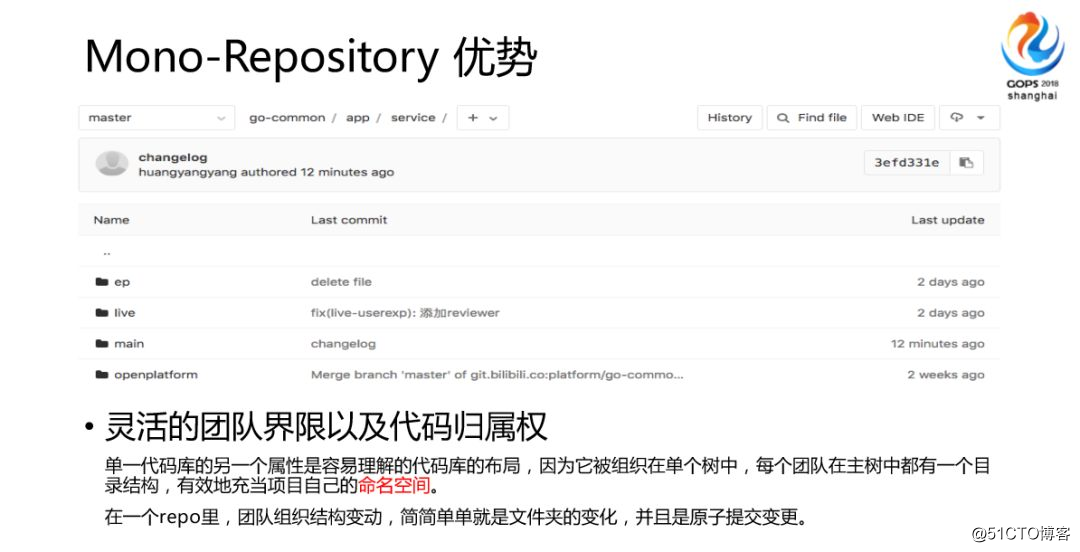
コードベースの構造により、チーム間の協力を強化するために、開発者はコードベースの境界を決定する必要がありました。たとえば、私は開発共有グループであり、あなたは開発レビューグループです。今ではこのような共有開発は必要ありません。とても便利で、カタログを調整するだけで、それぞれの属性を変更できるので、非常に協力的です。
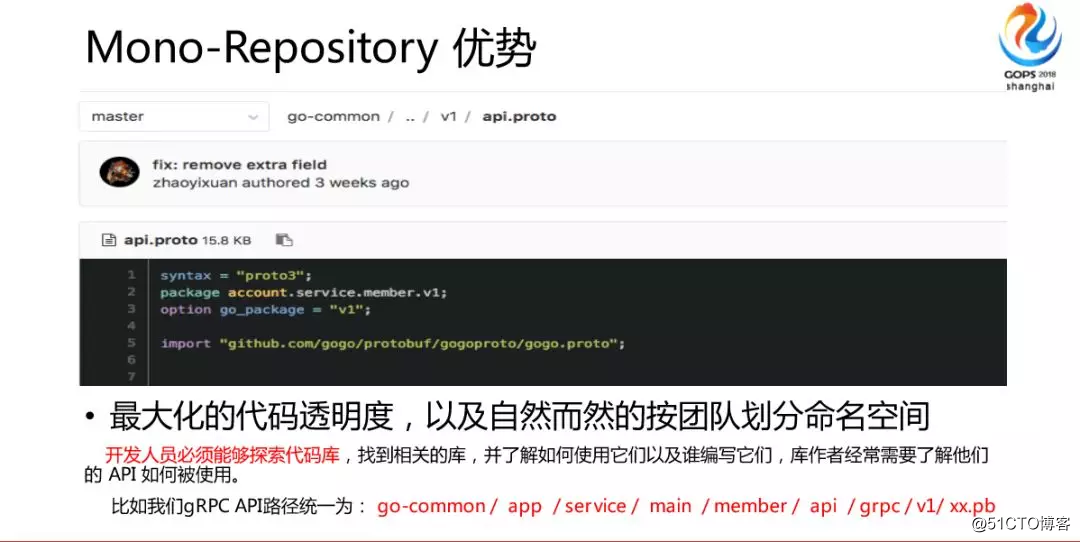
さらに、コードの透過性が最大化され、名前空間はチームによって自然に分割されます。これがAPIのパスまたは名前空間になります。たとえば、私たちは主に内部でGRPCを使用していますが、なぜAPIパスが統合されているのですか?たとえば、彼はアプリケーションに参加しており、メンバーシップサービスであり、APIはGRPCなどに対応しており、V1バージョンです。
実際、ドキュメントを使用することはめったにありません。ドッキング時に要求するインターフェイスを尋ねられたのを覚えています。それを検索して自分のドキュメントを見つけて配布したところ、このドキュメントの更新を忘れてしまう可能性があります。しばらくの間はい、このイベントは頻繁に発生し、最終的にはドキュメントを確実に更新するためのコードジェネレーターが存在する可能性があります。
この種の作業モードでは、開発者は頻繁に上下に切り替えることになります。これは、一種のドキュメントの検索と一種のコードの検索です。私たちは実際にドキュメント接続コードになりました。彼はまた、このインターフェイスの機能とその中にあるパラメータを非常に明確に伝えることができます。これらはすべて非常に明確に説明されています。VIPのステータスを取得したいなど、必要な情報に基づいて、コードリポジトリ全体でVIPファイルを検索すると、それを見つけることができる場合がありますが、必要はありません。どこでもテキストを検索します。
2.モノリポジトリツールチェーン
Mono-Repository 问题
大規模な倉庫を使用した後、いくつかの問題は解決されましたが、それはまたいくつかの問題をもたらしました。
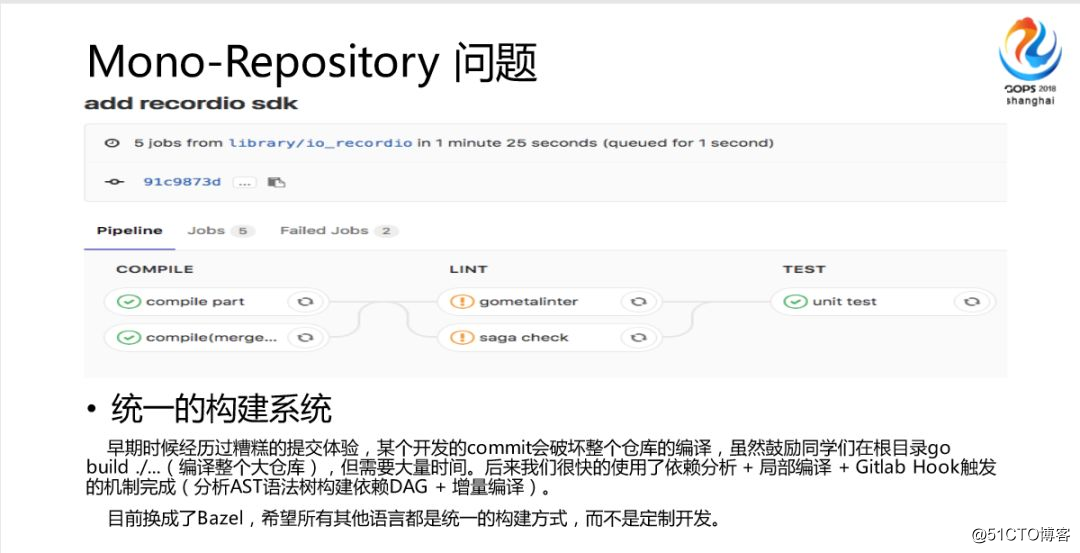
最初に非常に複雑なのは、システムを構築することです。当時、私はそのようなアイデアを紹介したかったので、初期の経験は非常に悪かったですが、私たちのチームには約50人がいます。全体的にコラボレーションするのは実はとても難しいのですが、なぜですか?特定の開発クラスメートがデフォルトでメイントランクに設定されることがよくありますが、コードを送信するかメイントランクにマージするときは、すべて編集する必要があることを伝えます。
時間がかかるため、コード全体が非常に大きく、非常に長い時間がかかる可能性があり、開発者はこれを行うことを躊躇します。後で、Gitlab CI / CDに統合できるかどうか疑問に思いました。後でいくつかの改善を行いました。最初は、Gitlab CI / CDを使用しませんでしたが、GitlabフックAPIをベースにして、イベントトリガーを実行しました。当時の私たちのコマンドはガモ値と呼ばれ、フックをトリガーしましたが、このフックは何をしますか?私たちはいくつかのことをしました。
まず、Gitlabパッケージを使用し、彼の依存関係の元のファイル全体を解析できるので、彼がどのパッケージを壊したかがわかります。これらの依存関係とこれらのデータを依存関係グラフに保存します。デフォルト値を追加する操作をトリガーするたびに、依存関係の数を確認します。次に、どの依存関係を再構築する必要があるかがわかったので、増分ミューテーションを作成しました。 、そして私たちは実際にそれを自分たちで実践しました。
その後、ビルドシステムを使ってFacebookを聴いたときなど、会社もどんどん増えていきましたが、実際にはグーグルの中にバゼルというものがあることに気づき、徐々に自社モデルからバゼルに切り替えていきます。
なぜ私はバゼルを宣伝するのですか?チームごとに言語があることがわかりました。言語ごとに同じことをすると、コストが高くなります。そのため、後でBazelが実際に言語と組み合わせることができることを発見しました。
各ディレクトリにbulidファイルがあると考えることができます。このbulidファイルは、私が依存しているディレクトリを記述します。このようにして、グローバルな依存関係を知ることができます。これには、すべての構築方法が統一され、すべての言語がサポートされているという別の利点があります。独自の言語エントリを実装するだけで済みます。
もう1つの利点は、彼の依存関係を分析した後、実際に増分突然変異を実行できることです。たとえば、Aライブラリを変更した場合、Aは実際にはBによってのみ使用されます。インクリメンタルミューテーションを使用する場合、Bをミューテーションするだけでよく、他のミューテーションは必要ありません。第二に、彼は複数の言語をサポートするツールを持っています。
三つ目は拡張できるということですが、なぜバゼルが出たのですか?グーグルも社内で大きな倉庫であるため、3点目です。第4に、独自に作成できるため、拡張できます。これにより、IOSでの現在のOkuraのプラクティスはかなりうまくいっています。
Okuraは、ディレクトリ構造と依存関係の仕様も優れています。これは非常に単純なようです。実際、私たちの実践では、私と私たちのチームは多くの間違いを犯しました。
これで、IOSウェアハウスを少しこのように見ることができます。複数のパッケージ、さまざまな基本ライブラリ、およびサードパーティに依存するライブラリが含まれている場合があります。
goウェアハウスでも同様になります。3つのライブラリがあります。1つはサードパーティライブラリ、基本ライブラリ、およびAPPです。バックエンドの場合、APPは管理バックエンド、マイクロサービス、ゲートウェイ、およびその他のモジュールのようなものです。
コードを書くとき、ライブラリとライブラリ間の依存関係がうまく処理されていない場合、ウェアハウスを変更するとウェアハウス全体が完全に変更されることがわかります。ミューテーションの中間結果は特に無効化されやすく、すべてがオーバーラップするたびに発生します。
私たちは長い間これを修復してきましたが、特定のライブラリがすべての人に使用されていること、頻繁に破壊される可能性があることなど、さまざまな歴史的理由から、問題があるかどうかを考慮する必要があります。単に環境に依存するCHANGELOGもあります。

Okuraには、超高コード品質要件というもう1つの問題があります。以前にいくつかの間違いを犯しました。つまり、ベースライブラリに小さな変更を加えたため、すべてが影響を受けました。
トランクにマージされたバグがあると仮定すると、リスクがあります。したがって、大規模な倉庫に入った後は、コード仕様を含め、より多くの理由があるか、クラスメートにさらに多くのセルフテストを作成するように要求します。この要件非常に厳しいです。
同時に、Bazelを使用してインクリメンタルUTを実行します。さらに、私たちがUT開発者の完全な数になっている場合は、インクリメンタルUTも作成しました。
さらに、以前の人間によるレビューであるこのツールは、業界で頻繁に使用される多くのツールを導入しただけでなく、多くのカスタマイズされた開発を行い、これらのライブラリをプロセスに組み込んで、必須の手段になりました。

UTと静的スキャンツールがたくさんあるとしても、間違いを避けることはできないと言ったばかりです。ですから、クラスメートはUTを書くのがとても好きですが、それでもまだいくつかのバグがあります。
後でグレースケールメカニズムを使用しました。まず、この変更をバックボーンにできるだけ早く組み込むことができることを望んでいますが、すぐに有効にしたくないので、フィーチャーフラグを渡しました。
たとえば、以下に機能ゲートがあり、paasプラットフォームと組み合わされ、この方法でアクティブ化されます。基本ライブラリのグレーレベルが3、4、または7日間比較的安定していることが判明すると、フラグは削除されます。

さらに、Bazelなど、多くのツールチェーンへの投資が必要です。彼を十分に知っており、Bazelのリモートキャッシュを管理しています。
さらに、コードホスティング、コードウェアハウスが非常に大きい場合、ストレージが必要ですか?または、大規模な倉庫の場合、IDEが必要ですか?これらは需要と供給の入力であり、時間と労力が必要です。さらに、テストインフラストラクチャは非常に複雑です。もう1つの重要なポイントはCodeReviewです。コミュニケーションを奨励します。
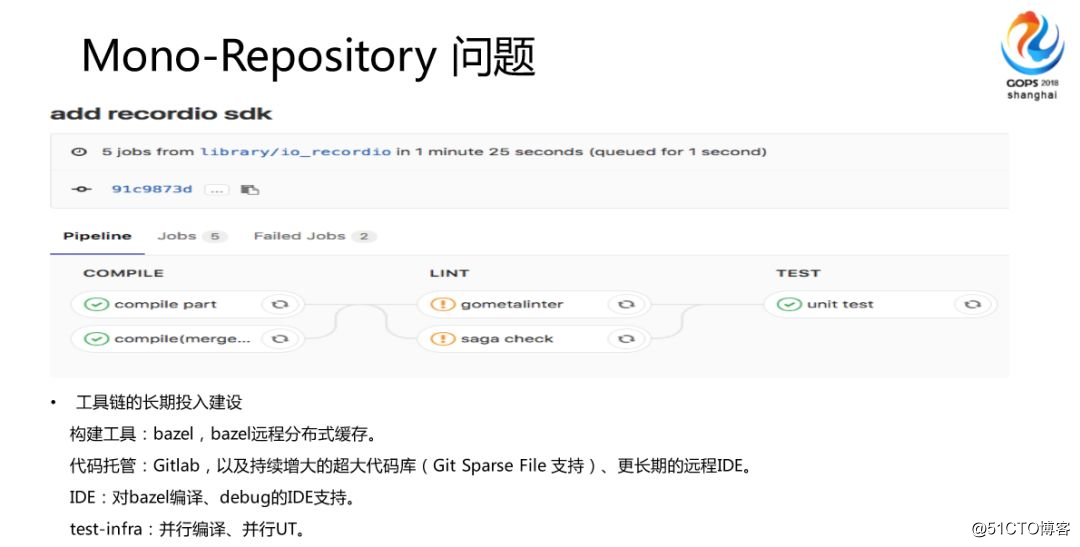
CodeReviewにはいくつかの利点があります。私は深い気持ちを持っています。1つはコードの品質を保証できること、もう1つは人員のバックアップです。チーム間のレビューをお勧めします。実際、ステーションBは部門内のグループ間のレビューでしたが、現在は部門間のレビューがあり、これは実際には非常に優れたスタッフのバックアップツールです。もちろん、誰にとっても、多くの人があなたのコードを読んだり、多くの人がそれを信用したり、誰でもそれを補うことができます。
さらに、それは知識の共有と教育のツールであることを意味します。なぜなら、私があなたのコードを見ているので、他の人のコードがうまく書かれていないという良性の不満だからです。いいえ、私は実際にプレッシャーにさらされています。
私は自分で上手に話したり書いたりすることができます。それから私はあなたのコードをもう一度見ます、なぜならあなたはいつも私にスプレーするので、私はあなたにスプレーします、それでこの種の好循環はこのコードをますます良くするでしょう。もう1つの非常に優れた方法は、知識の共有です。これは、さまざまな同僚に送信して共有できます。
以前と同じように、管理責任は非常に重く、私もコードを調べます。一部の新入生は特定の時点にいる可能性があるため、彼はあなたが予期していなかったいくつかのハイライトを書いた可能性があります。さらに、CodeReviewを通じて、コードを作成するだけでなく、その品質を複雑にする必要があるため、すべての人が自分のコードに責任を持つ必要があることを強調しました。
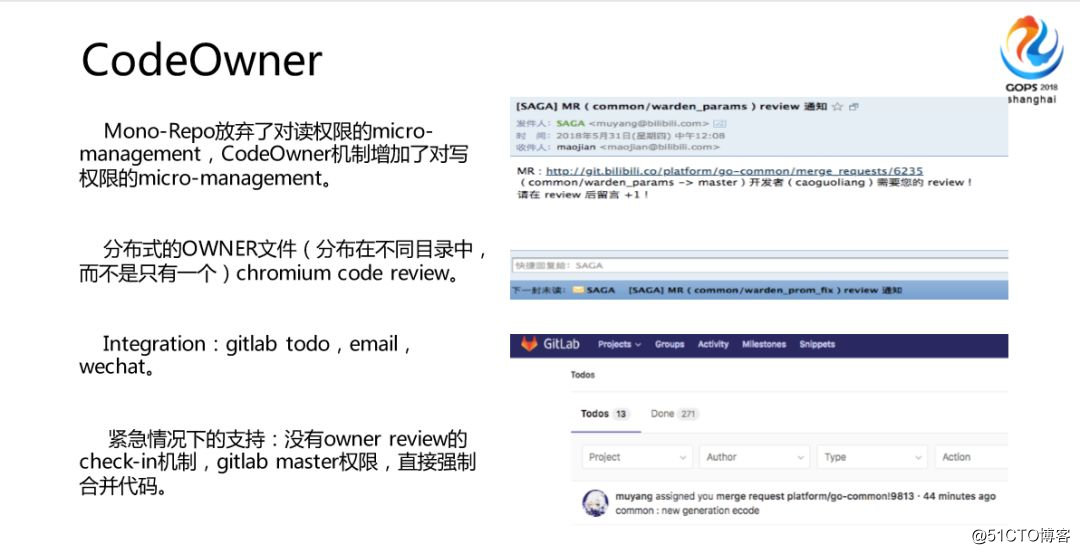
後でCodeOwnerについて話させてください。あなたはライフサイクル全体に責任があり、操作やメンテナンス、テストはありません。誰もがエンジニアです。まず、大倉は読み取り許可をあきらめました。大倉は基本的に誰もが入力するコードを見ることができるので、基本的に読み取り許可をあきらめましたが、書き込み許可をある程度制御できます。あなたはすべてのディレクトリではありません。他の人のコードを自由に破壊します。どうやってやったの?
比較的簡単だと思っていたのですが、当時は各ディレクトリにオーナーファイルを入れて説明するのかと思っていたのですが、後にグーグル内の多くのプロジェクトでこのメカニズムが採用されていることに気づきました。後で、他のコードを調べましたが、それらも処理されたファイルでした。詳細には多少の違いがあるかもしれません。社内で3つの役割を定義しています。1つは所有者、2つ目は責任者、3つ目はそれを作成する人です。
さらに、それをどのように統合し、Gitlabのtodoを使用します。私たちは習慣を身につけ、インターフェースに入り、最初にクリックして、今日私がしなければならない仕事を確認します。これは、Tencentの製品のようで、グループで毎日叫ぶわけではありません。
もう1つはメールで、これもコミュニケーションの手段です。誰もがメールで長い会話をしています。もちろん、より緊急の通知の一部は、企業のWeChatにも送信されます。デフォルト値でコマンドを渡すと言ったので、gitlabマスターはより緊急のメカニズムであり、これも必要です。
最後に、いくつかのより複雑な問題、完全な継続的インテグレーションについて話させてください。私は彼の強く推奨される写真を取り出しました。まず、コードを送信してリリースする必要があります。いくつかのプロセスがあります。
まず第一に、GitlabのCI / CDは特にフレンドリーなUIです。ディスカッションエリアでは、今回はコードの変更を通知し、これらの人々に通知します。この情報はGitlabtodoに追加されます。
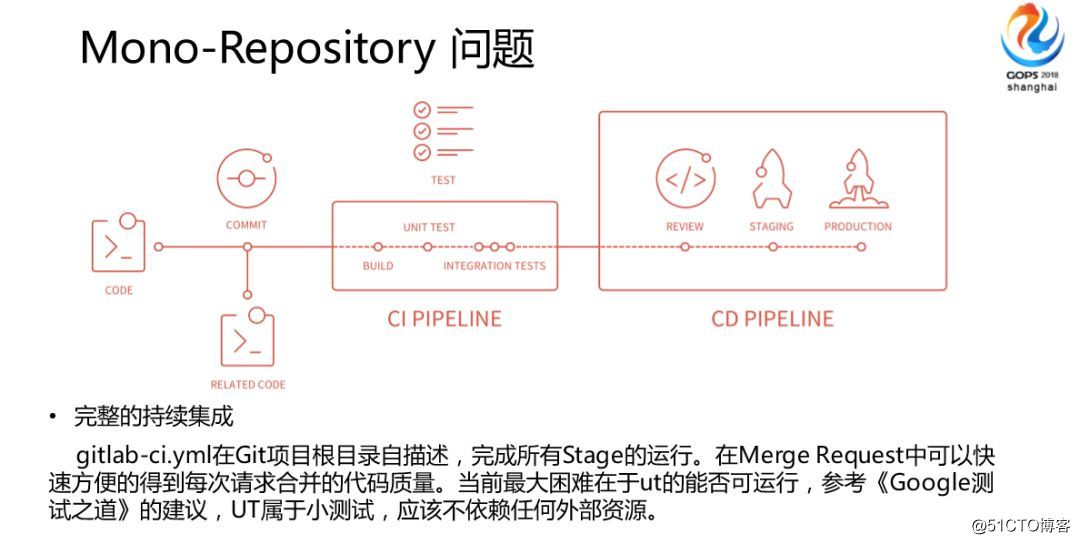
3. Mono-Repo CI/CD
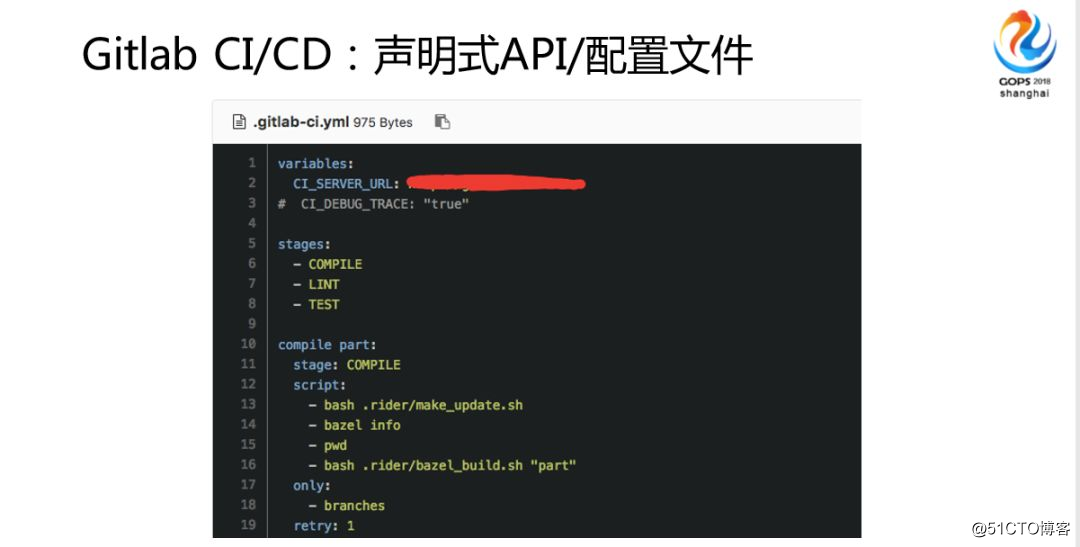
もう1つの非常に重要な点があります。無数の企業が多くのCI / CDシステムを製造しているのを見てきましたが、それらはすべて開発シナリオから外れています。なんでそんなこと言うの?さまざまなシステムをカットする必要がないため、1つのプラットフォームですべてを実行することを強くお勧めします。これらはコストがかかり、開発者が絶えず切り替えるため、特に面倒です。すべてのCI / CDプロセスをカスタマイズする必要はありませんが、無料でプレイできます。
最初はなぜこのアプローチが好きなのか特にわかりませんでしたが、Googleの内部では誰もがエンジニアであり、コードを使用できるため、それについて考えました。ですから、これは非常に良いことだと思います。いくつかのドキュメントが宣言型の説明であることがわかったかどうかも含めて、本質的には、それらを説明できることを願っています。
さらに、フックプラグインを作成しました。このプラグインは、各ディレクトリの一部の情報を解釈します。たとえば、このディレクトリにアクセスする必要がある人は、ここに小さな矢印があります。Gitlabの場合と同じように、気に入ってもらえます。取得できれば、メイントランクにマージされます。
また、CodeOwnerを使用すると、いくつかの問題が発生します。まず、私たちは技術的な専門家ではなく、保守が非常に困難です。そして、彼のCodeOwnerは基本的に何もインストールする必要がなく、変更されたすべての環境をコンテナーにしました。したがって、すべての言語ミューテーション環境には鏡像(音)があります。後で、自分でミラーを作成することをお勧めします。また、内部にプライベートミラーもあり、自分で環境を構築できます。
後でGitlabCI / CDの何が問題だったのかがわかりましたか?1つ目は、ブランチアフィニティのスケジューリングです。コードをドラッグし続ける必要があります。これらのファイルは非常に小さいため、多くのネットワーク要求を送信する必要があります。そして、CI / CDをさらに抽象化する必要があります。

その後、K8Sには実際に船首があることがわかり、徐々にこの方向に進化しています。

これはProwのアーキテクチャです。実際、彼には追加の抽象化レイヤーがあります。フックが抽象化された後、彼には別のモジュールがあります。現在、Prowの関係者と連絡を取り合っているため、Gitlabコードの埋め込みを数多く行っており、関係者とも連絡を取り続けています。時間関係図は、単純にスケジューリングに分割され、処理タスクに分割されます。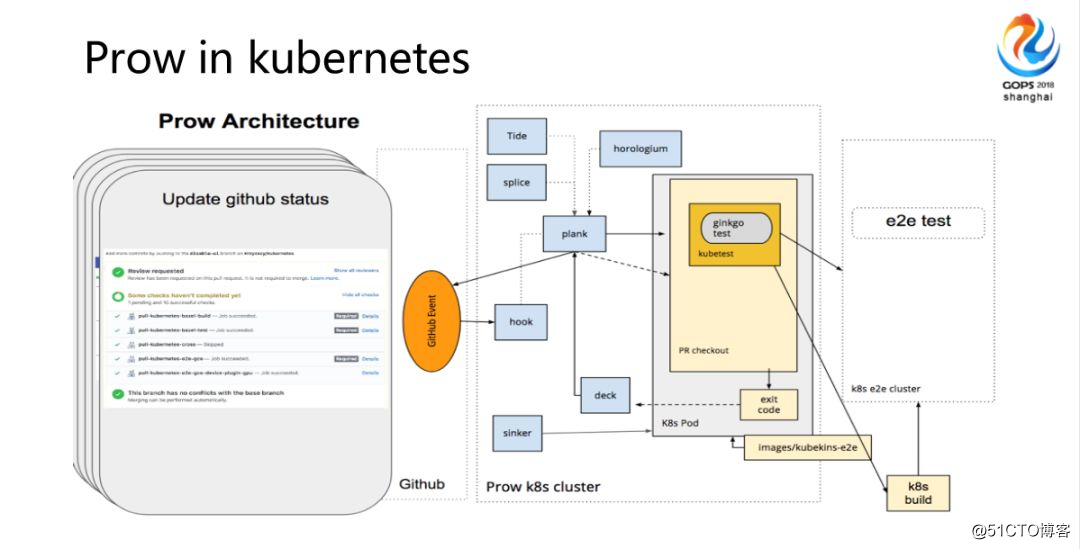
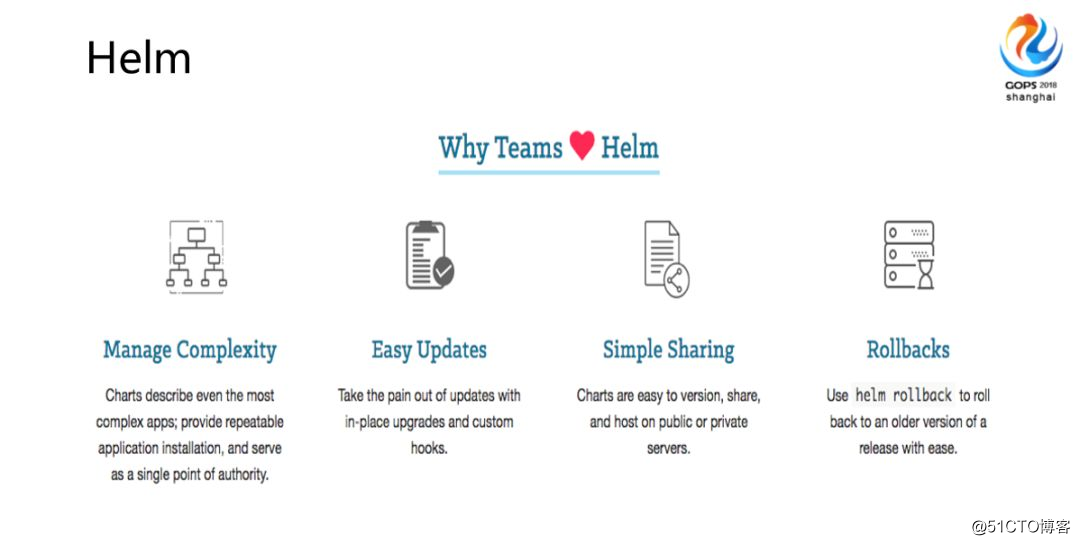
また、非常に興味深いトピックがあります。後で、彼の中にヘルムと呼ばれるツールがあることを発見しました。UTのカバー率が非常に高いため、基本的なライブラリは言うまでもありませんが、ビジネスコードが実際にUTをうまく実行することは非常に困難です。私たちはますますミドルウェアに依存していますが、実際には非常に複雑です。すべてのエンジンをコーディングする必要があります。非常に複雑で、さまざまな言語があると思います。
それで、最初は自分で何かを作ることを考えましたが、後でそれが少しばかげていて、作業負荷が非常に重いことがわかりました、それはコンテナ化できますか?つまり、彼が依存しているリソースであるデータ操作レイヤーは、コンテナーにもあります。
私たちは物理的なマシンに依存しています。データにぶつかってデータを入力します。クリーンアップしないと非常に面倒です。Helmは、これらのイメージの管理とアップグレードを支援します。また、依存するバージョンと開始するタイミングを示す自己記述型ファイルでもあり、非常に便利だと思います。
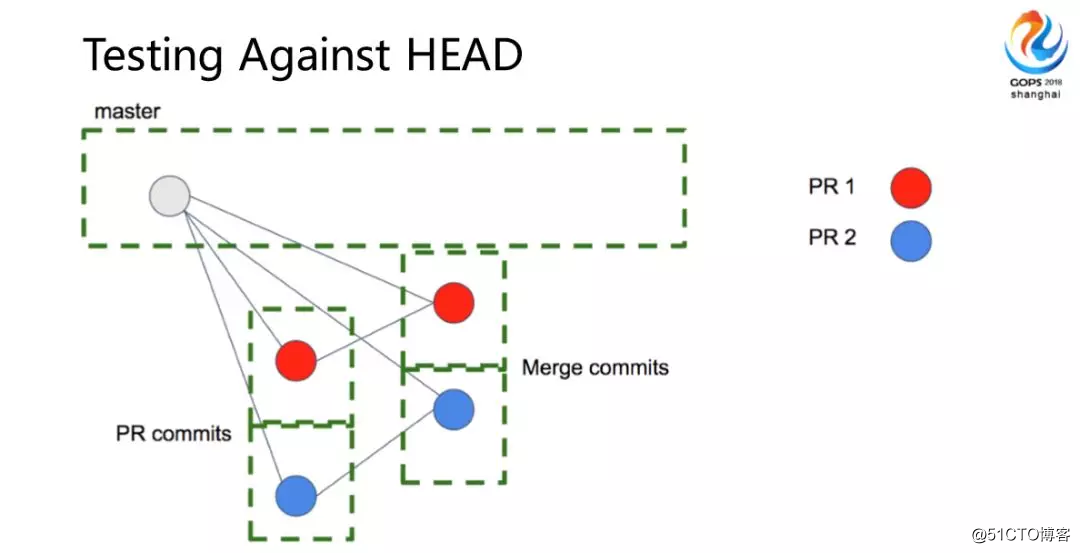
コードを調整するとき、トランクは1つしかないため、他はブランチコードです。クローズするときは、最初に最初のクロージングを渡す必要があります。最初のクロージングの完了後、トランクに入るコードは、失敗する可能性があるため、パイプラインを再度実行する必要があります。統合テストを含め、パイプラインを1回だけ実行します。この場合、後でリスクデータを読みました。彼は1日に数個または数十個しか組み合わせることができませんでしたが、1日に数十個を組み合わせることができます。